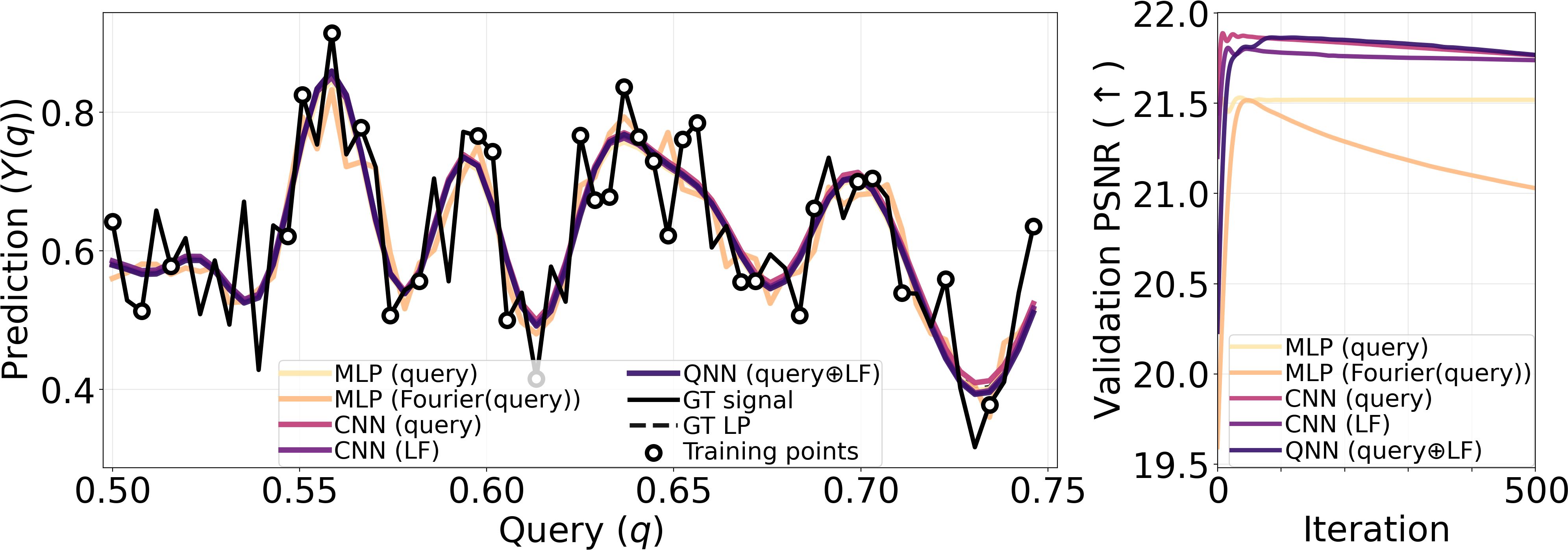
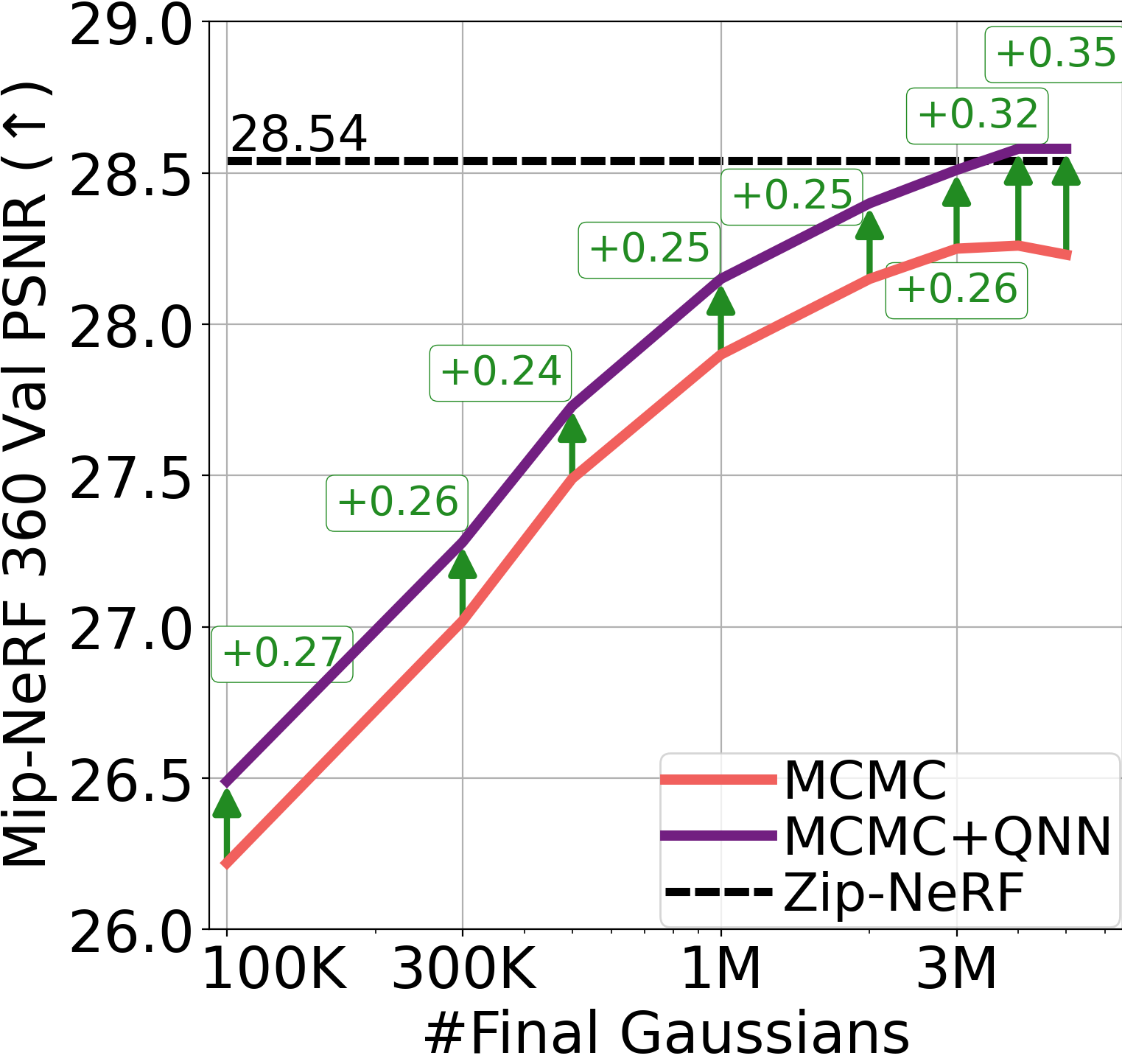
Accurately learning high-frequency signals is a challenge in computer vision and graphics, as neural networks often struggle with these signals due to spectral bias or optimization difficulties. While current techniques like Fourier encodings have made great strides in improving performance, there remains scope for improvement when presented with high-frequency information. This paper introduces Queried-Convolutions (Qonvolutions), a simple yet powerful modification using the neighborhood properties of convolution. Qonvolution convolves a low-frequency signal with queries (such as coordinates) to enhance the learning of intricate high-frequency signals. We empirically demonstrate that Qonvolutions enhance performance across a variety of high-frequency learning tasks crucial to both the computer vision and graphics communities, including 1D regression, 2D super-resolution, 2D image regression, and novel view synthesis (NVS). In particular, by combining Gaussian splatting with Qonvolutions for NVS, we showcase state-of-the-art performance on real-world complex scenes, even outperforming powerful radiance field models on image quality.
💡 Deep Analysis
📄 Full Content
QONVOLUTION:
TOWARDS
LEARNING
HIGH-
FREQUENCY SIGNALS WITH QUERIED CONVOLUTION
Abhinav Kumar1, Tristan Aumentado-Armstrong2∗, Lazar Valkov1∗, Gopal Sharma1,
Alex Levinshtein2, Radek Grzeszczuk1,2, Suren Kumar1
1Samsung Research America, AI Center – Mountain View, CA, USA
2Samsung Research, AI Center – Toronto, ON, Canada
{a.kumar4,tristan.a,lazar.valkov,gopal.sharma}@samsung.com
{alex.lev,radek.g,suren.kumar}@samsung.com
Project Page: https://abhi1kumar.github.io/qonvolution/
ABSTRACT
Accurately learning high-frequency signals is a challenge in computer vision and
graphics, as neural networks often struggle with these signals due to spectral
bias or optimization difficulties. While current techniques like Fourier encod-
ings have made great strides in improving performance, there remains scope for
improvement when presented with high-frequency information. This paper intro-
duces Queried-Convolutions (Qonvolutions), a simple yet powerful modification
using the neighborhood properties of convolution. Qonvolution convolves a low-
frequency signal with queries (such as coordinates) to enhance the learning of
intricate high-frequency signals. We empirically demonstrate that Qonvolutions
enhance performance across a variety of high-frequency learning tasks crucial to
both the computer vision and graphics communities, including 1D regression, 2D
super-resolution, 2D image regression, and novel view synthesis (NVS). In partic-
ular, by combining Gaussian splatting with Qonvolutions for NVS, we showcase
state-of-the-art performance on real-world complex scenes, even outperforming
powerful radiance field models on image quality.
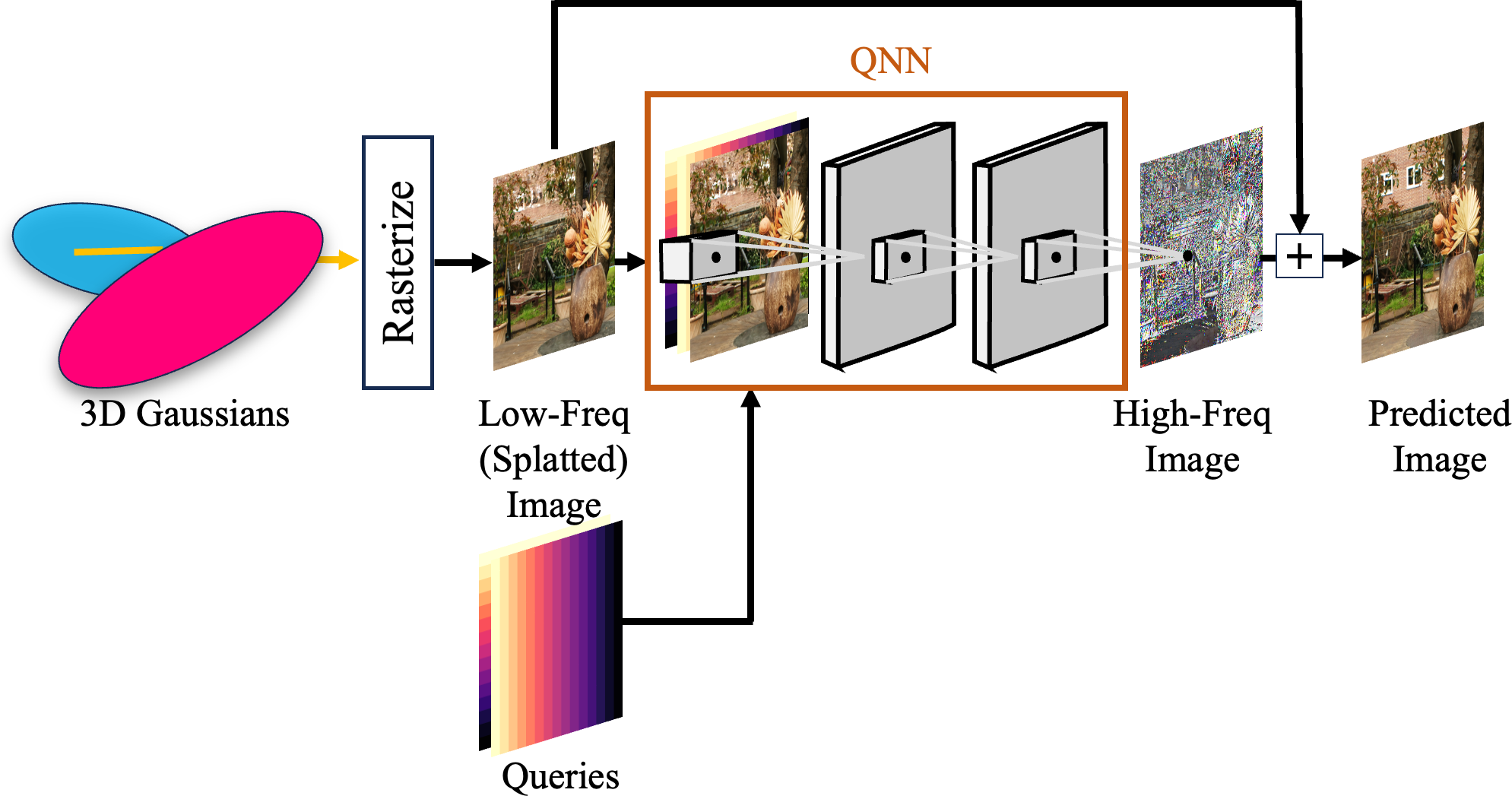
Figure 1: Learning high-frequency with Qonvolution. We provide an example on novel view synthesis of 3D
Gaussian Splatting (Kerbl et al., 2023) and adding QNN. Adding QNN faithfully reconstructs high-frequency
details in various regions and results in higher quality synthesis. We highlight the differences in inset figures.
1
INTRODUCTION
Neural networks are now fundamental to computer vision and graphics, for deciphering a wide
range of signals, from intricate 1D data like time series (Kazemi et al., 2019) and natural language
(Vaswani et al., 2017) to rich 2D images (Tancik et al., 2020), and immersive 3D scenes (Barron
et al., 2023). However, these networks often struggle to capture high-frequency details, a challenge
often attributed to spectral bias (Rahaman et al., 2019) or optimization difficulties (Tab. 10) due to
complicated landscapes (Li et al., 2018).
The challenge of capturing high-frequency details in neural networks has spurred a rich and diverse
body of research. A key strategy involves modifying positional encodings, using Fourier encod-
∗Equal Second Authors.
1
arXiv:2512.12898v1 [cs.CV] 15 Dec 2025
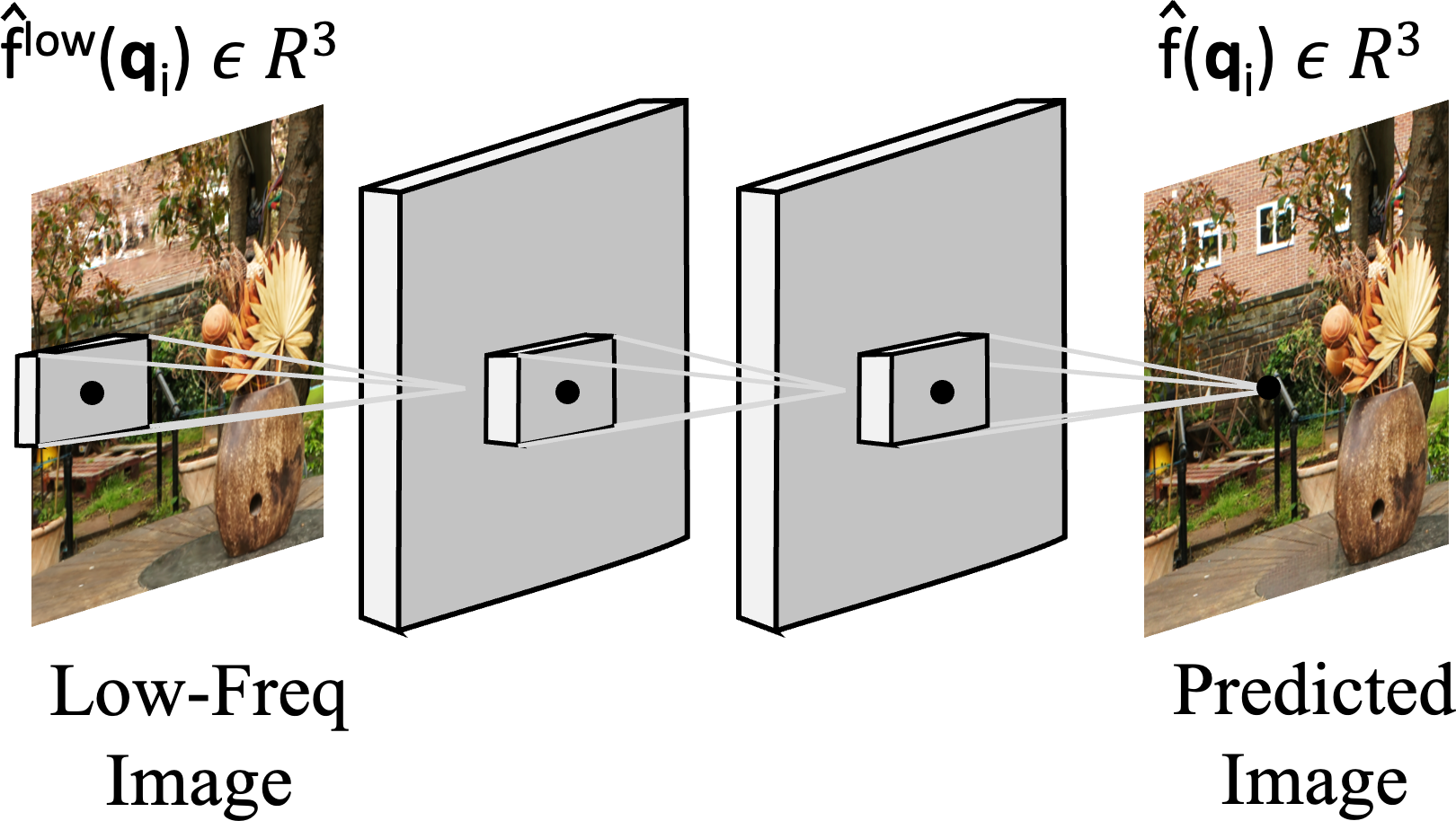
(a) MLP-based Neural Fields
(b) CNN
(c) QNN
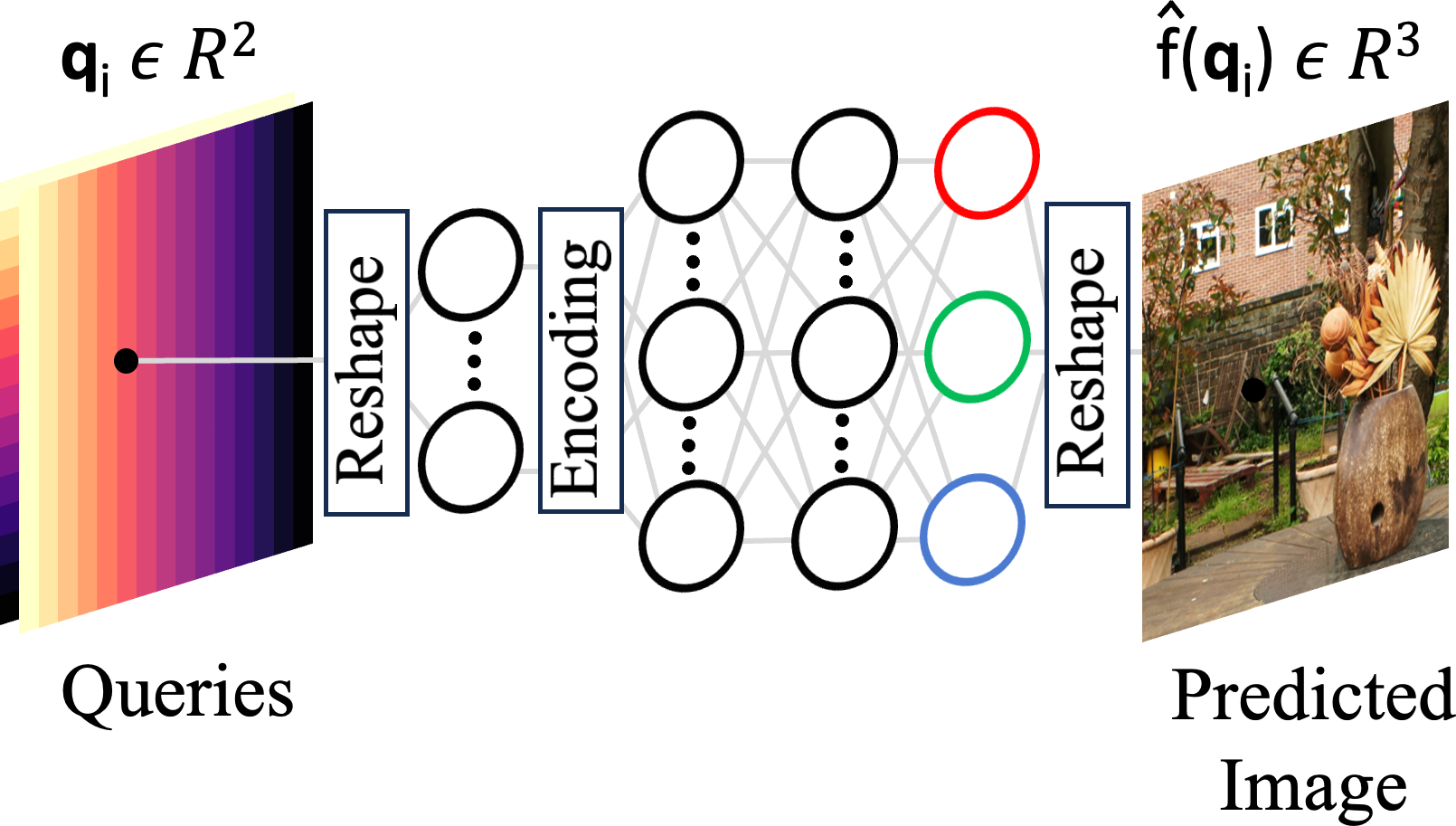
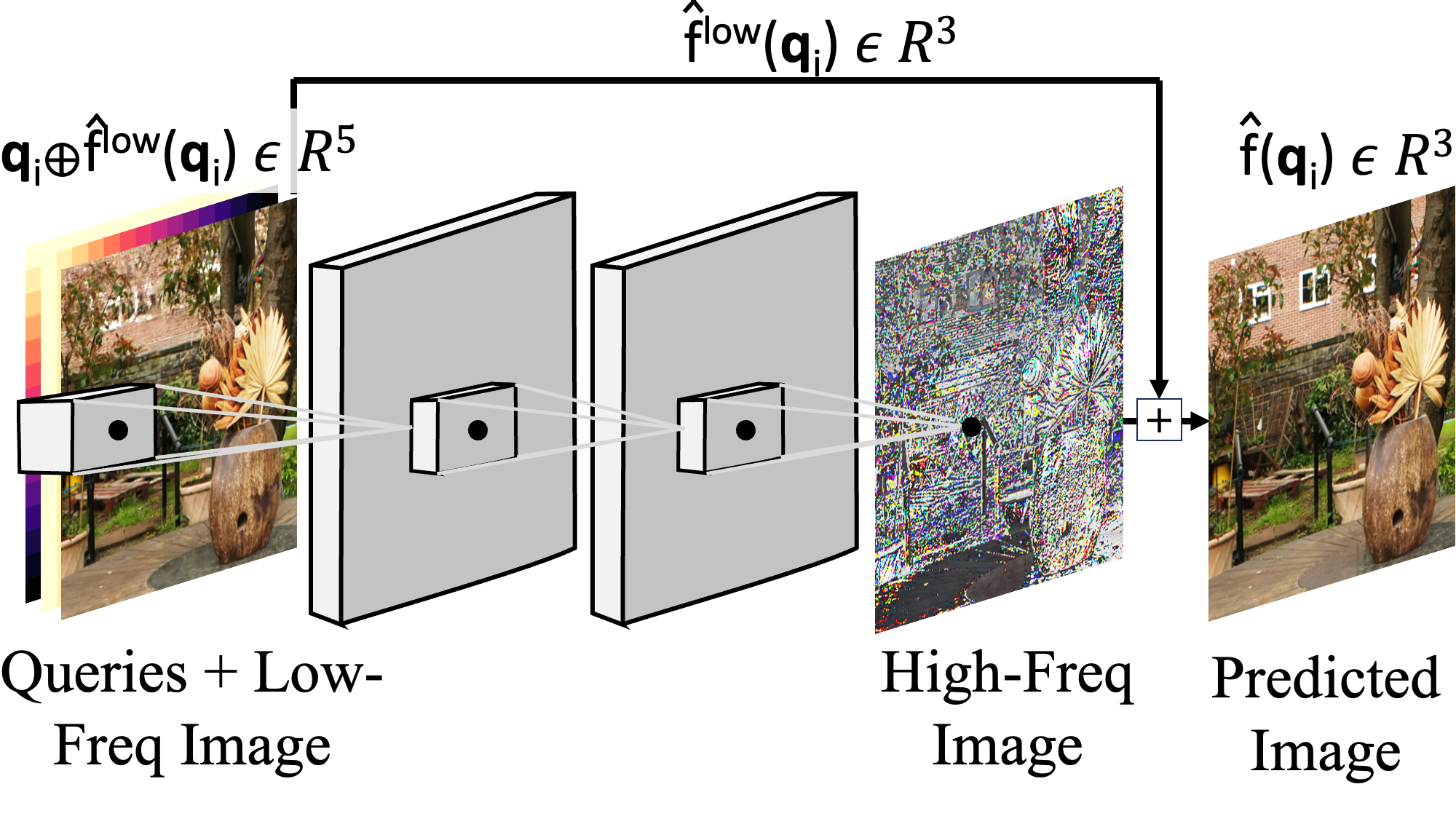
Figure 2: Overview of MLPs, CNNs and QNNs. MLPs take (encoded) queries γ(qi) and uses linear layers.
CNNs take the low-frequency signal bf low and uses convolutions. QNN concatenates the low-frequency signal
bf low to the (encoded) queries γ(qi) and uses convolutions. [Key: Freq = Frequency, ⊕= Concatenation]
ings (Tancik et al., 2020). Another approach focuses on altering activation functions, such as those
in SIREN (Sitzmann et al., 2020). Other methods aim to predict Fourier series coefficients (Lee
et al., 2021), use high-frequency weighted losses (Zhang et al., 2024) or tune weight initialization
(Saratchandran et al., 2024). While all these innovations improve performance, the spectrum of
frequencies effectively learned remains limited, highlighting a compelling need for further advance-
ments in high-frequency signal representation.
There are two classes of tasks that attempt to learn high-frequency signals. One stream, which in-
cludes the popular novel view synthesis (NVS) task, uses Multi-Layer Perceptrons (MLPs) (Fig. 2a)
to directly fit signals. However, MLPs lack the necessary inductive biases (Cohen & Welling, 2016;
LeCun et al., 1998) to capture the local neighborhood dependencies inherent in most 1D and 2D
signals. We conjecture that these local relationships are crucial for learning high-frequency infor-
mation effectively. By processing data points or pixels in isolation, existing MLP networks often
neglect these local connections, which limits their capacity to fully represent high-frequency signals.
On the other hand, if a low-frequency signal is given, the second class of problems, which includes,
e.g., 2D super-resolution (SR), convolves the low-frequency signal with a CNN (Fig. 2b), and thus,
uses neighborhood information. However, these approaches (Karras et al., 2018) often do not uti-
lize the information present in the input queries (e.g.: spatial coordinates) in predicting the output
high-frequency signal. As shown in previous work (Liu et al., 2018), architectures that are aware of
locality, such as CNNs, often fail at tasks that require even a simple transformations of coordinates.
Thus, the potential for