Unequal representation of demographic groups in training data poses challenges to model generalisation across populations. Standard practice assumes that balancing subgroup representation optimises performance. However, recent empirical results contradict this assumption: in some cases, imbalanced data distributions actually improve subgroup performance, while in others, subgroup performance remains unaffected by the absence of an entire subgroup during training. We conduct a systematic study of subgroup allocation across four vision and language models, varying training data composition to characterise the sensitivity of subgroup performance to data balance. We propose the latent separation hypothesis, which states that a partially fine-tuned model's dependence on subgroup representation is determined by the degree of separation between subgroups in the latent space of the pre-trained model. We formalise this hypothesis, provide theoretical analysis, and validate it empirically. Finally, we present a practical application to foundation model fine-tuning, demonstrating that quantitative analysis of latent subgroup separation can inform data collection and balancing decisions.
There is a wide consensus in machine learning that model performance improves monotonically with increasing training data [Kaplan et al., 2020, Rosenfeld et al., 2020]. This principle, formalised through dataset scaling laws, has guided much of the recent progress in model training. However, real-world data rarely satisfies the assumption of being independent and identically distributed (i.i.d.) [Arjovsky et al., 2020, Wang et al., 2023]. Instead, datasets are composed of clusters of correlated samples, corresponding to subgroups or domains. In the medical domain, clusters may correspond to demographic categories, while in image datasets they may reflect camera types, and in multilingual corpora they may represent language varieties.
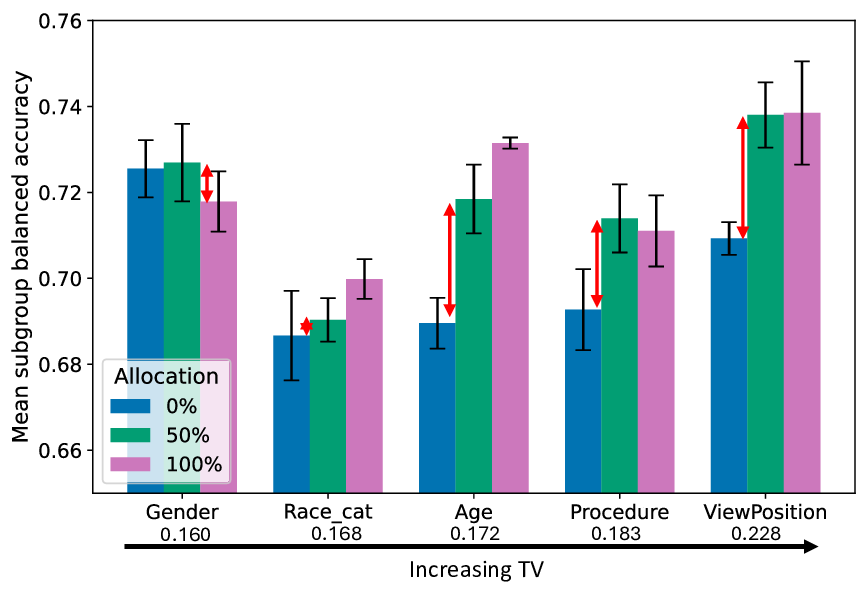
In such cases, the question becomes more nuanced: how does model performance on a particular subgroup scale as its representation in the training data increases? While intuition suggests that a higher proportion of subgroup-specific data should directly improve performance on that subgroup, recent studies have revealed surprising counterexamples [Čevora et al., 2025, Rolf et al., 2021, Weng et al., 2023], where increasing subgroup allocation had little or even no effect. This challenges the widely held view that dataset rebalancing is always a reliable solution [Idrissi et al., 2022]. Therefore, understanding the relationship between subgroup allocation and subgroup performance remains an important open question. When concerned about model fairness, practitioners must decide whether to conduct certain interventions, like collecting balanced data across demographic groups, or resampling or augmenting their dataset, potentially at the cost of reduced overall performance [Idrissi et al., 2022, Raji andBuolamwini, 2019]. In domain generalisation, practitioners must weigh whether fine-tuning on a smaller set of domain-specific data will yield better deployment performance than fine-tuning on a larger set of general data [Hulkund et al., 2025]. More broadly, given the cost of data collection and annotation, knowing when subgroup representation matters can guide whether to prioritise general high-quality data or group-specific data.
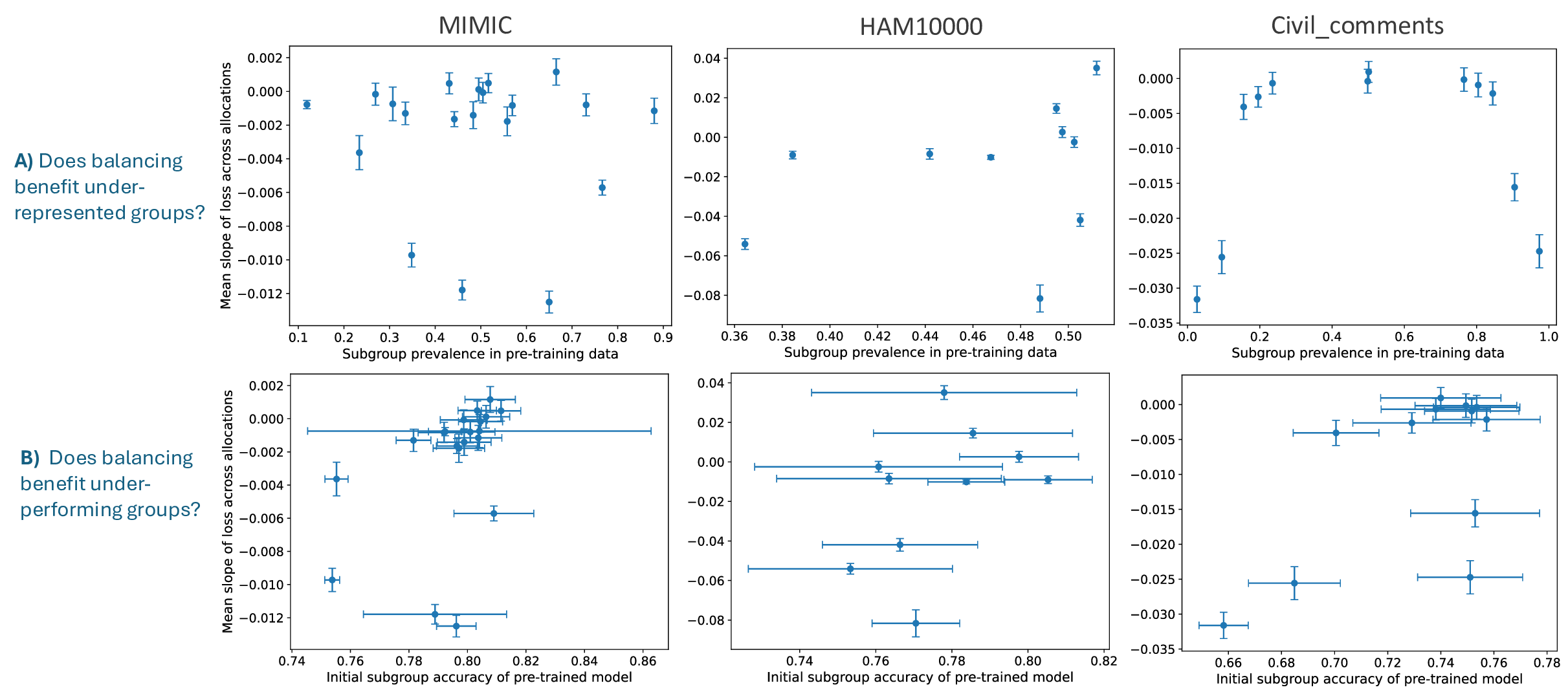
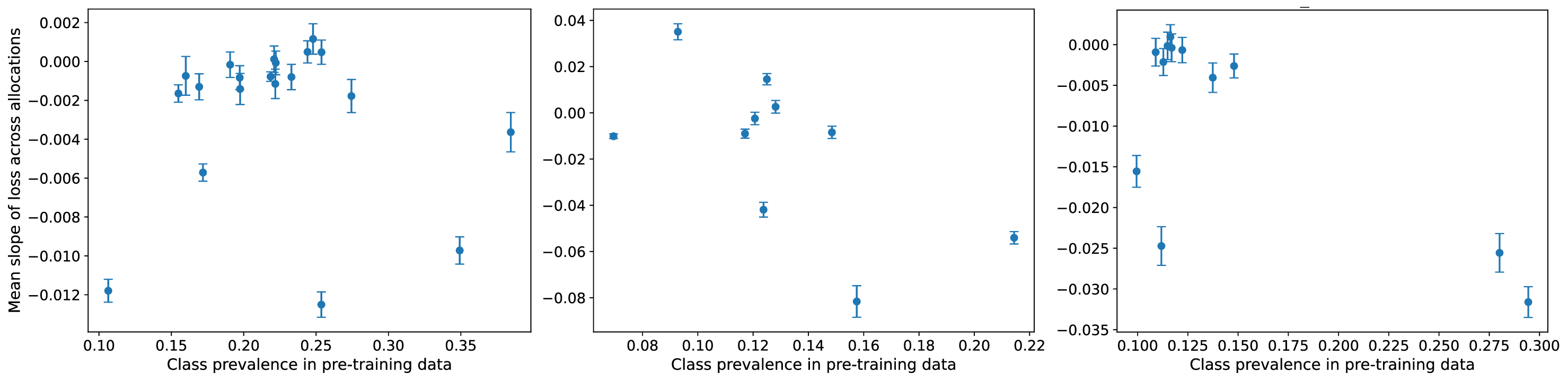
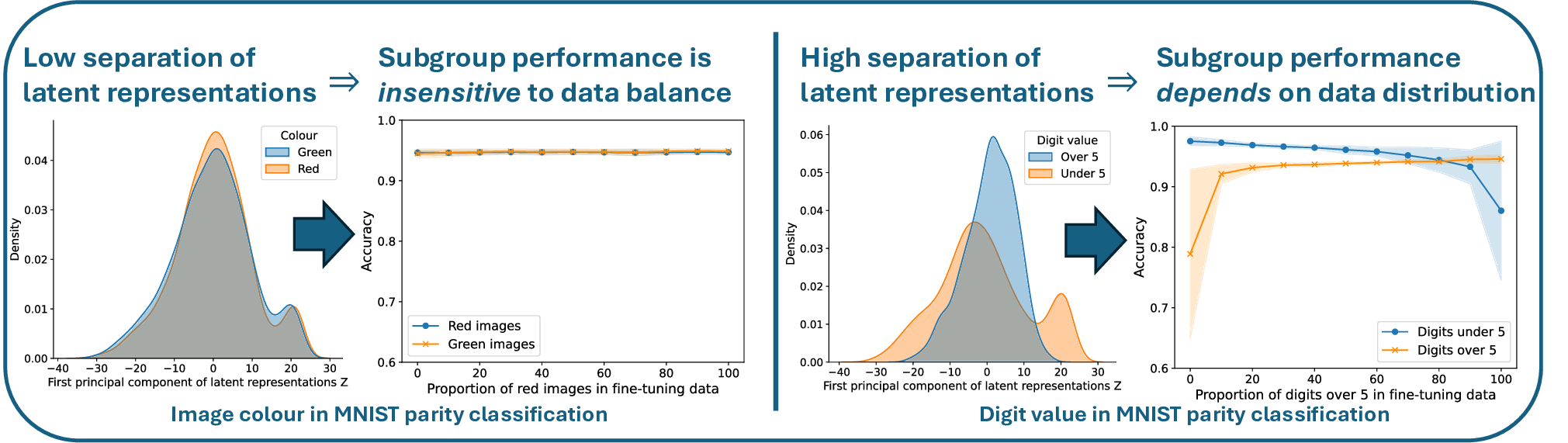
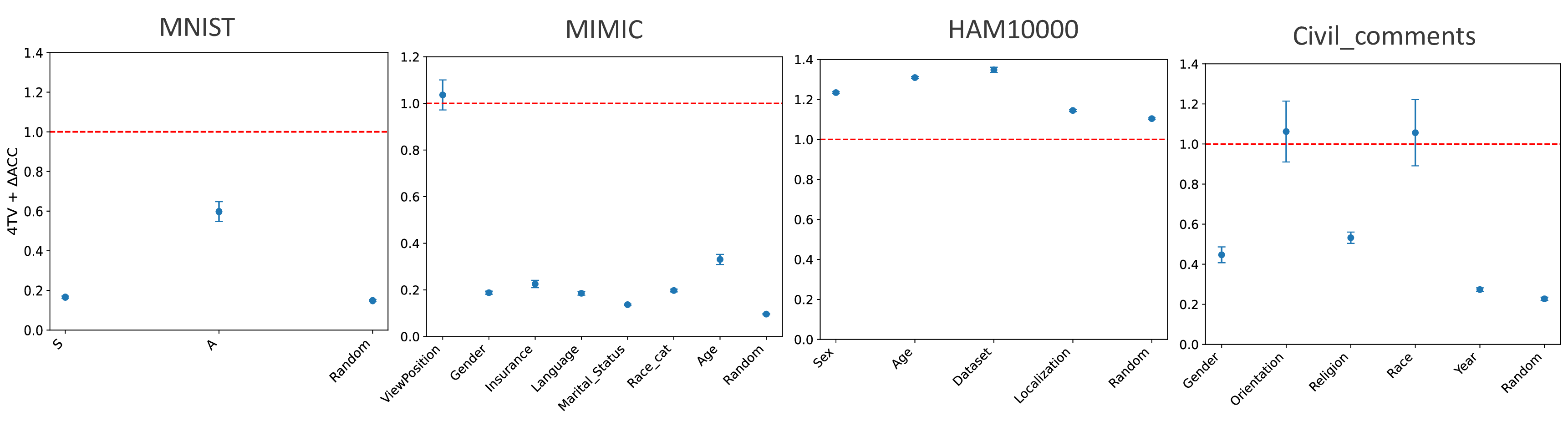
In this work, we aim to understand how the allocation of data across subgroups affects subgroup performance at inference time, given a fixed training budget. Through extensive experiments in vision and language tasks, we find that subgroup sensitivity to allocation varies dramatically across datasets, models, and attributes. We probe why these differences arise and put forward a novel hypothesis: the degree to which redistributing subgroup data improves subgroup performance is determined by how strongly the set of subgroups are separated in the pre-trained model’s latent representations. We provide both theoretical justification and empirical evidence of this hypothesis.
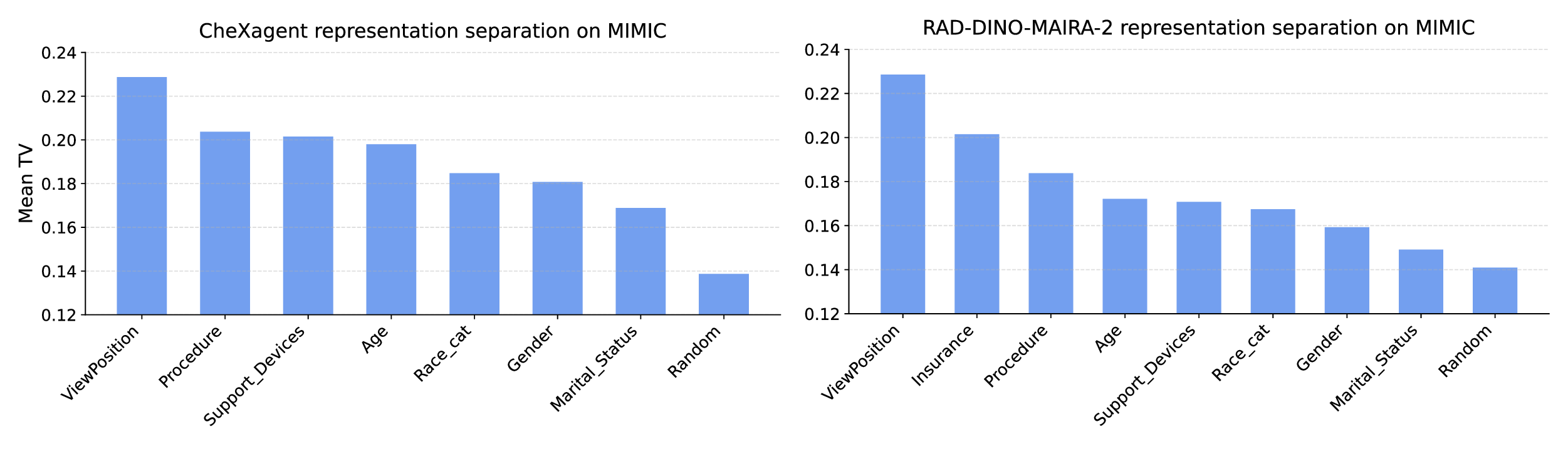
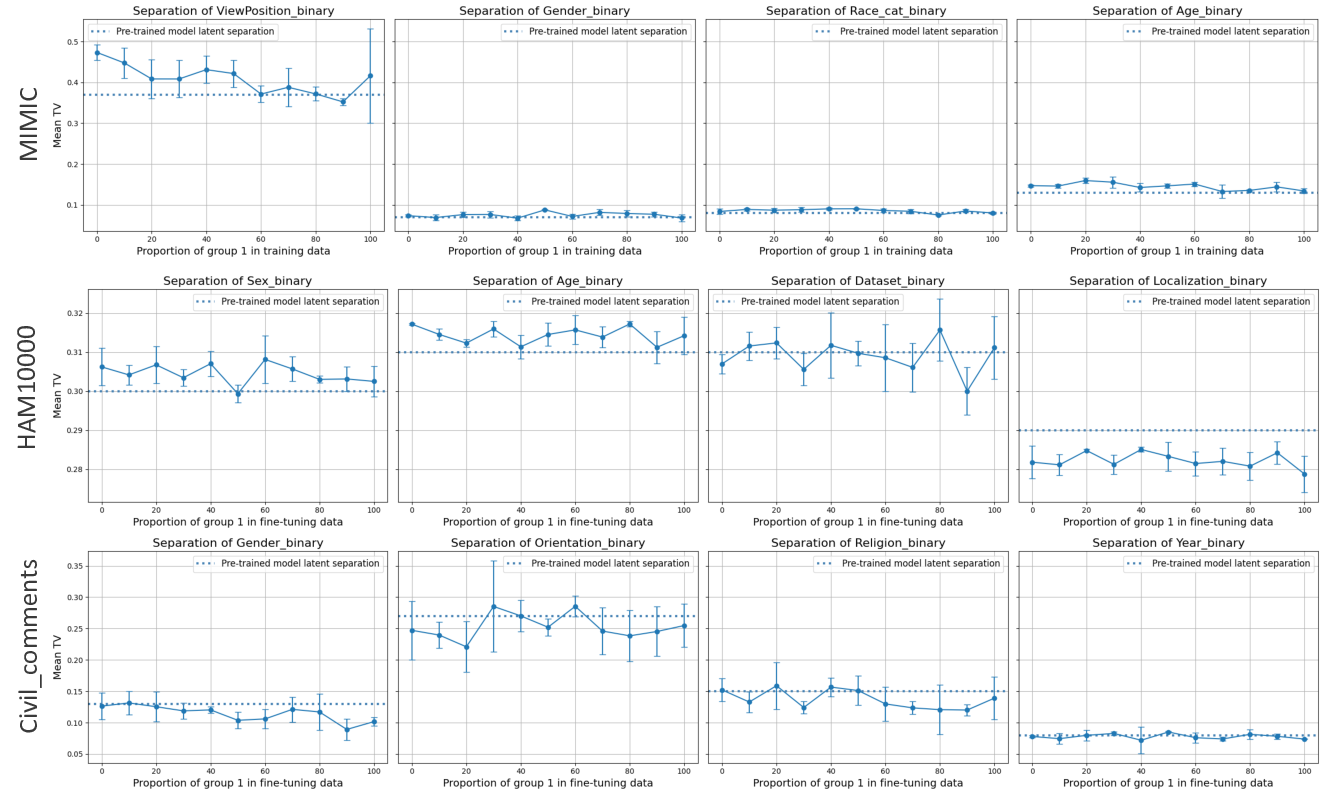
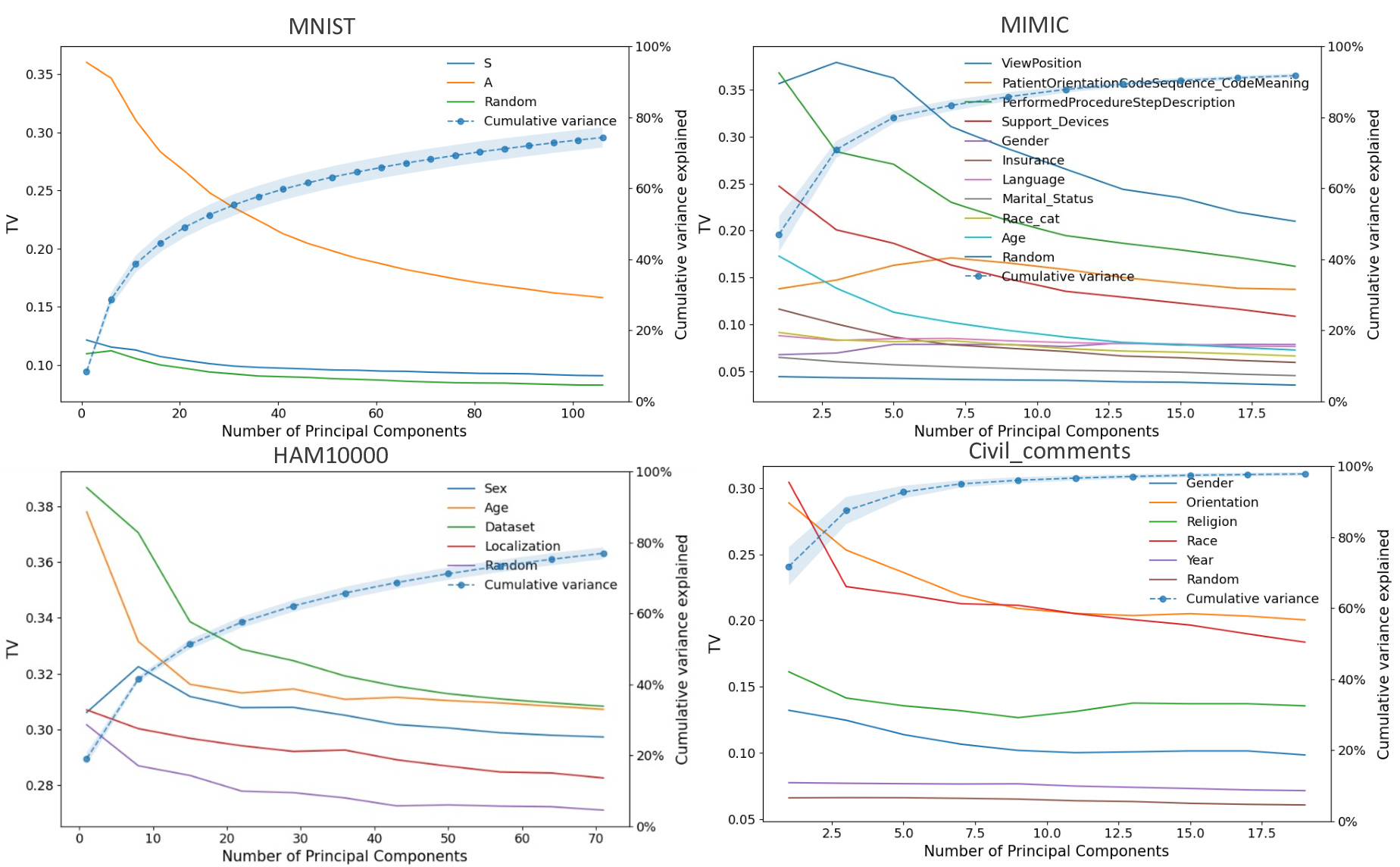
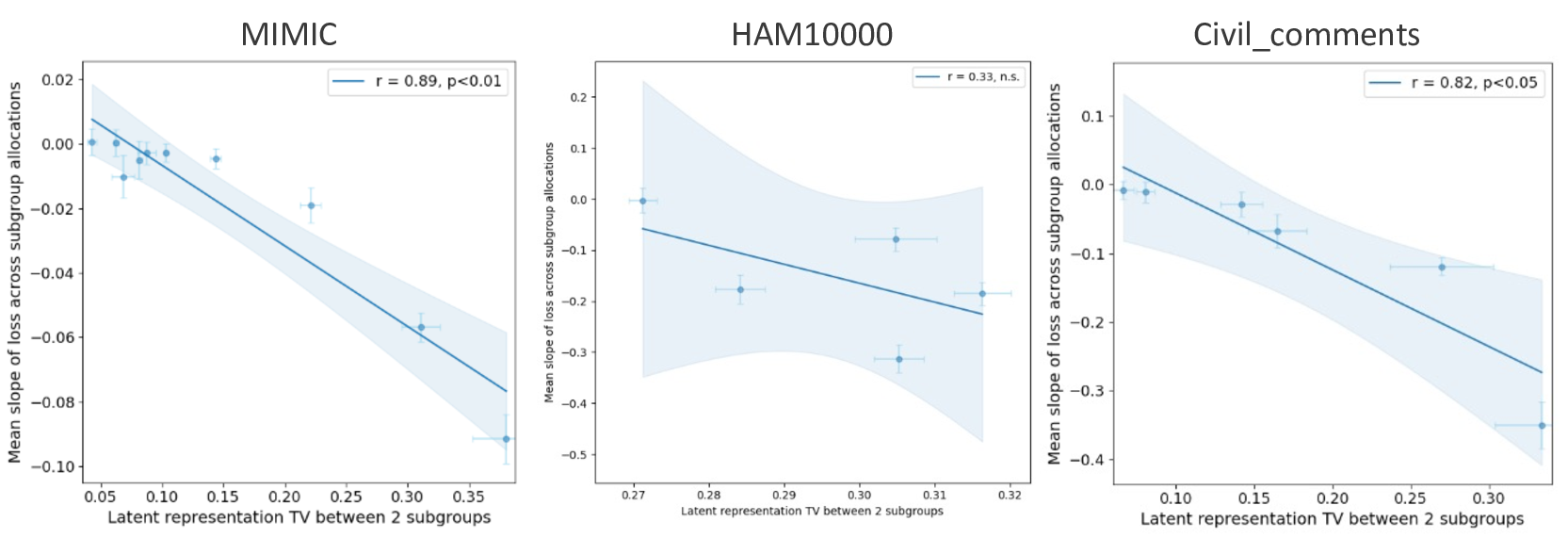
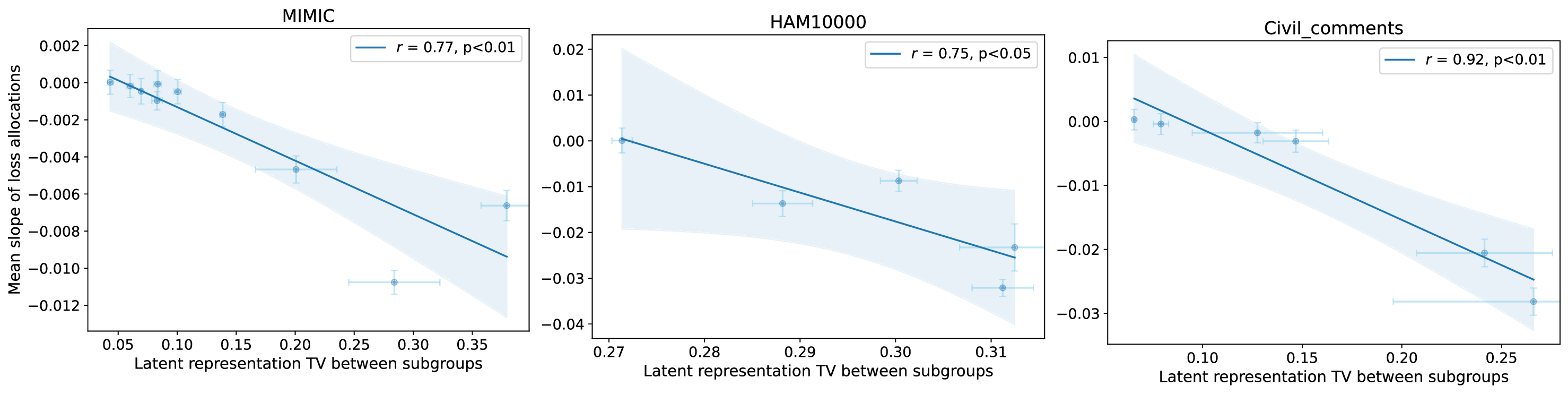
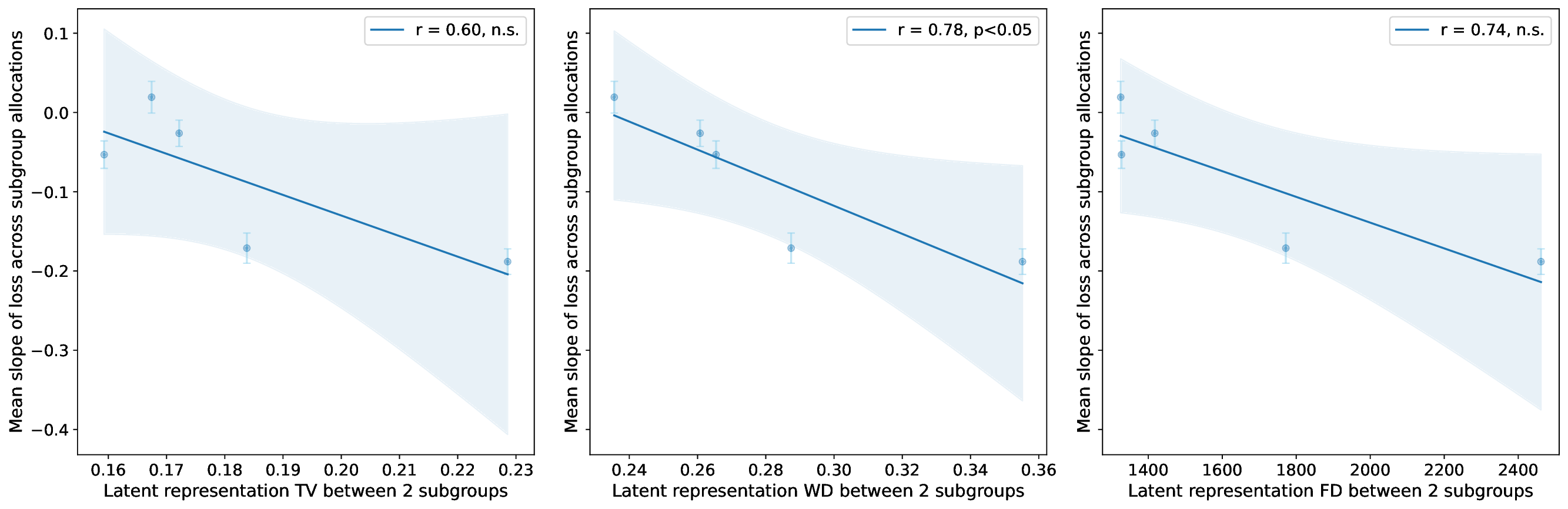
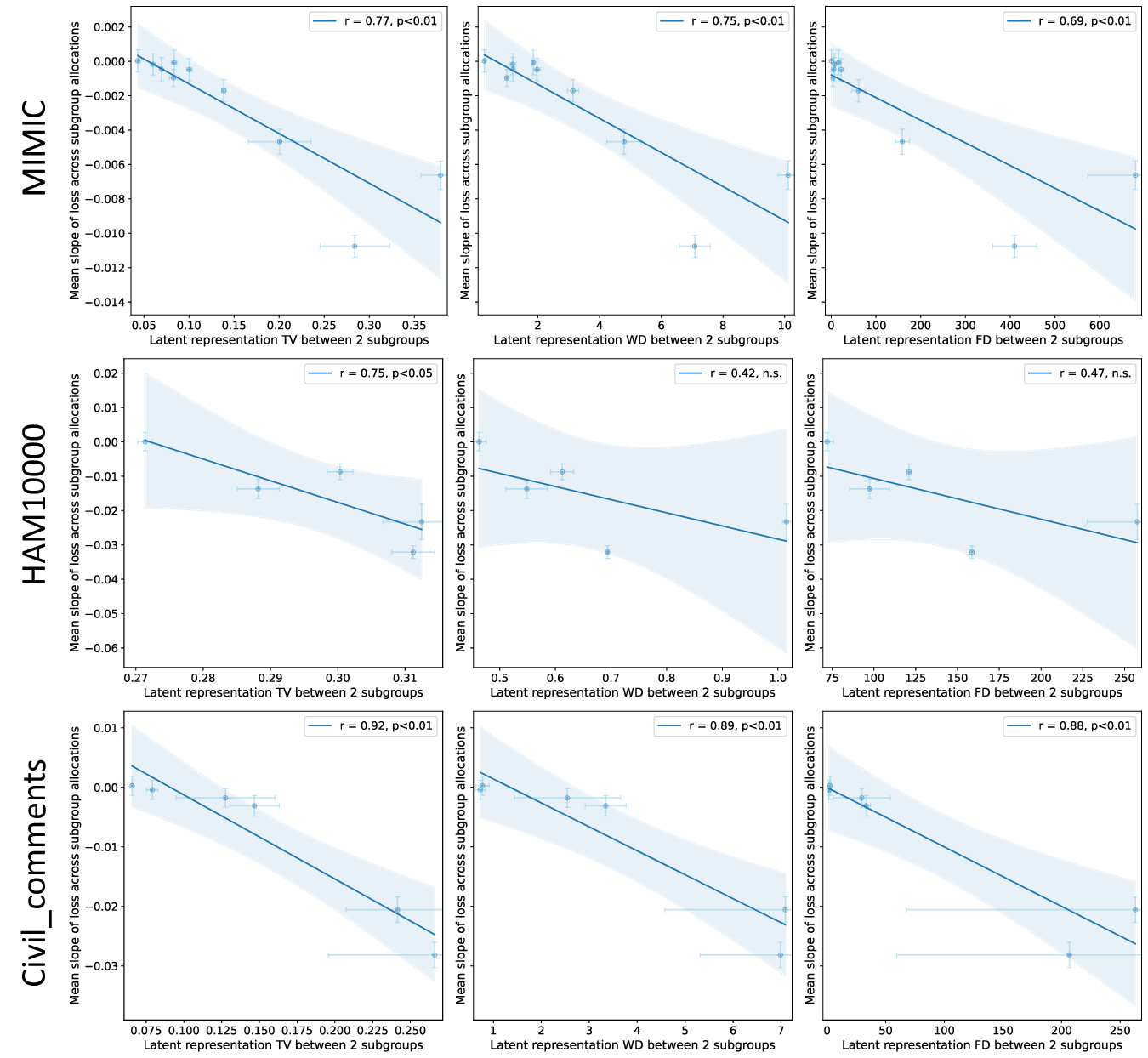
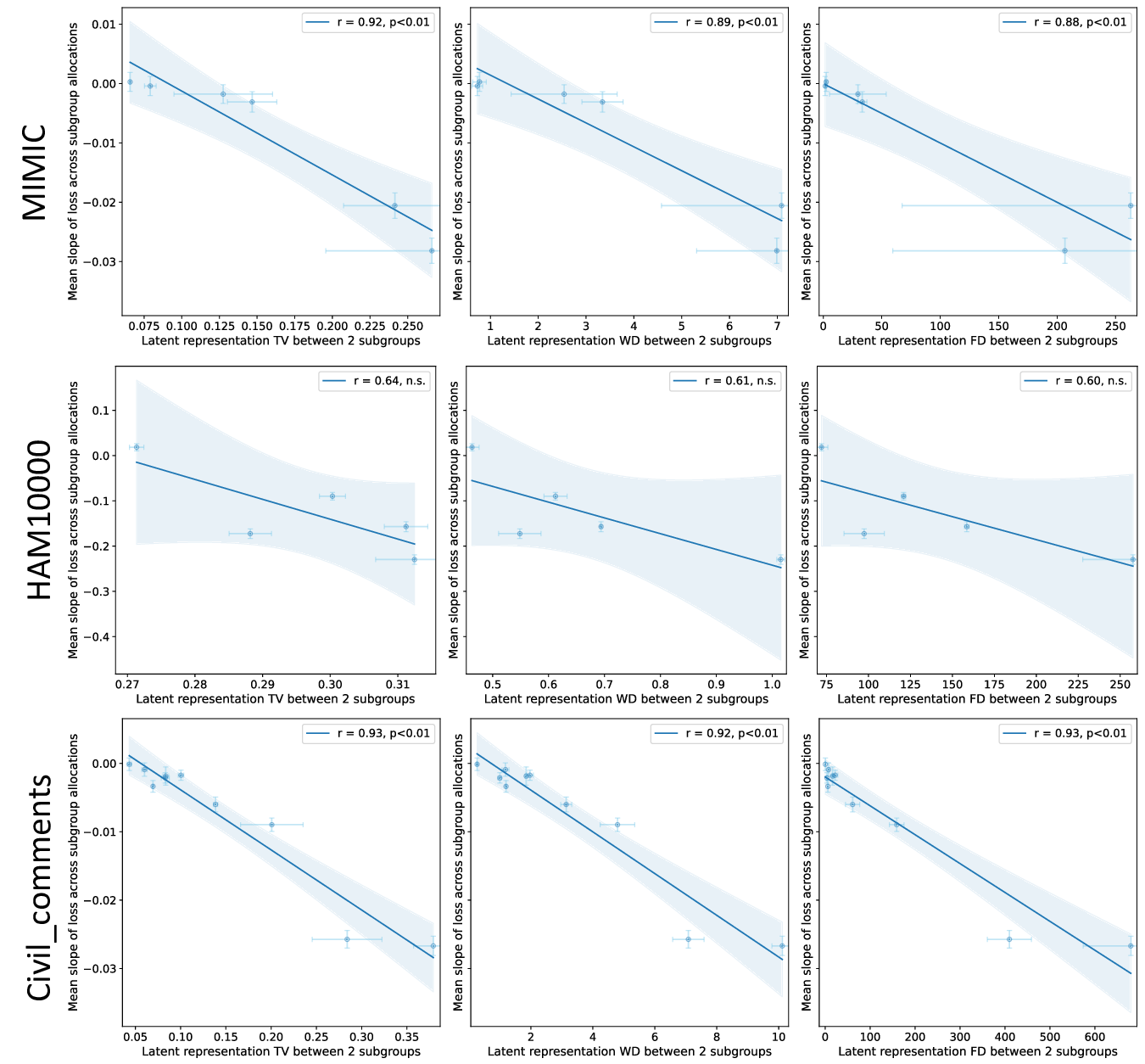
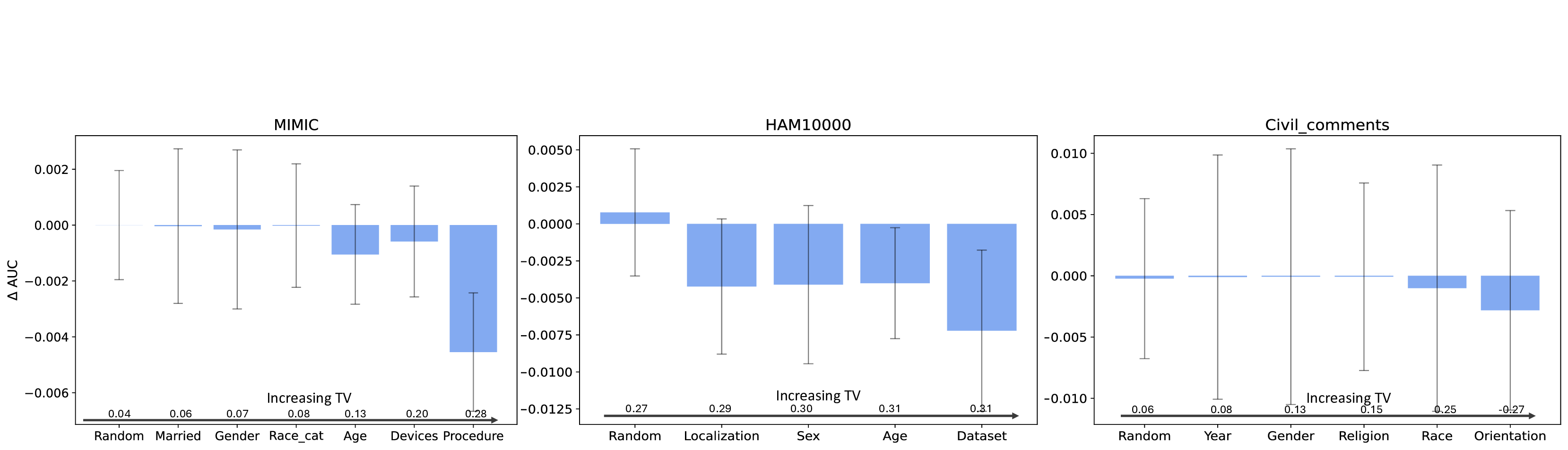
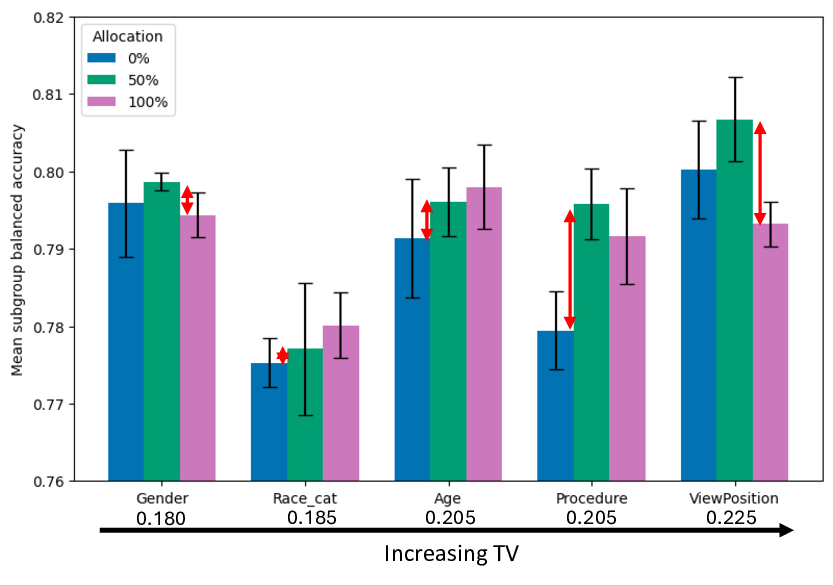
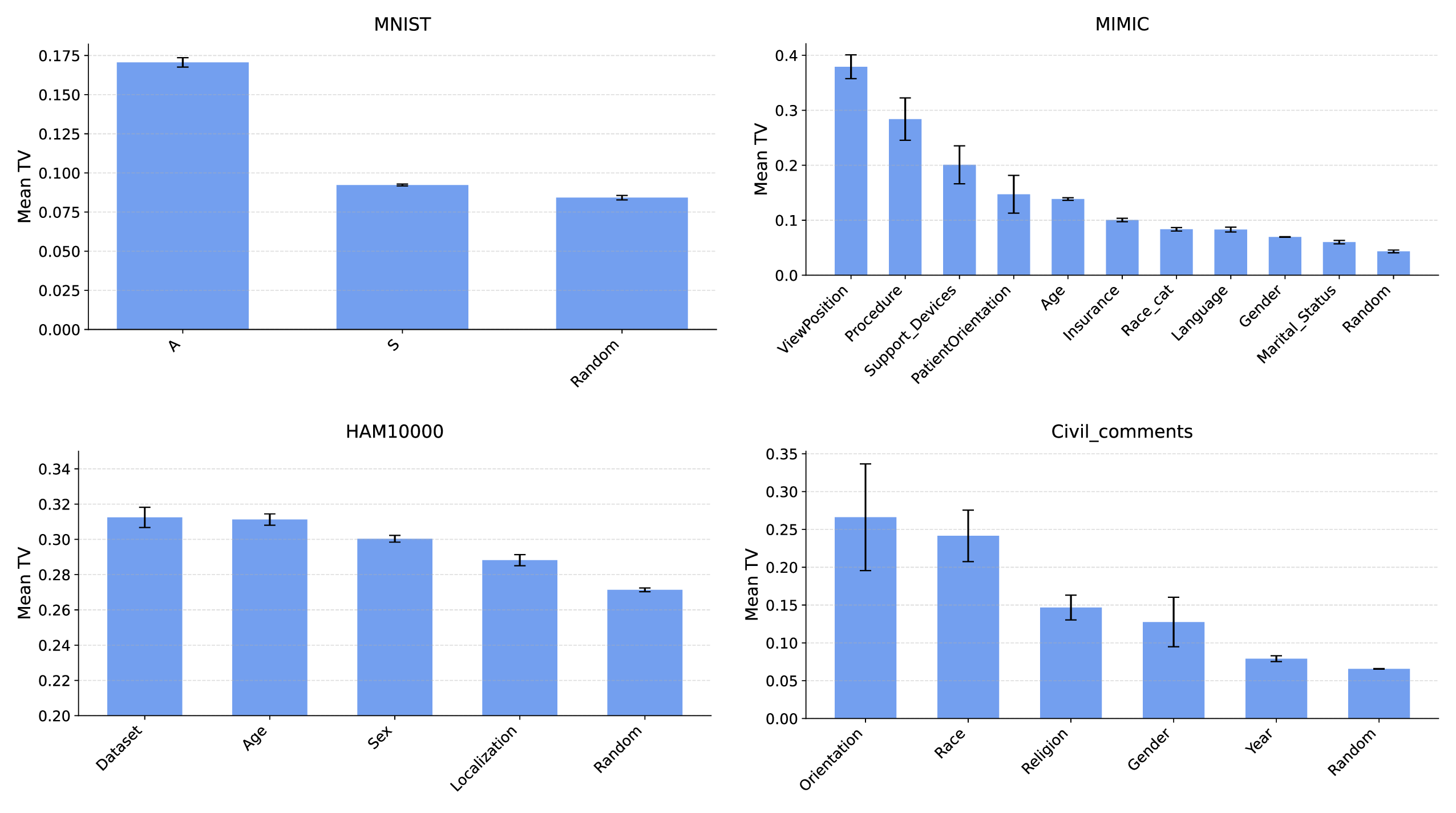
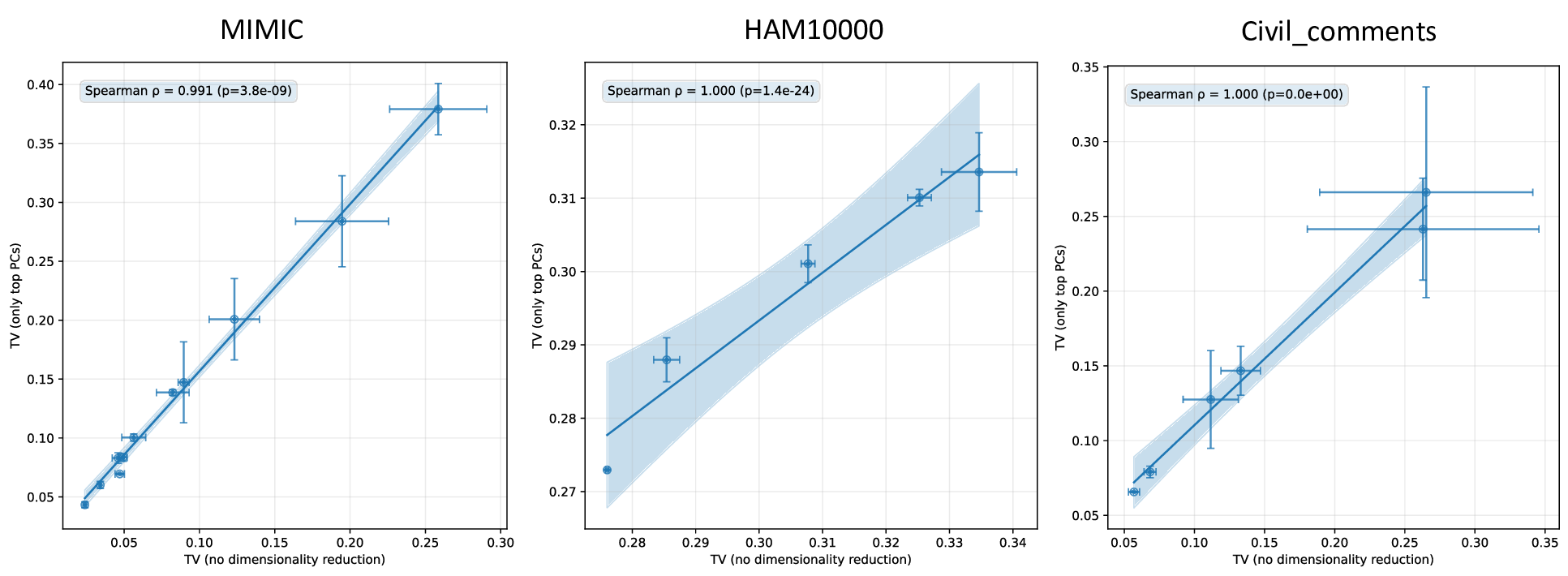
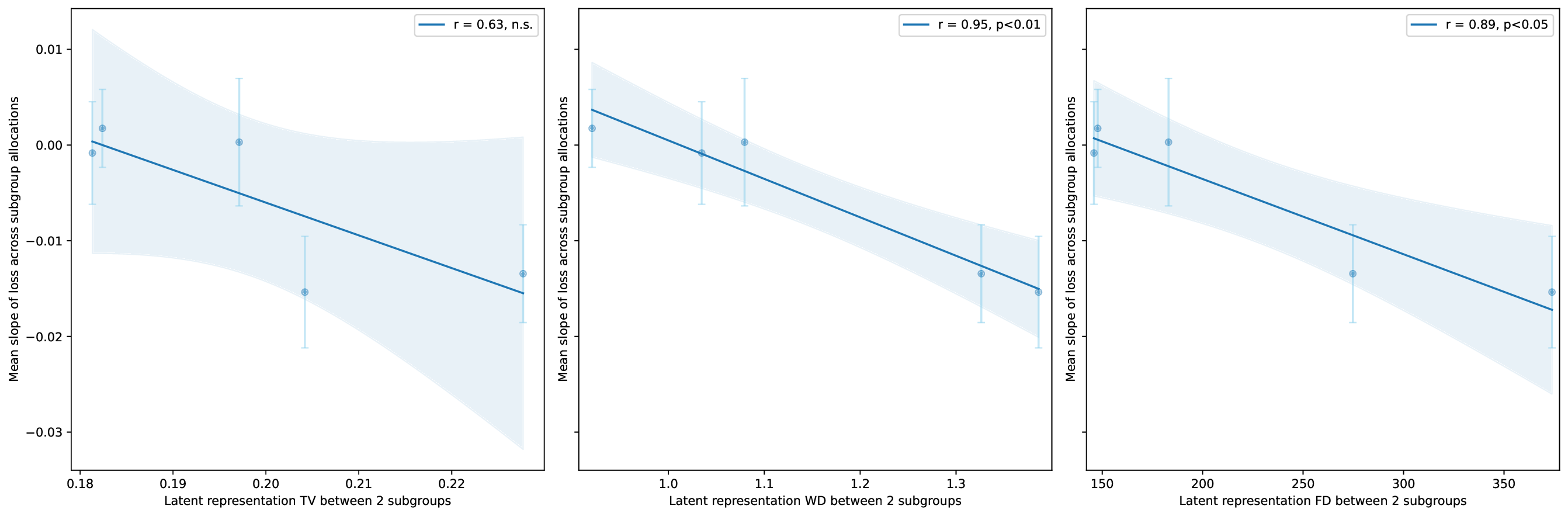
Our contributions are: §4 We demonstrate that widely held explanations for sensitivity to subgroup allocation fail to match empirical behaviour. §5 We derive a theoretical upper bound on sensitivity to subgroup allocation based on subgroup separation in the pre-trained model’s latent space. §6 We show empirically that sensitivity to subgroup allocation is significantly correlated to the distance between two subgroups in the pre-trained model’s latent representations. §6.5 We show how our findings can guide dataset selection decisions to improve fairness in a practical case-study fine-tuning a vision-language foundation model.
Dataset scaling is not straightforward when the train and deployment settings are not i.i.d. We are broadly interested in the relationship between model training data and model performance. Research in this area has investigated different aspects of data (e.g., size, composition, or individual points) and different performance metrics (e.g., overall loss, fairness, or domain-specific accuracy) [Hashimoto, 2021]. While dataset scaling laws have shown that performance improvements follow predictable power law trends [Kaplan et al., 2020, Rosenfeld et al., 2020], this relationship becomes more complex when the training and test data are drawn from different distributions. In such cases more data is not necessarily better. For instance, Hulkund et al. [2025] and Shen et al. [2024] both show that when optimising for a specific deployment setting, a subset of the data can yield better performance than the full dataset. Similarly, Diaz and Madaio [2025] argue that scaled training data can have a negative impact depending on the evaluation metrics and subpopulations considered.
Subgroup data scaling through the lens of fairness This problem has also been studied indirectly in the field of fairness, where data are grouped into subgroups (e.g., based on demographic attributes), and one investigates how training data composition (i.e., number/proportion of samples from certain subgroups) affects fairness (i.e., some metric based on model performance on certain subgroups).
This content is AI-processed based on open access ArXiv data.