Vision Foundation Models (VFMs) and Vision Language Models (VLMs) have revolutionized computer vision by providing rich semantic and geometric representations. This paper presents a comprehensive visual comparison between CLIP based and DINOv2 based approaches for 3D pose estimation in hand object grasping scenarios. We evaluate both models on the task of 6D object pose estimation and demonstrate their complementary strengths: CLIP excels in semantic understanding through language grounding, while DINOv2 provides superior dense geometric features. Through extensive experiments on benchmark datasets, we show that CLIP based methods achieve better semantic consistency, while DINOv2 based approaches demonstrate competitive performance with enhanced geometric precision. Our analysis provides insights for selecting appropriate vision models for robotic manipulation and grasping, picking applications.
A paradigm shift from purely geometric methods to semantically aware systems is represented by the incorporation of Vision Foundation Models (VFMs) and Vision Language Models (VLMs) into 3D pose estimation. While mathematically correct, existing deep learning ways for 6D pose estimation [2] lack the contextual knowledge required for practical robotic manipulation and human computer interaction.
Two prominent paradigms have emerged from recent developments in self-supervised learning: DINOv2 [3], which uses self-distillation to capture rich visual features without explicit language supervision, and CLIP [4], which learns joint vision language representations through contrastive learning. Although both methods have demonstrated impressive performance in a variety of computer vision applications, their use in 3D pose estimation is still largely unexplored.
This paper makes the following contributions:
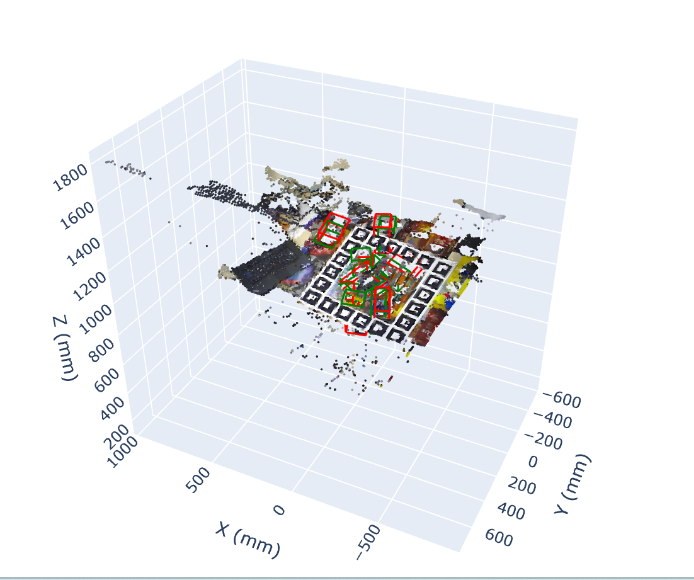
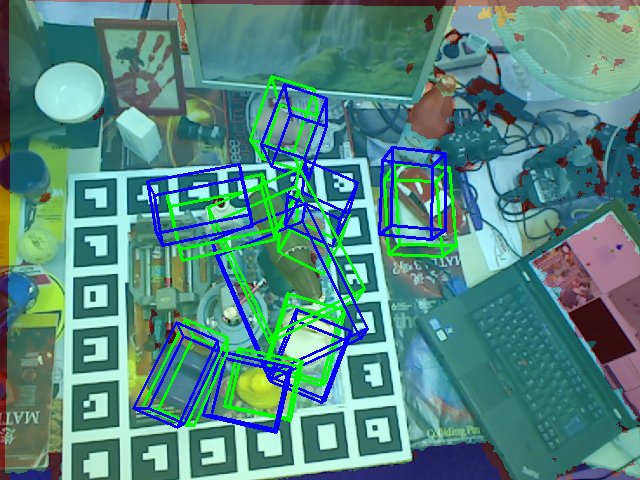
• A systematic comparison of CLIP based and DINOv2 based architectures for 6D object pose estimation in grasping scenarios • Visual analysis of prediction quality through 2D keypoint projection and 3D bounding box visualization • Quantitative evaluation using standard metrics (ADD, ADD-S, rotation error, translation error)
• Insights between semantic understanding and geometric precision
3D pose estimation can be systematically categorized along multiple dimensions, forming a comprehensive taxonomy that guides our understanding of the field’s evolution.
Input Modality: Methods are divided into RGB-only approaches, which leverage color information and learned representations, RGB-D methods that exploit depth sensors for geometric constraints, and multi-modal approaches combining various sensor inputs. Recent VFM based methods primarily operate on RGB input but extract rich geometric and semantic features.
Output Representation: Direct pose regression methods predict 6D pose parameters (rotation and translation) [5] endto-end. Keypoint-based approaches first detect 2D projections of 3D keypoints, then solve PnP for pose recovery. Dense correspondence methods [6] establish pixel-to-model mappings before pose optimization. Hybrid methods combine multiple representations for robustness.
Learning Paradigm: Supervised methods require extensive labeled pose annotations. Self-supervised approaches leverage geometric constraints (epipolar geometry, photometric consistency) [7] or reconstruction losses. Foundation models introduce a new paradigm of pre-training on massive unlabeled datasets followed by task specific fine-tuning, bridging the gap between pure supervision and self-supervision.
Architecture: CNN based methods (PoseCNN, Dense-Fusion) [8] [9] dominated early deep learning approaches. Transformer-based architectures capture global context and long range dependencies. Point cloud networks (PointNet, PointNet++) [10] process 3D geometric data directly. VFM based approaches leverage pre-trained vision transformers with billions of parameters, representing the current frontier.
This taxonomy reveals that VFM aided methods represent a convergence point: they primarily use RGB input, produce multiple output representations (keypoints, dense features, direct pose), leverage self-supervised pre-training at scale, and employ transformer architectures. Our work positions CLIP and DINOv2 within this taxonomy as representatives of language grounded and pure visual self-supervised paradigms, respectively.
Traditional methods for estimating 6D poses depended on template matching [11] and manually created features (SIFT, SURF). The best method for determining pose from 2D-3D correspondences [6] is still the PnP algorithm. However, strong occlusion and textureless objects are difficult for these techniques to handle.
While later research investigated dense correspondence (DenseFusion), point cloud processing (PointNet) [10], and differentiable rendering, PoseCNN [8] pioneered end-to-end learning for 6D pose. CNN feature extraction and physics based refinement are combined in recent hybrid techniques.
Using 400 million image text pairs, CLIP develops transferable visual representations that allow for semantic reasoning [12] and zero-shot recognition. DINOv2 uses self-supervised learning on 142M photos to produce state-of-the-art performance on dense prediction challenges. Although both models are excellent in their respective fields, it is still unclear how to incorporate them into pipelines for 3D pose estimation.
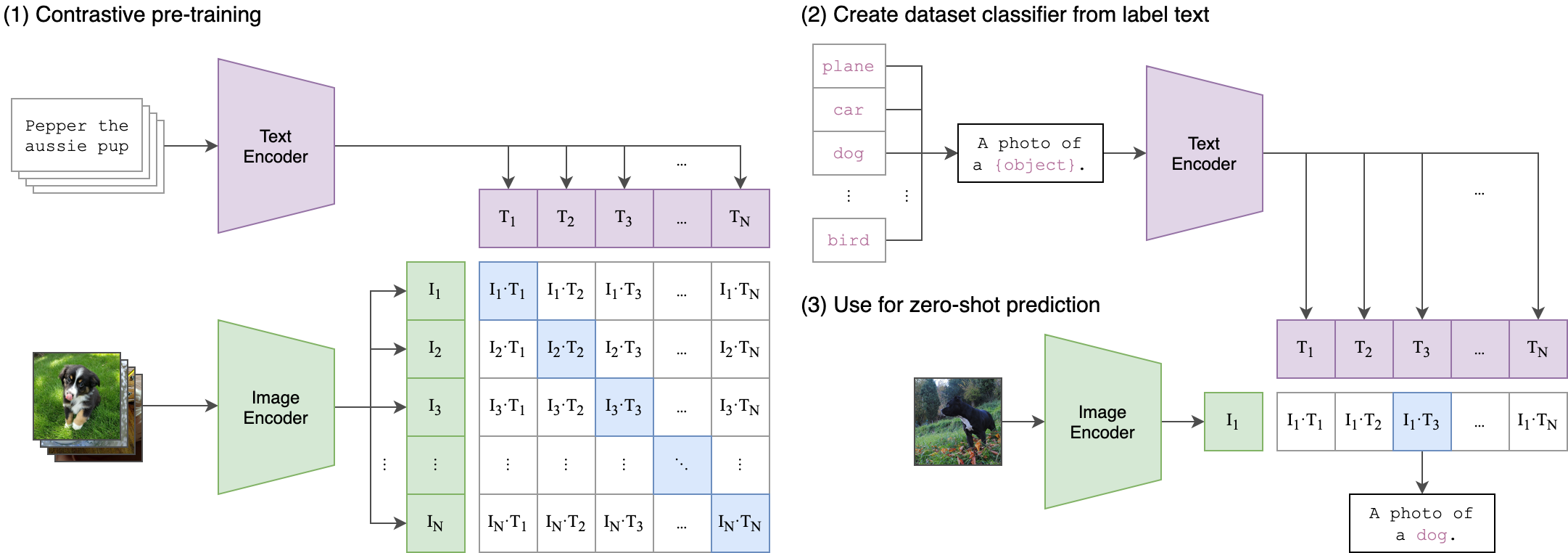
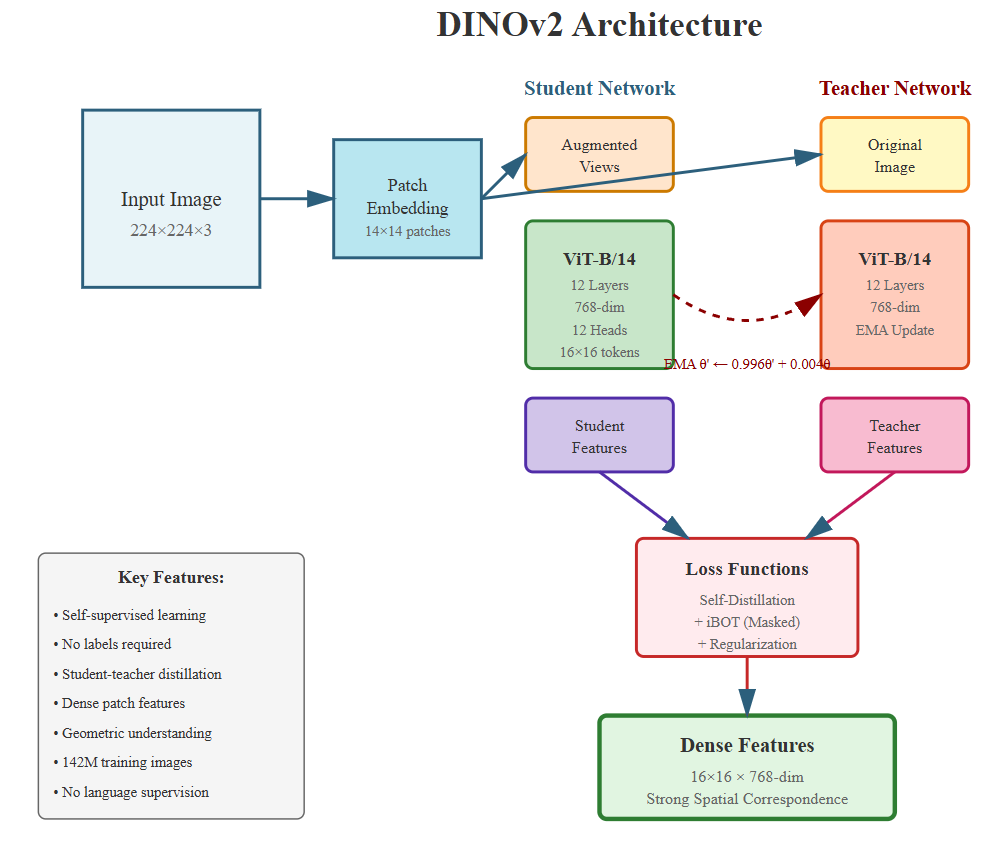
Given an RGB image I ∈ R H×W ×3 containing an object of interest, our goal is to estimate the 6D pose T = [R|t] ∈ SE(3), where R ∈ SO(3) is the rotation matrix and t ∈ R 3 is the translation vector. [13] CLIP (Figure 1) employs a dual-encoder architecture trained through contrastive learning on 400M image-text pairs, producing semantically-aligned visual and language representations. DINOv2 (Figure 2) leverages self-supervised learning on 142M images through self-distillation, generating dense
The CLIP-
This content is AI-processed based on open access ArXiv data.