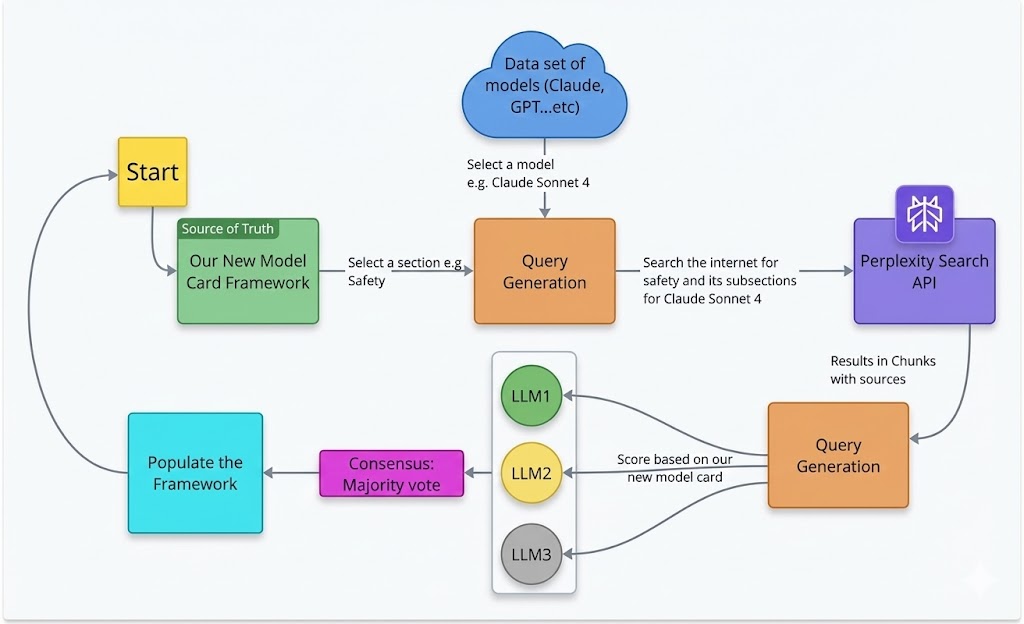
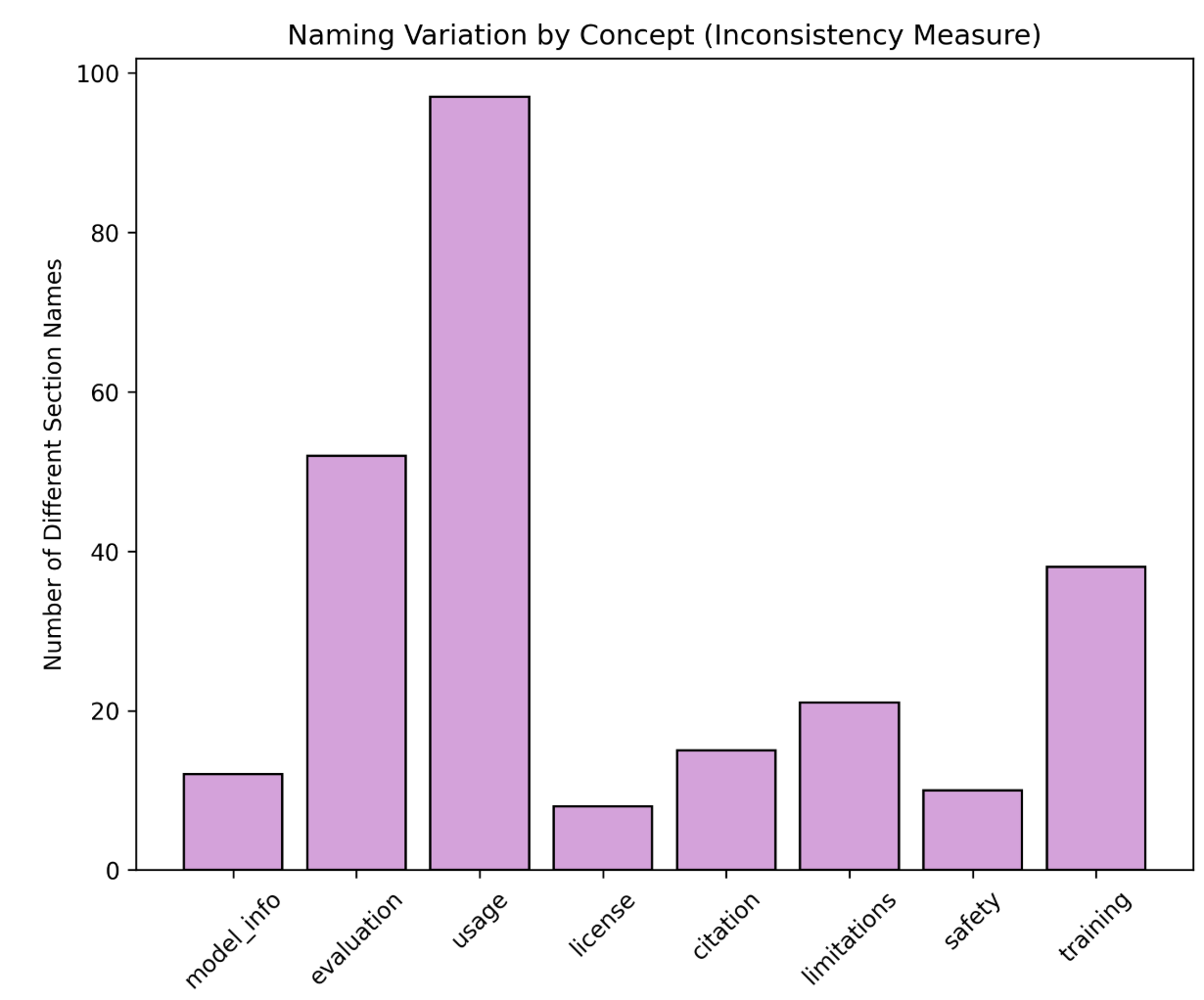
Title: AI Transparency Atlas: Framework, Scoring, and Real-Time Model Card Evaluation Pipeline
ArXiv ID: 2512.12443
Date: 2025-12-13
Authors: Akhmadillo Mamirov, Faiaz Azmain, Hanyu Wang
📝 Abstract
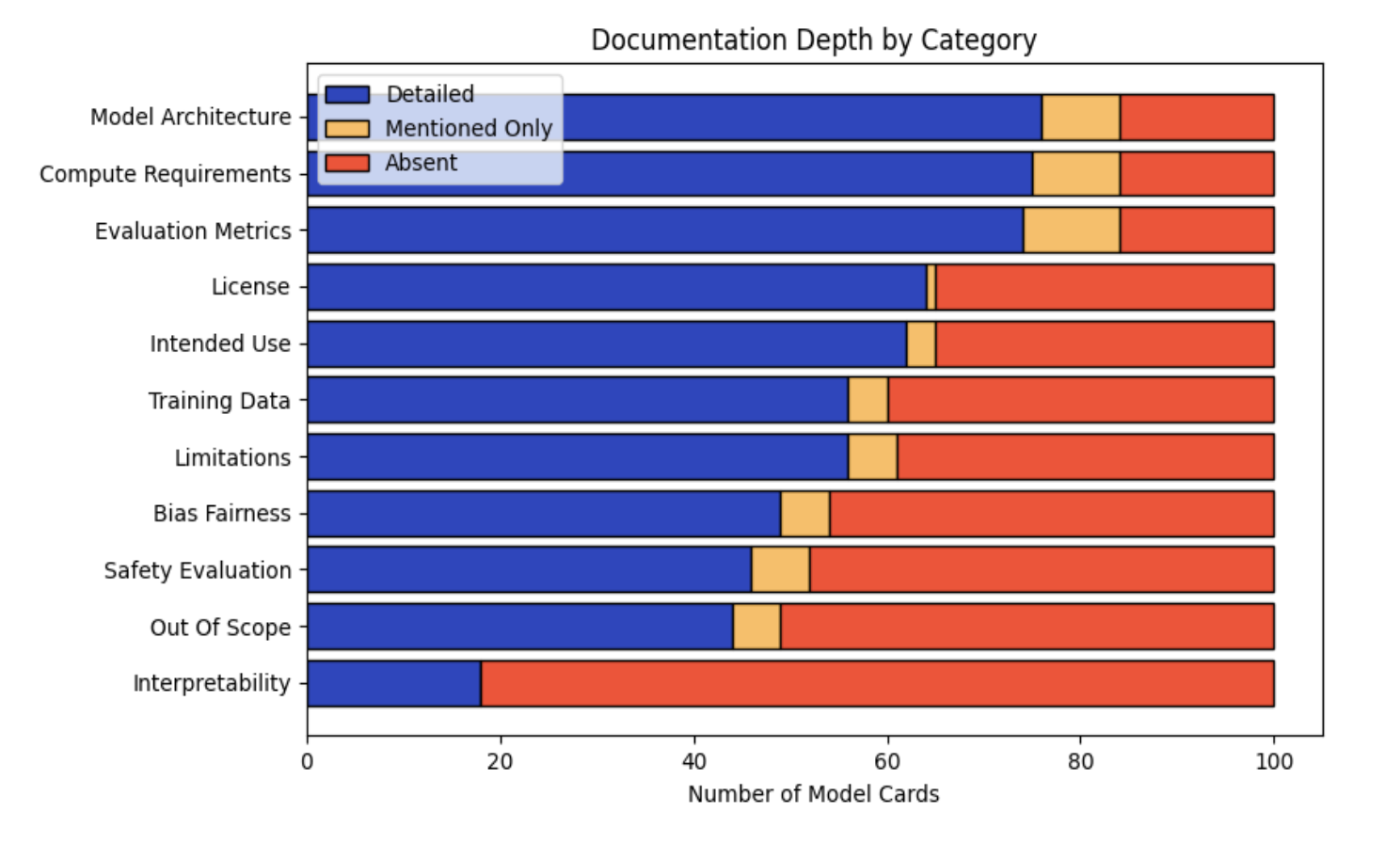
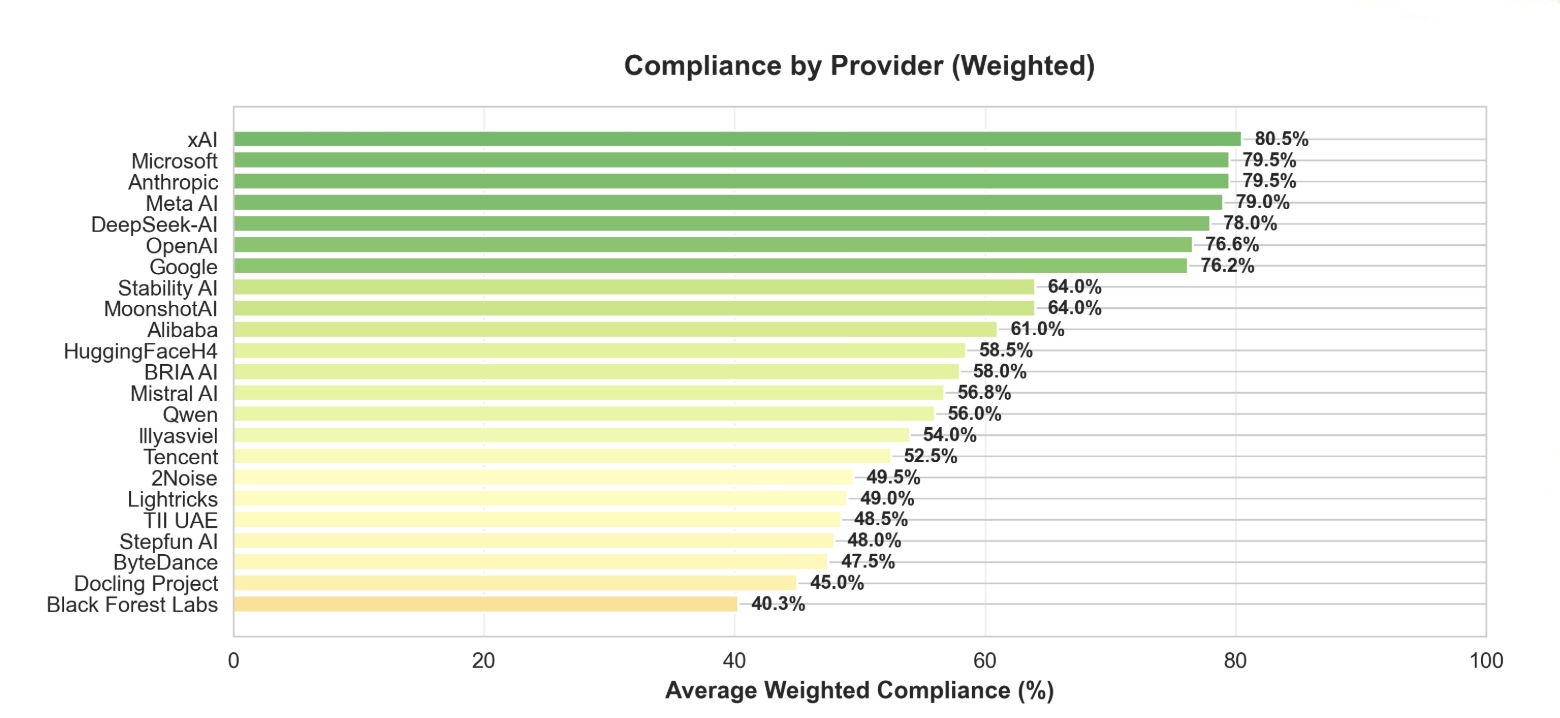
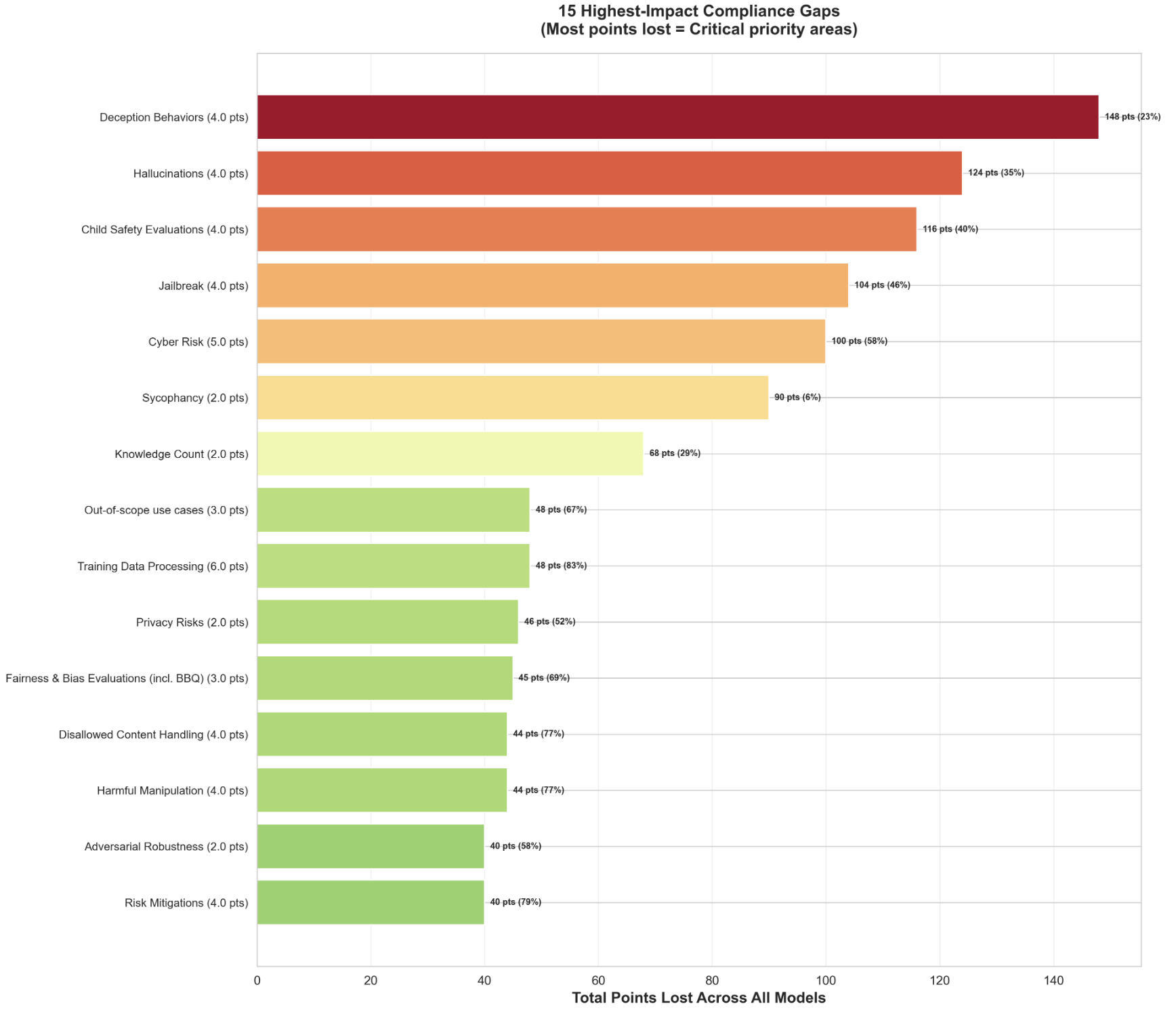
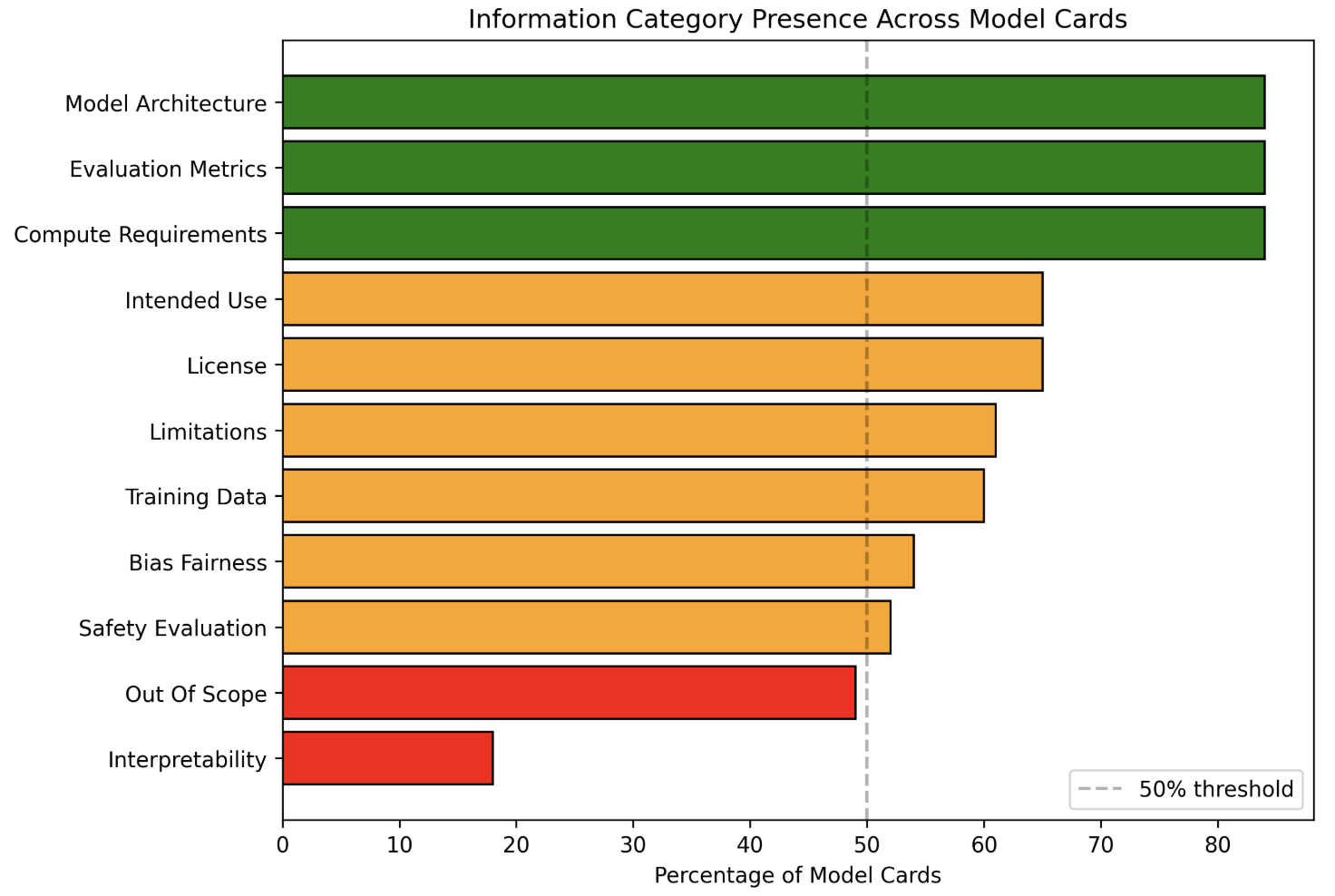
AI model documentation is fragmented across platforms and inconsistent in structure, preventing policymakers, auditors, and users from reliably assessing safety claims, data provenance, and version-level changes. We analyzed documentation from five frontier models (Gemini 3, Grok 4.1, Llama 4, GPT-5, and Claude 4.5) and 100 Hugging Face model cards, identifying 947 unique section names with extreme naming variation. Usage information alone appeared under 97 distinct labels. Using the EU AI Act Annex IV and the Stanford Transparency Index as baselines, we developed a weighted transparency framework with 8 sections and 23 subsections that prioritizes safety-critical disclosures (Safety Evaluation: 25%, Critical Risk: 20%) over technical specifications. We implemented an automated multi-agent pipeline that extracts documentation from public sources and scores completeness through LLM-based consensus. Evaluating 50 models across vision, multimodal, open-source, and closed-source systems cost less than $3 in total and revealed systematic gaps. Frontier labs (xAI, Microsoft, Anthropic) achieve approximately 80% compliance, while most providers fall below 60%. Safety-critical categories show the largest deficits: deception behaviors, hallucinations, and child safety evaluations account for 148, 124, and 116 aggregate points lost, respectively, across all evaluated models.
💡 Deep Analysis
📄 Full Content
AI Transparency Atlas: Framework, Scoring, and
Real-Time Model Card Evaluation Pipeline
Akhmadillo Mamirov∗, Faiaz Azmain∗, Hanyu Wang†
∗Department of Computer Science, The College of Wooster, Wooster, OH, USA
Emails: amamirov26@wooster.edu, fazmain25@wooster.edu
†Robert F. Wagner Graduate School of Public Service, New York University, New York, NY, USA
Email: hw3592@nyu.edu
Abstract—AI model documentation is fragmented across plat-
forms and inconsistent in structure, preventing policymakers,
auditors, and users from reliably assessing safety claims, data
provenance, and version changes. We analyzed documentation
from five frontier models (Gemini 3, Grok 4.1, Llama 4, GPT-
5, Claude 4.5) and 100 Hugging Face model cards, identifying
947 unique section names with extreme naming variation—usage
information alone appeared under 97 different labels. Using
the EU AI Act Annex IV and Stanford Transparency Index
as baselines, we developed a weighted transparency framework
with 8 sections and 23 subsections that prioritizes safety-critical
disclosures (Safety Evaluation: 25%, Critical Risk: 20%) over
technical specifications. We implemented an automated multi-
agent pipeline that extracts documentation from public sources
and scores completeness through LLM consensus. Evaluating
50 models across vision, multimodal, open-source, and closed-
source systems cost less than $3 total and revealed systematic
gaps: frontier labs (xAI, Microsoft, Anthropic) achieve
80%
compliance, while most providers fall below 60%. Safety-critical
categories show the largest deficits—deception behaviors, hallu-
cinations, and child safety evaluations account for 148, 124, and
116 aggregate points lost respectively across all evaluated models.
I. INTRODUCTION
AI model documentation today is fragmented across
whitepapers, GitHub READMEs, Hugging Face model cards,
system cards, and blog posts. This fragmentation raises a core
question: what practical steps can move the ecosystem from
documentation inconsistency toward something standardized
enough to be useful?
Documentation gaps affect every stakeholder. Regulators
cannot reliably assess governance or safety without consistent
reporting. Downstream institutions such as hospitals, schools,
and public agencies lack visibility into model risks, evaluation
protocols, and version-level changes. Even within the same
platform, model cards differ dramatically in length, scope, and
granularity. Some include details about architecture, training
data, and evaluation settings, while others provide only brief
paragraphs. Critically, documentation often does not evolve as
models evolve. Major capability updates, training adjustments,
and safety interventions rarely trigger corresponding updates.
Versioning is ad hoc or entirely absent, causing transparency
to degrade over time.
System cards attempt to address transparency at the deploy-
ment level, but they introduce their own challenges. Many
system cards are high-level but not actionable; others remain
closed, incomplete, or not understandable to external auditors.
When modern AI systems depend on chains of interconnected
models, datasets, and processes, opacity at the system layer
becomes a structural barrier to accountability. When something
goes wrong, responding is difficult because relevant informa-
tion is scattered across multiple documents and repositories
[1].
A. Why Does This Inconsistency Persist?
The persistence of fragmented AI documentation reflects
structural challenges in the AI development ecosystem. Unlike
regulated industries where documentation is mandatory and
enforcement mechanisms are well established, AI transparency
remains largely voluntary, resulting in misaligned incentives.
Economic and competitive pressures. Comprehensive doc-
umentation is resource-intensive, requiring dedicated teams
for safety evaluations, data provenance tracking, and version
management. Organizations prioritizing rapid deployment of-
ten treat documentation as secondary to product development.
Closed-source developers face additional tension: detailed
transparency can expose competitive advantages related to
training methods, data sources, or architectural choices. As
a result, disclosure decisions frequently involve trade-offs
between transparency commitments and intellectual property
protection.
Organizational fragmentation. High-quality documenta-
tion requires coordination across teams that typically operate
independently. Engineers prioritize model performance, safety
teams focus on risk assessment, and communications teams
manage external messaging. Without integrated workflows that
treat documentation as a natural byproduct of development,
information remains siloed across internal wikis, isolated
reports, and fragmented public communications.
Competing standards. Developers encounter overlapping
documentation proposals, including Model Cards, Datasheets
for Datasets, System Cards, and emerging regulatory frame-
works, each emphasizing differe