Full-body motion tracking plays an essential role in AR/VR applications, bridging physical and virtual interactions. However, it is challenging to reconstruct realistic and diverse full-body poses based on sparse signals obtained by head-mounted displays, which are the main devices in AR/VR scenarios. Existing methods for pose reconstruction often incur high computational costs or rely on separately modeling spatial and temporal dependencies, making it difficult to balance accuracy, temporal coherence, and efficiency. To address this problem, we propose KineST, a novel kinematics-guided state space model, which effectively extracts spatiotemporal dependencies while integrating local and global pose perception. The innovation comes from two core ideas. Firstly, in order to better capture intricate joint relationships, the scanning strategy within the State Space Duality framework is reformulated into kinematics-guided bidirectional scanning, which embeds kinematic priors. Secondly, a mixed spatiotemporal representation learning approach is employed to tightly couple spatial and temporal contexts, balancing accuracy and smoothness. Additionally, a geometric angular velocity loss is introduced to impose physically meaningful constraints on rotational variations for further improving motion stability. Extensive experiments demonstrate that KineST has superior performance in both accuracy and temporal consistency within a lightweight framework. Project page: https://kaka-1314.github.io/KineST/
Full-body pose reconstruction based on Head-Mounted Displays (HMDs) facilitates a diverse array of AR/VR applications, including patient rehabilitation, realistic avatar generation, and the control of teleoperated humanoid robots (He et al. 2024;Dai et al. 2024c). However, due to the sparsity of signals captured by HMDs, inferring accurate and natural full-body motion remains a challenging problem.
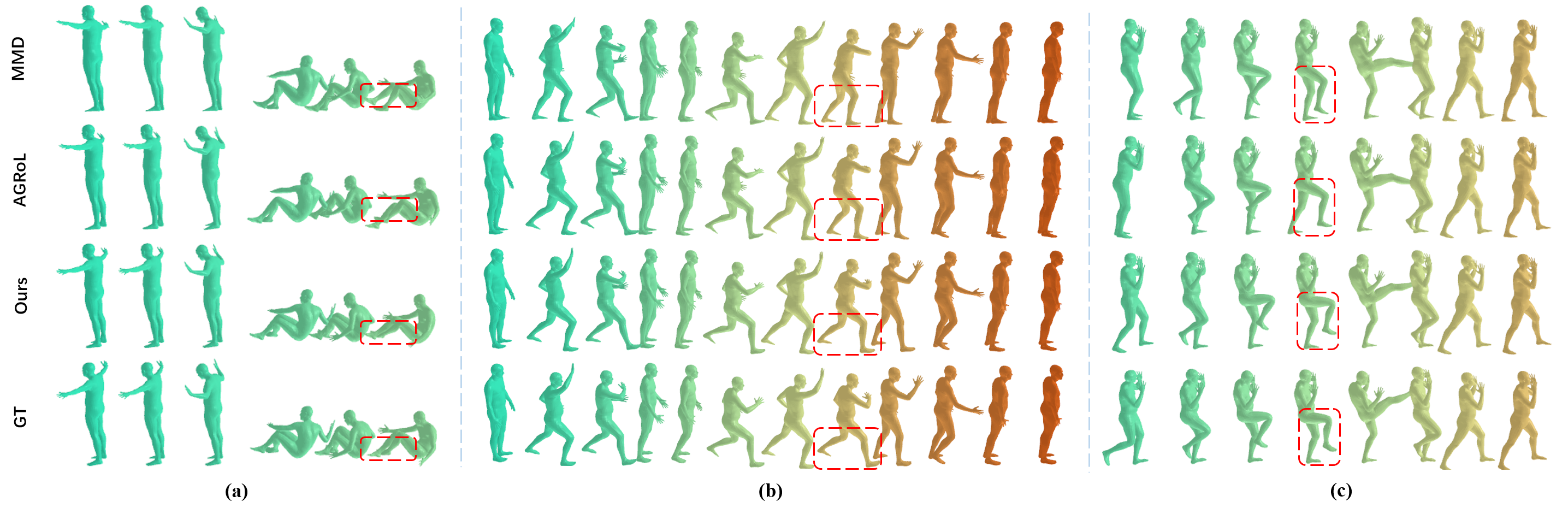
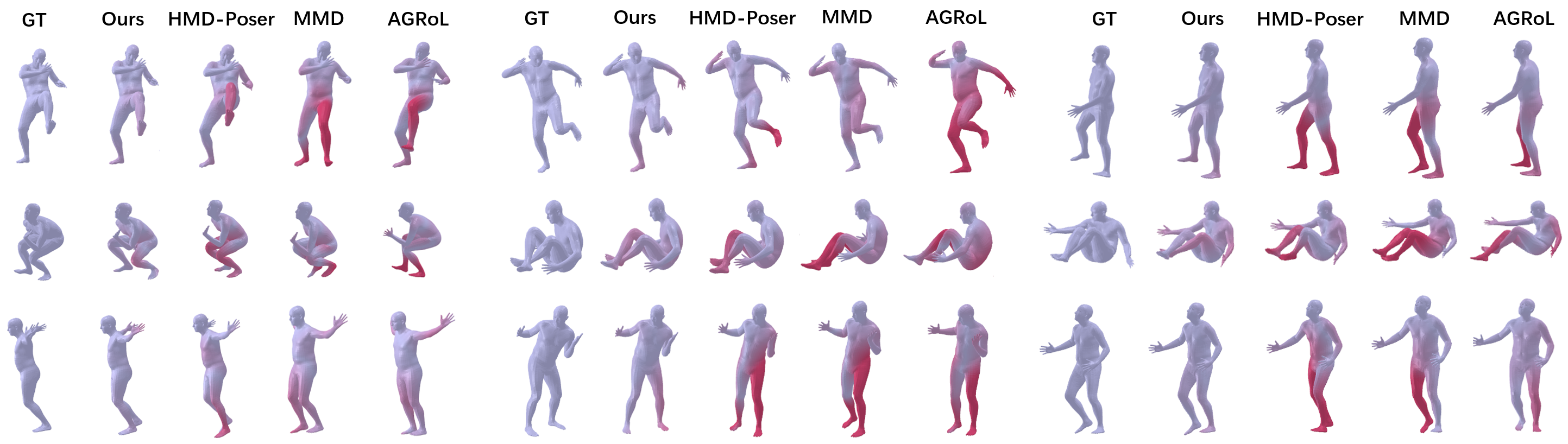
Previous works have demonstrated the feasibility of reconstructing realistic full-body motion, but often at the expense of substantial computational cost and large parameter counts, which limits its application. For example, Avatar-JLM (Zheng et al. 2023) improves performance by stack-Figure 1: Comparison of our approach with state-of-theart methods in terms of overall performance. Our method achieves the smallest average position error and smoother motion, and maintains a lightweight model architecture.
ing multiple Transformer blocks (Vaswani 2017) in a highdimensional space, while SAGE (Feng et al. 2024) leverages large generative models such as VQ-VAE (Van Den Oord, Vinyals et al. 2017) and diffusion models (Rombach et al. 2022). Their high deployment costs underline the need for more efficient solutions that can achieve high accuracy with a compact framework.
To build lightweight and robust models for realistic fullbody pose estimation from sparse inputs, recent works have explored various solutions. For example, RPM (Barquero et al. 2025) introduces a prediction consistency anchor to reduce sudden motion drift, which improves smoothness but sacrifices pose accuracy. To improve pose accuracy, separate temporal and spatial modules are adopted to better capture the complex dependencies of human motion (Dai et al. 2024a;Dong et al. 2024). Although this dual-module design enhances joint interaction modeling, some modeling capacities are shifted to single-frame spatial features, which can compromise motion smoothness. Therefore, a key question is raised: how can we design a model that remains lightweight yet achieves both high accuracy and motion smoothness?
Recently, the State Space Duality (SSD) framework (Dao and Gu 2024) introduces a special and robust scanning strategy and shows great promise for efficient time-series mod-eling, making it a strong candidate for our task. However, directly applying SSD to human motion tracking yields unsatisfactory performance, primarily due to its unidirectional scanning and the absence of specific designs for full-body pose reconstruction.
To tackle this challenge, we propose KineST, a lightweight yet effective model, to fully extract spatiotemporal dependencies while integrating local and global pose information. Specifically, we first design a Temporal Flow Module (TFM) to learn inter-frame dynamics. The main components in TFM are SSD blocks in which a bidirectional scanning strategy is employed to initially capture motion features. These are followed by a Local Motion Aggregator (LMA) and a Global Motion Aggregator (GMA), which progressively refine local and global motion dependencies.
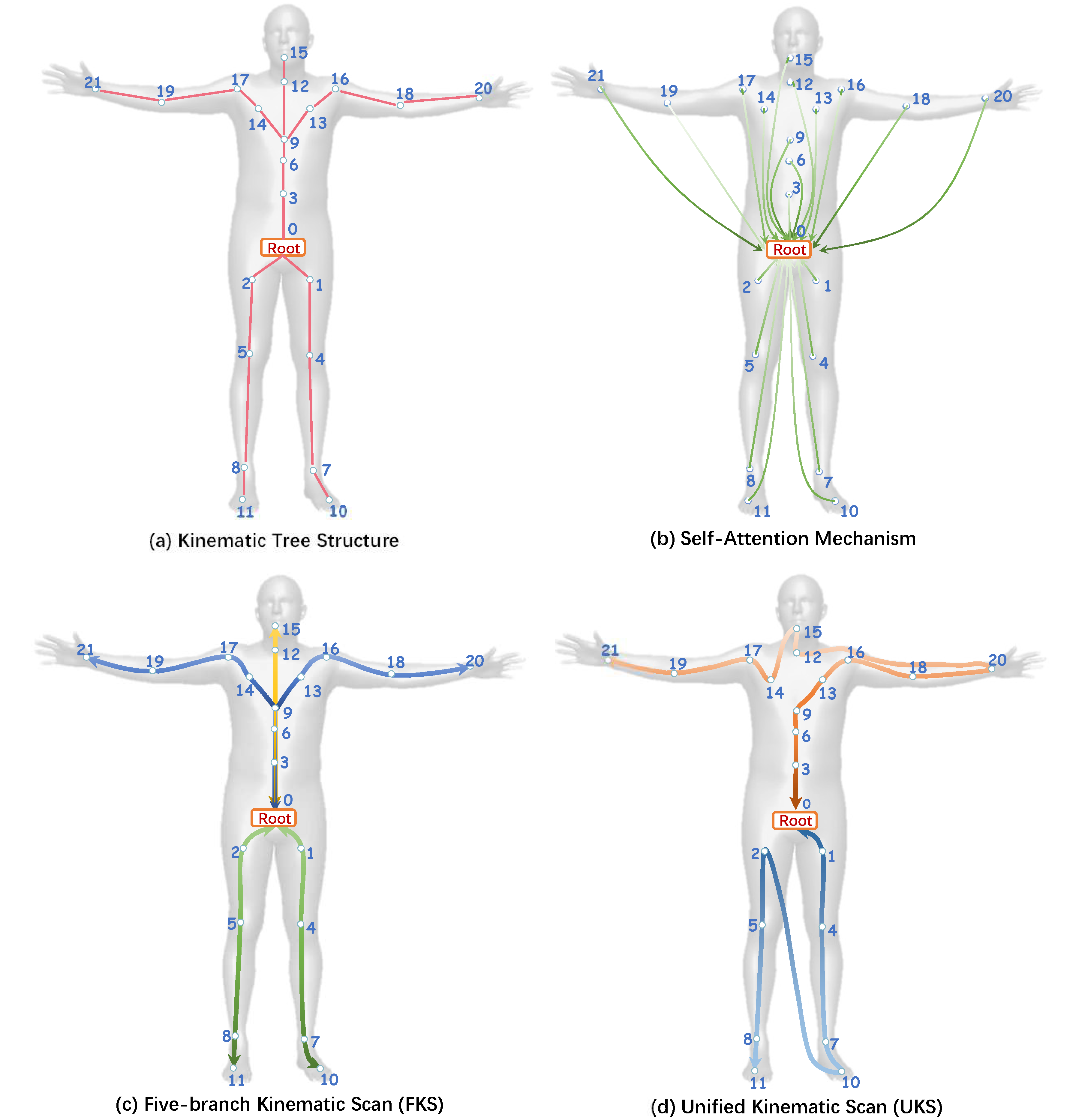
Secondly, we introduce a robust Spatiotemporal Kinematic Flow Module (SKFM), which employs a Spatiotemporal Mixing Mechanism (STMM) to tightly couple spatial and temporal contexts and maintain a balance between accuracy and temporal continuity. Moreover, a novel Kinematic Tree Scanning Strategy (KTSS) is employed to incorporate kinematic priors into spatial feature capture and fully capture intricate joint relations. To further improve motion continuity, a geometric angular velocity loss is proposed, jointly constraining both the magnitude and direction of rotation changes in a geometrically consistent way. The contributions of this work are summarized as follows:
• A kinematics-guided state space model, KineST, is proposed, which can not only fully extract spatiotemporal information but also integrate local-global perception.
Earlier methods explore full-body tracking using 4 or 6 IMUs (Huang et al. 2018;Yi et al. 2022;Yang, Kim, and Lee 2021;Yi, Zhou, and Xu 2021;Von Marcard et al. 2017;Jiang et al. 2022b). However, in AR/VR scenarios, HMDs are more practical and widely adopted, which typically provide only 3 tracking signals from the head and hands.
Based on HMD inputs, generative techniques are adopted to synthesize full-body poses. For example, in FLAG (Aliakbarian et al. 2022) and VAE-HMD (Dittadi et al. 2021), a variational auto-encoder (VAE) and a flow-based model are applied, respectively. In AGRoL (Du et al. 2023) and SAGE (Feng et al. 2024), the reconstruction of avatars is achieved by diffusion models or VQ-VAEs. Correspondingly, another type of work is based on regression-based approaches. Transformer-based architecture is adopted to predict full-body poses from these three sparse signals, such as AvatarPoser (Jiang et al. 2022a), AvatarJLM (Zheng et al. 2023), HMD-Poser (Dai et al. 2024a), and RPM (Barquero et al. 2025). KCTD (Dai et al. 2024b) designs an MLPbased mo
This content is AI-processed based on open access ArXiv data.