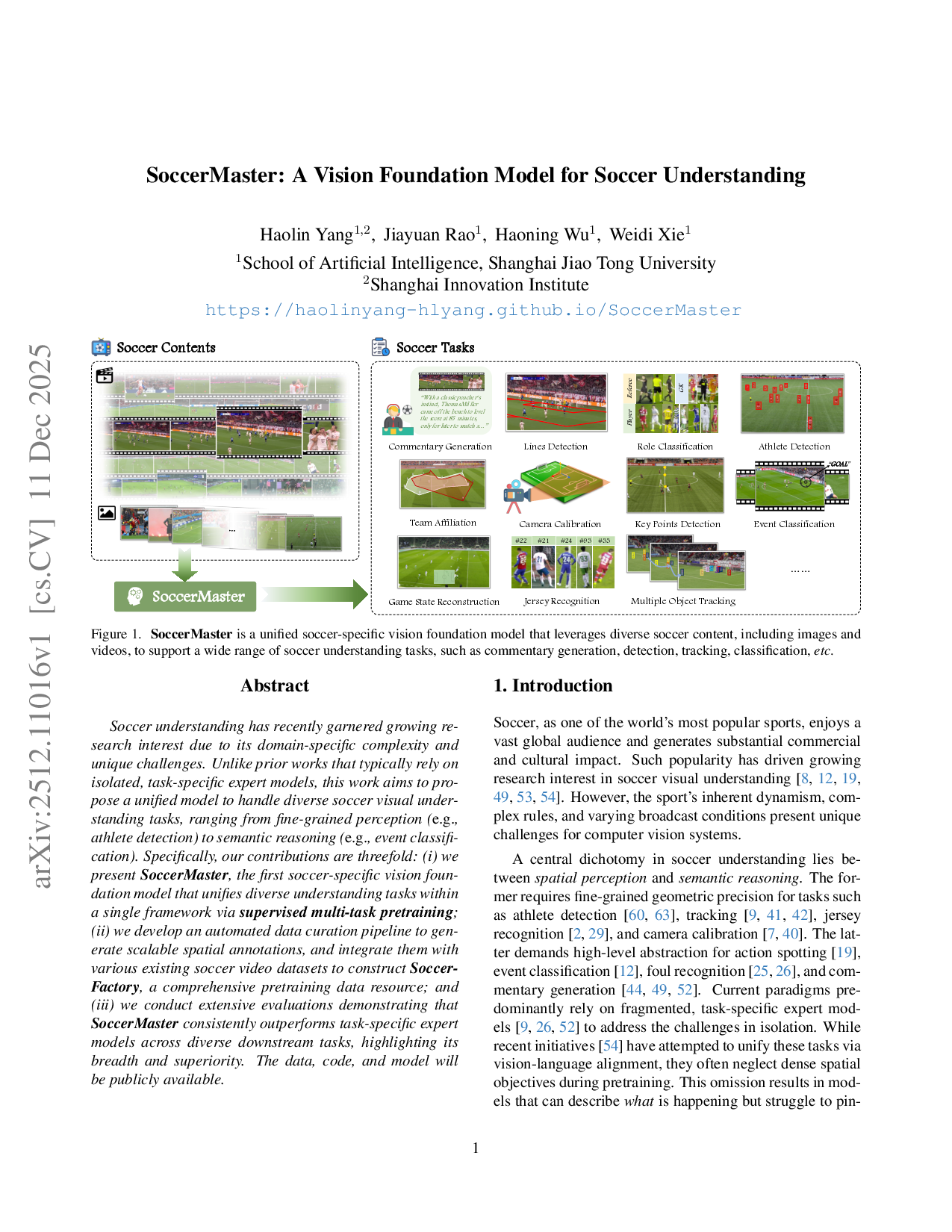
Soccer understanding has recently garnered growing research interest due to its domain-specific complexity and unique challenges. Unlike prior works that typically rely on isolated, task-specific expert models, this work aims to propose a unified model to handle diverse soccer visual understanding tasks, ranging from fine-grained perception (e.g., athlete detection) to semantic reasoning (e.g., event classification). Specifically, our contributions are threefold: (i) we present SoccerMaster, the first soccer-specific vision foundation model that unifies diverse understanding tasks within a single framework via supervised multi-task pretraining; (ii) we develop an automated data curation pipeline to generate scalable spatial annotations, and integrate them with various existing soccer video datasets to construct SoccerFactory, a comprehensive pretraining data resource; and (iii) we conduct extensive evaluations demonstrating that SoccerMaster consistently outperforms task-specific expert models across diverse downstream tasks, highlighting its breadth and superiority. The data, code, and model will be publicly available.
Soccer, as one of the world's most popular sports, enjoys a vast global audience and generates substantial commercial and cultural impact. Such popularity has driven growing research interest in soccer visual understanding [8,12,19,49,53,54]. However, the sport's inherent dynamism, complex rules, and varying broadcast conditions present unique challenges for computer vision systems.
A central dichotomy in soccer understanding lies between spatial perception and semantic reasoning. The former requires fine-grained geometric precision for tasks such as athlete detection [60,63], tracking [9,41,42], jersey recognition [2,29], and camera calibration [7,40]. The latter demands high-level abstraction for action spotting [19], event classification [12], foul recognition [25,26], and commentary generation [44,49,52]. Current paradigms predominantly rely on fragmented, task-specific expert models [9,26,52] to address the challenges in isolation. While recent initiatives [54] have attempted to unify these tasks via vision-language alignment, they often neglect dense spatial objectives during pretraining. This omission results in models that can describe what is happening but struggle to pin-point where or who is involved, leading to a disconnect between geometric perception and semantic reasoning.
To address the aforementioned challenges, we introduce SoccerMaster, the first soccer-specific vision foundation model that unifies fine-grained spatial perception and high-level semantic representations within a single framework. As depicted in Figure 1, SoccerMaster is designed to learn holistic representations through multi-task learning. By simultaneously optimizing for (i) athlete detection, (ii) pitch registration, (iii) event classification, and (iv) vision-language alignment, we enforce a shared representation that captures both the geometry of the pitch and the semantics of the game.
Large-scale training requires massive data. To address the scarcity of dense spatial labels, we develop an automated data curation pipeline capable of generating highquality annotations from broadcast footage at scale. By integrating this curated data with existing heterogeneous datasets, we construct SoccerFactory. This comprehensive pretraining resource balances breadth (coverage of diverse events, leagues, and camera styles) with depth (dense spatial labels and temporally precise semantics), driving effective multi-task optimization.
We conduct extensive evaluations across a broad spectrum of tasks, spanning both spatial perception (e.g., athlete detection, pitch registration, camera calibration, multiple object tracking) and semantic reasoning (e.g., visionlanguage alignment, event classification, commentary generation). Our results demonstrate that SoccerMaster substantially outperforms both general-purpose vision foundation models (e.g., SigLIP 2 [62], DINOv3 [59]) and soccer-specific models (MatchVision [54]) across all pretraining tasks with direct evaluation. Moreover, with only lightweight task-specific fine-tuning, our model establishes state-of-the-art or competitive results on downstream applications such as camera calibration [20,40], multiple object tracking [9], and commentary generation [52]. These findings validate that SoccerMaster has learned universal, transferable representations that effectively generalize to diverse soccer visual understanding scenarios.
Overall, our contributions can be summarized as follows: (i) we introduce SoccerMaster, the first soccer-specific vision foundation model that unifies diverse soccer visual understanding tasks within a single framework, serving as a versatile backbone for comprehensive soccer analysis; (ii) we introduce a supervised multi-task pretraining strategy that jointly optimizes fine-grained spatial perception and high-level semantic reasoning tasks on soccer videos, enabling to learn multi-granularity representations that capture both local spatial details and global semantic context; (iii) we develop an automated data curation pipeline to generate large-scale spatial annotations from broadcast footage, and integrate these with various existing soccer video datasets to construct SoccerFactory, a comprehensive soccer-specific pretraining resource; and (iv) we conduct extensive evaluations demonstrating that SoccerMaster can serve as a foundation model for soccer understanding, which achieves state-of-the-art or competitive performance on all downstream tasks through simple fine-tuning.
Vision foundation models (VFMs) [13,45,51,55,59,62,79,82] have revolutionized computer vision by learning universal visual representations through large-scale pretraining, demonstrating strong generalization and transfer capabilities across diverse tasks. This has further inspired their adaptation and application in numerous downstream vertical domains or tasks, such as image captioning [31,32], 3D perception [66,77], medical imaging [68,83], robotics [16], and autonomous driving [17
This content is AI-processed based on open access ArXiv data.