Social media platforms, while enabling global connectivity, have become hubs for the rapid spread of harmful content, including hate speech and fake narratives \cite{davidson2017automated, shu2017fake}. The Faux-Hate shared task focuses on detecting a specific phenomenon: the generation of hate speech driven by fake narratives, termed Faux-Hate. Participants are challenged to identify such instances in code-mixed Hindi-English social media text. This paper describes our system developed for the shared task, addressing two primary sub-tasks: (a) Binary Faux-Hate detection, involving fake and hate speech classification, and (b) Target and Severity prediction, categorizing the intended target and severity of hateful content. Our approach combines advanced natural language processing techniques with domain-specific pretraining to enhance performance across both tasks. The system achieved competitive results, demonstrating the efficacy of leveraging multi-task learning for this complex problem.
💡 Deep Analysis
📄 Full Content
Decoding Fake Narratives in Spreading Hateful Stories: A Dual-Head
RoBERTa Model with Multi-Task Learning
Yash Bhaskar1
IIIT Hyderabad
yash.bhaskar@research.iiit.ac.in
Sankalp Bahad1
IIIT Hyderabad
sankalp.bahad@research.iiit.ac.in
Parameswari Krishnamurthy2
IIIT Hyderabad
param.krishna@iiit.ac.in
Abstract
Social media platforms, while enabling global
connectivity, have become hubs for the rapid
spread of harmful content, including hate
speech and fake narratives (Davidson et al.,
2017; Shu et al., 2017).
The Faux-Hate
shared task focuses on detecting a specific phe-
nomenon: the generation of hate speech driven
by fake narratives, termed Faux-Hate. Partici-
pants are challenged to identify such instances
in code-mixed Hindi-English social media text.
This paper describes our system developed for
the shared task, addressing two primary sub-
tasks: (a) Binary Faux-Hate detection, involv-
ing fake and hate speech classification, and
(b) Target and Severity prediction, categoriz-
ing the intended target and severity of hate-
ful content. Our approach combines advanced
natural language processing techniques with
domain-specific pretraining to enhance perfor-
mance across both tasks. The system achieved
competitive results, demonstrating the efficacy
of leveraging multi-task learning for this com-
plex problem.
1
Introduction
Social media has revolutionized communication,
providing unprecedented connectivity across the
globe. This increased connectivity, however, has
also inadvertently fostered the rapid dissemination
of harmful content, including the troubling com-
bination of hate speech and fabricated narratives.
Hate speech, particularly when intertwined with
falsehoods, exacerbates its detrimental impact, fu-
eling discrimination, violence, and societal unrest.
In response to this growing concern, the Faux-
Hate shared task (Biradar et al., 2024a), based on
a phenomenon recently characterized and dataset
curated by Biradar et al. (Biradar et al., 2024b), in-
troduces a unique challenge: identifying and cate-
gorizing instances of hate speech generated through
fake narratives in code-mixed Hindi-English text.
This task emphasizes the importance of detecting
and analyzing content that misleads and provokes
through a combination of misinformation and hate-
ful language. Researchers and practitioners have
increasingly turned their attention to understanding
and combating these complex phenomena.
The shared task comprises two sub-tasks: Task
A focuses on binary classification of fake and hate
labels, while Task B involves predicting the tar-
get and severity of hateful content. This paper
describes our system, methodologies, and experi-
mental results for both sub-tasks, contributing to
the broader effort to address hate speech and fake
narratives in multilingual, code-mixed contexts.
2
Related Work
The detection of hate speech and misinforma-
tion on social media has been a prominent area
of research within natural language processing
(NLP). Studies have extensively explored tech-
niques for identifying hate speech across various
languages and platforms (Warner and Hirschberg,
2012), often leveraging machine learning and deep
learning approaches.
Recent advancements in-
clude transformer-based models like BERT (Devlin
et al., 2019), RoBERTa, and multilingual BERT
(mBERT), which have shown significant success
in text classification tasks, including hate speech
detection.
Fake news and misinformation detection have
similarly gained attention (Zubiaga et al., 2018),
with methods ranging from linguistic feature anal-
ysis to neural network-based classification. The
intersection of hate speech and fake narratives,
however, remains a relatively unexplored domain,
particularly in code-mixed languages like Hindi-
English. Prior work in code-mixed text process-
ing has highlighted the challenges posed by non-
standard grammar, orthographic variations, and the
lack of annotated datasets.
This shared task builds on these research threads,
offering a novel opportunity to investigate Faux-
arXiv:2512.16147v1 [cs.CL] 18 Dec 2025
Hate in a multilingual and culturally nuanced con-
text. Our approach draws inspiration from prior
work in hate speech and fake news detection while
tailoring solutions to the unique challenges of the
code-mixed Hindi-English dataset provided in this
task.
3
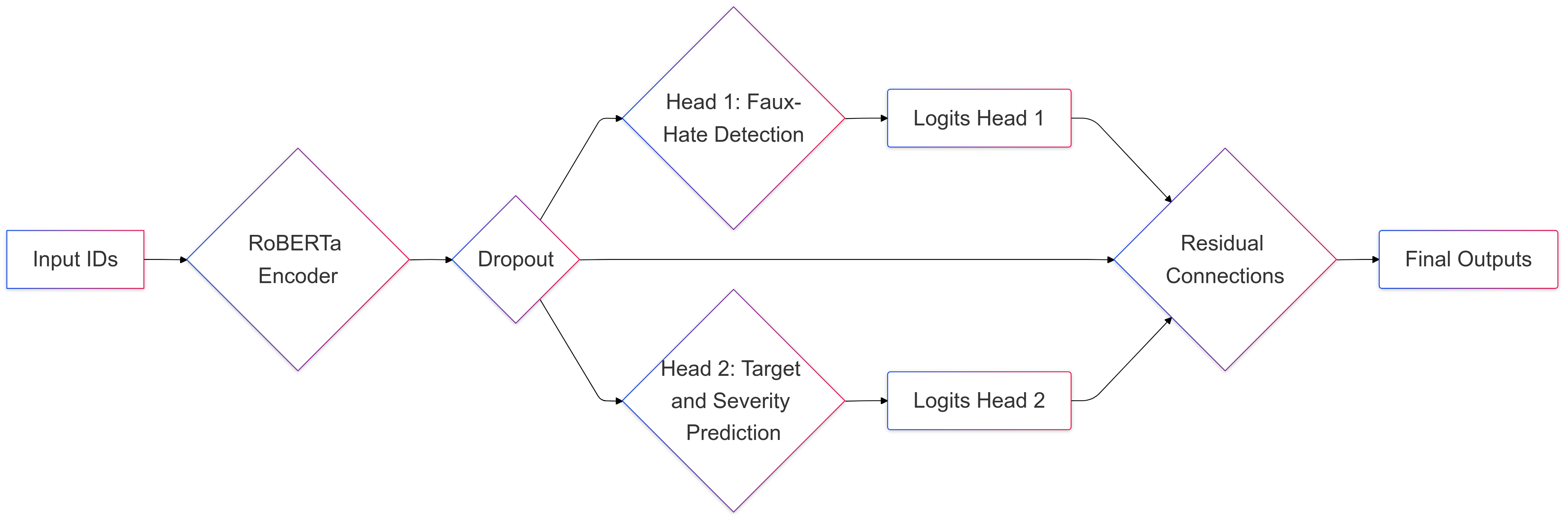
Methodology
This section outlines the architecture, compo-
nents, and training methodology of the dual-head
RoBERTa model developed for the Faux-Hate
shared task.
Our system leverages RoBERTa-
base (Liu et al., 2019) as the backbone encoder
and extends it with a dual-head classification
mechanism for simultaneous hate speech and fake
news detection. The architecture adopts a multi-
task learning approach (Caruana, 1997), enabling
the model to effectively share information across
tasks while maintaining task-specific parameteriza-
tion through dedicated classification heads. The
code for our system, including implementation
details and pre-train