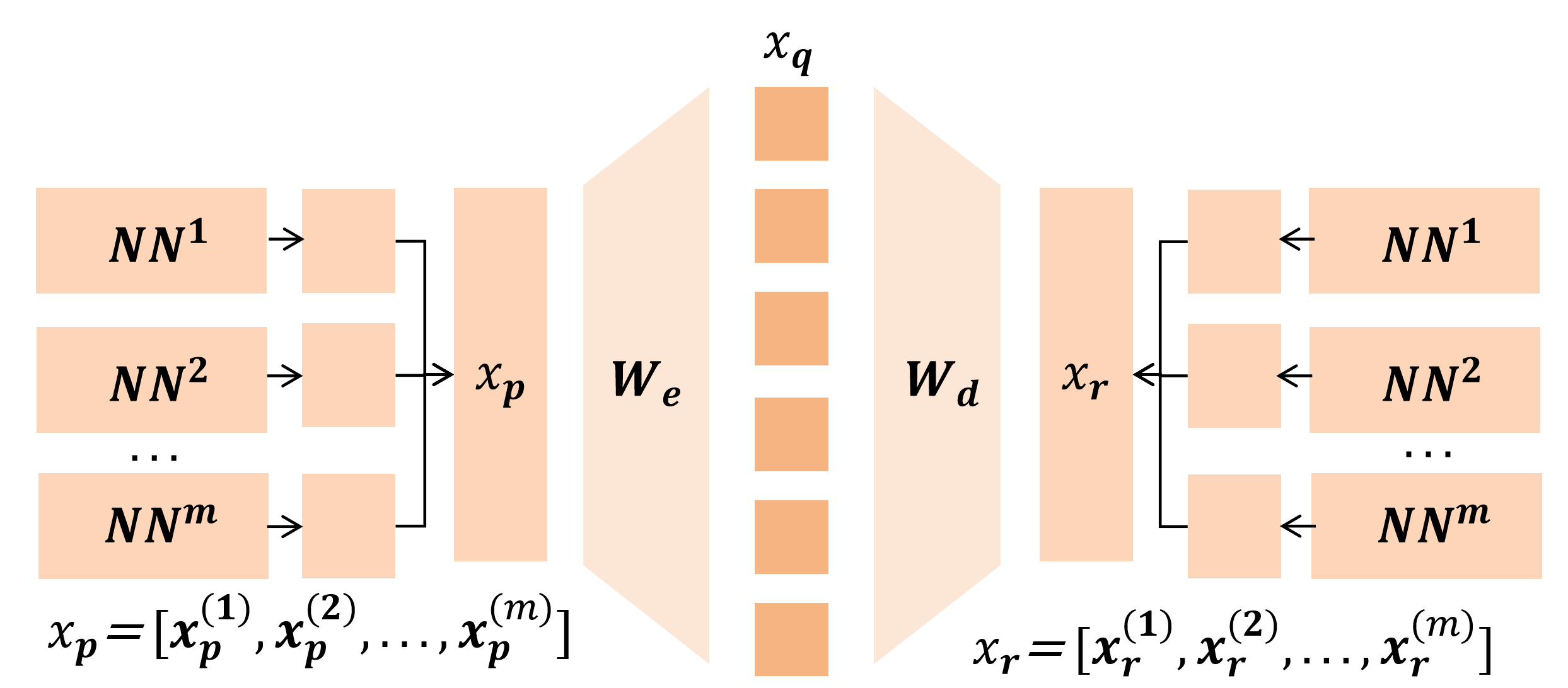As AI models achieve remarkable capabilities across diverse domains, understanding what representations they learn and how they encode concepts has become increasingly important for both scientific progress and trustworthy deployment. Recent works in mechanistic interpretability have widely reported that neural networks represent meaningful concepts as linear directions in their representation spaces and often encode diverse concepts in superposition. Various sparse dictionary learning (SDL) methods, including sparse autoencoders, transcoders, and crosscoders, are utilized to address this by training auxiliary models with sparsity constraints to disentangle these superposed concepts into monosemantic features. These methods are the backbone of modern mechanistic interpretability, yet in practice they consistently produce polysemantic features, feature absorption, and dead neurons, with very limited theoretical understanding of why these phenomena occur. Existing theoretical work is limited to tied-weight sparse autoencoders, leaving the broader family of SDL methods without formal grounding. We develop the first unified theoretical framework that casts all major SDL variants as a single piecewise biconvex optimization problem, and characterize its global solution set, non-identifiability, and spurious optima. This analysis yields principled explanations for feature absorption and dead neurons. To expose these pathologies under full ground-truth access, we introduce the Linear Representation Bench. Guided by our theory, we propose feature anchoring, a novel technique that restores SDL identifiability, substantially improving feature recovery across synthetic benchmarks and real neural representations.
As artificial intelligence systems scale to frontier capabilities, understanding their internal mechanisms has become essential for safe deployment (Lipton, 2017;Rudin, 2019). A central insight from mechanistic interpretability is that neural networks encode interpretable concepts as linear directions in superposition (Park et al., 2024;Elhage et al., 2022), where individual neurons respond to multiple unrelated concepts-a phenomenon known as polysemanticity (Bricken et al., 2023;Templeton et al., 2024). To disentangle these superposed representations, Sparse Dictionary Learning methods, including sparse autoencoders (SAEs) (Cunningham et al., 2023), transcoders (Dunefsky et al., 2024), and crosscoders (Lindsey et al., 2024), have emerged as the dominant paradigm, achieving remarkable empirical success on frontier language models (Templeton et al., 2024;Gao et al., 2024) and enabling applications from feature steering (Wang et al., 2025) to circuit analysis (Marks et al., 2025) and medical diagnosis (Abdulaal et al., 2024).
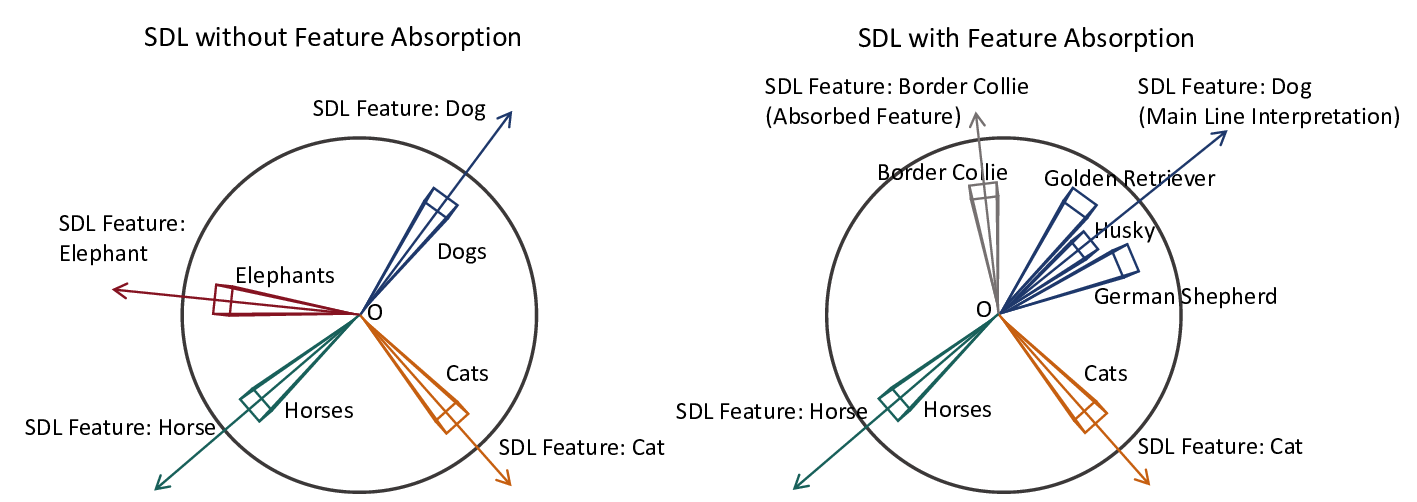
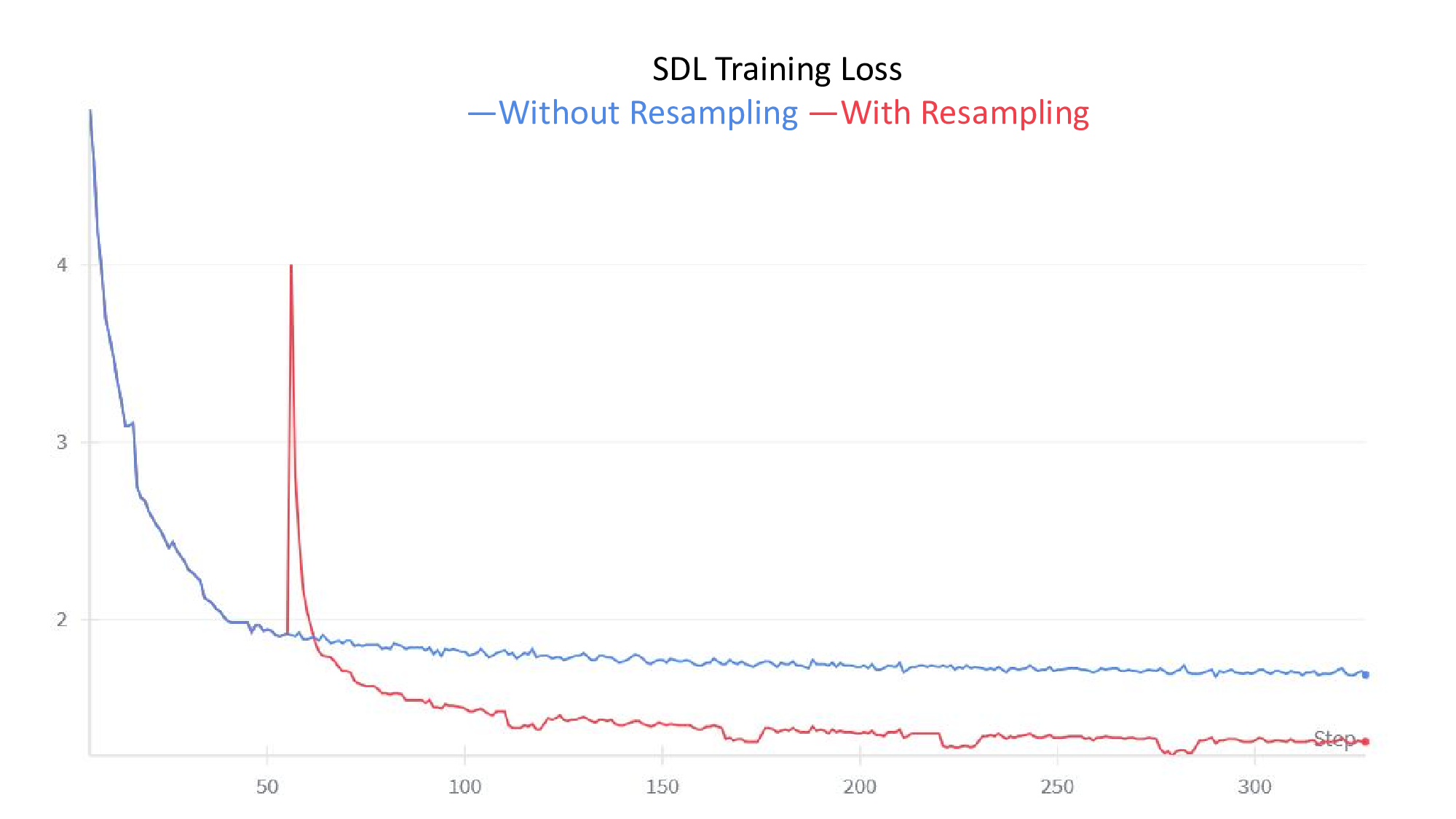
Despite this empirical success across diverse applications, SDL methods consistently exhibit persistent failure modes: learned features remain polysemantic (Chanin et al., 2025), “dead neurons” fail to activate on any data samples (Bricken et al., 2023), and “feature absorption” occurs where one neuron captures specific sub-concepts while another responds to the remaining related concepts (Chanin et al., 2025). Practitioners have developed techniques to address these issues, including neuron resampling (Bricken et al., 2023), auxiliary losses (Gao et al., 2024), and careful hyperparameter tuning, yet these fixes remain ad-hoc engineering solutions without principled justification. Critically, these phenomena persist even with careful training on clean data, suggesting they are not mere implementation artifacts but reflect fundamental structural properties of the SDL optimization problem itself.
We argue that the root cause of these failure modes is the non-identifiability of SDL methods: even under the idealized Linear Representation Hypothesis, SDL optimization admits multiple solutions achieving perfect reconstruction loss, some recovering no interpretable ground-truth features at all, necessitating comprehensive theoretical analysis on SDL methods. While classical dictionary learning theory provides identifiability guarantees under strict conditions (Spielman et al., 2012;Gribonval & Schnass, 2010), and recent work establishes necessary conditions for tied-weight SAEs (Cui et al., 2025), no unified theoretical framework explains why diverse SDL methods, SAEs, transcoders, crosscoders, and their variants, systematically fail in predictable ways. Without theoretical grounding, the development of improved SDL methods remains largely empirical, potentially leaving highly effective techniques underexplored.
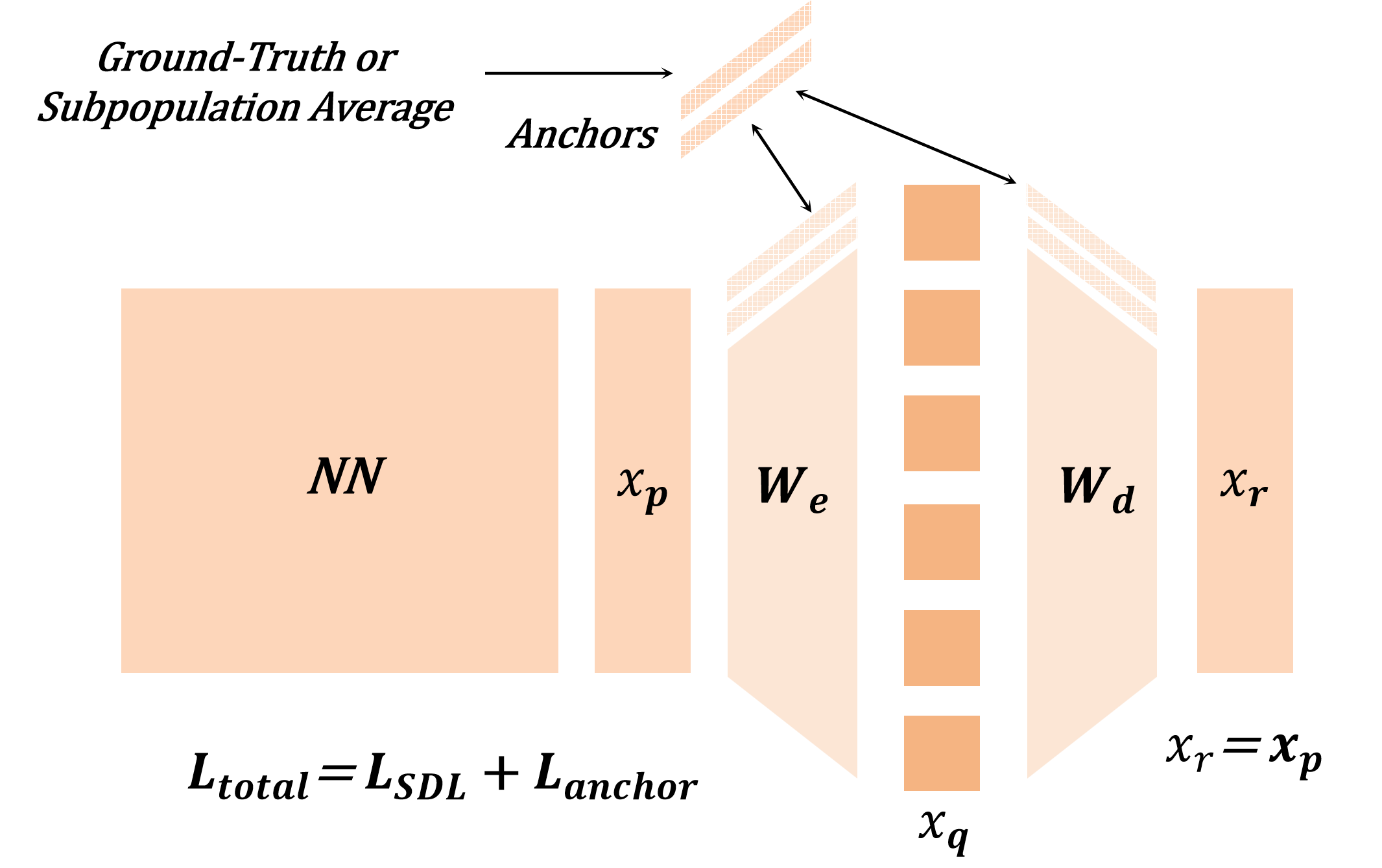
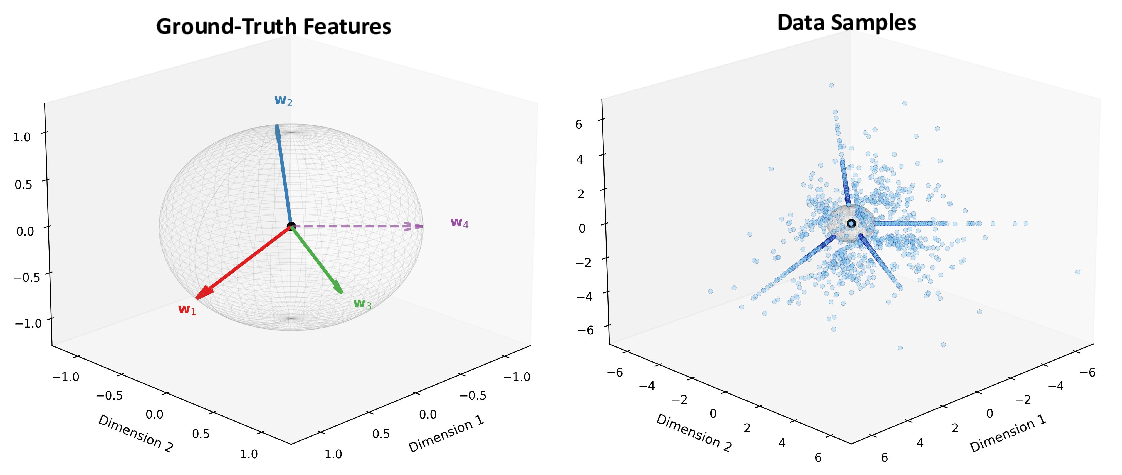
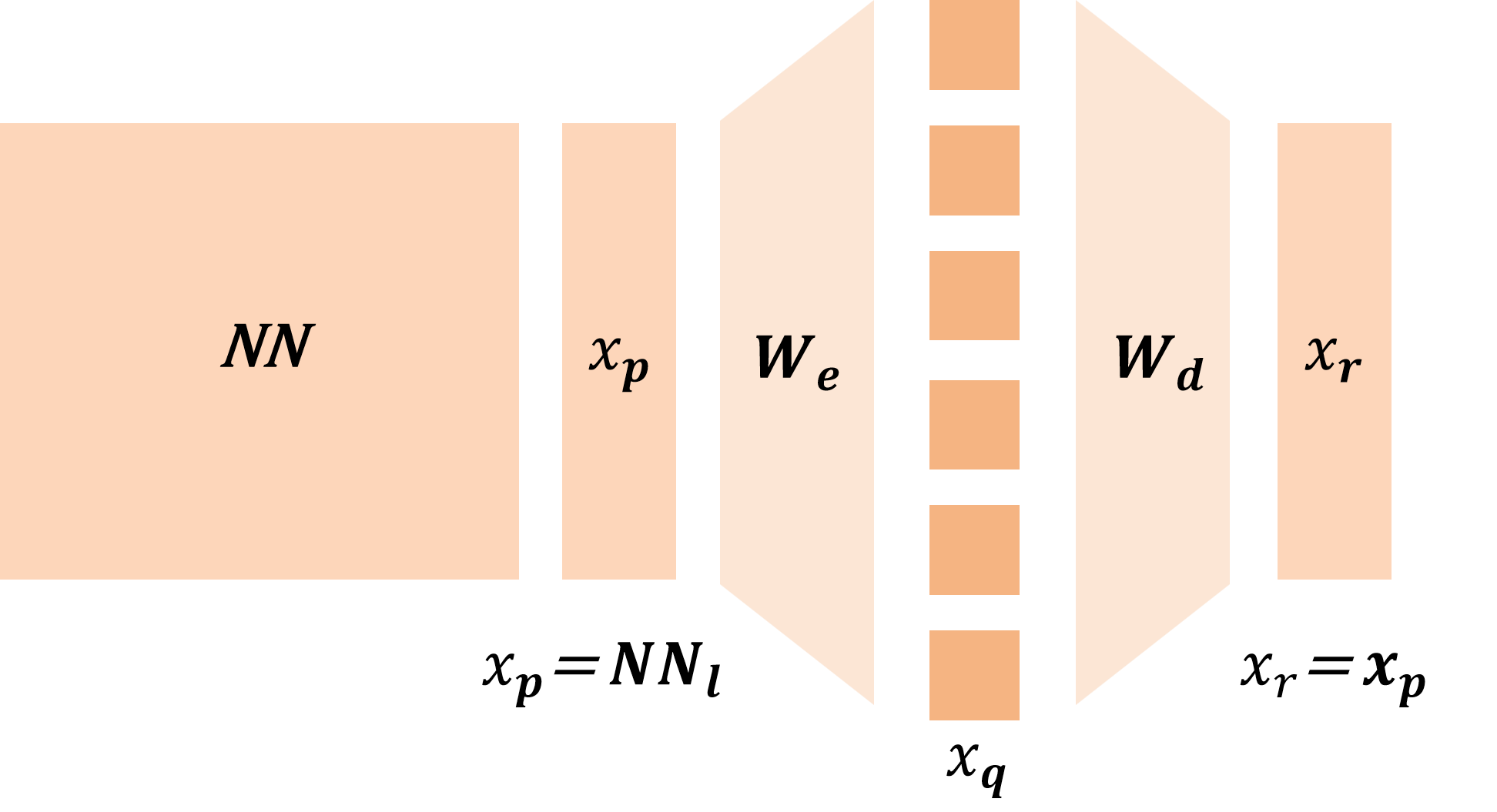
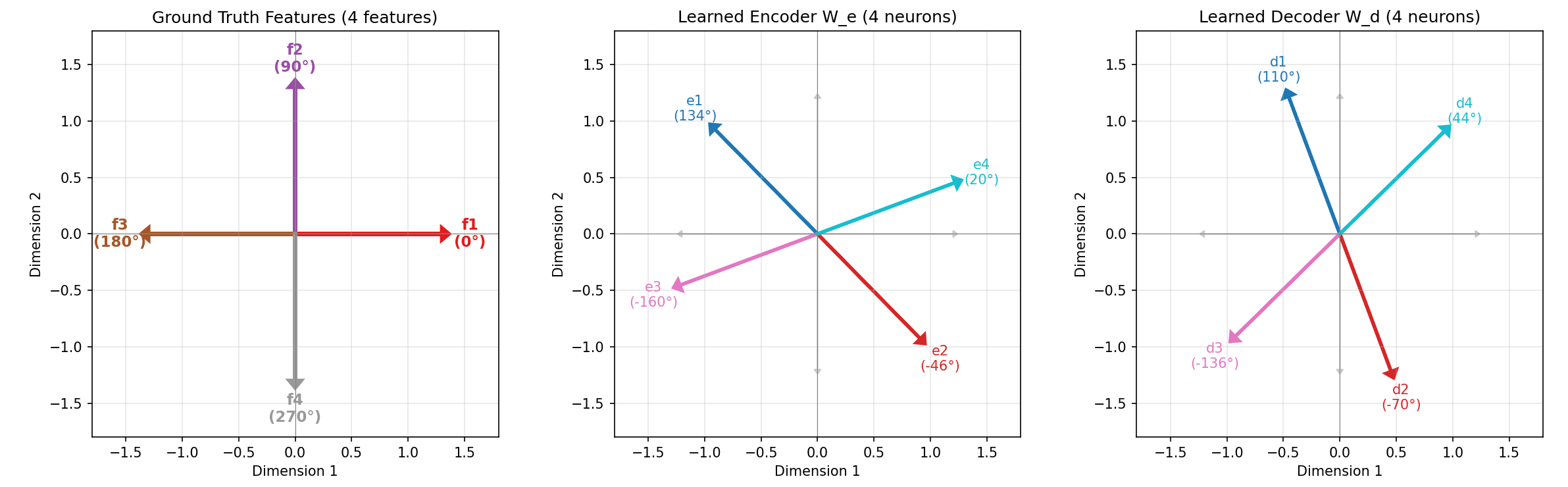
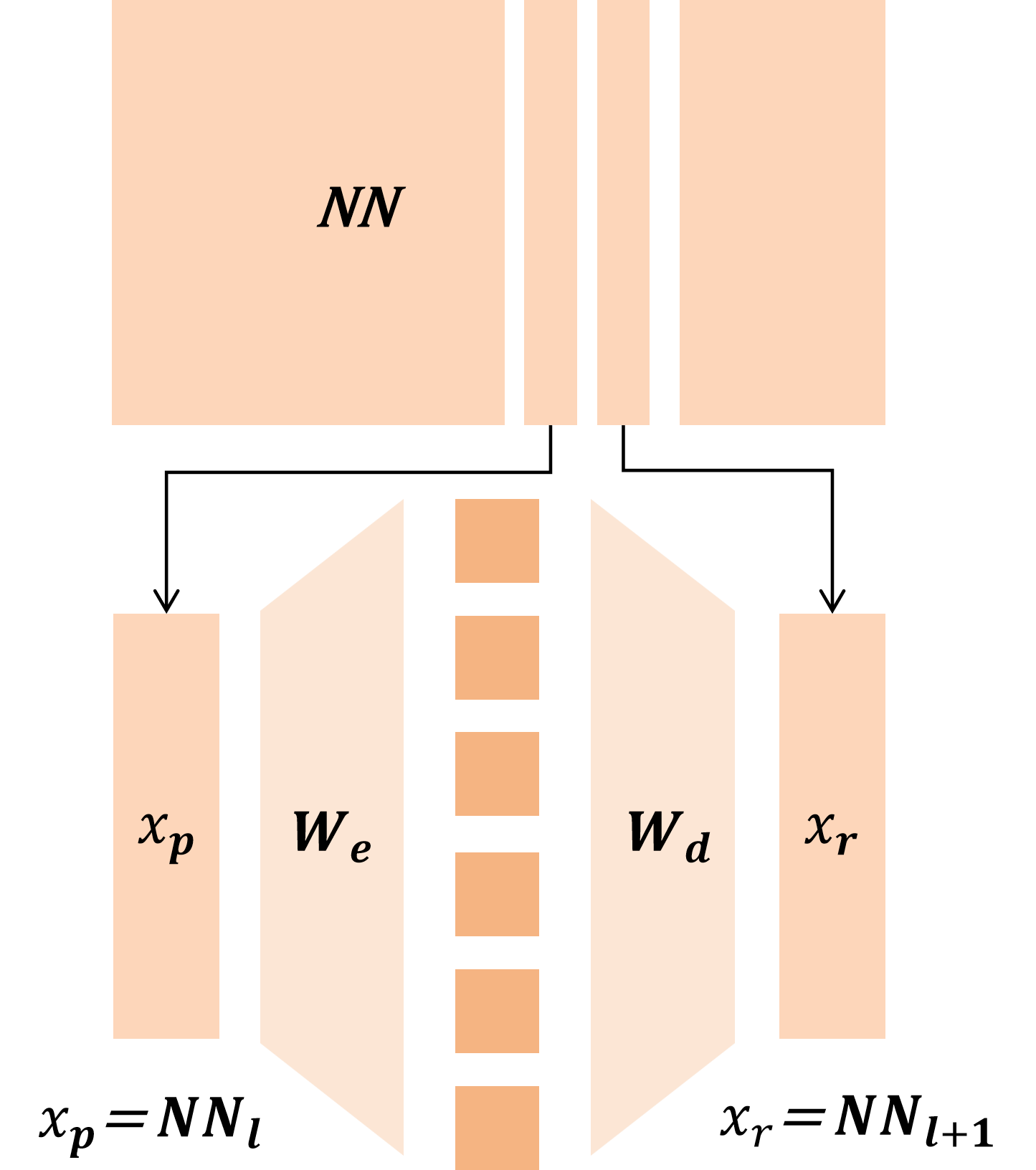
In this work, we develop a unified theoretical framework that formalizes SDL as a general optimization problem, encompassing various SDL methods (Bussmann et al., 2024;2025;Tang et al., 2025b) as special cases. We demonstrate how these diverse methods instantiate our framework through different choices of input-output representation pairs, activation functions, and loss designs. We establish rigorous conditions under which SDL methods provably recover groundtruth interpretable features, characterizing the roles of feature sparsity, latent dimensionality, and activation functions. Through detailed analysis of the optimization landscape, we demonstrate that global minima correspond to correct feature recovery and provide necessary and sufficient conditions for achieving zero loss. We establish the prevalence of spurious partial minima exhibiting un-disentangled polysemanticity, providing novel theoretical explanations for feature absorption (Chanin et al., 2025) and the effectiveness of neuron resampling (Bricken et al., 2023). We design the Linear Representation Bench, a synthetic benchmark that strictly follows the Linear Representation Hypothesis, to evaluate SDL methods with fully accessible ground-truth features. Motivated by our theoretical insights, we propose feature anchoring, a technique applicable to all SDL methods which achieves improved feature recovery by constraining learned features to known anchor directions.
Our main contributions are as follows:
• We build the first theoretical framework for SDL in mechanistic interpretability as a general optimization problem encompassing diverse SDL methods.
• We theoretically prove that SDL optimization is biconvex, bridging mechanistic interpretability methods with traditional biconvex optimization theory.
• We characterize SDL optimization landscape and prove its non-identifiability, providing novel explanations for various phenomena observed empirically.
• We design the Linear Representation Bench, a benchmark with fully accessible ground-truth features, enabling fully transparent evaluation of SDL methods.
• We propose
This content is AI-processed based on open access ArXiv data.