We leverage increasingly popular three-dimensional neural representations in order to construct a unified and consistent explanation of a collection of uncalibrated images of the human face. Our approach utilizes Gaussian Splatting, since it is more explicit and thus more amenable to constraints than NeRFs. We leverage segmentation annotations to align the semantic regions of the face, facilitating the reconstruction of a neutral pose from only 11 images (as opposed to requiring a long video). We soft constrain the Gaussians to an underlying triangulated surface in order to provide a more structured Gaussian Splat reconstruction, which in turn informs subsequent perturbations to increase the accuracy of the underlying triangulated surface. The resulting triangulated surface can then be used in a standard graphics pipeline. In addition, and perhaps most impactful, we show how accurate geometry enables the Gaussian Splats to be transformed into texture space where they can be treated as a view-dependent neural texture. This allows one to use high visual fidelity Gaussian Splatting on any asset in a scene without the need to modify any other asset or any other aspect (geometry, lighting, renderer, etc.) of the graphics pipeline. We utilize a relightable Gaussian model to disentangle texture from lighting in order to obtain a delit high-resolution albedo texture that is also readily usable in a standard graphics pipeline. The flexibility of our system allows for training with disparate images, even with incompatible lighting, facilitating robust regularization. Finally, we demonstrate the efficacy of our approach by illustrating its use in a text-driven asset creation pipeline.
Facial avatars are essential for a wide range of applications including virtual reality, video conferencing, gaming, feature films, etc. As virtual interactions become more prevalent, the demand for compelling digital representations of human faces will continue to grow. A person's face avatar should accurately reflect their identity, while also being controllable, relightable, and efficient enough to use in real-time applica-tions. These requirements have driven significant research endeavors in computer vision, computer graphics, and machine learning. However, it is still challenging to create such avatars in a scalable and democratized way, i.e. with commodity hardware and limited input data and without using multiple calibrated cameras or a light-stage.
Neural Radiance Fields (NeRFs) [74] have become increasingly prevalent in both computer vision and computer graphics due to their impressive ability to reconstruct and render 3D scenes from 2D image collections. In particular, various authors have achieved impressive photorealistic results on 3D human faces. The implicit nature of the NeRF representation facilitates high-quality editing (see e.g. [21]), since it keeps edits both non-local and smooth (similar to splines, but dissimilar to triangulated surfaces). In addition, the regularization provided by the low dimensional latent space keeps edits of faces looking like faces. It is far more difficult for non-expert users to edit triangulated surface geometry and textures directly.
Although only recently proposed, Gaussian Splatting [53] has quickly become remarkably popular. Its explicit nature makes it significantly more amenable to various constraints than other (typically implicit) neural models. Importantly, NeRFs and Gaussian Splatting complement each other, as one can edit a NeRF representation before converting it into a Gaussian Splatting model for various downstream tasks that would benefit from having a more structured and constrained representation.
The standard graphics pipeline has been refined over decades via both software and hardware optimizations and has become quite mature, especially for real-time applications. In fact, in spite of the maturity and impact of ray tracing, it has only recently been somewhat incorporated into gaming consoles and other real-time applications. Silicon chip development is often a zero-sum game where adding one capability necessarily removes another. However, ray tracing has been embraced in non-realtime applications and is often used to create content for real-time applications. It is not a stretch to assume that neural rendering methods will be treated similarly. Thus, converting neural models, such as Gaussian Splatting, into triangulated surfaces with tex-
Segmentation Maps
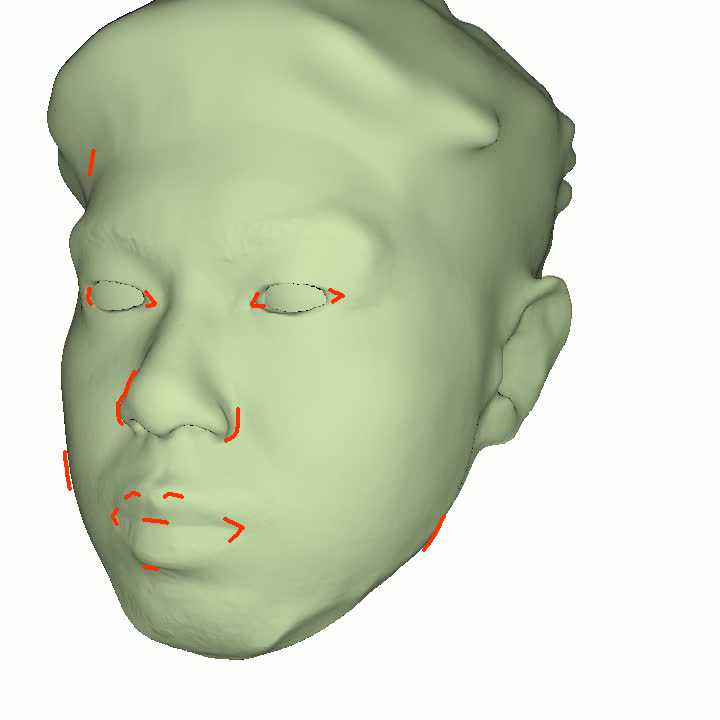
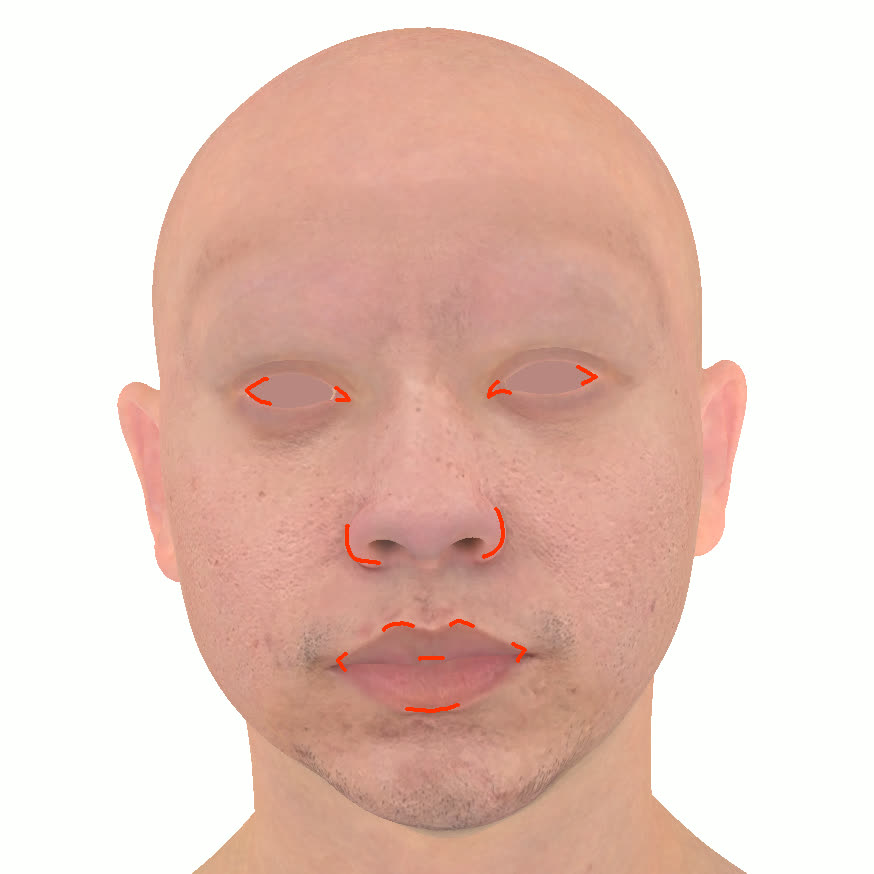
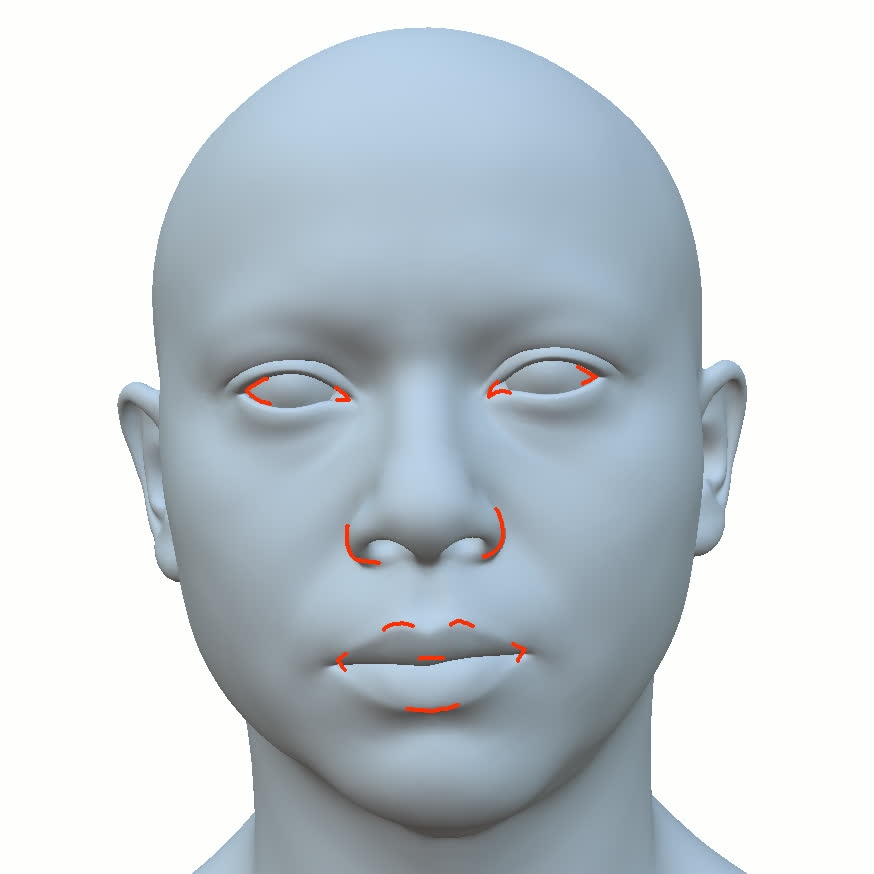
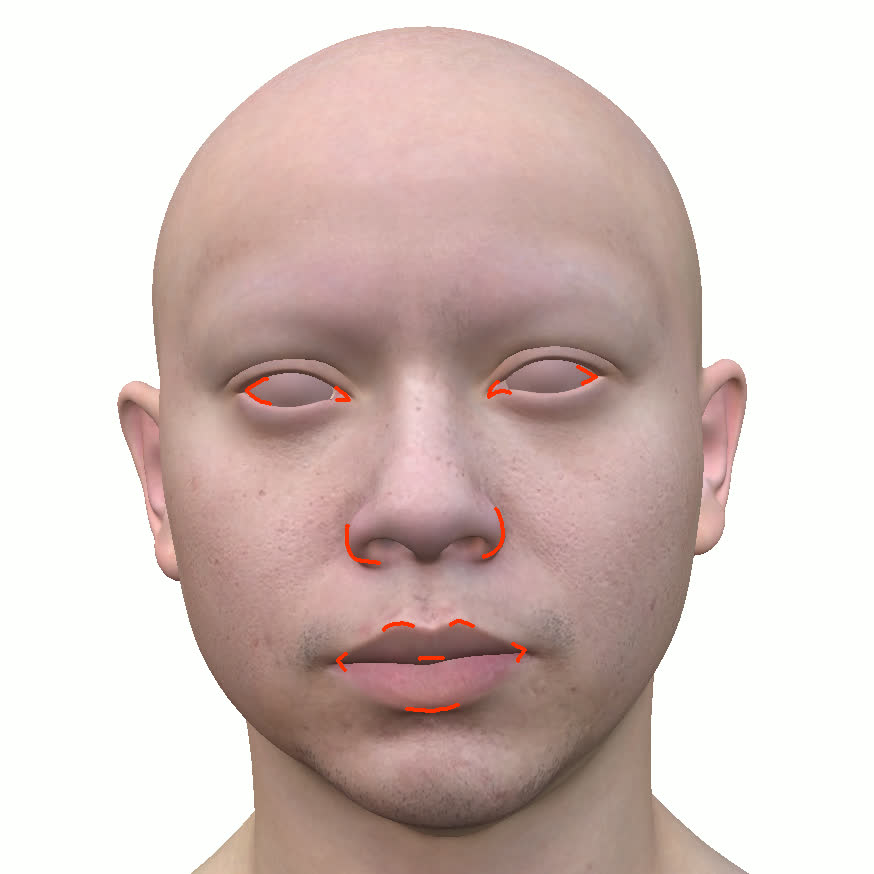
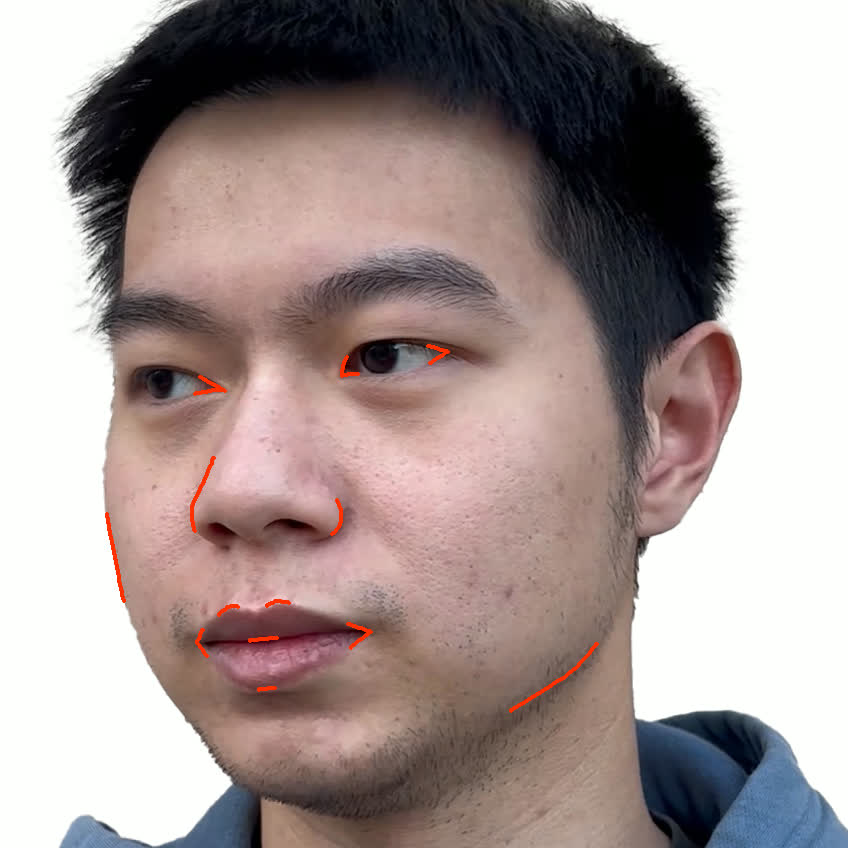
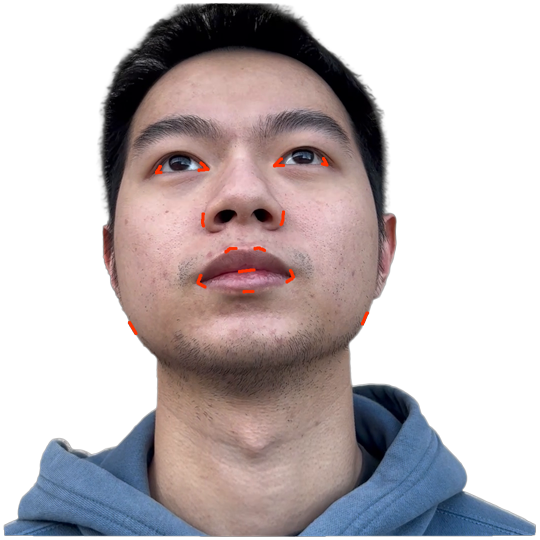
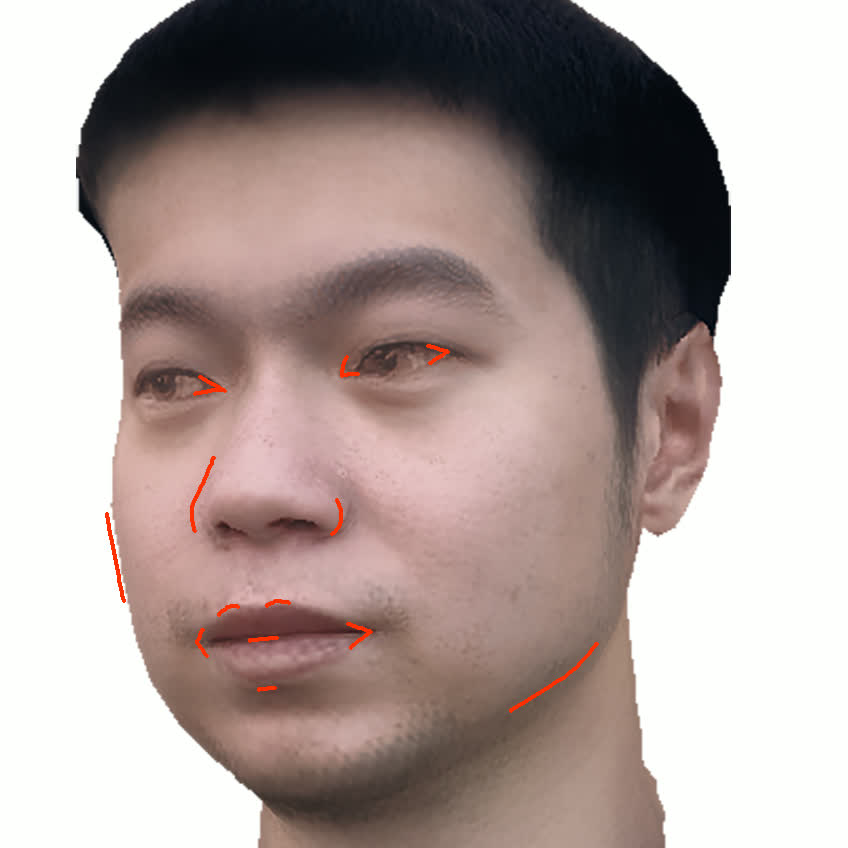
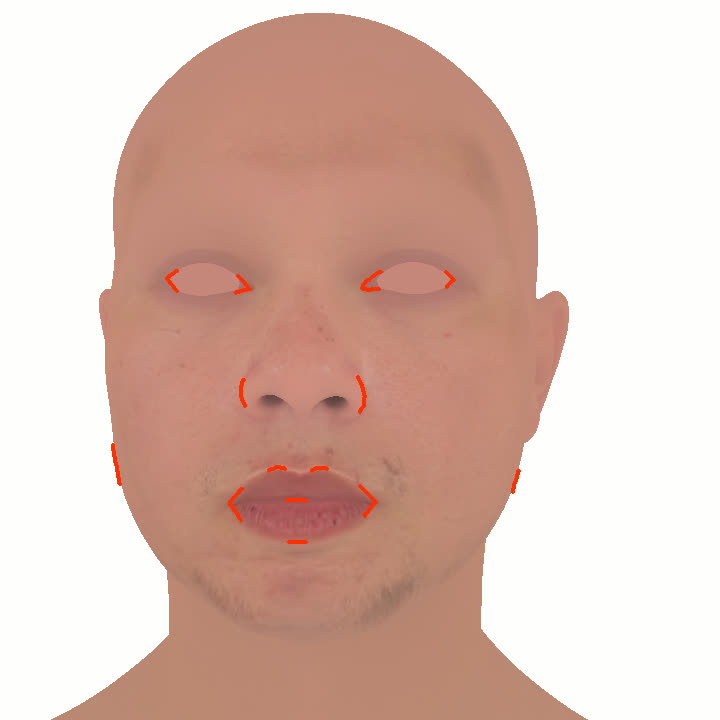
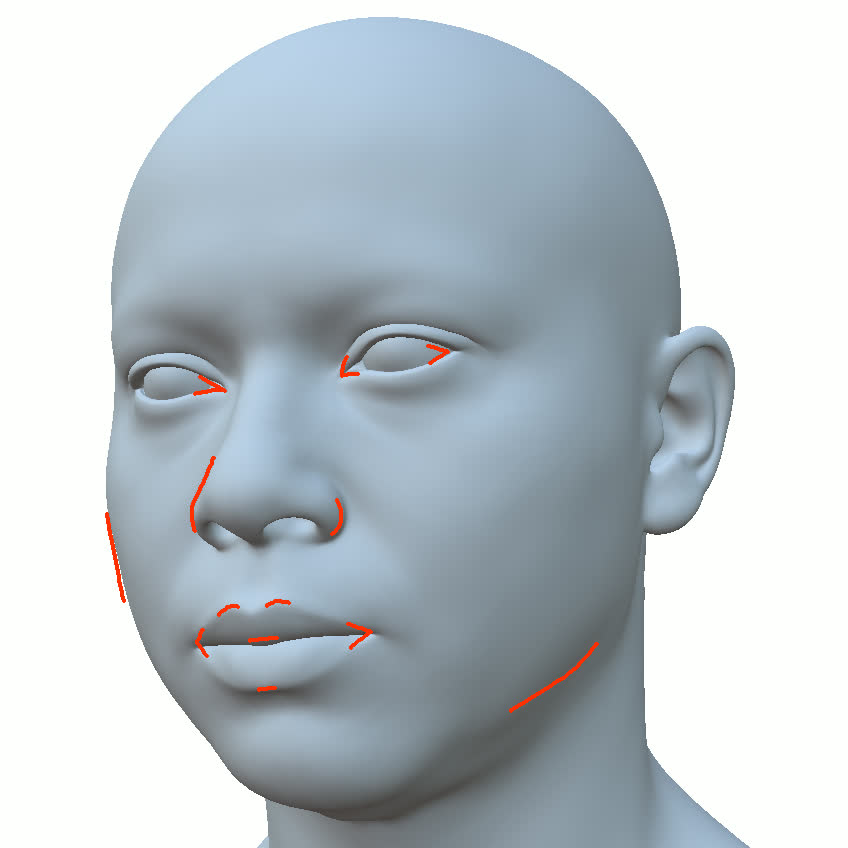
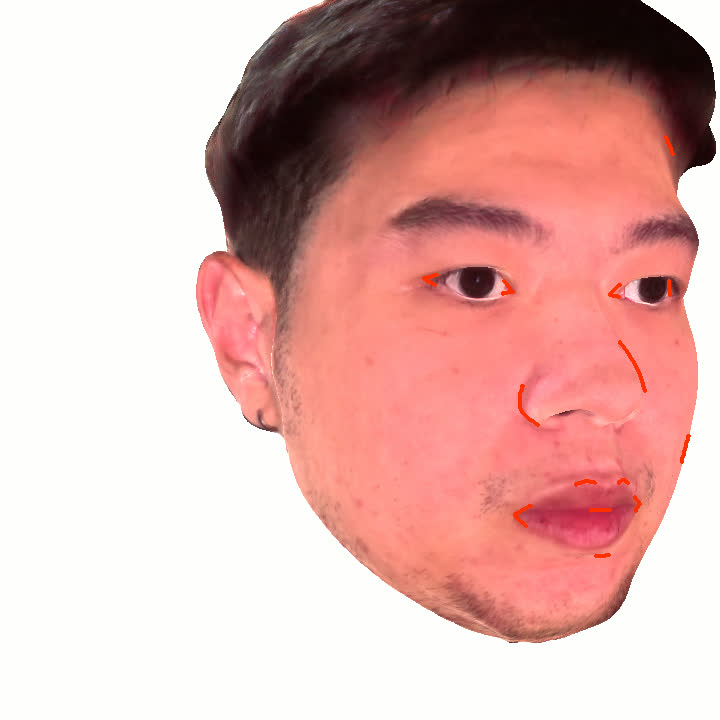
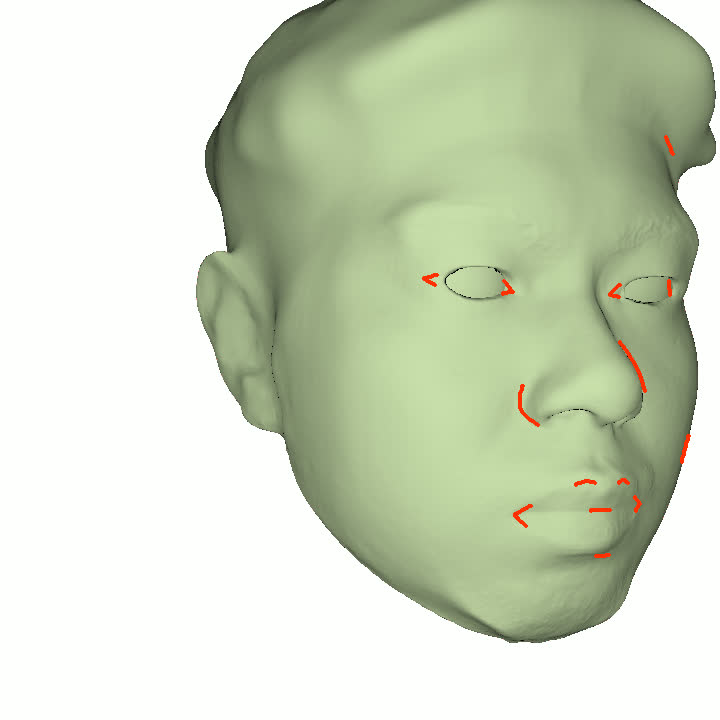
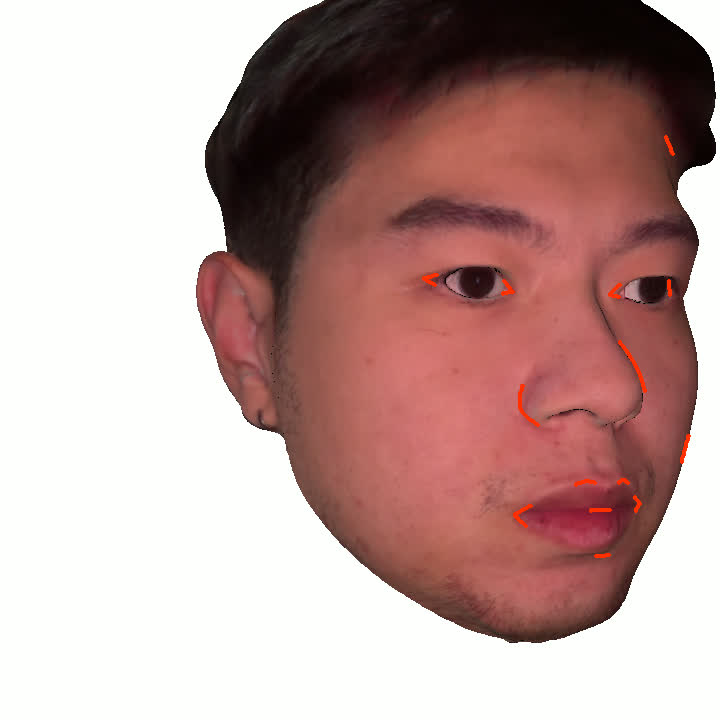
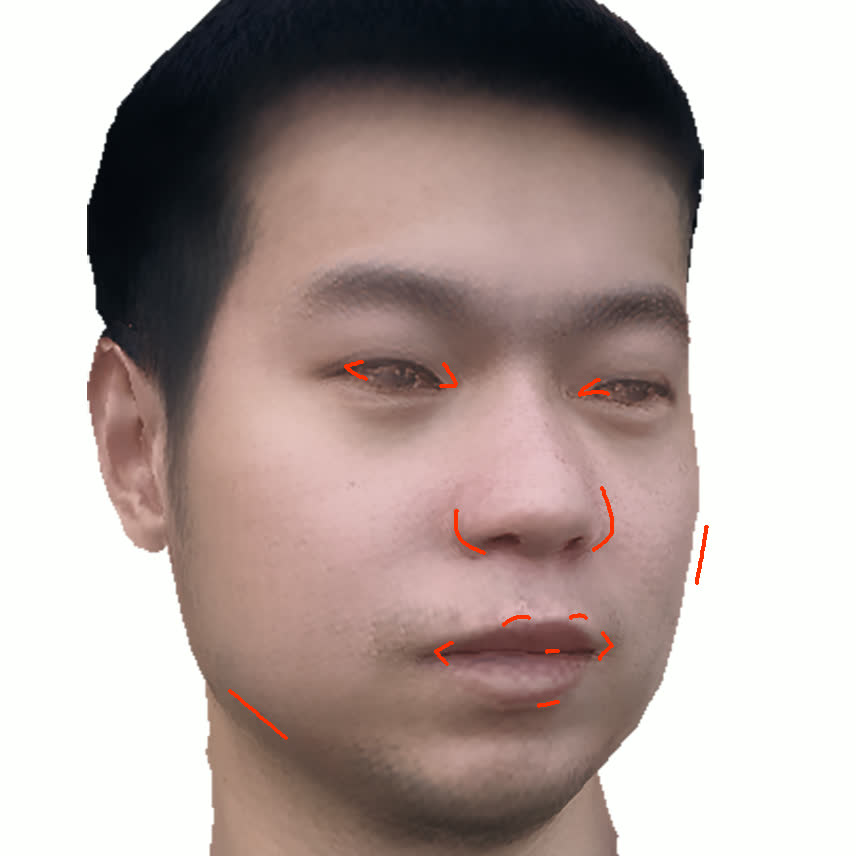
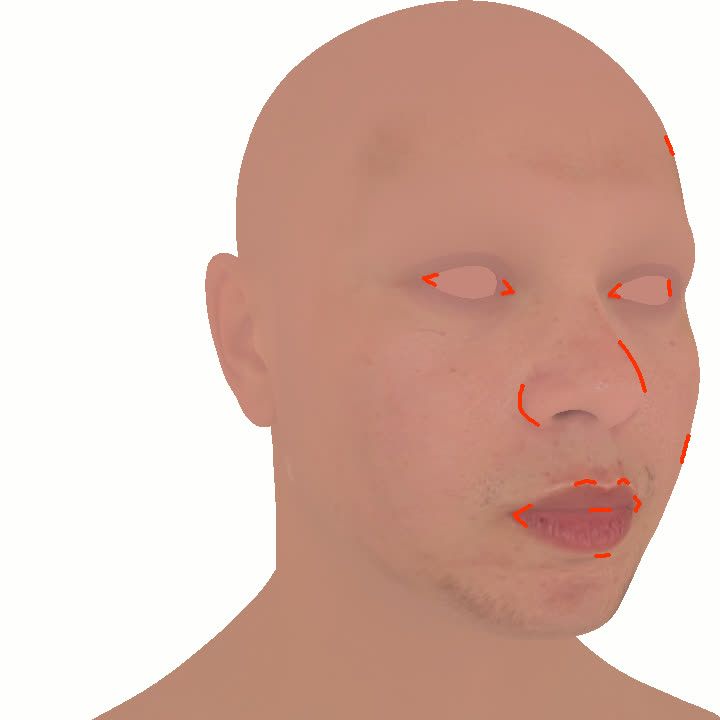
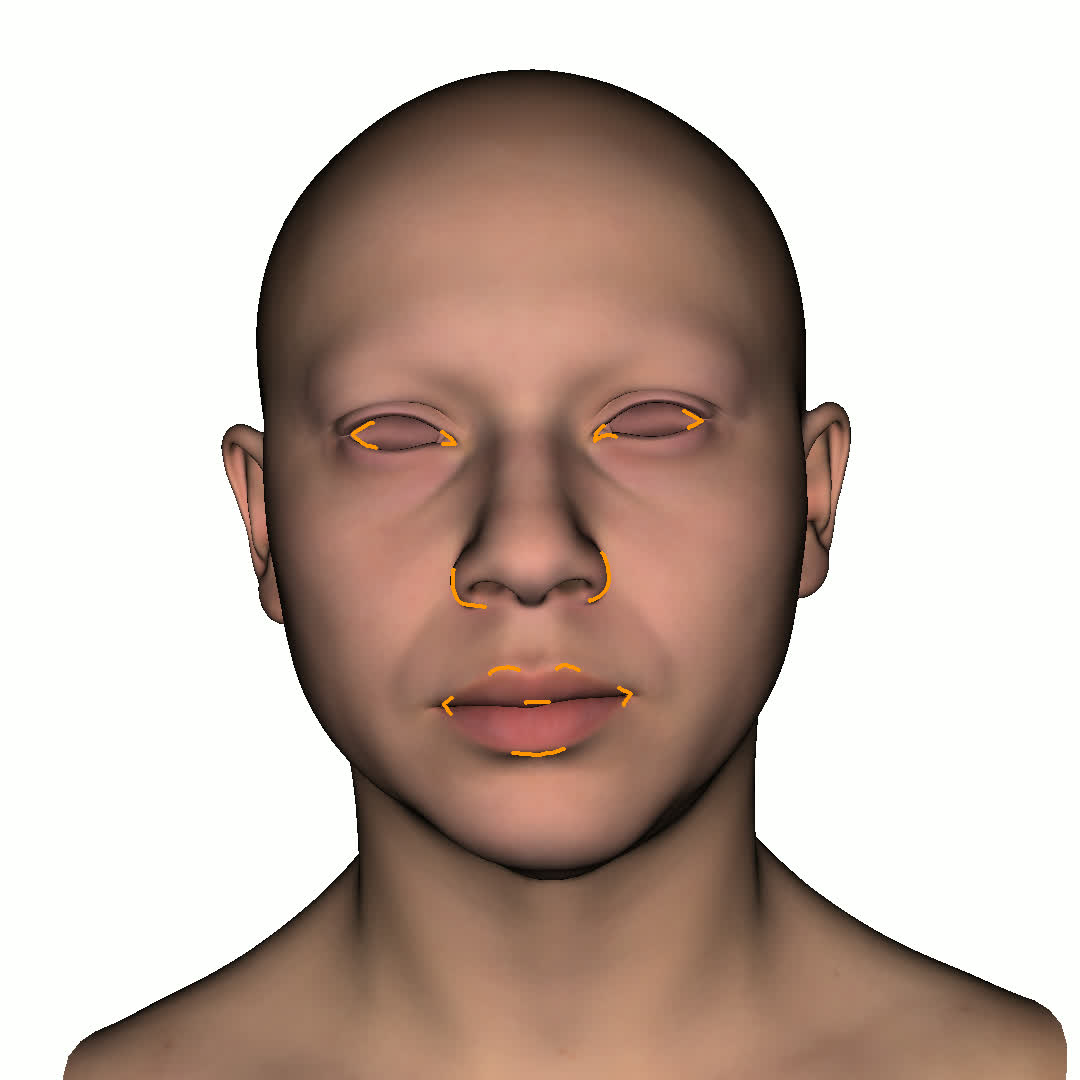
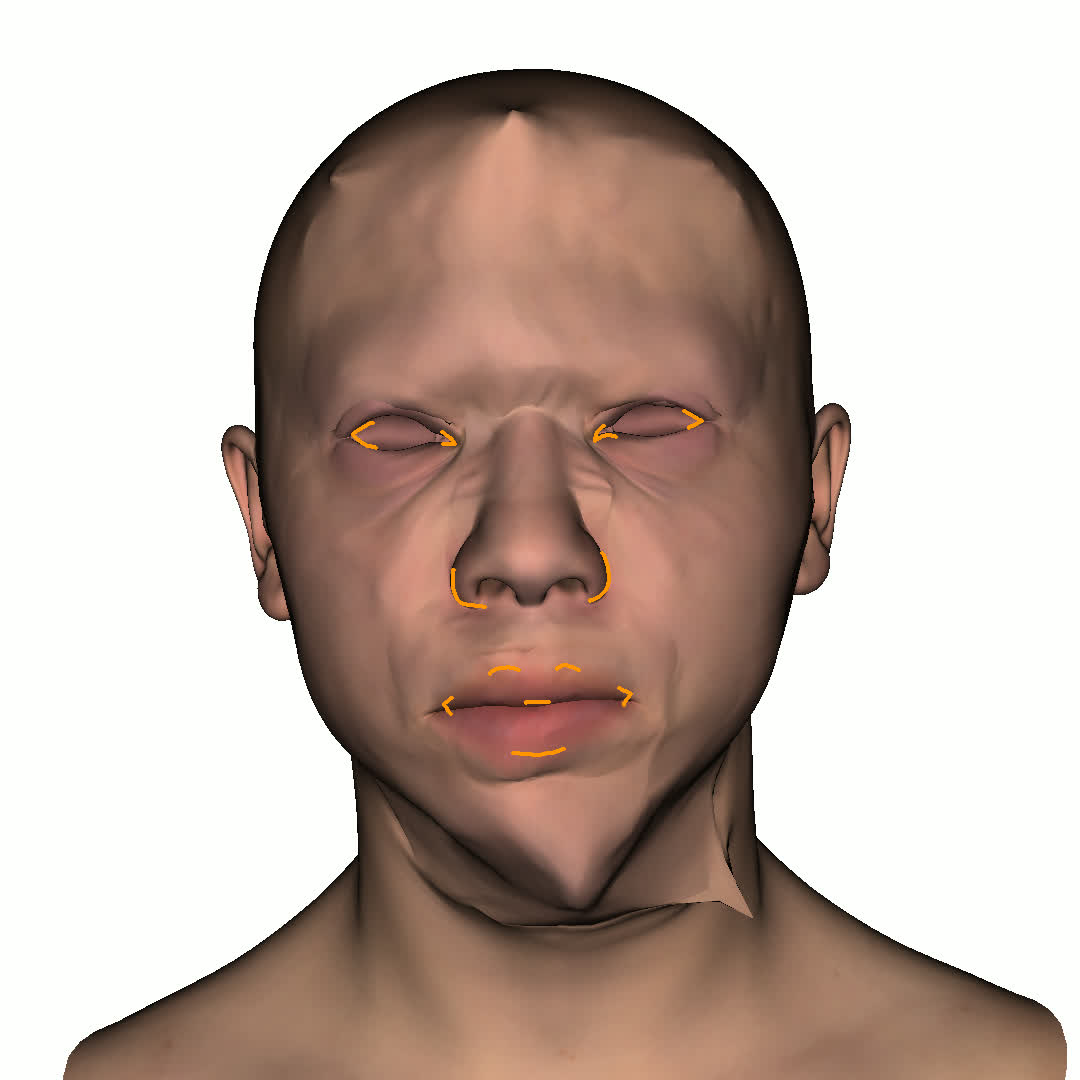
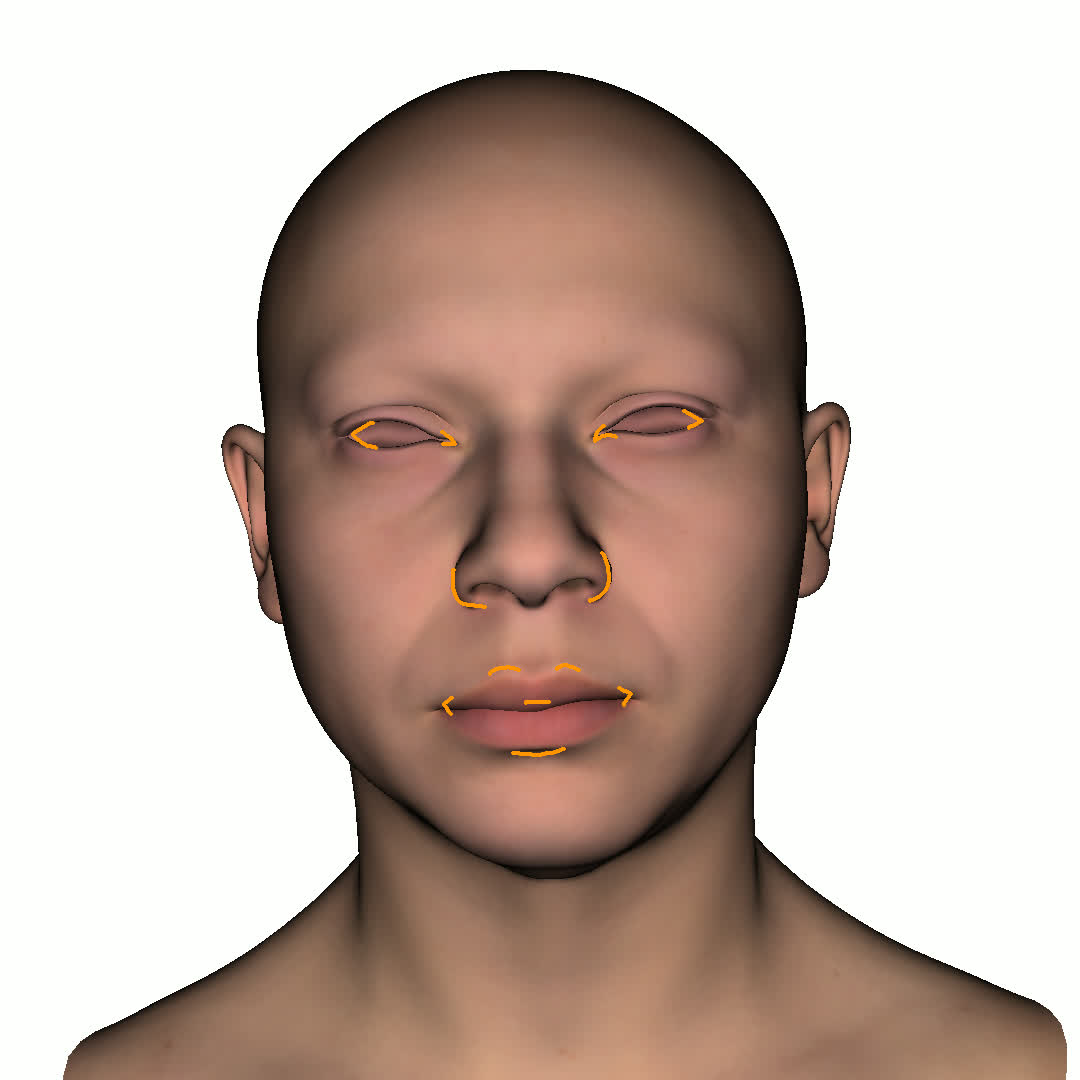
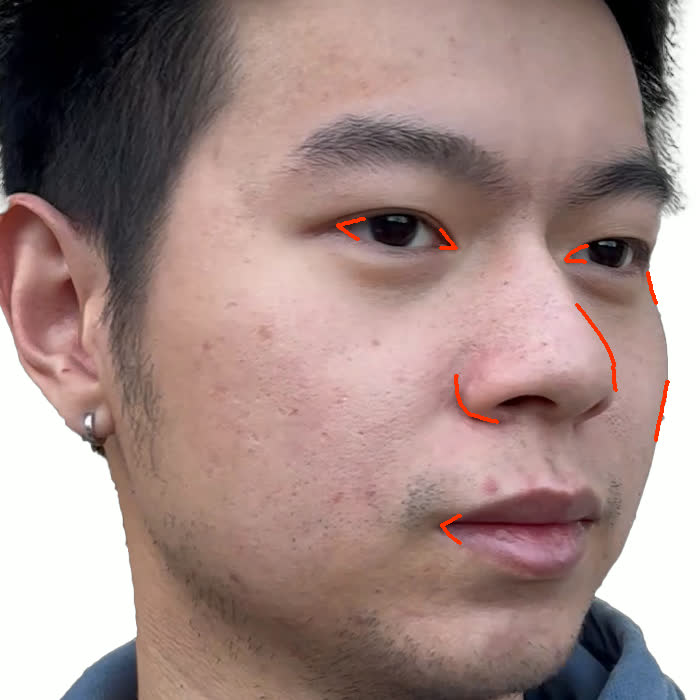
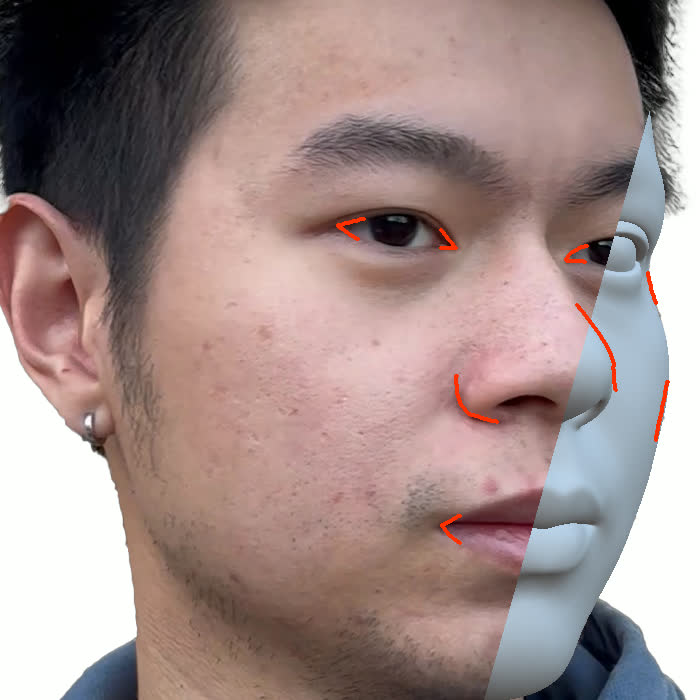
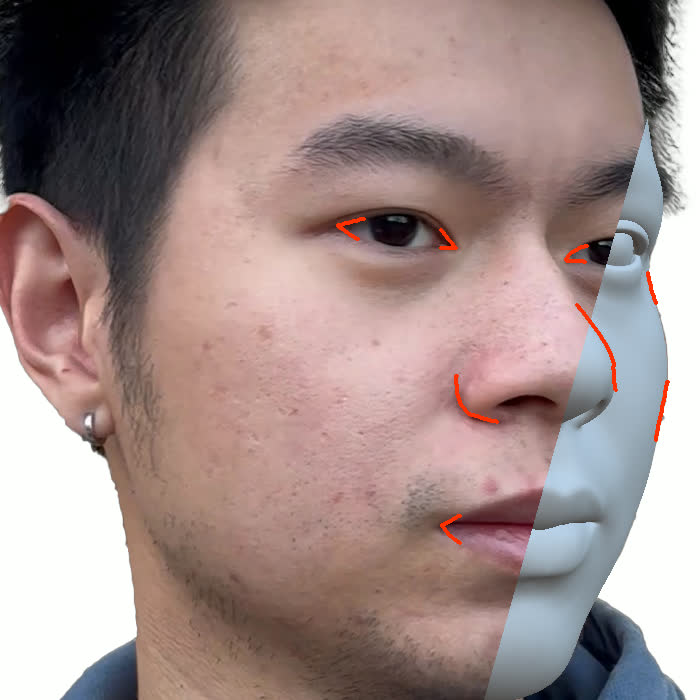
Figure 1. Using a small number of self-captured uncalibrated multi-view images, we use segmentation annotations along with size and shape constraints to force the Gaussians to move instead of deform. In addition, soft constraints are used to keep the Gaussians tightly coupled and close to the triangulated surface. After training, in a post process, the triangulated surface is deformed to better approximate the Gaussian reconstruction.
tures disentangled from lighting necessarily increases their immediate impact on real-time computer graphics applications. In this work, we address this by introducing a pipeline that transforms a Gaussian Splatting model trained with selfcaptured uncalibrated multi-view images into a triangulated surface with de-lit textures.
Our method offers significant advantages over traditional mesh-based geometry reconstruction, since it does not rely on the ability of advanced shading models to overcome the domain gap between synthetic and real images. Instead, neural rendering is used to close the domain gap, while constraints are used to tightly connect the neural rendering degrees of freedom to an explicit triangulated surface. The Gaussian Splatting model is modified to more tightly couple it to the triangulated surface in two ways: segmentation annotations along with size and shape constraints are used to force the Gaussians to move (instead of deform) in order to explain the data, and soft constraints are used to keep the Gaussians tightly coupled and close to the triangulated surface. After training, in a post process, the triangulated surface is deformed to better approximate the Gaussian reconstruction. See Fig. 1 and Fig. 2.
In order to obtain a de-lit texture with albedo disentangled from normal and lighting, without the need of a light-stage, we regularize this underconstrained problem by utilizing a PCA representation of a mesh-based facial texture derived from the Metahuman dataset [33]. We optimize the PCA coefficients to reconstruct albedo as faithfully as possible, while minimizing reliance on a Relightable Gaussian Splatting model that is used to capture residual differences between a target image and a rendering of the textured mesh.
This content is AI-processed based on open access ArXiv data.