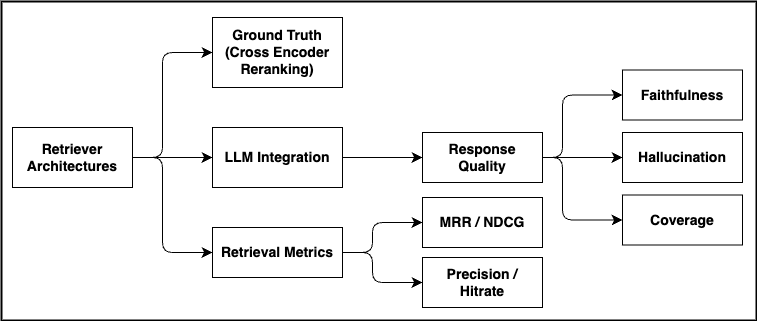
In enterprise settings, efficiently retrieving relevant information from large and complex knowledge bases is essential for operational productivity and informed decision-making. This research presents a systematic framework for metadata enrichment using large language models (LLMs) to enhance document retrieval in Retrieval-Augmented Generation (RAG) systems. Our approach employs a comprehensive, structured pipeline that dynamically generates meaningful metadata for document segments, substantially improving their semantic representations and retrieval accuracy. Through extensive experiments, we compare three chunking strategies-semantic, recursive, and naive-and evaluate their effectiveness when combined with advanced embedding techniques. The results demonstrate that metadata-enriched approaches consistently outperform content-only baselines, with recursive chunking paired with TF-IDF weighted embeddings yielding an 82.5% precision rate compared to 73.3% for semantic content-only approaches. The naive chunking strategy with prefix-fusion achieved the highest Hit Rate@10 of 0.925. Our evaluation employs cross-encoder reranking for ground truth generation, enabling rigorous assessment via Hit Rate and Metadata Consistency metrics. These findings confirm that metadata enrichment enhances vector clustering quality while reducing retrieval latency, making it a key optimization for RAG systems across knowledge domains. This work offers practical insights for deploying high-performance, scalable document retrieval solutions in enterprise settings, demonstrating that metadata enrichment is a powerful approach for enhancing RAG effectiveness.
Efficiently retrieving and leveraging information from large-scale knowledge repositories is vital for modern organizational productivity and innovation. Retrieval-Augmented Generation (RAG) systems have emerged as a powerful paradigm for enhancing Large Language Models (LLMs) by integrating external knowledge sources [21]. This approach addresses inherent limitations of LLMs, such as knowledge cut-off dates, lack of domain-specificity, and hallucinations [22].
While effective for structured datasets, traditional retrieval methods often struggle with the complexity, scale, and dynamic nature of enterprise knowledge bases. Manual curation becomes impractical as repositories expand, and these methods are prone to overlooking relevant information in lengthy contexts, resulting in the “Lost in the Middle” phenomenon.
Recent advancements in LLMs offer transformative solutions. LLMs can process unstructured data, extract meaningful insights, and generate structured metadata aligned with semantic and contextual needs. For example, Sundaram and Musen’s FAIRMetaText framework demonstrated how LLMs could align metadata with ontologies, reducing manual effort [7]. Similarly, Song et al. highlighted the potential of fewshot prompting for enriching metadata in Earth science datasets, significantly improving metadata completeness and accuracy [10].
Despite these developments, building effective RAG pipelines remains challenging, requiring management of large data volumes, optimization of retrieval strategies, and continual performance tuning.
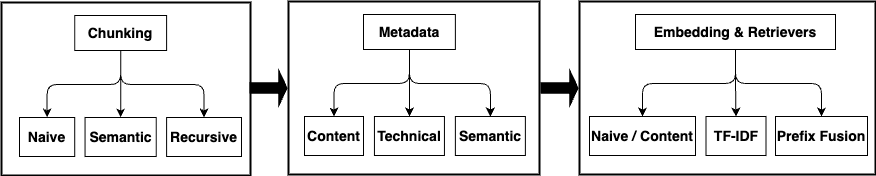
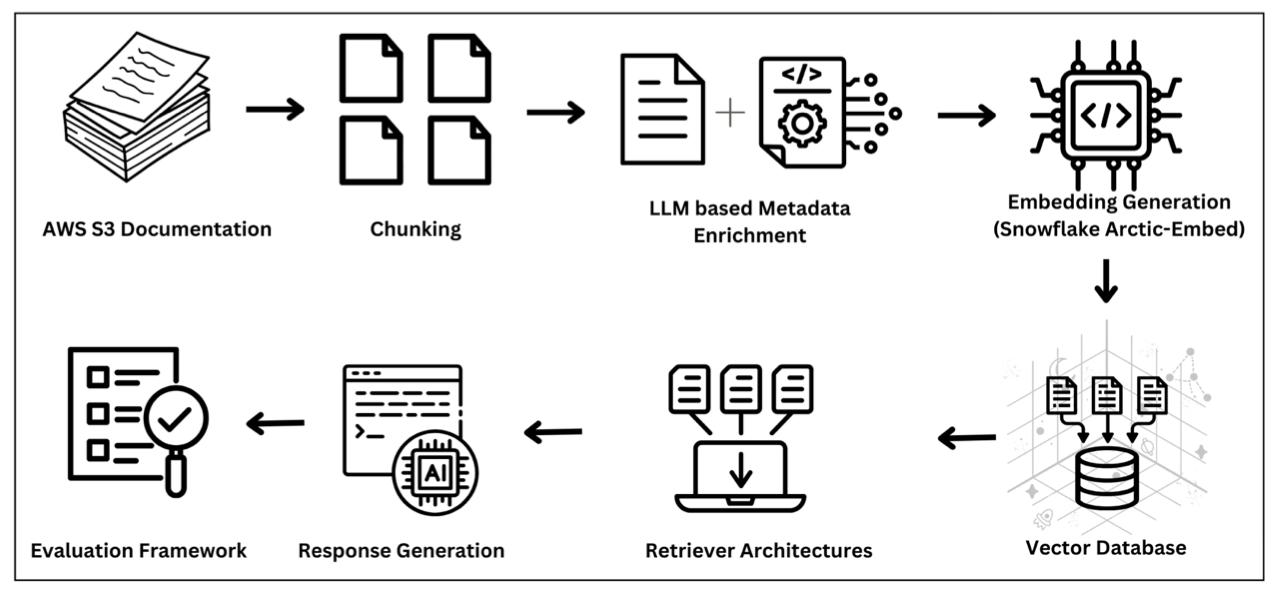
This paper presents a comprehensive, systematic framework for metadata enrichment using LLMs to optimize RAG systems in enterprise settings. Our structured pipeline dynamically generates meaningful metadata for document segments, enhancing semantic understanding and retrieval accuracy. We compare various chunking strategies-semantic, recursive, and naive-and evaluate their effectiveness with advanced embedding techniques, including TF-IDF weighting and prefix-fusion, using the Snowflake Arctic-Embed model.
Beyond methodology, we conduct an extensive experimental analysis to measure the impact of metadata enrichment on retrieval accuracy, clustering quality, and latency. Our results show that metadata-enriched retrieval outperforms contentonly approaches, achieving higher precision and hit rates while reducing latency. This framework establishes metadata enrichment as a scalable, practical optimization for RAG systems across diverse domains, providing a foundational guideline for high-performance deployment in enterprise knowledge management and technical document retrieval.
The rest of this paper is organized as follows: in Section II, we review related work in RAG, metadata enrichment, and embedding strategies. Section III details our systematic framework, covering document processing, metadata generation, embedding, retrieval architecture, and evaluation methodology. Experimental results are presented and analyzed in Section IV. Finally, Section V concludes the paper with key insights and directions for future research.
The advent of Large Language Models (LLMs) has revolutionized metadata enrichment and retrieval-augmented generation (RAG) systems. These technologies address longstanding challenges in metadata management, including inaccuracies, inconsistencies, and scalability issues. LLMs offer transformative capabilities for automating metadata structuring, refining search processes, and enhancing document retrieval. Despite these advancements, persistent challenges such as retrieval bias, hallucination in generated metadata, domain adaptability, and real-time validation continue to hinder their broader application. This review explores recent progress in metadata enrichment, RAG systems, semantic embeddings, and LLM-driven search architectures, synthesizing insights from 25 key studies.
RAG systems vary in complexity from Naive RAG, which simply indexes and retrieves document chunks, to Advanced RAG, incorporating techniques like query rewriting and reranking, to Modular RAG with configurable pipeline components [5]. Recent innovations include Agentic RAG with dynamic adaptation, GraphRAG utilizing structured knowledge representations [23], and Multimodal RAG integrating non-textual data formats. Our approach builds upon these foundations by specifically focusing on metadata enrichment to optimize retrieval precision.
Metadata serves as the backbone of information retrieval systems, yet traditional methods often struggle with unstructured datasets. Sundaram and Musen’s FAIRMetaText framework [7] aligned metadata with FAIR principles using GPTbased embeddings, though performance varied across domains. Song et al. [10] applied taxonomy-guided techniques for metadata completion in Earth sciences, while Mombaerts et al. [11] introduced Meta Knowledge Summaries, though both approaches had limitations in generalizability and dynamic adaptation. Saad-Falcon et al. [14] prop
This content is AI-processed based on open access ArXiv data.