Title: Human-Inspired Learning for Large Language Models via Obvious Record and Maximum-Entropy Method Discovery
ArXiv ID: 2512.12608
Date: 2025-12-14
Authors: Hong Su
📝 Abstract
Large Language Models (LLMs) excel at extracting common patterns from large-scale corpora, yet they struggle with rare, low-resource, or previously unseen scenarios-such as niche hardware deployment issues or irregular IoT device behaviors-because such cases are sparsely represented in training data. Moreover, LLMs rely primarily on implicit parametric memory, which limits their ability to explicitly acquire, recall, and refine methods, causing them to behave predominantly as intuition-driven predictors rather than deliberate, method-oriented learners. Inspired by how humans learn from rare experiences, this paper proposes a human-inspired learning framework that integrates two complementary mechanisms. The first, Obvious Record, explicitly stores cause--result (or question--solution) relationships as symbolic memory, enabling persistent learning even from single or infrequent encounters. The second, Maximum-Entropy Method Discovery, prioritizes and preserves methods with high semantic dissimilarity, allowing the system to capture diverse and underrepresented strategies that are typically overlooked by next-token prediction. Verification on a benchmark of 60 semantically diverse question--solution pairs demonstrates that the proposed entropy-guided approach achieves stronger coverage of unseen questions and significantly greater internal diversity than a random baseline, confirming its effectiveness in discovering more generalizable and human-inspired methods.
💡 Deep Analysis
📄 Full Content
JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015
1
Human-Inspired Learning for Large Language
Models via Obvious Record and Maximum-Entropy
Method Discovery
Hong Su
Abstract—Large Language Models (LLMs) excel at extracting
common patterns from large-scale corpora, yet they struggle
with rare, low-resource, or previously unseen scenarios—such
as niche hardware deployment issues or irregular IoT device
behaviors—because such cases are sparsely represented in train-
ing data. Moreover, LLMs rely primarily on implicit parametric
memory, which limits their ability to explicitly acquire, recall,
and refine methods, causing them to behave predominantly
as intuition-driven predictors rather than deliberate, method-
oriented learners.
Inspired by how humans learn from rare experiences, this
paper proposes a human-inspired learning framework that in-
tegrates two complementary mechanisms. The first, Obvious
Record, explicitly stores cause–result (or question–solution) rela-
tionships as symbolic memory, enabling persistent learning even
from single or infrequent encounters. The second, Maximum-
Entropy Method Discovery, prioritizes and preserves methods with
high semantic dissimilarity, allowing the system to capture diverse
and underrepresented strategies that are typically overlooked by
next-token prediction.
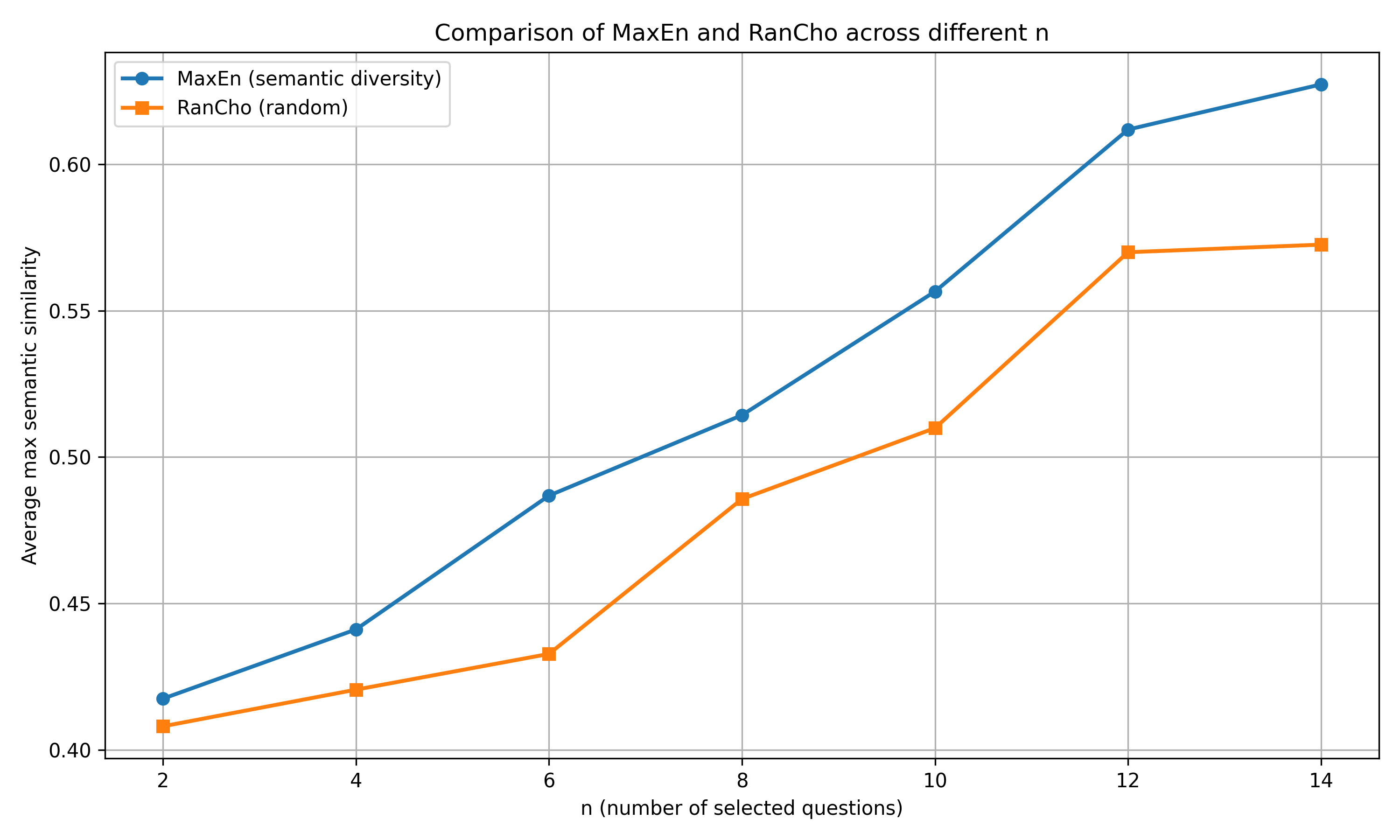
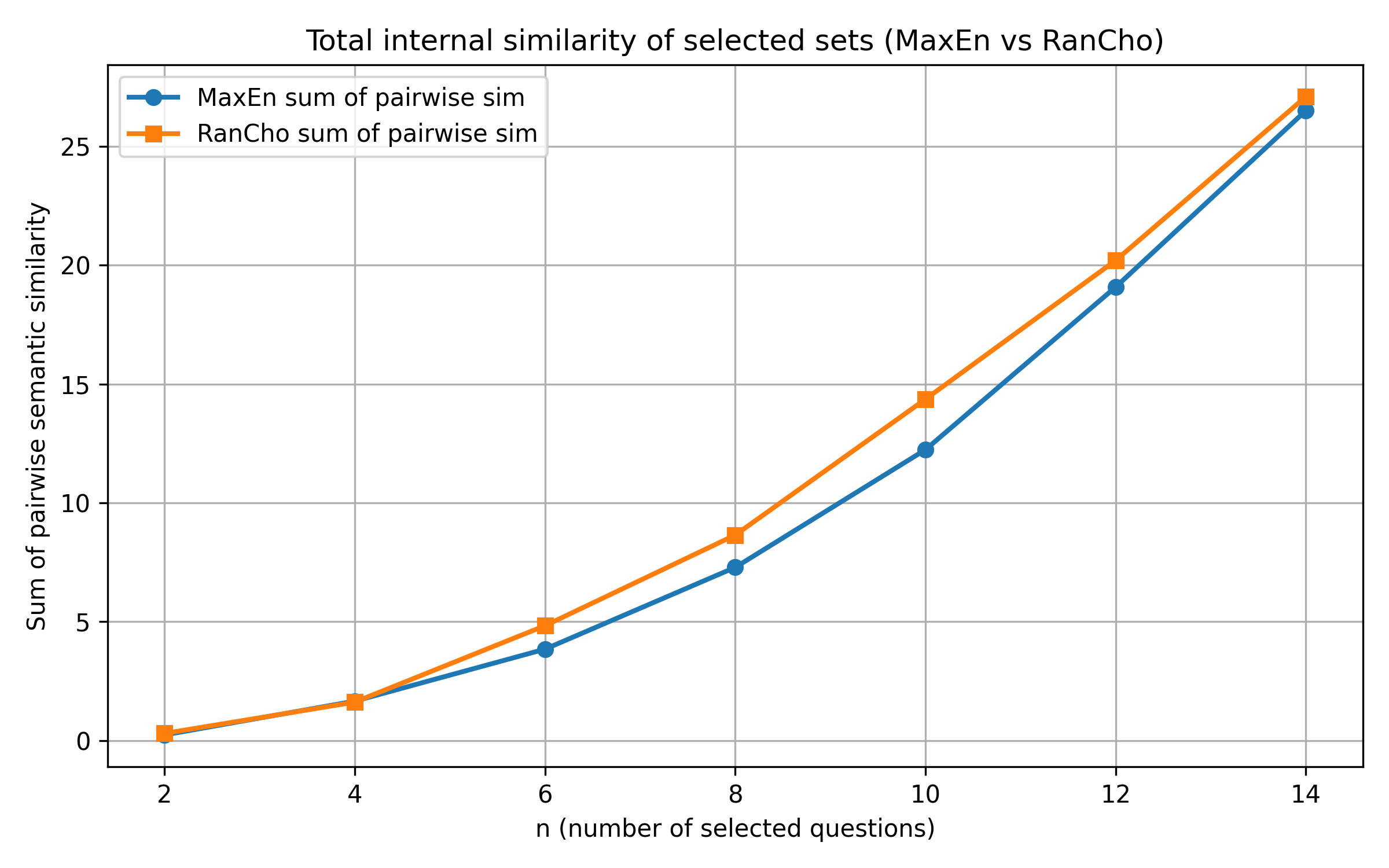
Verification on a benchmark of 60 semantically diverse
question–solution pairs demonstrates that the proposed entropy-
guided approach achieves stronger coverage of unseen questions
and significantly greater internal diversity than a random base-
line, confirming its effectiveness in discovering more generalizable
and human-inspired methods.
Index
Terms—Large
Language
Models;
Human-Inspired
Learning; Maximum-Entropy Method Discovery; Explicit Mem-
ory (Obvious Record)
I. INTRODUCTION
Large Language Models (LLMs) have achieved sub-
stantial progress across a wide range of reasoning, gen-
eration,
and
problem-solving
tasks
[1].
Their
training
paradigm—predicting the next token over massive cor-
pora—enables them to capture broad statistical regularities and
to perform well on problems that are commonly represented
in training data [2]. Despite these strengths, LLMs exhibit sig-
nificant limitations when confronted with rare, low-resource,
or previously unseen scenarios.
Typical examples include niche hardware deployment issues
(e.g., uncommon GPU models), atypical IoT device failures, or
real-world system problems that lack sufficient textual docu-
mentation online. For instance, mainstream software frame-
works such as TensorFlow and PyTorch primarily provide
H. Su is with the School of Computer Science, Chengdu University of
Information Technology, Chengdu, China.
E-mail: suguest@126.com.
default support for widely used GPU hardware and standard
operating systems, whereas newly released or less common
GPUs—especially when combined with highly customized
or non-mainstream operating systems—often require device-
specific configurations and undocumented adaptations. Be-
cause LLMs predominantly reflect commonly learned patterns,
they are often ineffective when addressing such specialized
GPU–OS combinations, forcing users to rely instead on tar-
geted technical forums or vendor-specific documentation to
obtain reliable solutions. As these cases are sparsely repre-
sented in training corpora, LLM-generated responses tend to
be incomplete, inaccurate, or overly generic.
A key reason for this limitation lies in the nature of paramet-
ric learning. In LLMs, knowledge is stored implicitly within
weight matrices, and retrieval occurs through an intuition-like
process in which the model selects high-probability continua-
tions based on previously learned patterns. In contrast, human
learners employ a dual mechanism: they rely on intuition
for familiar situations while also maintaining explicit memory
of specific cause–result relationships, which enables them to
recall rare experiences and refine methods over time. Such
explicit memory is essential for handling infrequent events
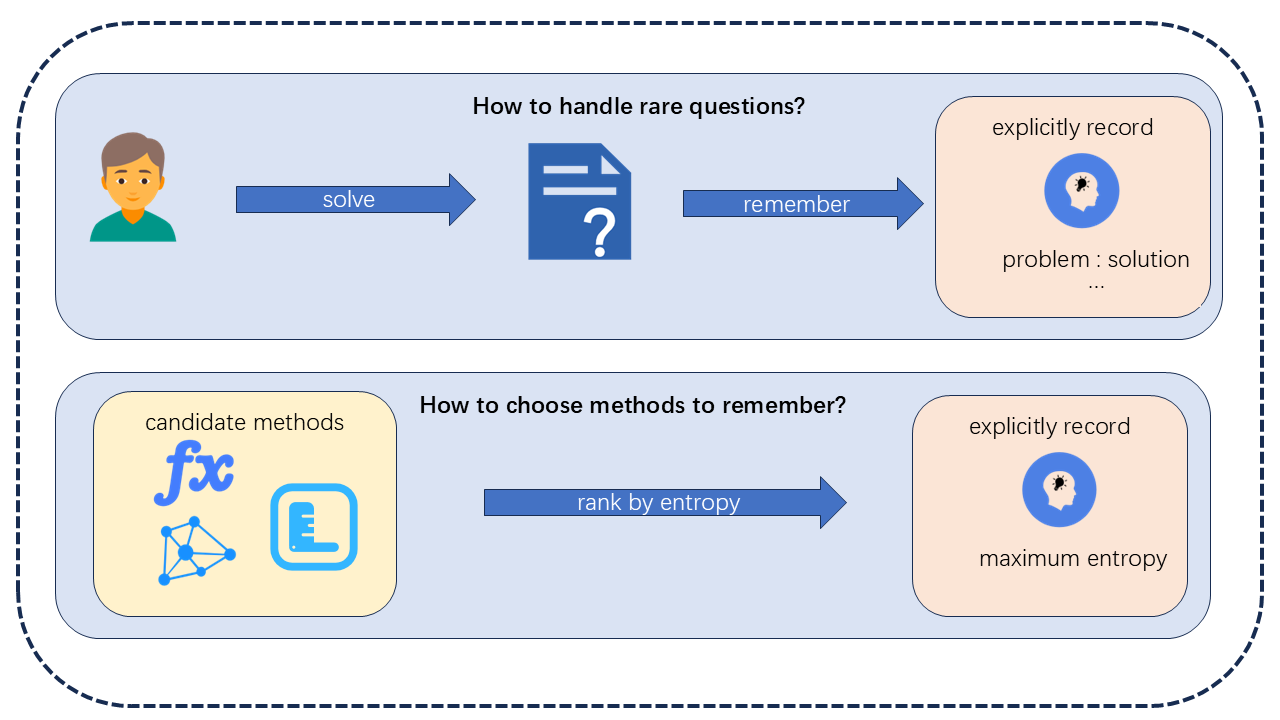
that intuition alone cannot resolve, as illustrated in Fig. 1.
Motivated by this gap, we propose a human-like learning
framework that augments LLMs with two complementary
capabilities:
• Obvious Record - Explicit Memory — an explicit,
symbolic, non-parametric memory for storing mappings
of the form featurecause →featureresult. This mechanism
enables the system to learn from single or rare encounters,
preserve interpretable knowledge, and update methods
when better solutions appear.
• Maximum-Entropy Method Discovery — a mechanism
for identifying and retaining methods that are most se-
mantically different from existing knowledge. These high-
entropy methods capture diverse perspectives and novel
strategies that LLMs tend to overlook because they are
not reinforced by next-token prediction.
Together, these mechanisms form a dual-process learning
model in which the LLM acts as an intuition engine while
the Obvious Record and entropy-guided