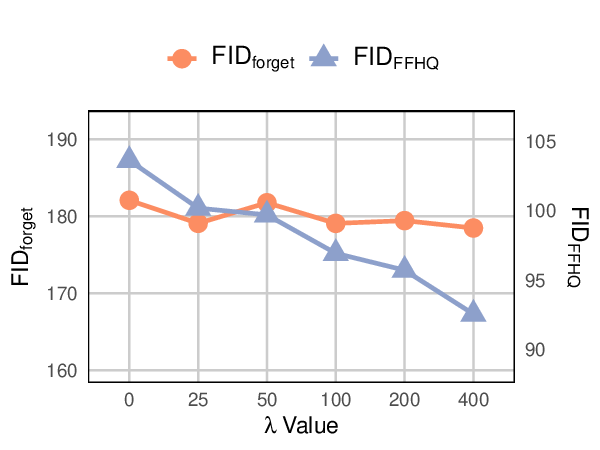
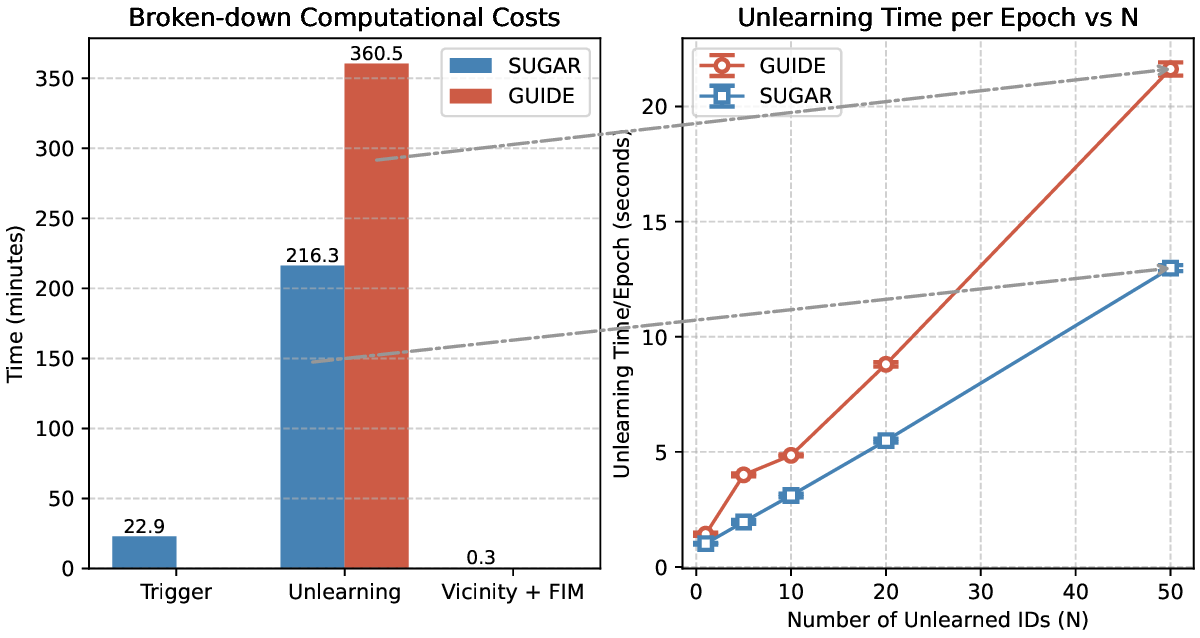
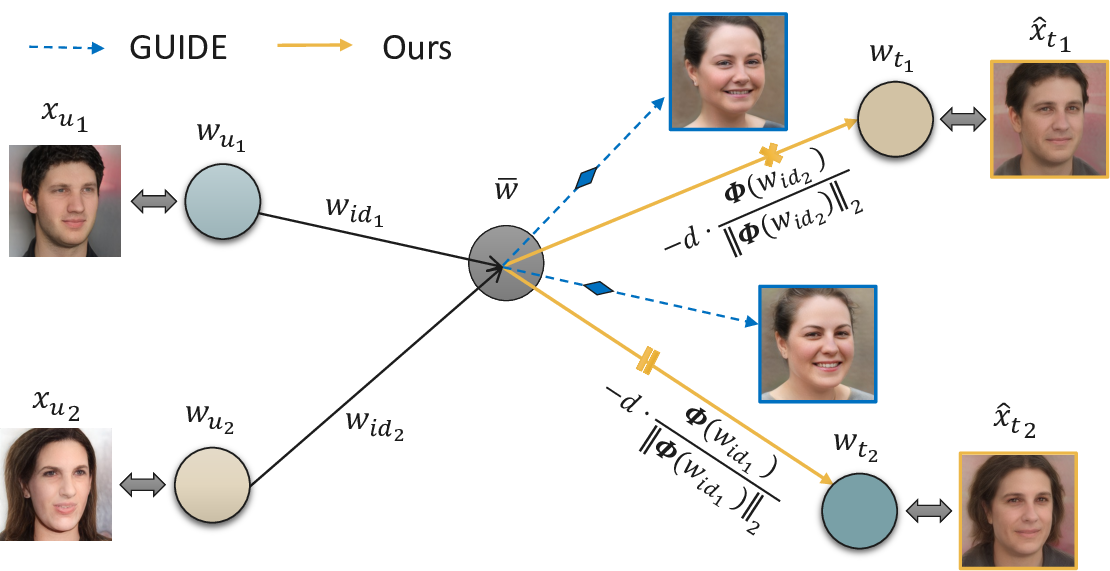
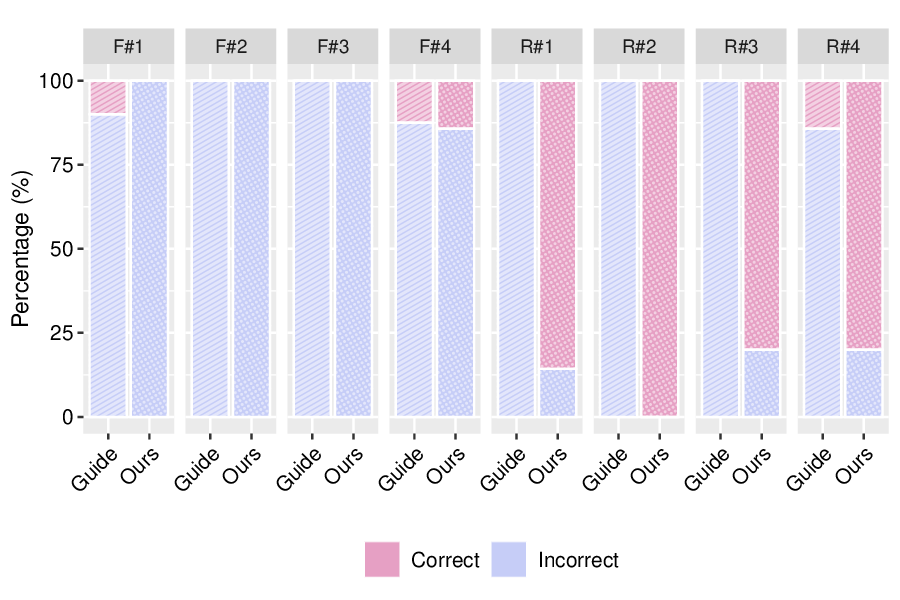
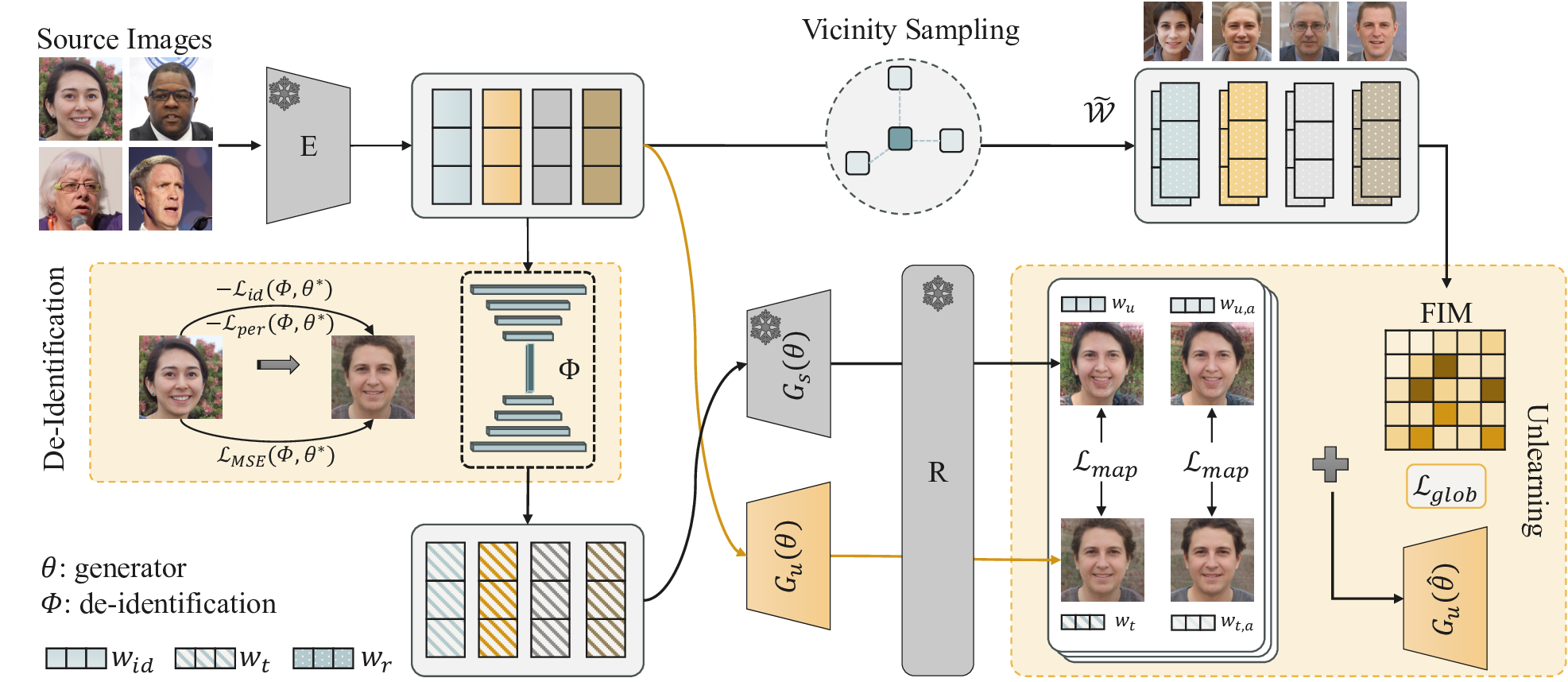
Recent advances in 3D-aware generative models have enabled high-fidelity image synthesis of human identities. However, this progress raises urgent questions around user consent and the ability to remove specific individuals from a model's output space. We address this by introducing SUGAR, a framework for scalable generative unlearning that enables the removal of many identities (simultaneously or sequentially) without retraining the entire model. Rather than projecting unwanted identities to unrealistic outputs or relying on static template faces, SUGAR learns a personalized surrogate latent for each identity, diverting reconstructions to visually coherent alternatives while preserving the model's quality and diversity. We further introduce a continual utility preservation objective that guards against degradation as more identities are forgotten. SUGAR achieves state-of-the-art performance in removing up to 200 identities, while delivering up to a 700% improvement in retention utility compared to existing baselines. Our code is publicly available at https://github.com/judydnguyen/SUGAR-Generative-Unlearn.
Despite the undeniable benefits of generative AI across various domains such as image synthesis and content creation [22,25,45,49], growing concerns have emerged regarding their potential misuse and unintended consequences [8,50,51]. In particular, generative models can inadvertently memorize and reproduce identifiable faces or proprietary images from their training data, posing significant risks to intellectual property rights and personal privacy [6,16,35].
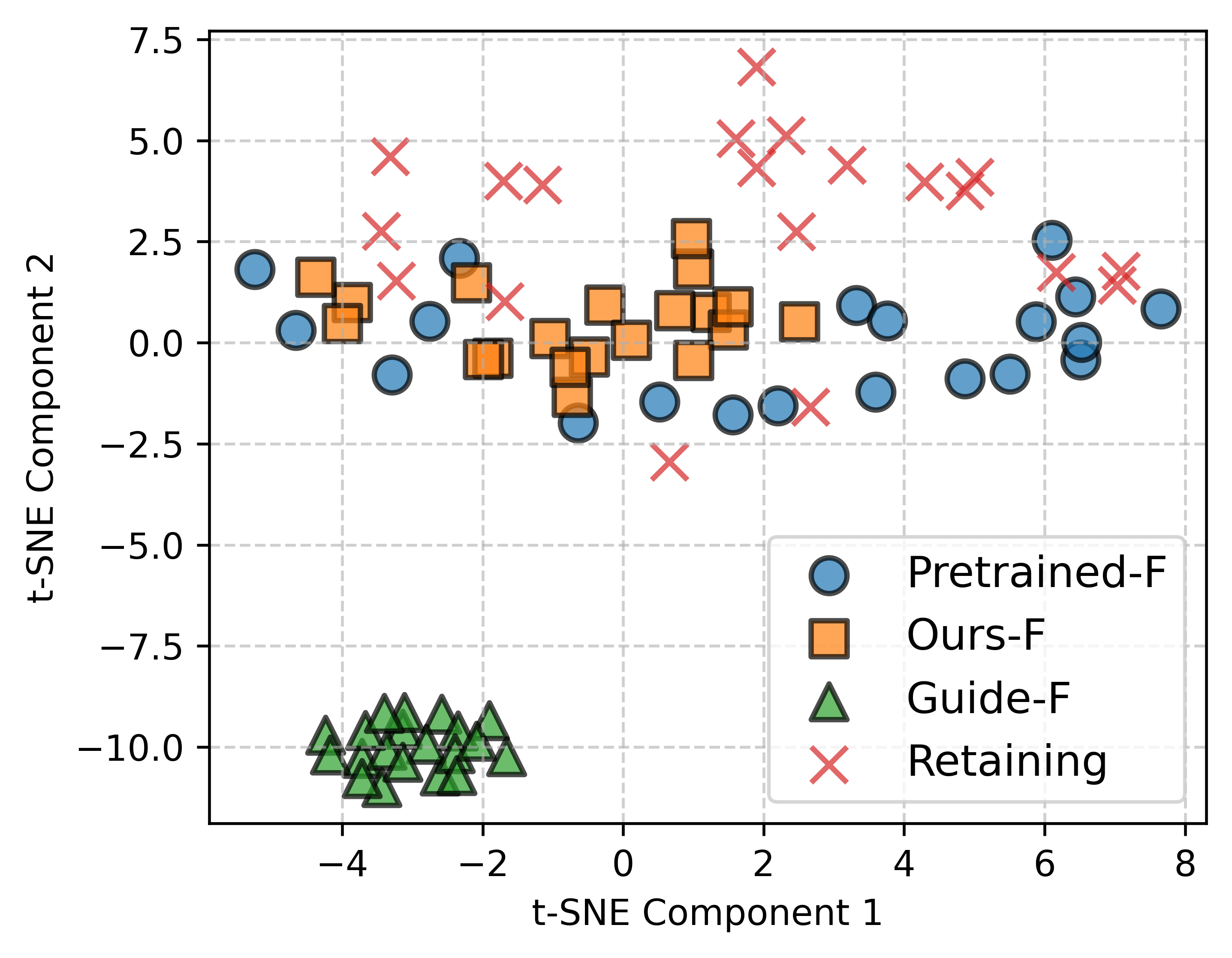
These issues have urged the right to be forgotten [32,46], a movement supporting individuals’ ability to request the removal of personal data (e.g., images of one’s face) from digital systems like AI models. While possible to remove requested images from training sets, retraining models from Our method effectively removes the specified identities from the generative model while maintaining the quality and distinctiveness of the retained identities. In contrast, the baseline (GUIDE) method causes noticeable degradation in the retained identities. scratch is computationally impractical, especially if there are multiple requests over time [24,42].
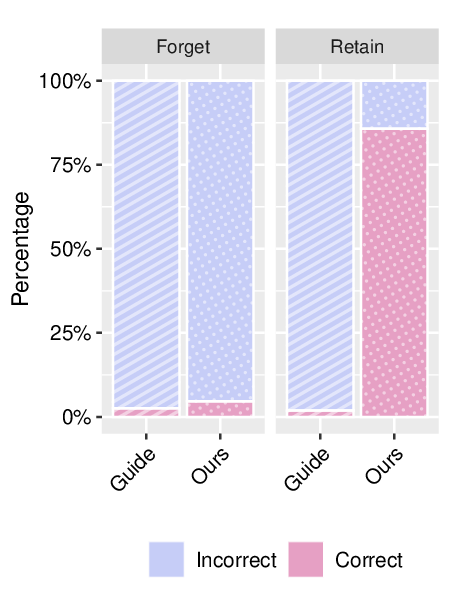
To address the growing need for post-hoc data removal, recent work has explored generative unlearning-the task of removing specific information from pretrained generative models without retraining from scratch [2,14,33,47]. Approaches vary in how they suppress unwanted identities. Selective Amnesia [14] targets diffusion and VAE-based models, using continual learning techniques to push erased concepts into noise-like outputs. GUIDE [33], the first to address Generative Identity Unlearning (GUI) in GANs, instead manipulates the latent space by redirecting target embeddings toward a fixed mean identity representation. As illustrated in Figure 1, both methods demonstrate initial effectiveness for single-identity removal but face key limitations: (a) they lack support for forgetting multiple identities at once or over time; (b) their suppression mechanisms-mapping to noise or an average face-may leak information about the forgotten identity; and (c) they often degrade unrelated generations, causing semantic drift in retained identities. For example, in GUIDE, retained faces in the Baseline row of Figure 1 begin to converge toward the median face, reducing output diversity and model utility.
Toward this end, we present SUGAR, which is capable of securely removing multiple identities while maintaining arXiv:2512.06562v1 [cs.CV] 6 Dec 2025 the usability of the model. Unlike previous approaches that introduce artifacts or distortions, SUGAR ensures that forgotten identities are effectively erased without compromising the fidelity, diversity, or usability of the model’s outputs. The contributions of this work, therefore, are the following: 1. We introduce SUGAR, which-to the best of our knowledge-is the first GUI method to address multipleidentity unlearning and sequential unlearning within the context of generative AI. 2. We demonstrate the effectiveness of our approach over SOTA methods using Identity Similarity (ID) and Fréchet Inception Distance (FID) quantitative metrics, achieving up to a 700% improvement over baselines in maintaining model utility. Furthermore, our qualitative analysis and human judgment study reinforce these findings, showing that our method effectively unlearns multiple target identities while preserving the visual quality of retained identities. 3. We conduct extensive ablation studies to evaluate controllable unlearning, identity retention, utility preservation, and privacy enhancement, highlighting our method’s advantages: (i) effectiveness in forgetting and retention; (ii) learnable and automatic determination of new identities for each forgotten identity; and (iii) privacy preservation throughout the unlearning process.
Mitigating Misuse of Generative Models. As generative models continue to advance in their ability to synthesize and manipulate highly realistic images, concerns about ethical misuse have intensified. The integration of powerful image editing techniques-such as latent space manipulation [34], language-guided editing [28], and photorealistic face retouching [43]-has made it increasingly accessible for users to modify images of real individuals or apply stylistic transformations [36]. More alarmingly, recent studies have shown that these models can be exploited to extract memorized, copyrighted training data [3], often without the consent of the individuals or content owners involved. One of the most pressing risks is the unauthorized synthesis of a person’s likeness in misleading or harmful contexts, such as deepfakes or defamatory media [1,26,30].
To counter this, Thanh et al. [39] developed an adversarial attack against UNet, effectively corrupting generated images. Other works in the concept erasure domain focus on eliminating certain visual concepts. For example, Gandikota et al. [9] were among the first to introduce removing specific concepts from diffusion models us
This content is AI-processed based on open access ArXiv data.