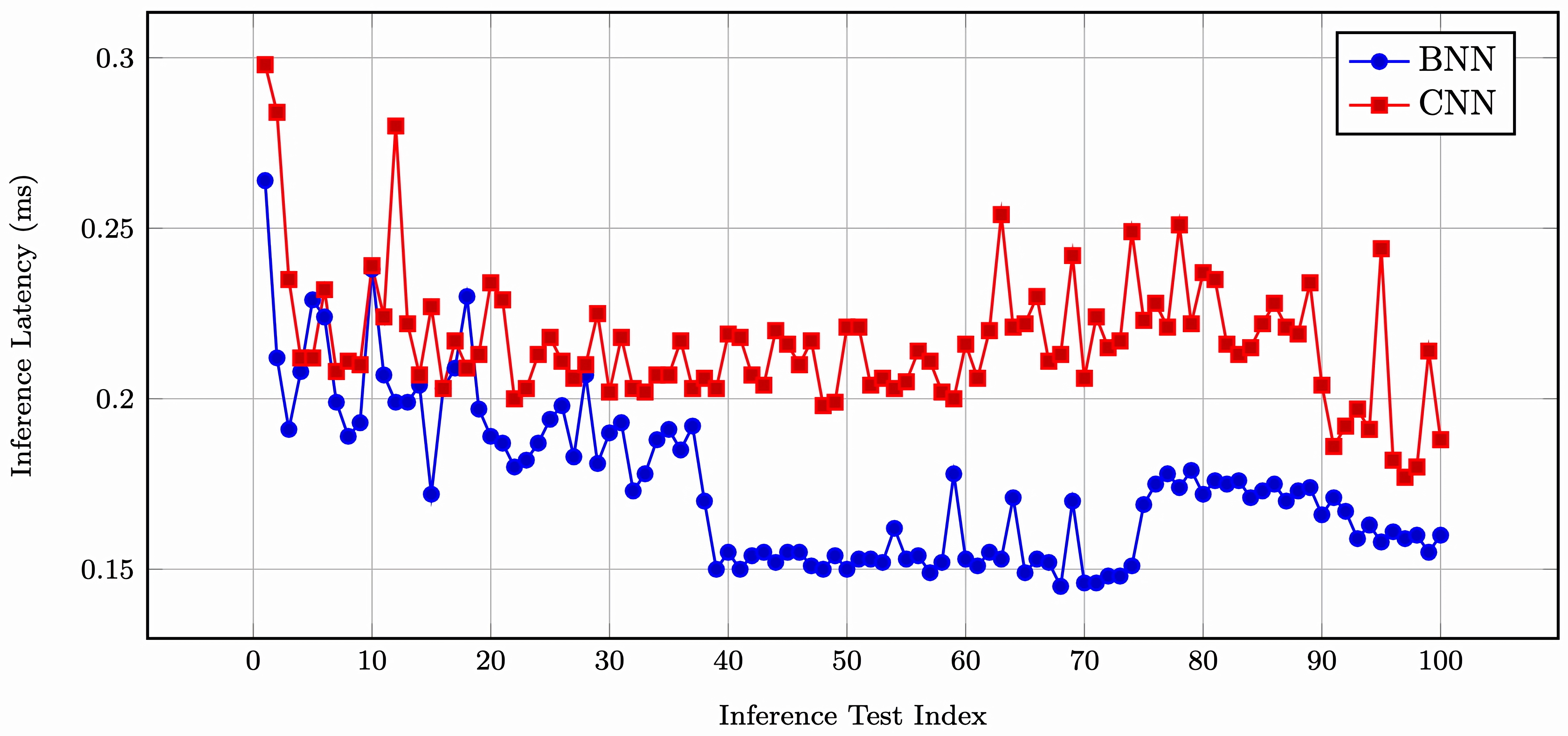
Binary neural networks provide a promising solution for low-power, high-speed inference by replacing expensive floating-point operations with bitwise logic. This makes them well-suited for deployment on resource-constrained platforms such as FPGAs. In this study, we present a fully custom BNN inference accelerator for handwritten digit recognition, implemented entirely in Verilog without the use of high-level synthesis tools. The design targets the Xilinx Artix-7 FPGA and achieves real-time classification at 80\,MHz with low power consumption and predictable timing. Simulation results demonstrate 84\% accuracy on the MNIST test set and highlight the advantages of manual HDL design for transparent, efficient, and flexible BNN deployment in embedded systems. The complete project including training scripts and Verilog source code are available at GitHub repo for reproducibility and future development.
The progress in the field of deep learning has led to major advancements in speech recognition, generative AI, large language models, and computer vision. The widely used neural network models used in these applications have achieved state of the art performance across a wide range of tasks. Despite their high accuracy, the models rely on floating-point computations that typically use 32-bit representations. Moreover, they have large number of parameters to be set ranging from millions to billions. These lead to significant computational cost and memory usage. Therefore, several model compression techniques have been proposed for this purpose. They try to reduce the memory and computational resource usage without severely impacting performance and accuracy.
One of the most effective compression techniques used for this purpose is quantization. Here, weight and activation values in a neuron are represented using low-precision numbers. Binary quantization is the most extreme form of quantization in this category. It restricts weights and activations to two possible values as -1 and +1 or 0 and 1. This form of quantization creates special class of models known as binary neural networks (BNNs). BNNs significantly reduce memory usage by representing both weights and activations using only 1 bit instead of 32 bits for floating-point values. Moreover, expensive floating-point matrix multiplications in neural network computations can be replaced with lightweight bitwise operations such as XNOR and popcount, which offer significant speedup. For instance, BNNs can achieve up to 32 times memory savings and up to 58 times computational speedup on CPUs [2].
We can summarize work in literature on BNNs as follows. Courbariaux et al. [3] introduced the BinaryNet, which used the sign function for binarization along with a straight-through estimator (STE) to enable gradient propagation during training. Rastegari et al. [4] extended this approach with XNOR-Net, introducing scaling factors to improve accuracy in convolutional architectures for large-scale tasks such as ImageNet classification. FPGAs are a natural fit for BNN acceleration due to their reconfigurable fabric, inherent parallelism, and potential for custom hardware optimization. Their configurable logic and on-chip memory make them efficient platforms for implementing bitwise operations. Therefore, several frameworks targeted BNN deployment on FPGAs using high-level synthesis (HLS) tools. Umuroglu et al. [5] proposed FINN, a dataflow-style framework composed of matrix-vector units for scalable BNN inference on reconfigurable hardware. Zhao et al. [6] developed a system for accelerating binary convolutional networks on programmable FPGAs using software-defined techniques. Prior studies have shown that BNNs can achieve competitive accuracy on benchmarks like MNIST and CIFAR-10 while offering substantial gains in energy efficiency and runtime performance [7]. The reader can consult review papers on BNNs for a comprehensive overview of their current status and developments [2,8,9].
While the previous methods have significantly advanced BNN deployment on hardware, they largely focus on convolutional architectures and relied on HLS tools for hardware generation or frameworks that abstract the underlying logic. While these tools accelerate development, they limit visibility into how the network operates at a low level, especially in terms of data flow, timing and logic decisions. This lack of transparency makes it harder to optimize, debug or fully understand the hardware behavior of the systems.
We propose a fully connected BNN inference system from scratch in Verilog without any use of HLS tools to overcome the shortcomings in previous studies. The target is handwritten digit classification using the MNIST dataset. All inference steps like binarized weight loading, XNOR-popcount operations, threshold comparison and argmax output are implemented using cycle-accurate FSMs on a Nexys A7-100T FPGA. This allows full control over memory layout, logic structure and timing which provides a transparent framework for understanding binary inference at hardware level. Therefore, this implementation provides direct insight into how each bit is processed, how intermediate values are handled and how control flows between layers. No other BNN implementation has been found that provides this level of manual control over both the model architecture and its bitwise execution on FPGA. The study focuses on the FPGA based inference stage of a trained BNN. The model is trained offline using Python and TensorFlow and then exported in binary format for hardware deployment. The design has a few limitations. First, it only supports fully connected architectures and convolutional layers are not included. Second, test images, weights and thresholds are stored in static ROM, which means changing the input set or the network architecture requires re-synthesis. Third, the Verilog code is specific
This content is AI-processed based on open access ArXiv data.