Rethinking Leveraging Pre-Trained Multi-Layer Representations for Speaker Verification
Reading time: 5 minute
...
📝 Original Info
Title: Rethinking Leveraging Pre-Trained Multi-Layer Representations for Speaker Verification
ArXiv ID: 2512.22148
Date: 2025-12-15
Authors: Jin Sob Kim, Hyun Joon Park, Wooseok Shin, Sung Won Han
📝 Abstract
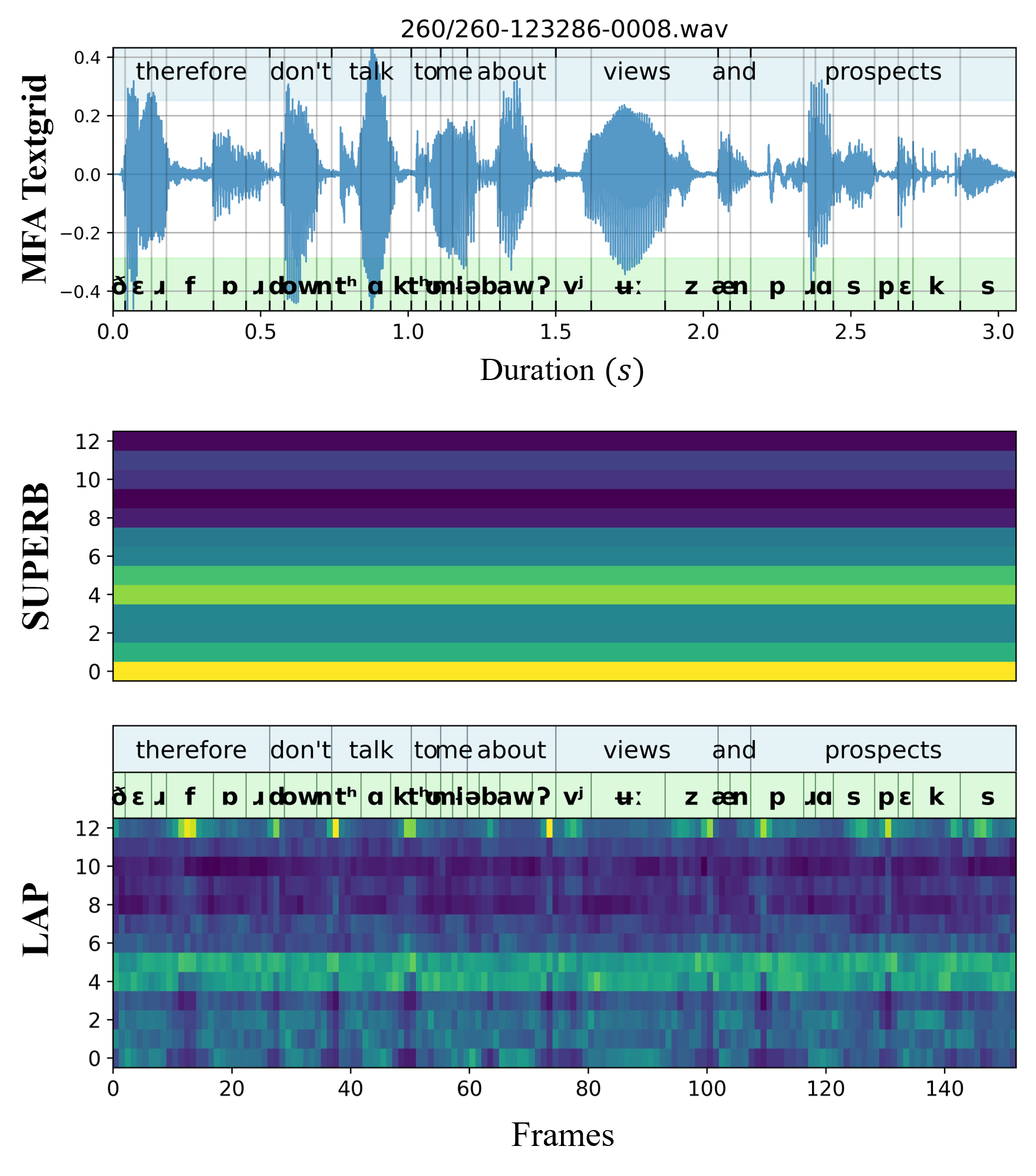
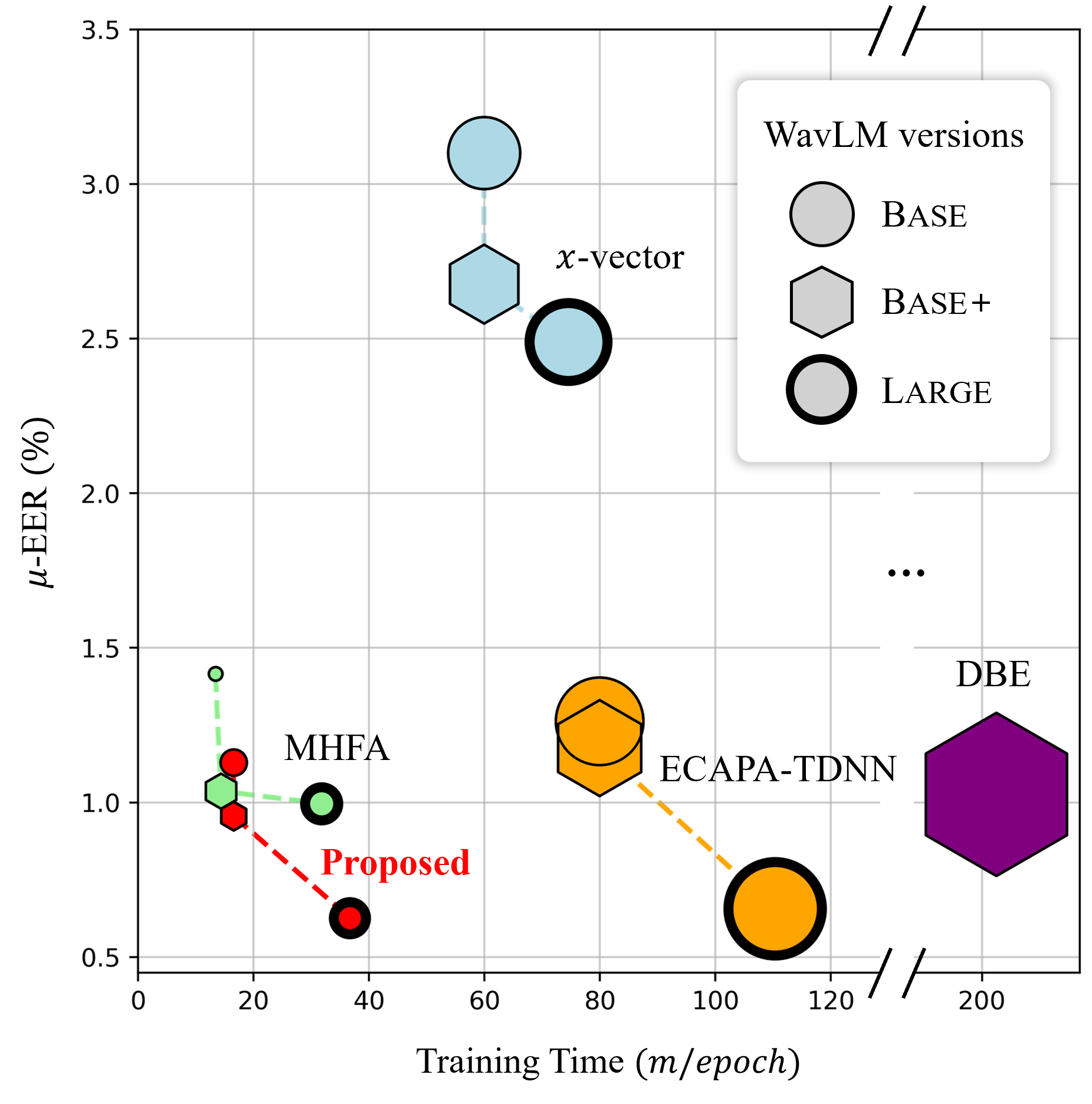
Recent speaker verification studies have achieved notable success by leveraging layer-wise output from pre-trained Transformer models. However, few have explored the advancements in aggregating these multi-level features beyond the static weighted average. We present Layer Attentive Pooling (LAP), a novel strategy for aggregating inter-layer representations from pre-trained speech models for speaker verification. LAP assesses the significance of each layer from multiple perspectives time-dynamically, and employs max pooling instead of averaging. Additionally, we propose a lightweight backend speaker model comprising LAP and Attentive Statistical Temporal Pooling (ASTP) to extract speaker embeddings from pre-trained model output. Experiments on the VoxCeleb benchmark reveal that our compact architecture achieves state-of-the-art performance while greatly reducing the training time. We further analyzed LAP design and its dynamic weighting mechanism for capturing speaker characteristics.
💡 Deep Analysis
📄 Full Content
Rethinking Leveraging Pre-Trained Multi-Layer Representations
for Speaker Verification
Jin Sob Kim, Hyun Joon Park, Wooseok Shin, Sung Won Han∗
School of Industrial and Management Engineering, Korea University, Republic of Korea
{jinsob,winddori2002,wsshin95,swhan}@korea.ac.kr
Abstract
Recent speaker verification studies have achieved notable suc-
cess by leveraging layer-wise output from pre-trained Trans-
former models.
However, few have explored the advance-
ments in aggregating these multi-level features beyond the static
weighted average. We present Layer Attentive Pooling (LAP),
a novel strategy for aggregating inter-layer representations from
pre-trained speech models for speaker verification. LAP as-
sesses the significance of each layer from multiple perspectives
time-dynamically, and employs max pooling instead of aver-
aging. Additionally, we propose a lightweight backend speaker
model comprising LAP and Attentive Statistical Temporal Pool-
ing (ASTP) to extract speaker embeddings from pre-trained
model output. Experiments on the VoxCeleb benchmark reveal
that our compact architecture achieves state-of-the-art perfor-
mance while greatly reducing the training time. We further an-
alyzed LAP design and its dynamic weighting mechanism for
capturing speaker characteristics.1
Index Terms: speaker recognition, speaker verification, speech
pre-trained model, fine-tuning efficiency, multi-level features
1. Introduction
Speaker Verification (SV) aims to authenticate an individual’s
identity based on their unique vocal characteristics.
In re-
cent years, unveiling large labeled datasets [1, 2] and ad-
vancements in deep-learning technologies have led to remark-
able improvements in this field.
Considerable efforts have
been dedicated to developing sophisticated model architectures
[3, 4, 5, 6, 7, 8, 9, 10] and training objectives [11, 12, 13] to
extract distinct speaker representations from acoustic features.
Meanwhile, the pre-training paradigm with Transformer
models [14, 15, 16, 17] has achieved significant success in
speech processing. Attained through speech predictive [18] or
denoising [16, 17] modeling, such models offer powerful fea-
tures for downstream tasks; boosting performance while also
leading to faster training convergence.
Various approaches have been explored to utilize pre-
trained representations in SV. For instance, [19] and [20] fine-
tuned wav2vec 2.0 [15] to extract speaker embeddings directly.
To obtain the speaker vector, the former averaged the output of
the last layer, while the latter inserted a constant cls token into
the input sequence of the Transformer encoder. [21] applied
a time-delay neural network (TDNN)-based backend architec-
ture to transform the pre-trained model output into speaker
embedding.
Previous studies [17, 22] have proposed utiliz-
ing layer-wise outputs from pre-trained models with a power-
ful backend speaker extractor, ECAPA-TDNN [9]. To achieve
1https://github.com/sadPororo/LAP
*Corresponding author
state-of-the-art verification performance, these methods em-
ployed a weighted sum of multiple hidden states as input to the
speaker model, as introduced in the SUPERB benchmark [23].
These two cases inspired subsequent SV studies to adopt similar
strategies to leverage pre-trained models [24, 25]. Emphasiz-
ing the efficiency of the fine-tuning, [24] designed an attention-
based backend module that is lightweight and convolution-free.
Dual-branch ECAPA-TDNN [25] was proposed with a multi-
level fusion strategy that combines outputs from a pre-trained
model and hand-crafted features.
On the other hand, both [24] and [25] discussed the under-
utilization of high-level representations, as shown in [17, 22],
and attempted to exploit features from all levels. They sepa-
rately applied a weighted sum on multiple branches, either of
key-value flow or of dividing low-high-level layers. However,
we fundamentally question the SUPERB strategy for incorpo-
rating layer-wise features to address this issue. Given the static
weights for each layer, Softmax-based aggregation favors low
layers, potentially constraining the exploitation of high-level
speech attributes [15, 16] such as phonemes and syllables.
In this paper, we discuss the time-dynamic utilization of
multi-layer representations and the effective integration of all
layers, from pre-trained models for SV. The main contributions
of this study can be summarized as follows:
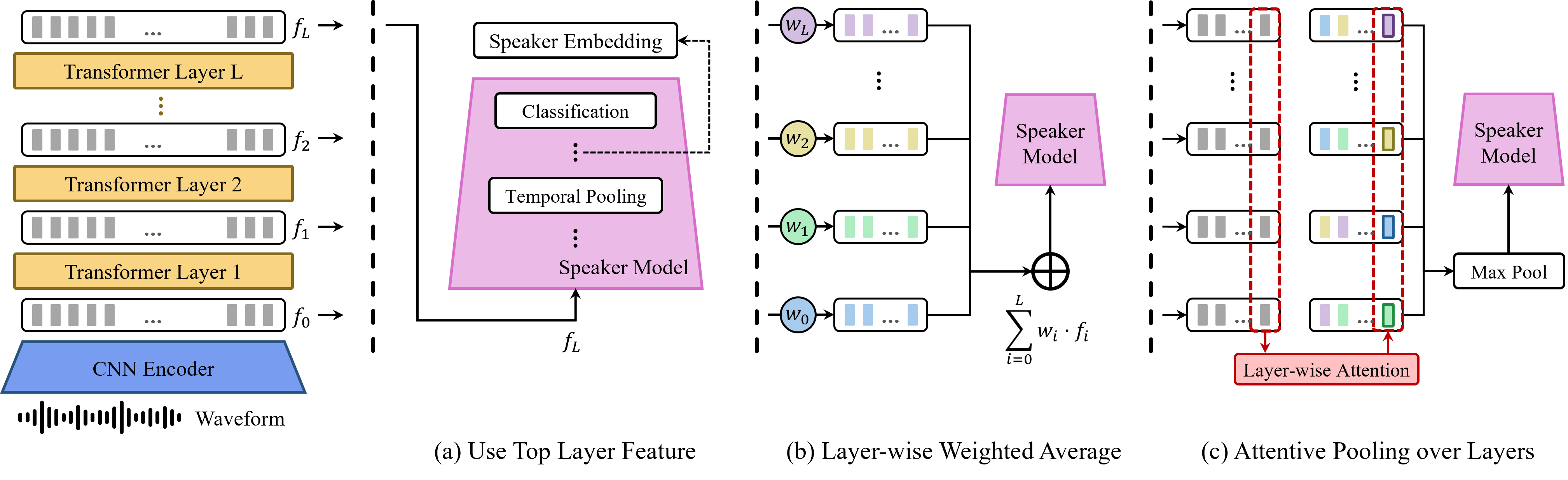
• We propose Layer-wise Attentive Pooling (LAP), which ap-
plies time-dynamic weighting to multi-layer representations
from pre-trained models.
LAP effectively leverages these
representations by addressing the issue of neglecting certain
layers in the conventional weighted summation approach.
• Aiming for efficient fine-tuning, we introduce a lightweight
backend speaker extractor comprising two attentive pooling
modules: LAP for layer-wise aggregation and attentive statis-
tics pooling [9] to capture temporal dynamics.
• The efficacy of the pro