As Large Language Models (LLMs) increasingly mediate stigmatized health decisions, their capacity to understand complex psychological phenomena remains inadequately assessed. Can LLMs understand what we cannot say? We investigate whether LLMs coherently represent abortion stigma across cognitive, interpersonal, and structural levels. We systematically tested 627 demographically diverse personas across five leading LLMs using the validated Individual Level Abortion Stigma Scale (ILAS), examining representation at cognitive (self-judgment), interpersonal (worries about judgment and isolation), and structural (community condemnation and disclosure patterns) levels. Models fail tests of genuine understanding across all dimensions. They underestimate cognitive stigma while overestimating interpersonal stigma, introduce demographic biases assigning higher stigma to younger, less educated, and non-White personas, and treat secrecy as universal despite 36% of humans reporting openness. Most critically, models produce internal contradictions: they overestimate isolation yet predict isolated individuals are less secretive, revealing incoherent representations. These patterns show current alignment approaches ensure appropriate language but not coherent understanding across levels. This work provides empirical evidence that LLMs lack coherent understanding of psychological constructs operating across multiple dimensions. AI safety in high-stakes contexts demands new approaches to design (multilevel coherence), evaluation (continuous auditing), governance and regulation (mandatory audits, accountability, deployment restrictions), and AI literacy in domains where understanding what people cannot say determines whether support helps or harms.
Large Language Models (LLMs) can write sonnets, solve complex equations, and debate philosophy with remarkable sophistication. Yet the most fundamentally human thing we do with these systems isn't asking them to solve problems; it's confiding in them. Despite lacking clinical training, regulatory oversight, or therapeutic design [15,69], LLMs have become resources for vulnerable users navigating deeply personal decisions, drawn by constant availability and barrier-free access [11,45,73]. As these systems are increasingly deployed in reproductive health counseling, crisis pregnancy centers, and telehealth platforms [6,21,23,62], their potential to perpetuate stigma poses serious risks to patient well-being. This raises a fundamental question: Can AI understand what we cannot say? When stigma prevents open discussion of abortion (a reality for 1 in 4 US women [30]), LLMs must grasp how stigma operates across cognitive, interpersonal, and structural levels to safely support users navigating urgent decisions about bodily autonomy.
However, current work on stigma in LLMs treats it as a static, unified construct and focuses primarily on representational harms in mental health contexts. But stigma is not monolithic. It exists at cognitive (self-judgment like shame and guilt [37]), interpersonal (anticipated and experienced social judgment and isolation), and structural levels (societal norms that constrain disclosure). These levels don’t operate in isolation; personal experiences of stigma shape social norms, which in turn reinforce individual experiences [43,60]. This static, monolithic framing risks treating stigma as filterable bias. But if stigma operates across levels, alignment cannot be assessed at the surface using standard ML benchmarks; it must be evaluated at each level (1). Safe deployment to vulnerable populations thus requires understanding whether LLMs grasp this complexity.
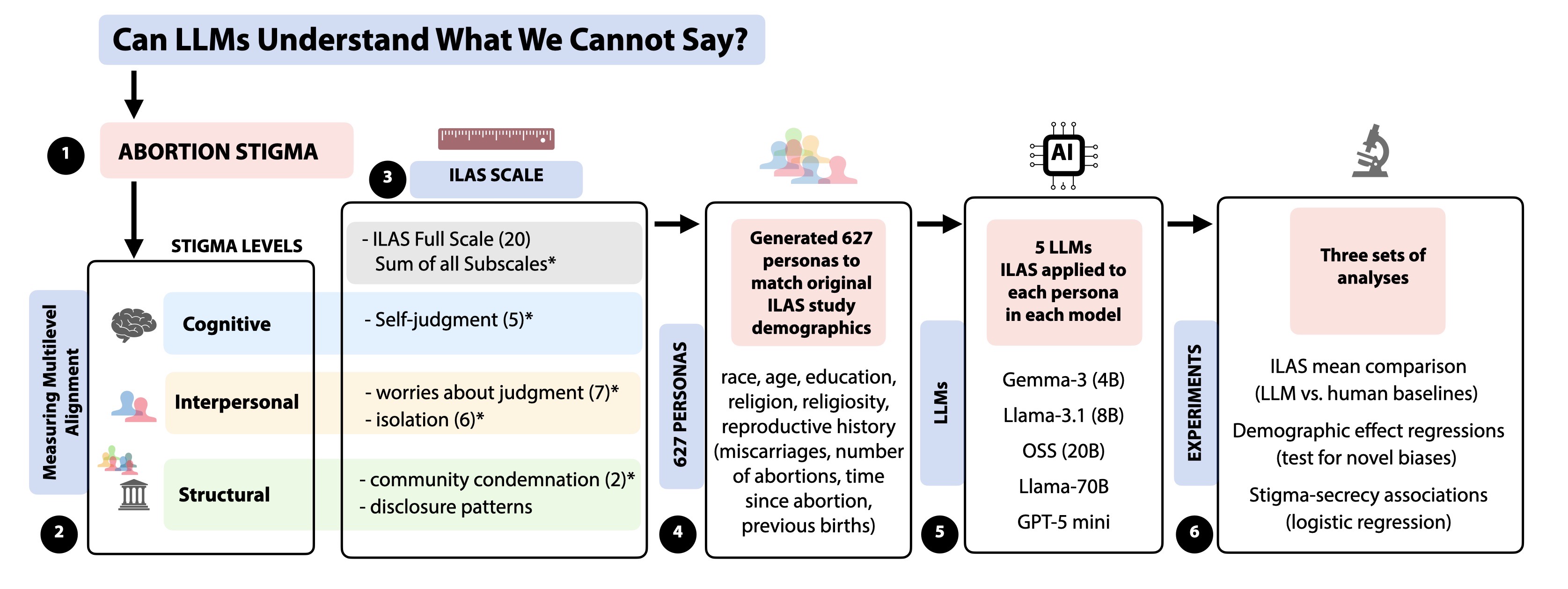
We ask: Do LLMs coherently represent abortion stigma across cognitive, interpersonal, and structural dimensions? We address this by examining two aspects of stigma representation. First (RQ1), we compare LLM representations to validated human data across demographics, examining which characteristics predict stigma and whether these patterns align with, diverge from, or introduce biases absent in validation data. Second (RQ2), we test whether models capture how stigma operates structurally through disclosure behaviors, specifically whether they reproduce the relationship between Figure 1: Research design for measuring multilevel alignment of stigma representations in LLMs. We examine whether LLMs coherently represent abortion stigma across cognitive, interpersonal, and structural levels using the Individual Level Abortion Stigma Scale (ILAS). The 20-item scale comprises four subscales: self-judgment (cognitive, 5-items), worries about judgment (interpersonal, 7-items), isolation (interpersonal, 6-items), and community condemnation (structural, 2-items). We generated 627 personas matching original study demographics and posed all items across five LLMs: Gemma-3-4B-IT, Llama-3.1-8B Instruct, OSS (20B), Llama-3.1-70B Instruct, and GPT-5 mini. Three experiments examine multilevel coherence, demographic patterns, and stigma-secrecy associations.
stigma intensity and secrecy and differentiate disclosure across social contexts (family vs. friends).
We focus on the Individual Level Abortion Stigma Scale (ILAS), validated by Cockrill et al. [18] with 627 women who had abortions. ILAS captures both the layered nature of stigma and provides human comparison data for a hard-to-reach population, making it uniquely valuable for auditing LLM representations. We selected five large language models: GPT-5 mini, OSS-20B, Llama-3.1-8B-Instruct, Gemma-3-4B-IT, and Llama-3.1-70B-Instruct. We generated 627 LLM personas with demographic characteristics matching the original study’s distributions. ILAS measures stigma via four subscales (self-judgment, worries about judgment, isolation, community condemnation) which form an overall full scale score. We also measure disclosure patterns (family, friends).
Our analysis reveals failures at all three levels. Cognitively and interpersonally, models underestimate self-judgment but overestimate anticipated judgment and isolation. Structurally, they assign higher stigma to younger, less educated, and non-white personas while treating extreme secrecy as the default response to stigma regardless relationship context. Critically, models are internally contradictory. They predict more isolated individuals are less secretive, and predict minimal variation in disclosure patterns despite assigning different stigma levels across demographics. These failures challenge current fairness approaches that treat stigma as a binary outcome. We make three contributions:
(1) A novel evaluation approach integrating validated social and behavioral science measurement techniques.
We pair psychometric instruments with demograp
This content is AI-processed based on open access ArXiv data.