Title: Explainable Preference Learning: a Decision Tree-based Surrogate Model for Preferential Bayesian Optimization
ArXiv ID: 2512.14263
Date: 2025-12-16
Authors: Nick Leenders, Thomas Quadt, Boris Cule, Roy Lindelauf, Herman Monsuur, Joost van Oijen, Mark Voskuijl
📝 Abstract
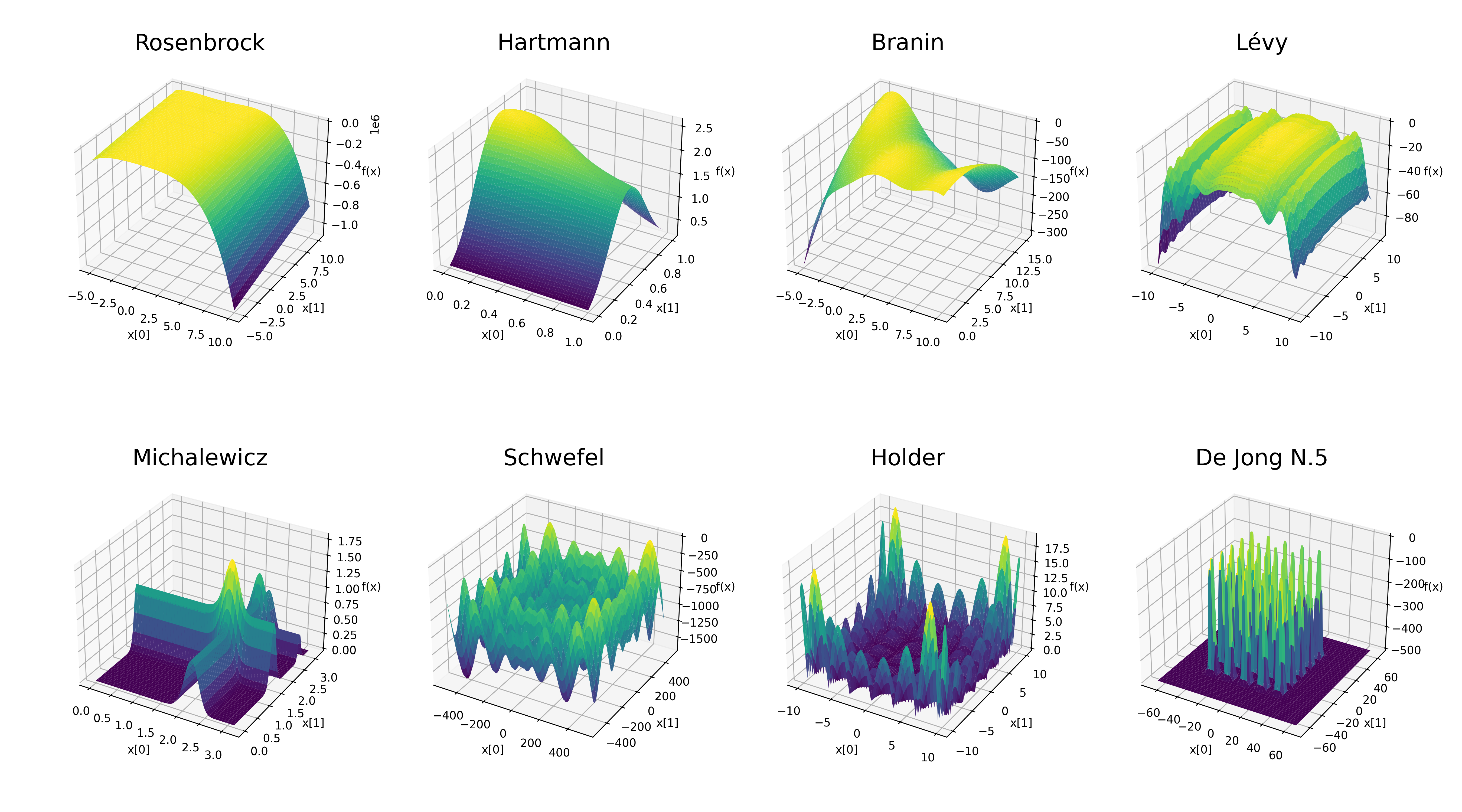
Current Preferential Bayesian Optimization methods rely on Gaussian Processes (GPs) as surrogate models. These models are hard to interpret, struggle with handling categorical data, and are computationally complex, limiting their real-world usability. In this paper, we introduce an inherently interpretable decision tree-based surrogate model capable of handling both categorical and continuous data, and scalable to large datasets. Extensive numerical experiments on eight increasingly spiky optimization functions show that our model outperforms GP-based alternatives on spiky functions and has only marginally lower performance for non-spiky functions. Moreover, we apply our model to the real-world Sushi dataset and show its ability to learn an individual's sushi preferences. Finally, we show some initial work on using historical preference data to speed up the optimization process for new unseen users.
💡 Deep Analysis
📄 Full Content
Preferential Bayesian Optimization (PBO) is a sampleefficient approach for finding the maximum of an unknown function using only pairwise comparisons (PCs) (González et al., 2017). This setting occurs in decision-making tasks, where a decision-maker's (DM's) preferences are modeled via a latent utility function. To find the DM's most preferred solution, one needs to find the maximum of this utility function. This function cannot be accessed directly as it is difficult for a DM to assign absolute numerical ratings to instances (Zintgraf et al., 2018). For example, why rate the taste of a slice of cake as 7? Why not 8? On the other hand, expressing preferences through pairwise comparisons (e.g., preferring chocolate cake over carrot cake) is cognitively much easier (Larichev, 1992;Greco et al., 2008).
PBO’s optimization loop, as shown in Figure 1, constructs a probabilistic surrogate model of the utility function, based on this probabilistic estimate an acquisition function identifies the most promising next PC to evaluate, performs the evaluation, and reconstructs the surrogate model based on the newly added data. First proposed by Chu & Ghahramani (2005), Gaussian Processes (GPs) have become the standard surrogate model. These models form a probabilistic estimate of the utility function via a kernel function measuring the similarity between points. Over the years, researchers have developed new acquisition functions (e.g., González et al. (2017); Fauvel & Chalk (2021); Astudillo et al. (2023)) and new methods to infer the intractable posterior distribution to train GPs on PC data(e.g., Nielsen et al. (2015); Siivola et al. (2021); Benavoli et al. (2021); Takeno et al. (2023)).
To the best of our knowledge, alternative surrogate models, however, have not yet been explored.
Addressing this is important because GPs have several practical limitations. First, GPs become difficult to interpret unless the kernel function is explicitly constrained to be additive over the input dimensions (Plate, 1999). Without such constraints, GPs behave as black box models, making it hard for DMs to understand why certain solutions are preferred, a critical issue in many real-world applications. Second, GPs struggle with handling qualitative data, especially when a qualitative factor contains many categories (Lin et al., 2024). Discrete data namely introduces discontinuities in the utility function, as the function values will now only change at discrete points. The most commonly used Radial Basis Function kernel and Matérn 2.5 kernels encode inherent smoothness assumptions (infinitely differentiable and twice differentiable, respectively) (Rasmussen & Williams, 2005) and are therefore incapable of modeling these discontinuities. Note that even without discrete data, the utility function can exhibit discontinuities (Gilboa et al., 2020).
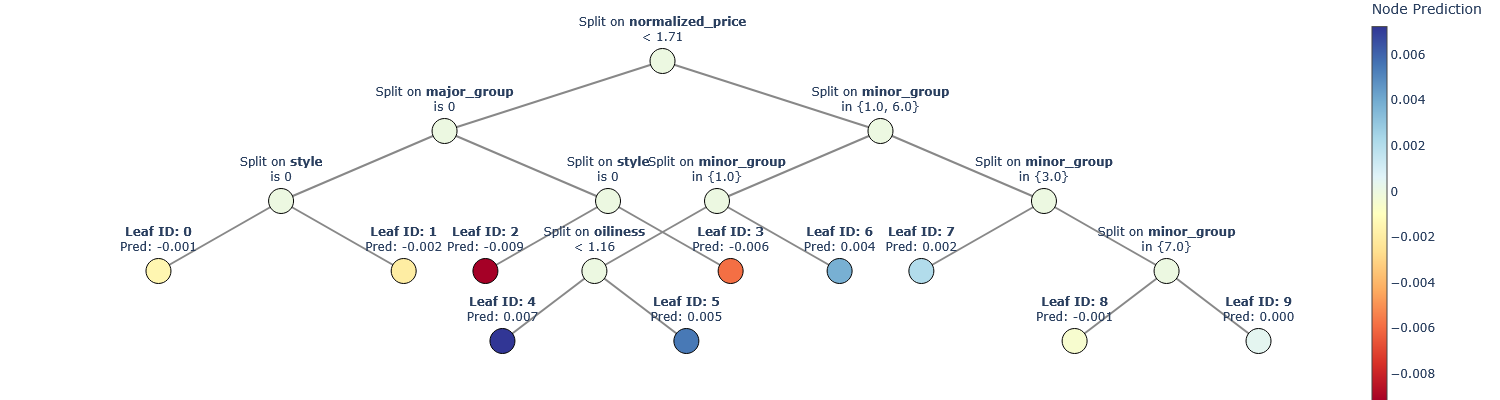
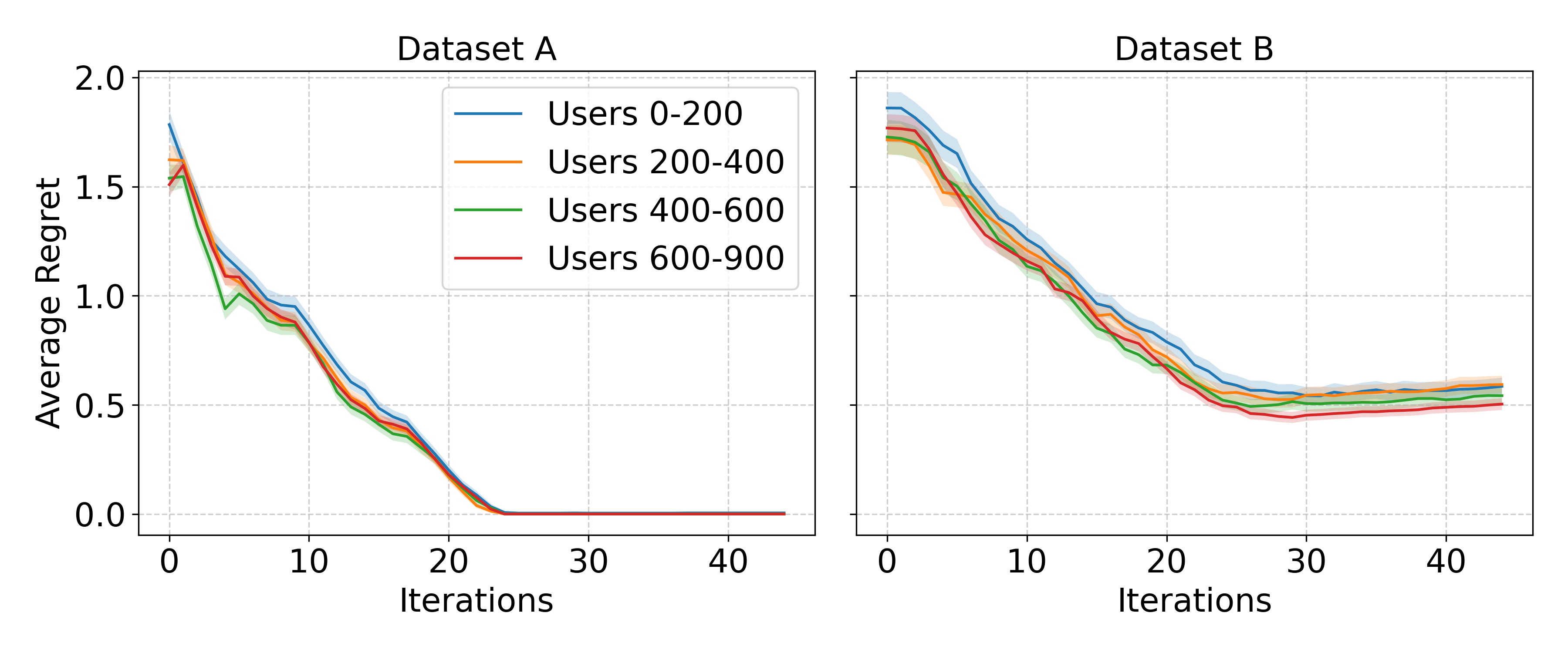
Instead of a GP-based surrogate model, we propose to use a tree-based surrogate model, as Decision Trees (DTs) are inherently interpretable, able to capture discontinuities, and well suited for categorical data. To use a DT as a surrogate model for PBO, it needs to provide a probabilistic estimate of the utility function and be learned solely from PC data. Additionally, to retain a high degree of interpretability, a single decision tree with probabilistic leaves is preferred over a completely probabilistic tree. Following these requirements, we thus propose a novel method of learning DTs with probabilistic leaves on PC data. We compare our model to two state-of-the-art GP-based models on eight increasingly spiky benchmark optimization functions and the results show that our model performs slightly worse on non-spiky optimization function but outperforms GP-based models on spiky functions. Moreover, our model scales much better on dataset size, making PBO possible on large datasets. A case study on the existing mixed-type Sushi dataset shows not only the high degree of interpretability of our proposed tree-based surrogate model as well as its capability of handling both qualitative and quantitative data out-of-the-box. Finally, we show some initial work on using historic preference data to speed up the learning process for new unseen decision-makers.
In PBO, a DM’s preferences are modeled by a latent utility function f : X → R, where X = X cont × X cat , with X cont ⊆ R dc , and
where each C i is a finite set of category labels. In particular, f measures the degree of preference of a solution x, where if x is preferred to x ′ , f (x) > f (x ′ ). The DM’s most preferred solution x M P S can then be found by solving the global optimization problem x M P S = arg max x∈X f (x).
The main premise in PBO is that f is not observed directly. Instead, f is observed via PCs (x, x ′ ) ∈ X × X from which we observe preference relations x ≻ x ′ indicating that x is preferred to x ′ . The goal is to find x M P S in as few PCs as possible.