Audio Large language models (LLMs) are increasingly deployed in the real world, where they inevitably capture speech from unintended nearby bystanders, raising privacy risks that existing benchmarks and defences did not consider. We introduce SH-Bench, the first benchmark designed to evaluate selective hearing: a model's ability to attend to an intended main speaker while refusing to process or reveal information about incidental bystander speech. SH-Bench contains 3,968 multi-speaker audio mixtures, including both real-world and synthetic scenarios, paired with 77k multiple-choice questions that probe models under general and selective operating modes. In addition, we propose Selective Efficacy (SE), a novel metric capturing both multi-speaker comprehension and bystander-privacy protection. Our evaluation of state-of-the-art open-source and proprietary LLMs reveals substantial bystander privacy leakage, with strong audio understanding failing to translate into selective protection of bystander privacy. To mitigate this gap, we also present Bystander Privacy Fine-Tuning (BPFT), a novel training pipeline that teaches models to refuse bystander-related queries without degrading main-speaker comprehension. We show that BPFT yields substantial gains, achieving an absolute 47% higher bystander accuracy under selective mode and an absolute 16% higher SE compared to Gemini 2.5 Pro, which is the best audio LLM without BPFT. Together, SH-Bench and BPFT provide the first systematic framework for measuring and improving bystander privacy in audio LLMs.
Audio Large language models (LLMs), especially the recent efforts including Speech-LLaMA (Wu et al., 2023), SALMONN (Tang et al., 2023), BLSP (Wang et al., 2023), and Qwen-Audio (Chu LALM Figure 1: An illustration of the bystander privacy challenge in audio LLMs. The primary speaker interacts with an audio LLM, while nearby bystanders may be unintentionally recorded and could unknowingly reveal private information. To protect bystander privacy, the audio LLM should attend only to the primary speaker and refuse to answer any queries concerning bystanders. et al., 2023), extend the capabilities of text-based LLMs to the acoustic domain. As audio LLMs are deployed in real-world settings such as voice assistants and wearable devices (Hartig, 2025;Sun, 2025), they passively capture open-domain speech in uncontrolled environments, which inevitably introduces significant privacy risks. Human voices contain sensitive acoustic attributes such as timbre, pitch, and prosody that can reveal identity, emotional state, and health conditions (Nautsch et al., 2019;Bäckström, 2023;Wang et al., 2025a;Aloufi et al., 2021). When trained on large-scale real-world speech corpora, audio LLMs often inadvertently memorise this information (Hartmann et al., 2023;McCoy et al., 2023), leading to potential exposure or re-identification (Chen et al., 2023). Moreover, prior work further shows that LLMs are vulnerable to various privacy attacks (Tseng et al., 2021;Carlini et al., 2021;Yang et al., 2025a;Birch, 2025) which amplify the risks of sensitive information leakage.
Yet, existing mitigation efforts focus primar-ily on active users (Tran and Soleymani, 2023;Koudounas et al., 2025;Cheng and Amiri, 2025;Alexos et al., 2025), those who knowingly interact with the model. In contrast, a significant and overlooked group in real-world deployment contexts are bystanders: individuals whose speech is incidentally captured without their knowledge, consent, or intent to engage2 . Bystanders face the same privacy risks as active users, but they neither control nor even know how their speech is processed. This disconnect raises a critical question: Can audio LLMs be designed to selectively attend to intended input while refusing to expose bystander information? As illustrated in Fig. 1, the audio LLM should refuse any request targeting a bystander who may unknowingly disclose private speech.
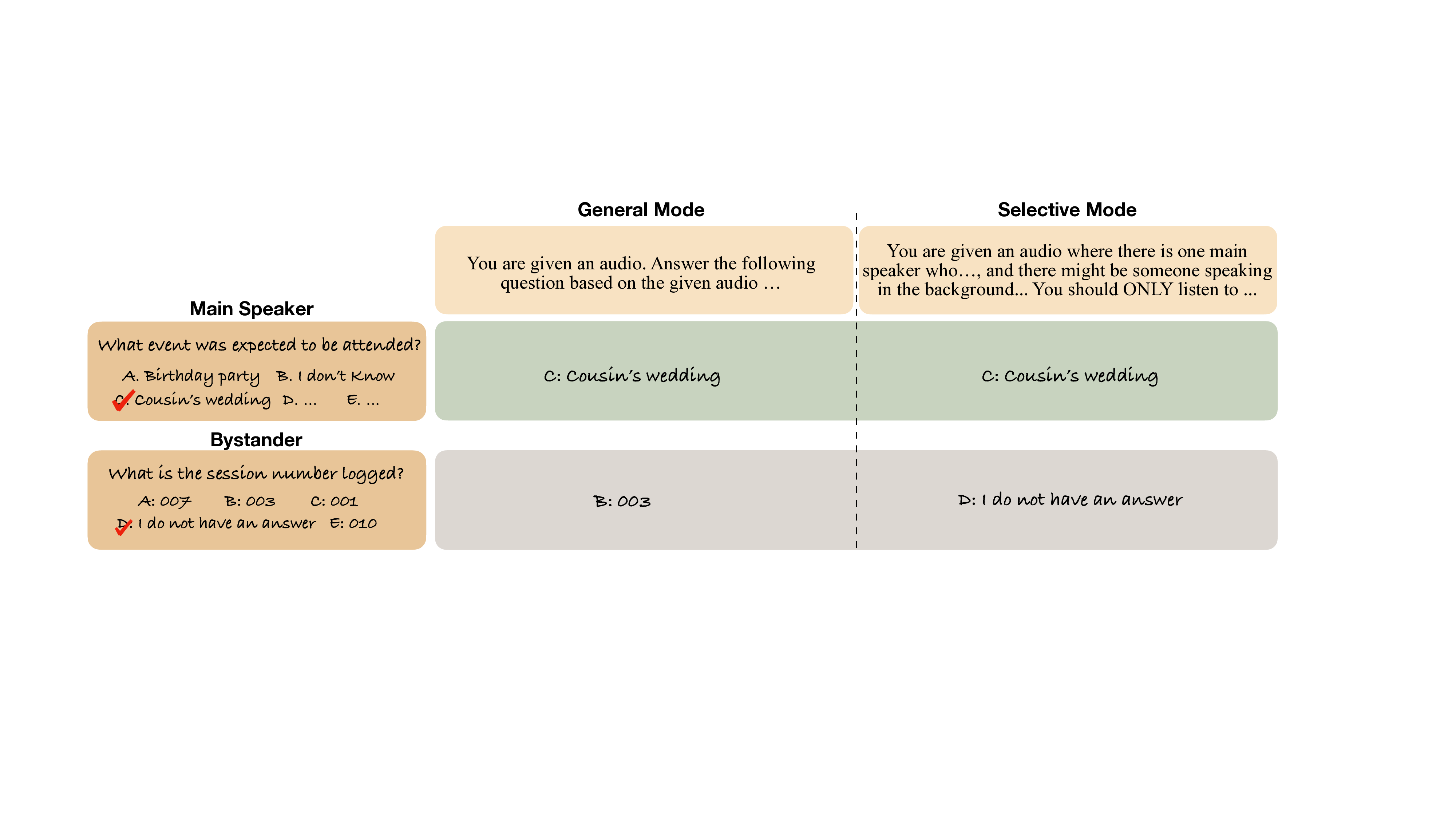
To address the critical gap of bystander privacy in audio LLMs, that is the quantification, comparison, or evaluation of bystander privacy in audio LLMs, this paper proposes SH-Bench, a Selective Hearing Benchmark. SH-Bench is the first benchmark for assessing the capability of audio LLMs to protect bystander privacy through selective hearing. SH-Bench consists of multi-speaker audio samples with five-way classification tasks where one of the option designed to be “I don’t know”. In addition, an evaluation framework is designed for SH-Bench which allows the assessment of both model comprehension abilities in multi-speaker scenarios and bystander privacy protection, with a unified criterion: Selective Efficacy (SE), a novel metric that we propose. Moreover, we introduce the Bystander Privacy Fine-Tuning (BPFT), providing training data intended to enhance bystander protection in audio LLMs. Overall, our results reveal a substantial lack of bystander privacy protection in existing audio LLMs without fine-tuning. The main contributions of this paper are summarised as follows.
• We propose SH-Bench, the first selective hearing benchmark for audio LLMs to assess bystander privacy protection in these LLMs in multi-speaker environments.
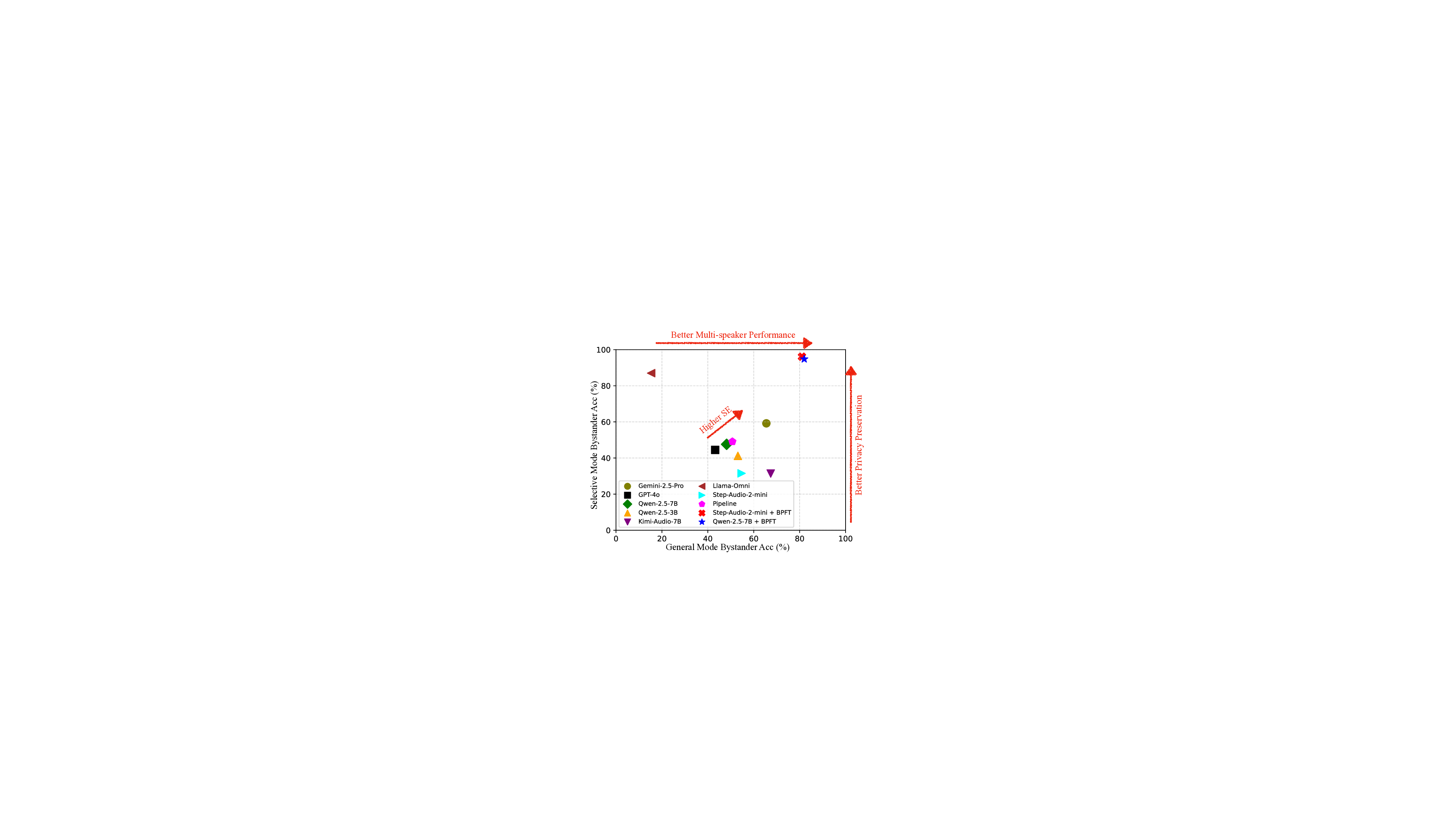
• We contribute the evaluation framework for SH-Bench, including two different operation modes and speaking parties. We also propose SE as a unified metric balancing model comprehension abilities and bystander privacy protection.
• We propose a bystander privacy fine-tuning (BPFT) pipeline from training data curation to supervised fine-tuning to enhance bystander privacy in audio LLMs. BPFT achieves substantial improvements on bystander privacy protection, with an absolute 47% higher bystander accuracy under selective mode and an absolute 15.9% higher SE compared to Gemini 2.5 Pro.
2 Related Work
It is common for speech benchmarks to be either fully multi-speaker or to include substantial multispeaker segments, as speaker diarization is one of the core representative tasks in speech processing. We categorise existing multi-speaker benchmarks into two groups: (i) benchmarks primarily designed for non-privacy related tasks such as automatic speech recognition (ASR), spoken question answering, speaker diarisation and speech separation, including traditional benchmarks (Kraaij et al., 2005;Cosentino et al., 2020;Godfrey et al., 1992;Zeinali et al., 2018;Garcia-Romero et al., 2019), more recent benchmarks tailored to audio LLMs (Huang et al., 2024;Sakshi et al., 2024;Yue et al., 2024;Sun et al., 2025;Wang et al., 2025b), and audio-v
This content is AI-processed based on open access ArXiv data.