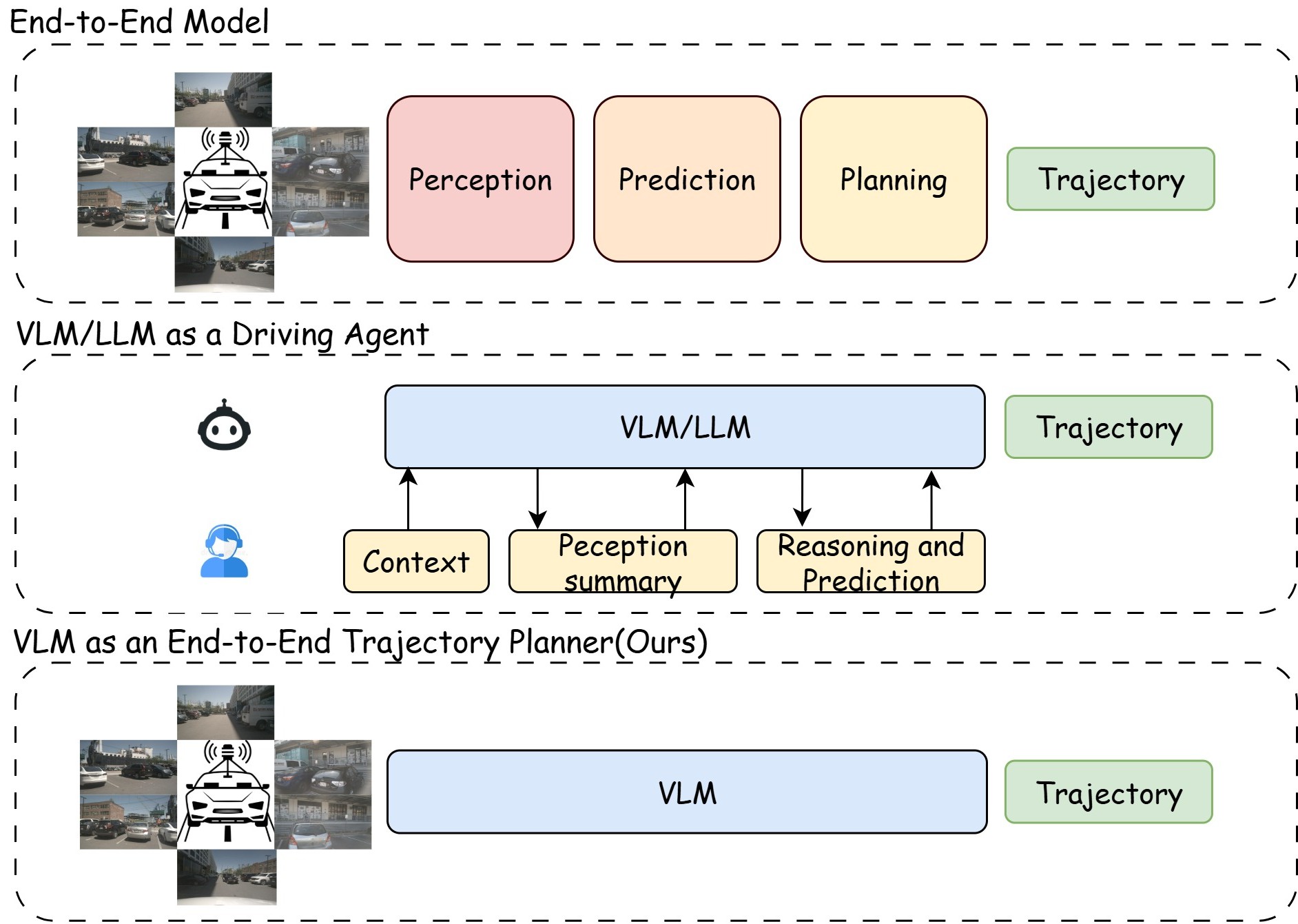
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
Trajectory planning transforms the dynamic visual environment into a safe and comfortable motion plan for autonomous vehicles. Conventional end-to-end models decompose this task into sequential modules-object detection, motion forecasting, occupancy prediction, and trajectory generation [10,11]. End-to-end trajectory planners lack semantic understanding and exhibit limited few-shot generalization, which makes them prone to errors such as failing to follow traffic signs and struggling under uncommon conditions like adverse weather, atypical road layouts, or non-standard human behaviors.
Vision language models (VLMs) have recently demonstrated striking few-shot learning, semantic grounding, and chain-of-thought reasoning across heterogeneous vision language tasks, hinting at a unified alternative: recast perception, prediction, and planning as a single vision-languageconditioned reasoning problem [7,8,38,39,45]. However, two obstacles stand in the way. First, without specialized training, general-purpose VLMs struggle to generate structured and numerically precise trajectory plans within a single inference step. Instead, they require multi-turn interactions to iteratively refine the output into a valid trajectory format [27,28], which introduces substantial and impractical latency that hinders real-world deployment. Second, most existing autonomous driving datasets lack structured naturallanguage rationales or action traces that explicitly connect scene understanding to the corresponding ground-truth trajectory-information that would teach a VLM how to reason through the scene and derive a proper driving plan, depriving the model of essential supervision [4,12,25,26,33].
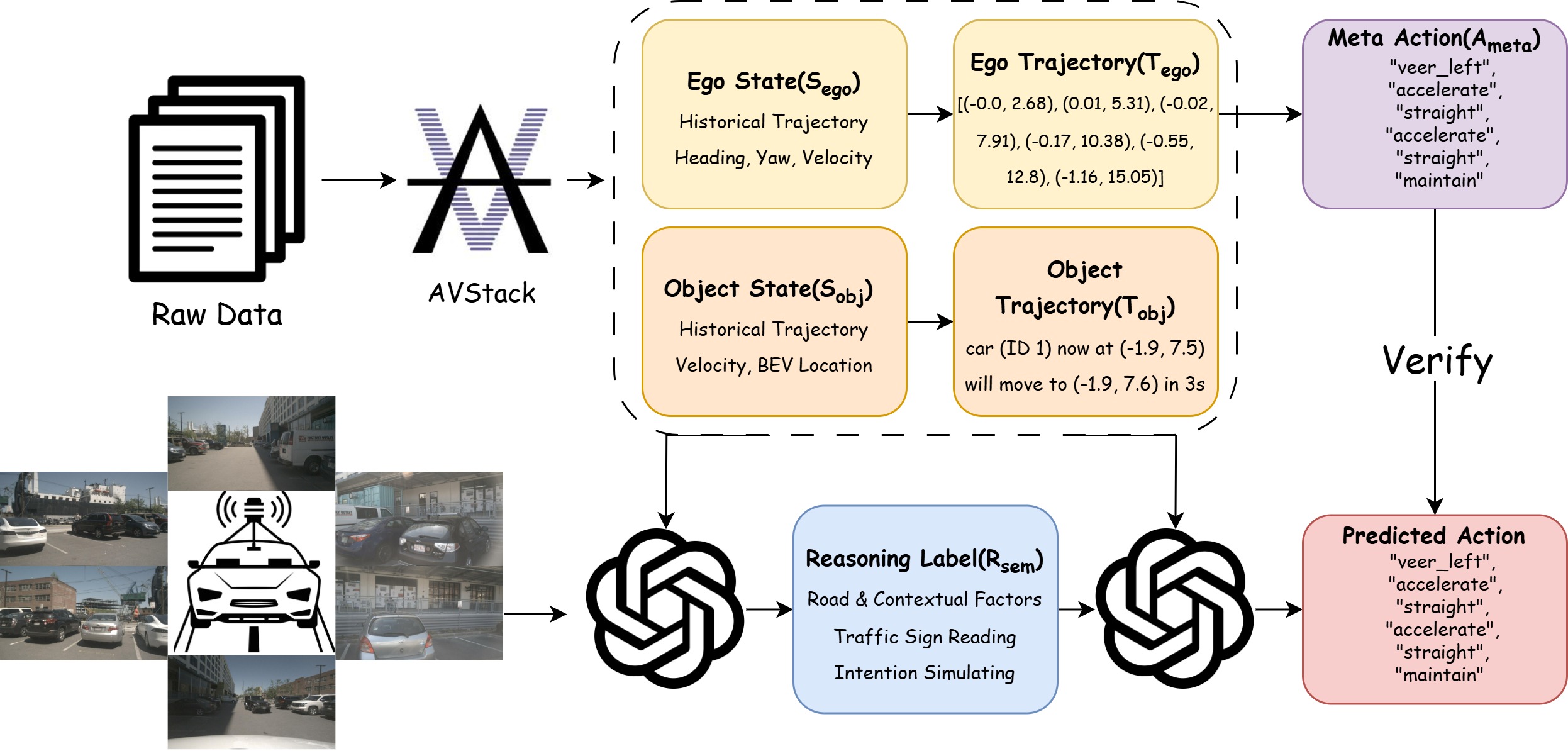
We address these challenges with LLaViDA, a Large Language Vision Driving Assistant for trajectory planning. Only taking camera images as input, the model produces Figure 2. Construction pipeline of the proposed NuScenes-TP dataset. Starting from the raw NuScenes data, we extract ego and object states, derive their corresponding future trajectories, and further compute ego meta-actions from the ego trajectory. In parallel, GPT-4o is used to generate reasoning annotations, which are then validated against the ground-truth meta-actions.
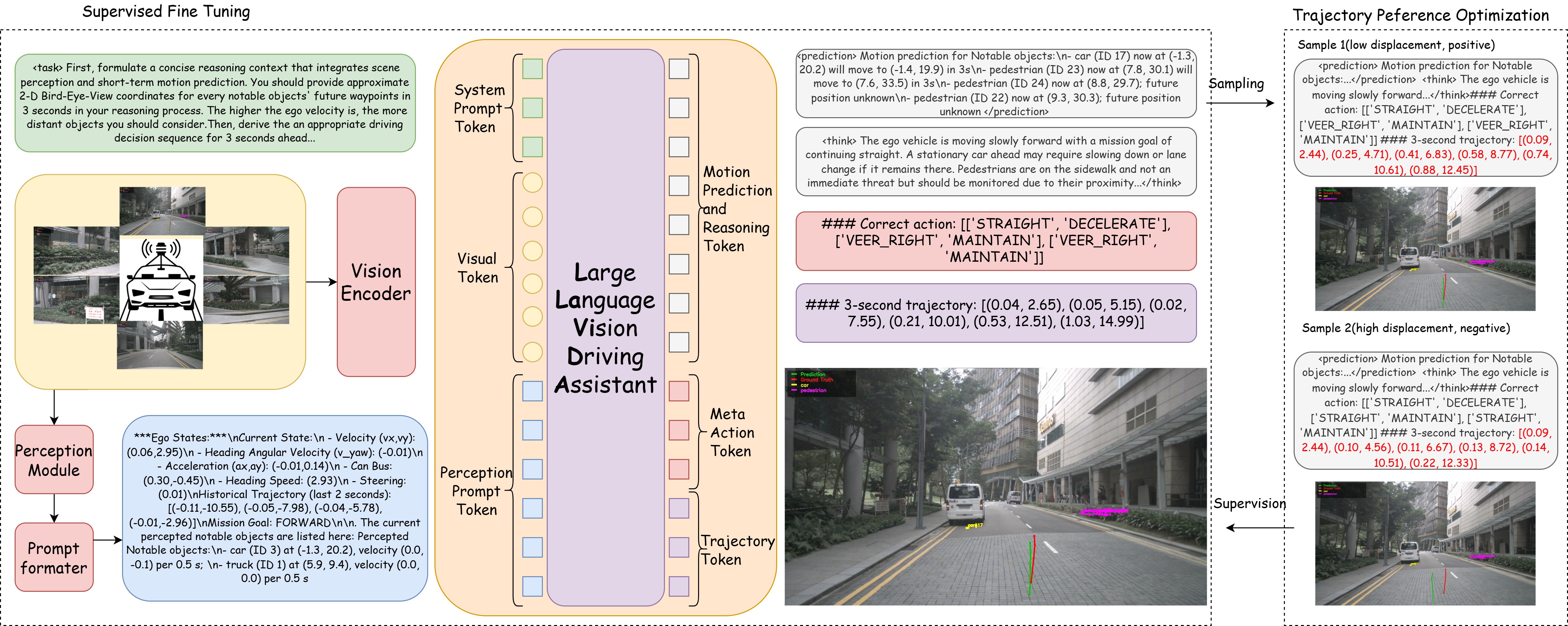
a hierarchical chain-of-thought that forecasts the motion of all salient traffic participants, describes scene semantics together with road layout and weather conditions, infers egovehicle intentions in context, derives a suitable meta-action (e.g., lane change, maintain speed), and finally emits a numerically precise low-risk trajectory that respects vehicle dynamics and traffic rules. Training proceeds in two stages. First, supervised vision-language fine-tuning grounds visual tokens in traffic semantics. Second, Trajectory Preference Optimization (TPO) further optimizes trajectory quality by injecting regression-based supervision without requiring additional annotations. For each training prompt, we sample multiple complete outputs from the checkpoint after supervised fine-tuning and score their trajectories by the ℓ 2 distance to the ground-truth path; these scores define preferred vs. dispreferred pairs for TPO. This replaces purely token-level supervision with a continuous, trajectory-quality signal-injecting a regression-like supervision into the generative objective-so the VLM learns to discriminate subtle geometric differences between candidate paths and consistently prefer lower-error plans.
To enable this process, we curate NuScenes-TP, a trajectory-planning dataset derived from the public NuScenes [4] corpus and enriched with ground-truth meta action sequences defined by crafted rules and a naturallanguage reasoning process generated by GPT-4o. The empirical results confirm the effectiveness of our approach. On the NuScenes evaluation benchmark, LLaViDA substantially reduces the average displacement error and the collision rate, outperforming both End-to-End planning pipelines and contemporary VLM/LLM-based baselines. These findings demonstrate that language-conditioned reasoning, enhanced by reinforcement learning, yields a robust and deployable VLM-based trajectory-planning system. In summary, our contributions are:
Vision-Language Models. Vision-Language Models (VLMs) have emerged as a central research topic in the computer vision community [3,17,18,21]. Pretrained on large-scale image-text pairs and subsequently fine-tuned with extensive vision instruction-tuning corpora, VLMs acquire strong commonsense reasoning capabilities, broad world knowledge, and robust in-context learning abilities. Building on these foundations, numerous works have ex-plored their application to downstream specialized domains, such as robotics [15,31,44], embodied AI [24,42], and autonomous driving [7,8,38,39,45]. These domain-specific systems are typically obtained by fine-tuning a base VLM on carefully curated datasets, transforming it into an expert for the target domain.
Traditional End-to-End Models for Trajec
This content is AI-processed based on open access ArXiv data.