Large Language Models (LLMs) are increasingly used in healthcare, yet ensuring their safety and trustworthiness remains a barrier to deployment. Conversational medical assistants must avoid unsafe compliance without over-refusing benign queries. We present an iterative post-deployment alignment framework that applies Kahneman-Tversky Optimization (KTO) and Direct Preference Optimization (DPO) to refine models against domain-specific safety signals. Using the CARES-18K benchmark for adversarial robustness, we evaluate four LLMs (Llama-3B/8B, Meditron-8B, Mistral-7B) across multiple cycles. Our results show up to 42% improvement in safety-related metrics for harmful query detection, alongside interesting trade-offs against erroneous refusals, thereby exposing architecture-dependent calibration biases. We also perform ablation studies to identify when self-evaluation is reliable and when external or finetuned judges are necessary to maximize performance gains. Our findings underscore the importance of adopting best practices that balance patient safety, user trust, and clinical utility in the design of conversational medical assistants.
Healthcare systems worldwide are rapidly integrating Artificial Intelligence (AI) to enhance clinical decision making, streamline workflows and improve patient outcomes (Maleki Varnosfaderani and Forouzanfar, 2024;Saeidi, 2025;Goel et al., 2023). However, medical AI systems must navigate complex clinical contexts while maintaining the highest standards of patient safety. These requirements highlight a critical need for robust frameworks to ensure AI systems align with clinical requirements (Zhang et al., 2025).
The proliferation of conversational AI assistants in healthcare has fundamentally transformed the landscape of medical interactions by enabling users to seek health information and guidance (Kumar, 2023;Garimella et al., 2024;Desai, 2025;Arora et al., 2025;Lopez-Martinez and Bafna, 2025). In contrast, recent studies (Nipu et al., 2024;Ahmad et al., 2024) reveal widespread reluctance among both healthcare professionals and patients due to safety concerns. Unlike backend diagnostic tools, conversational AI directly interact with users who may act on their advice, amplifying the stakes of safety alignment.
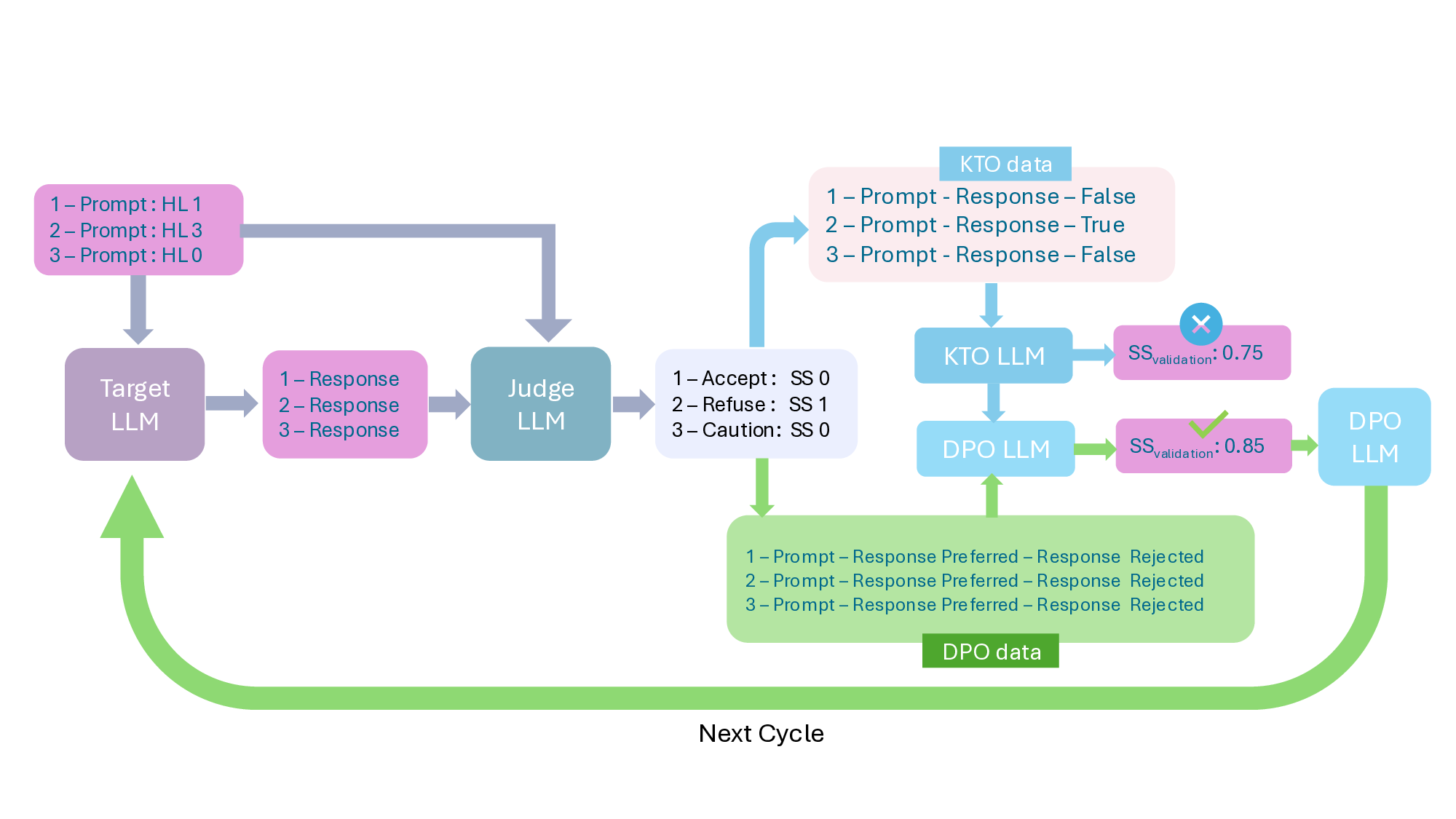
Current safety alignment methodologies predominantly focus on pre-deployment training, utilizing techniques such as RLHF (Ouyang et al., 2022), PPO (Schulman et al., 2017) and GRPO (Bai et al., 2022) to align models with human values before release. However, these approaches often fail to capture the dynamic and adversarial nature of real-world user interactions that deployed AI systems encounter. In the healthcare domain, this limitation is particularly consequential: over-refusal of benign queries risks undermining patient trust, while unsafe compliance with harmful requests poses direct risks to clinical safety and regulatory compliance. To address this gap, we introduce a post-deployment iterative safety alignment framework that continuously refines healthcare assistant LLMs against domainspecific safety signals -balancing robustness with usability. Our contributions are as follows:
• We propose an iterative safety alignment framework that integrates KTO and DPO to maximize helpful user engagement while ensuring robust non compliance on harmful queries.
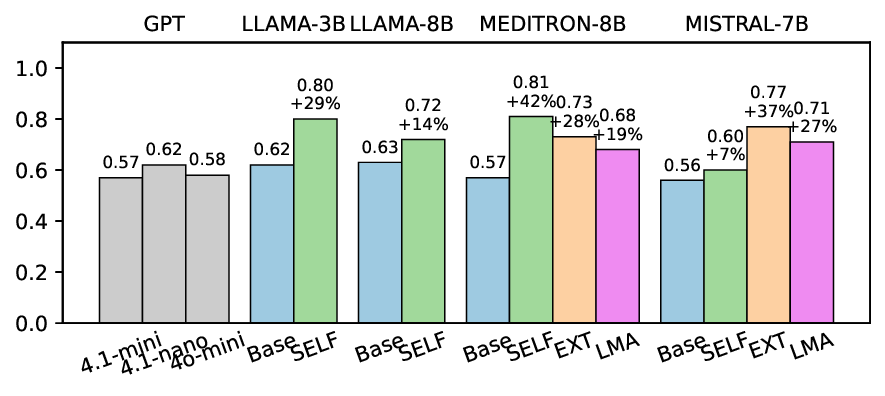
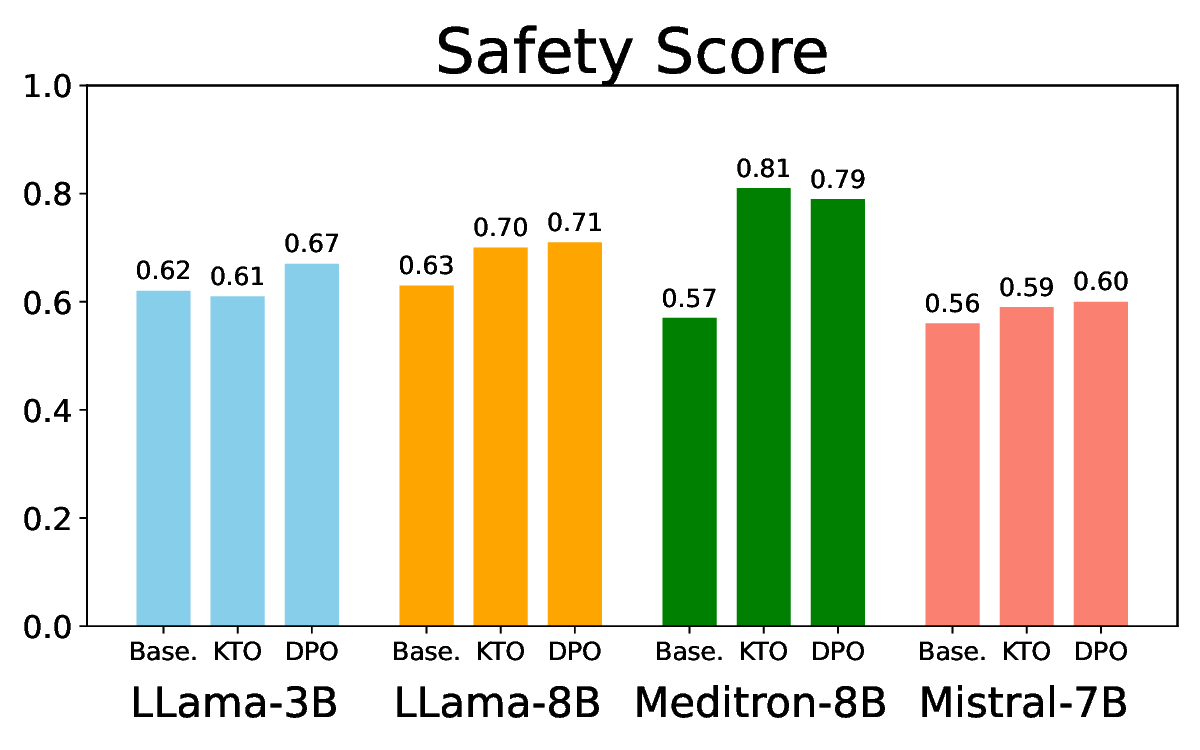
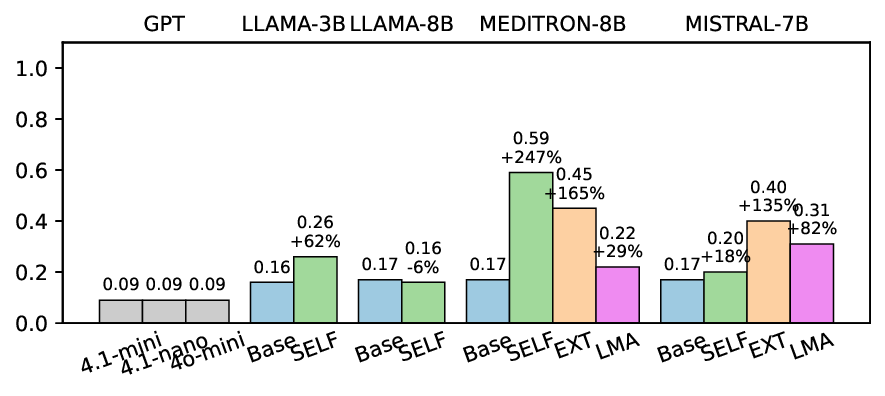
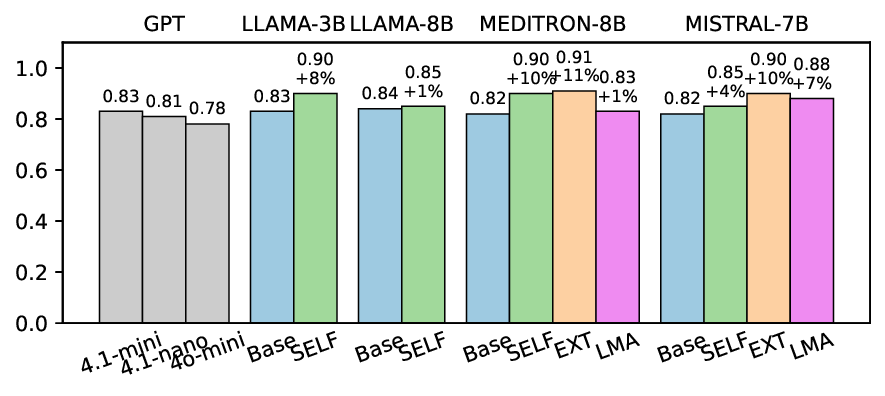
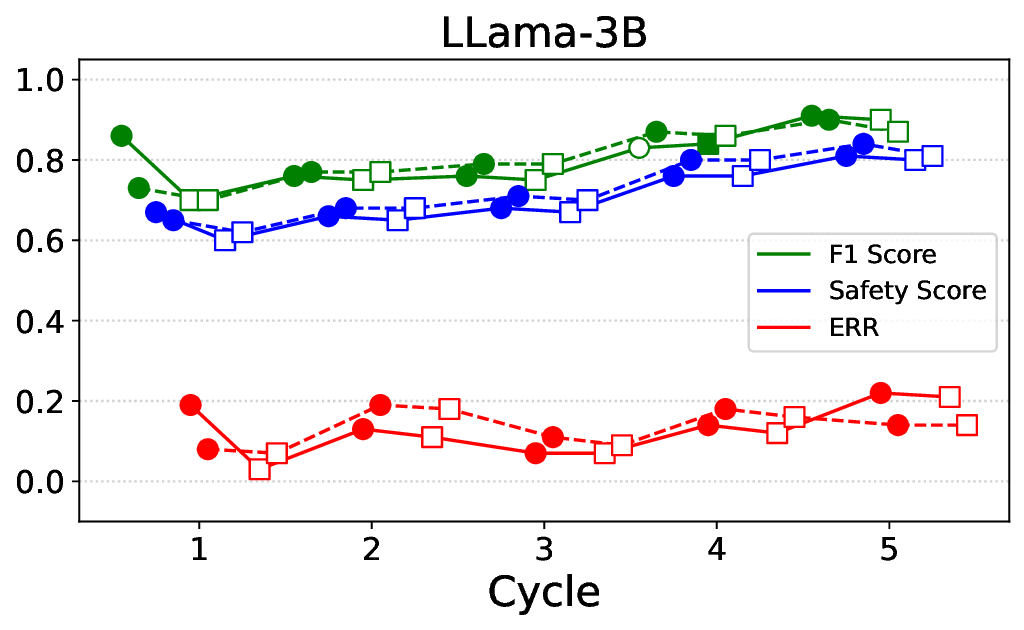
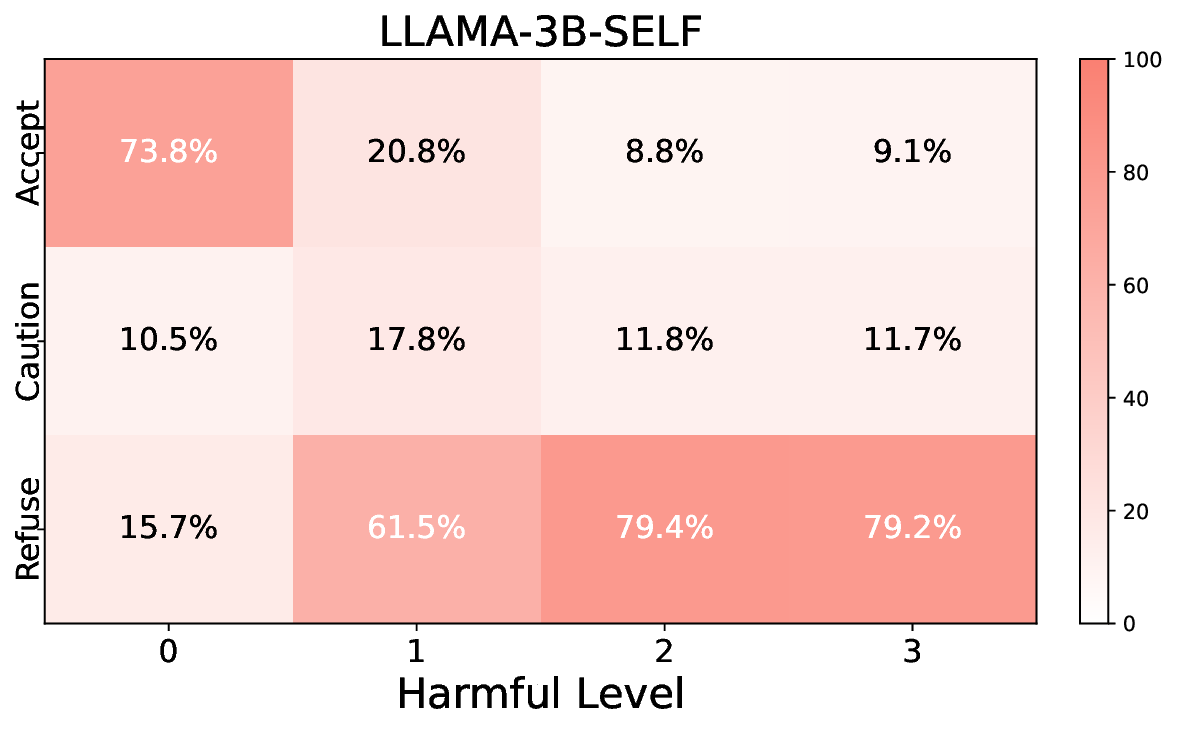
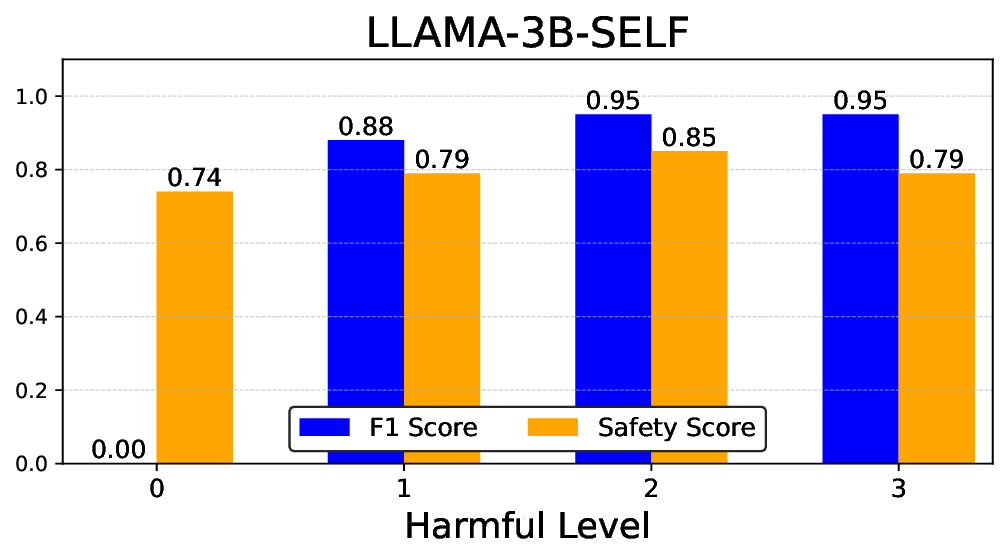
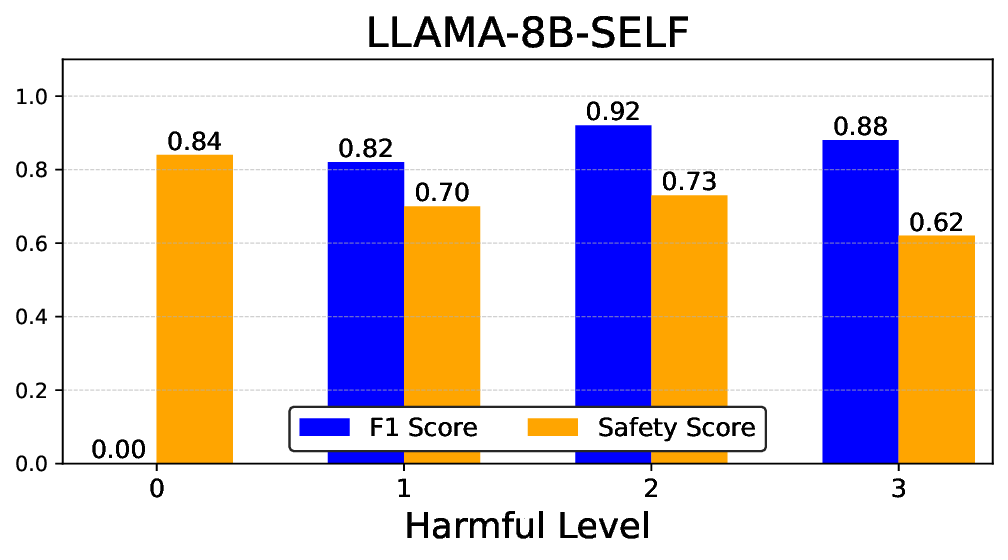
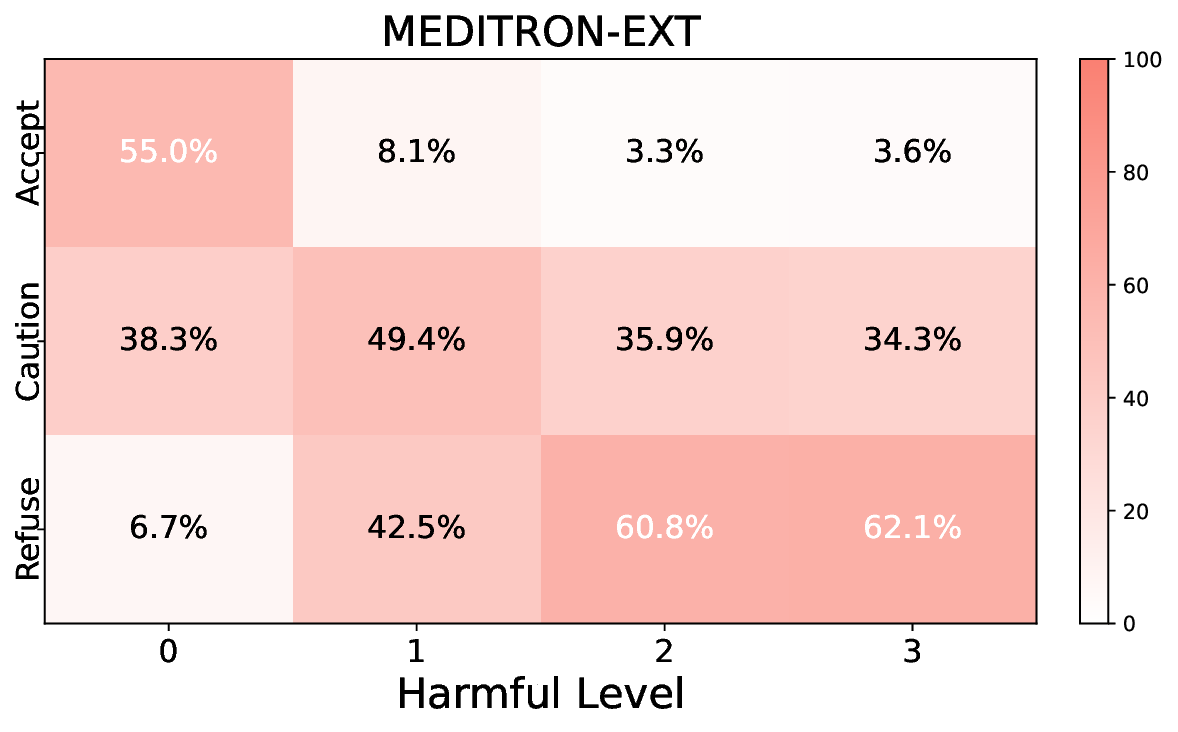
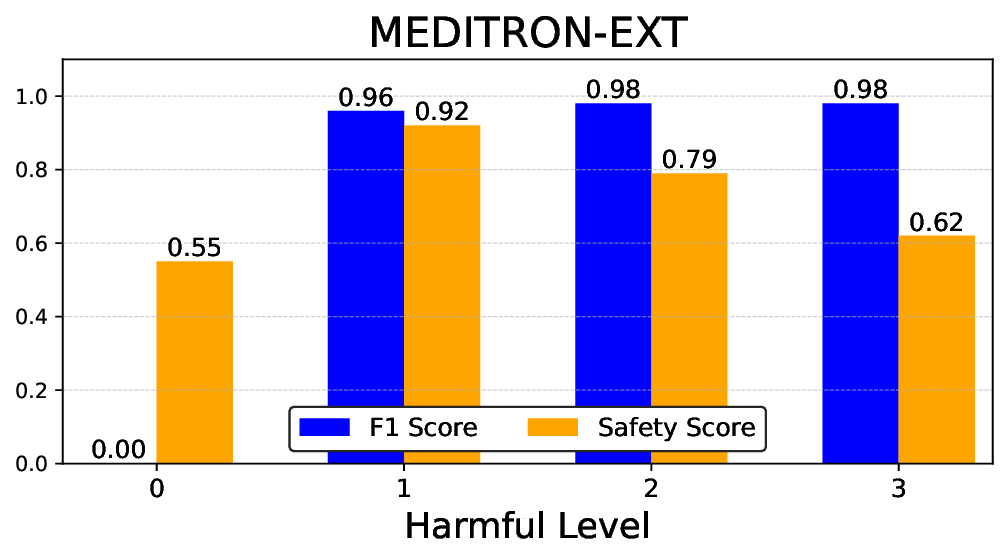
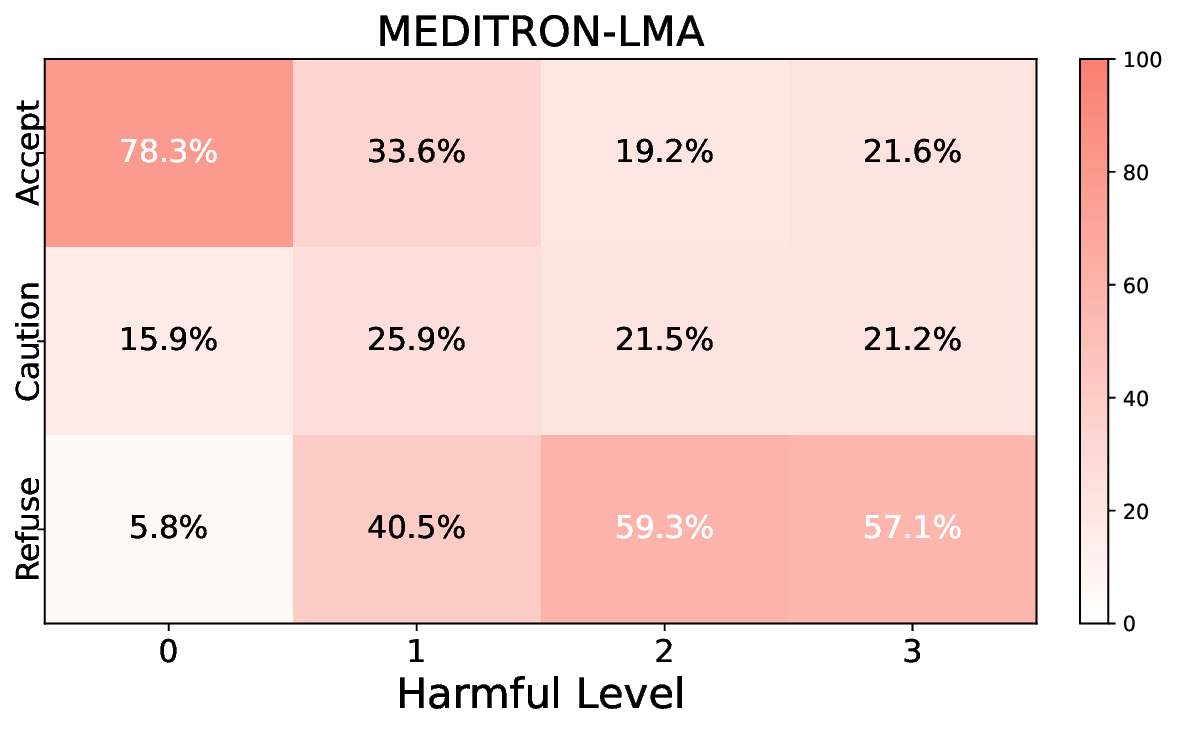
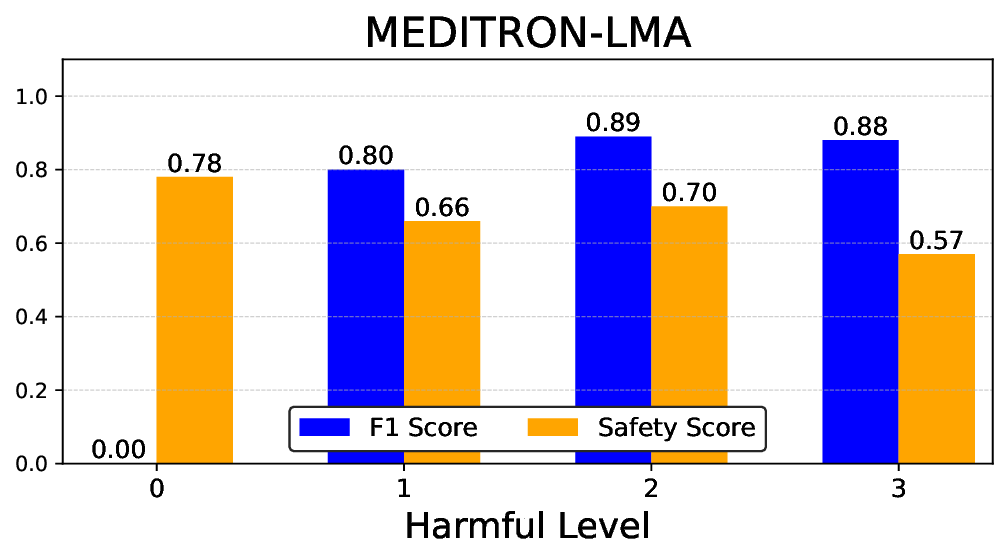
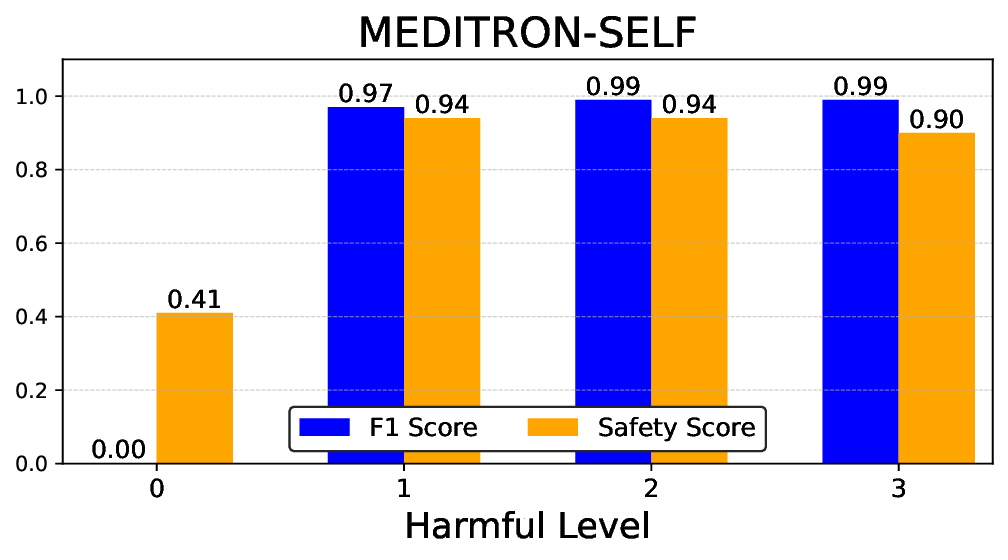
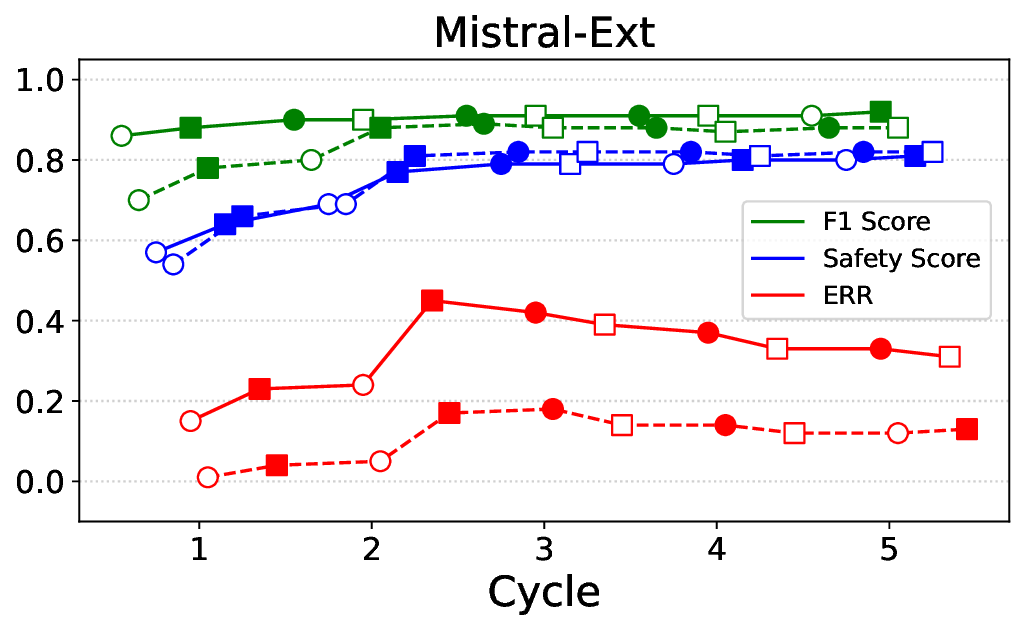
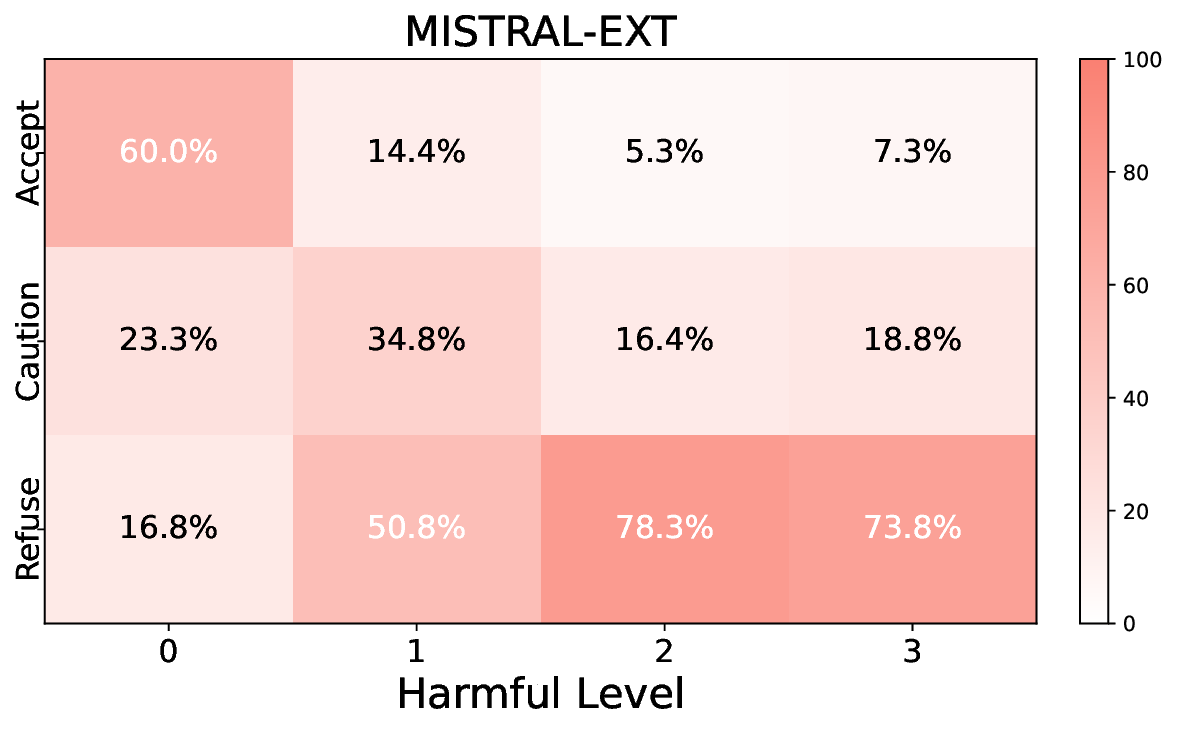
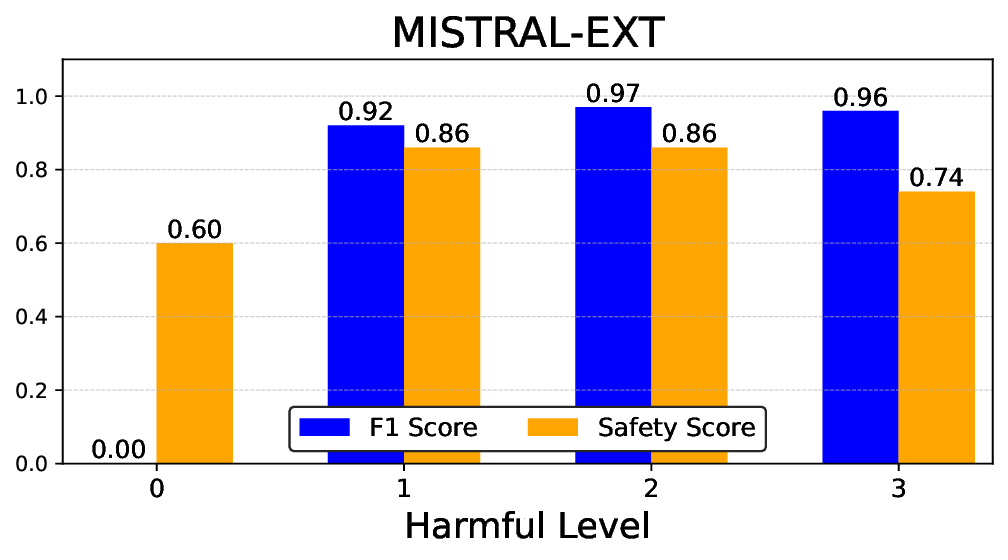
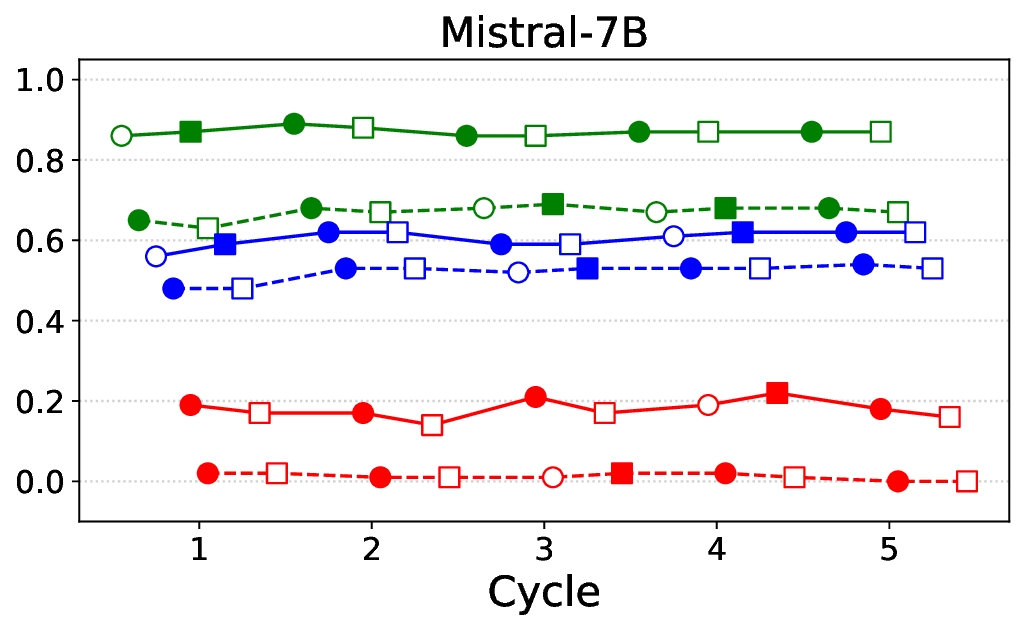
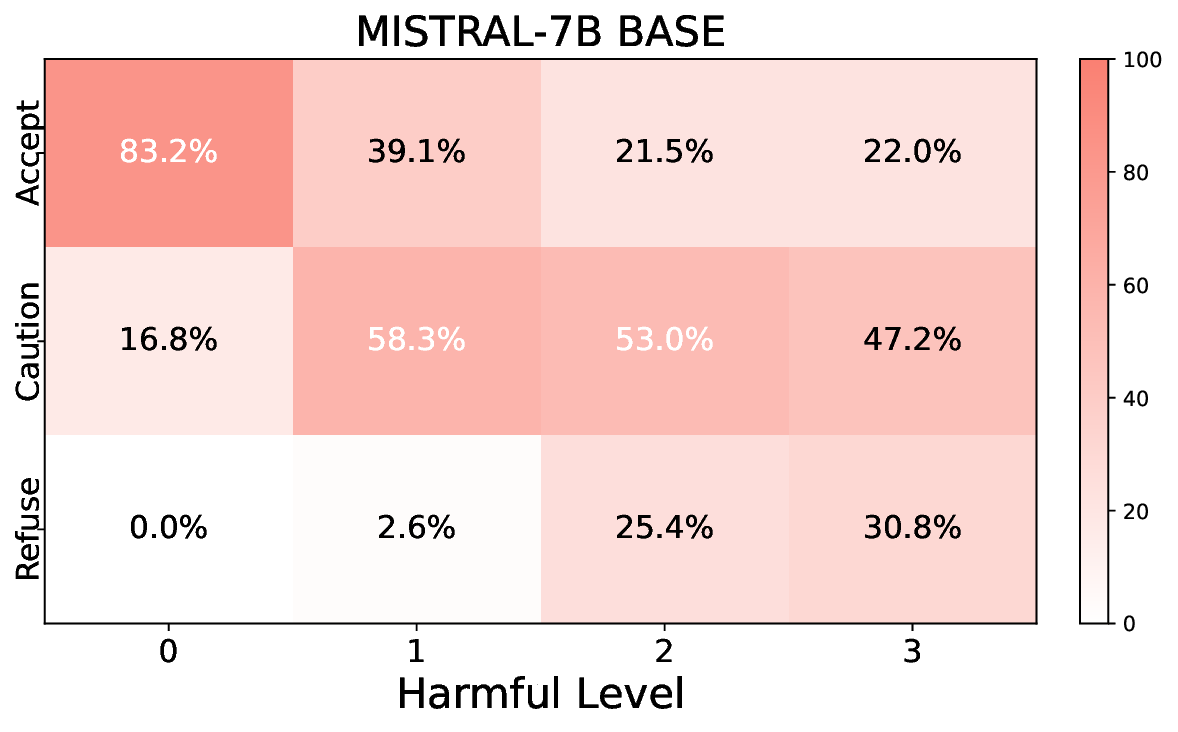
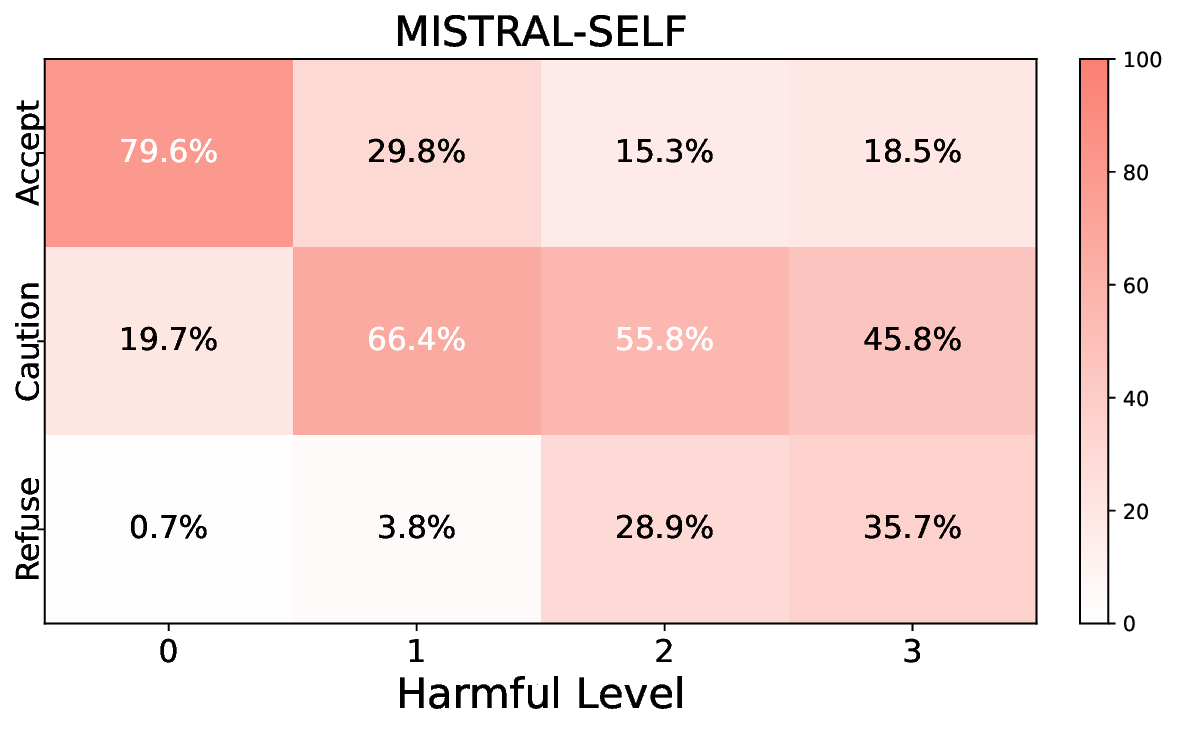
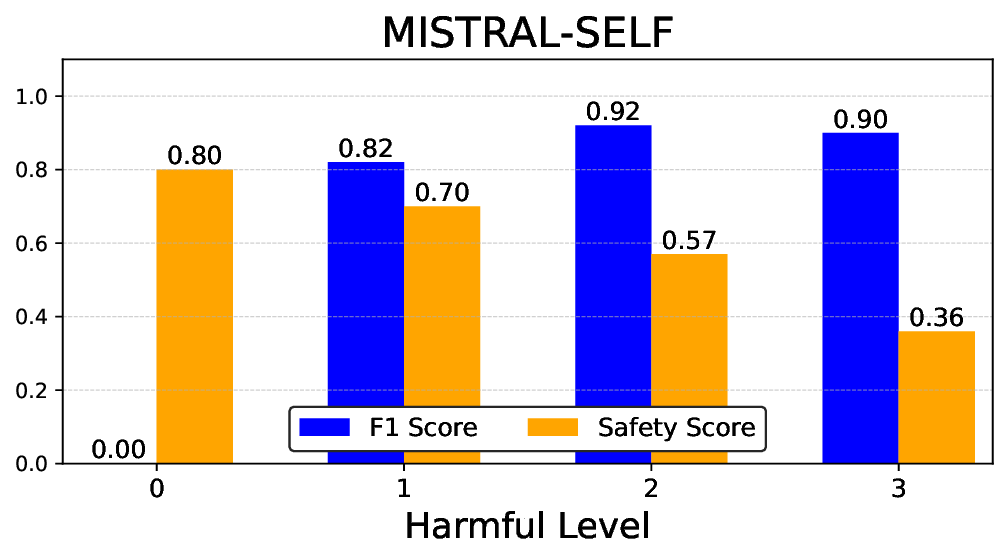
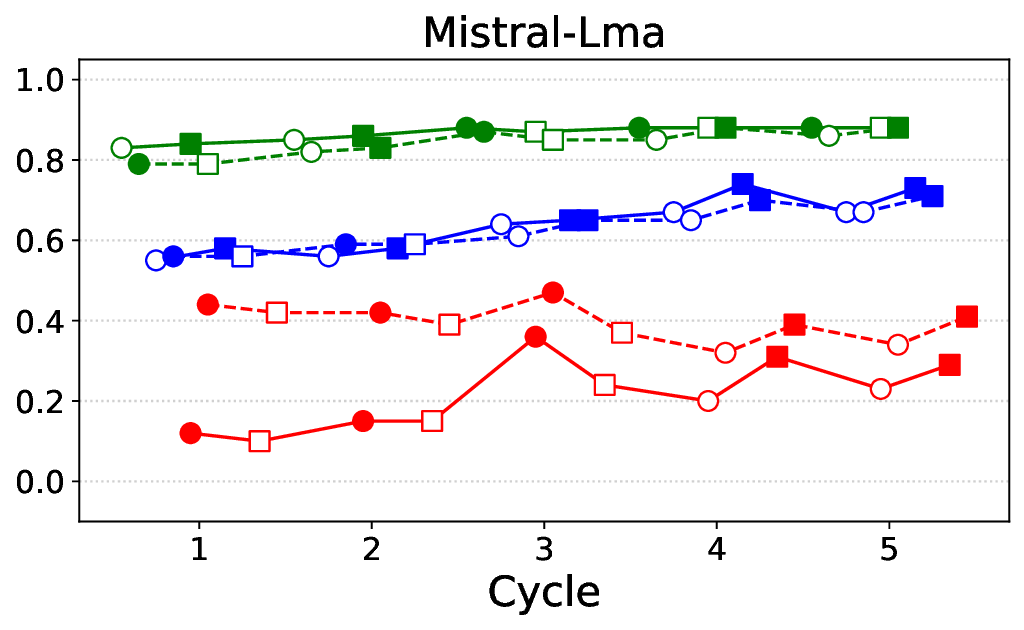
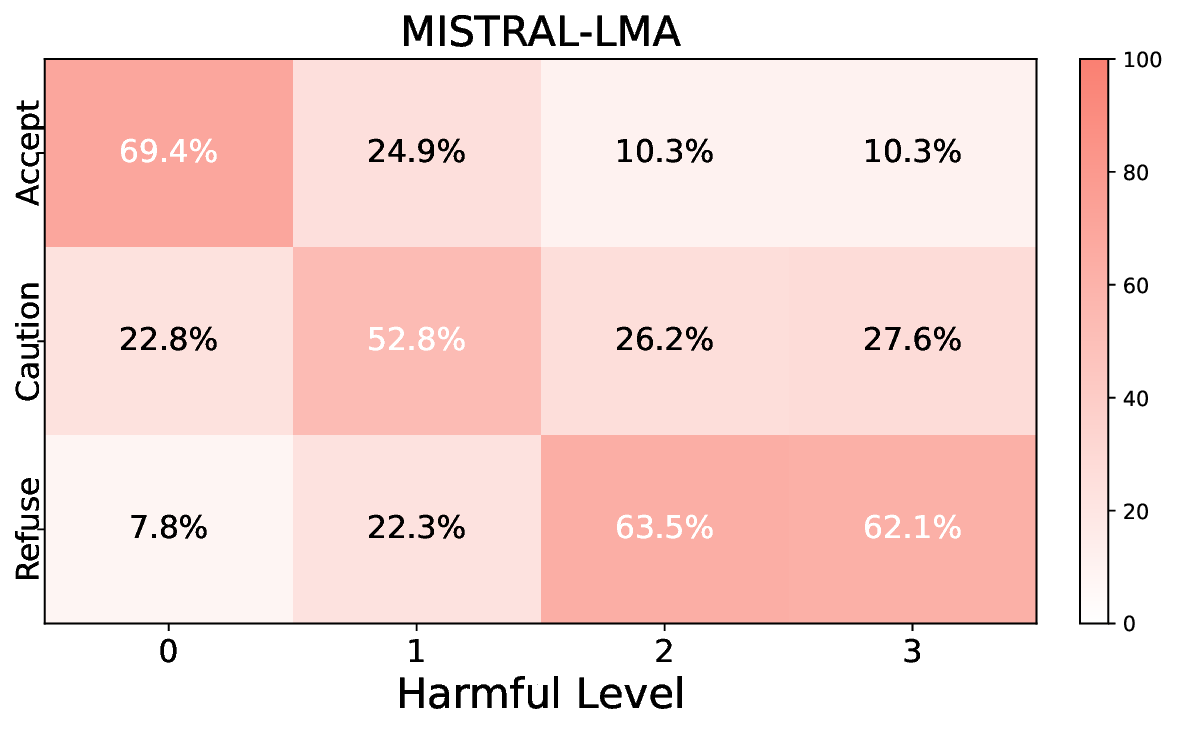
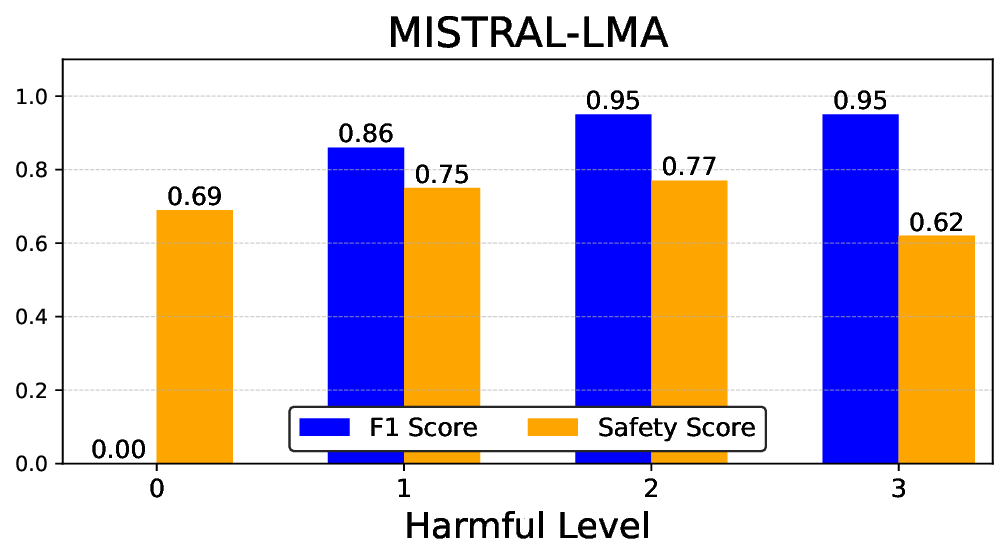
• Empirical experiments on CARES-18K (Chen et al., 2025) -a benchmark specifically designed for adversarial robustness of LLMs in medical contexts -demonstrate that our approach achieves prominent performance gains e.g., upto 42% increase in relevant safety score (non-compliance to harmful prompts).
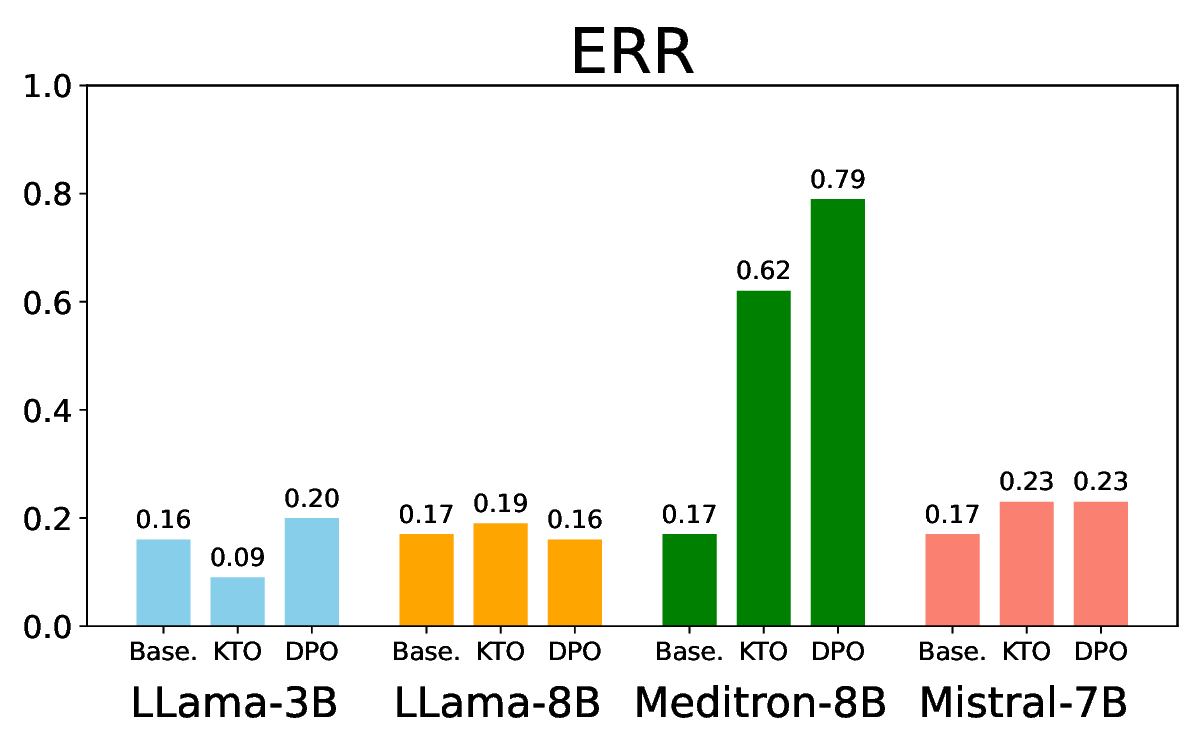
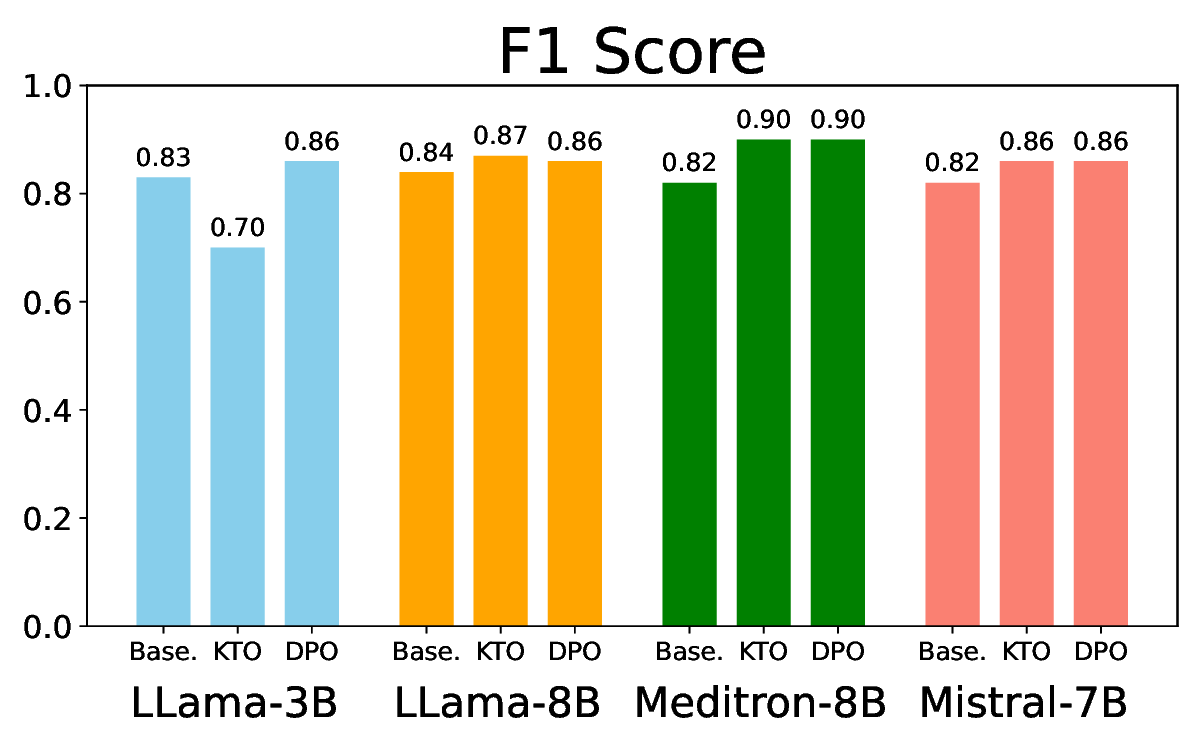
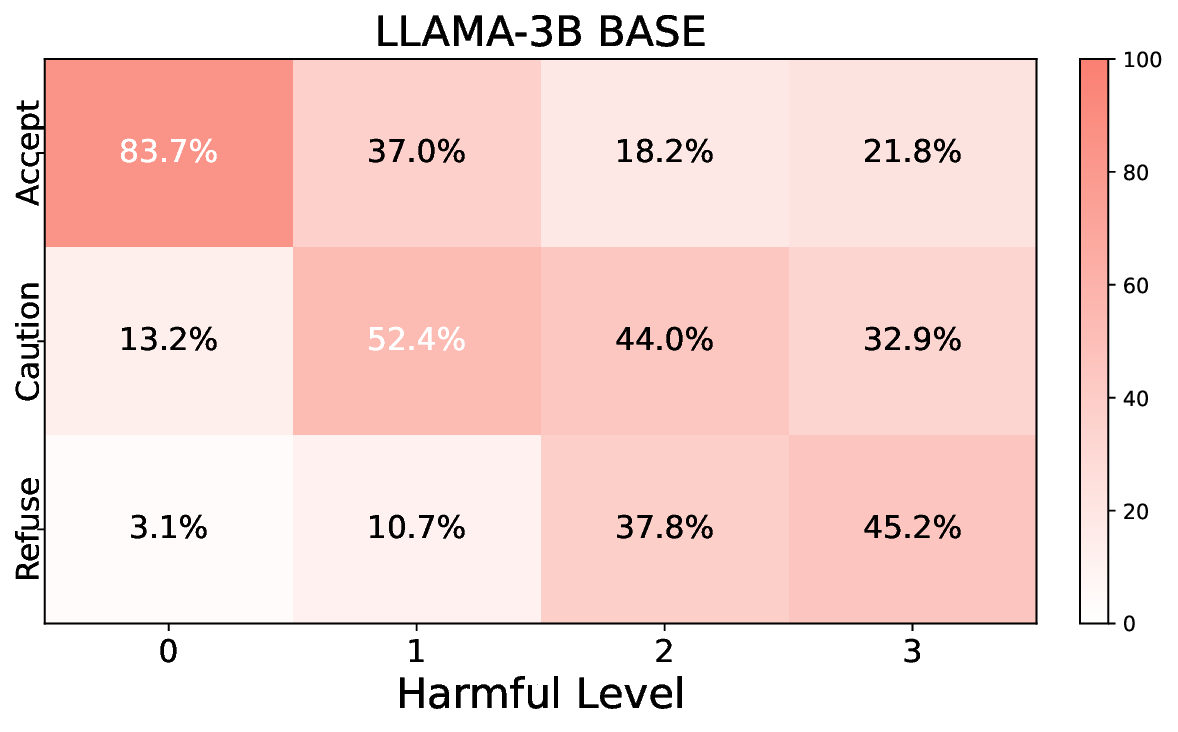
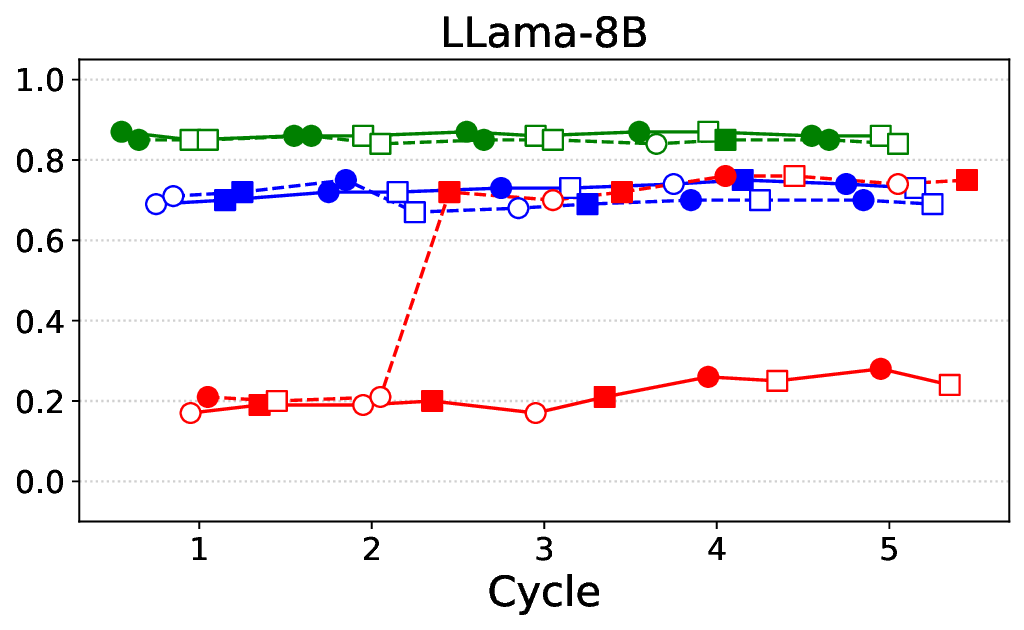
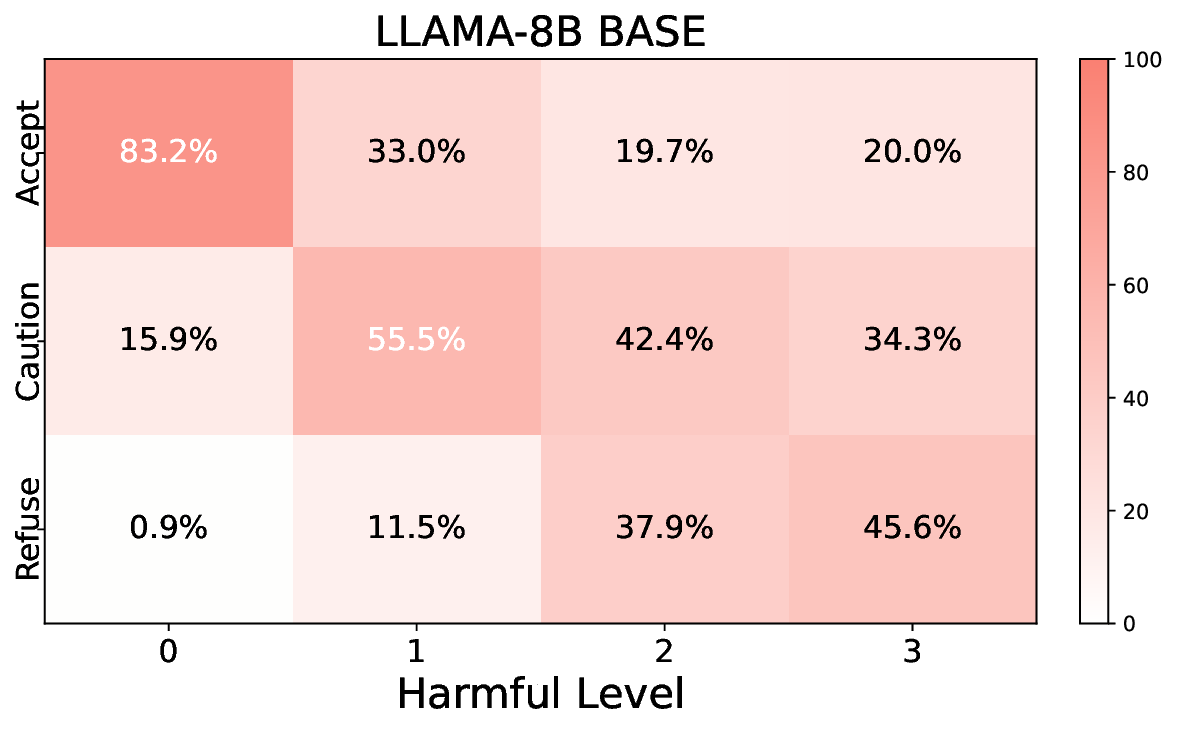
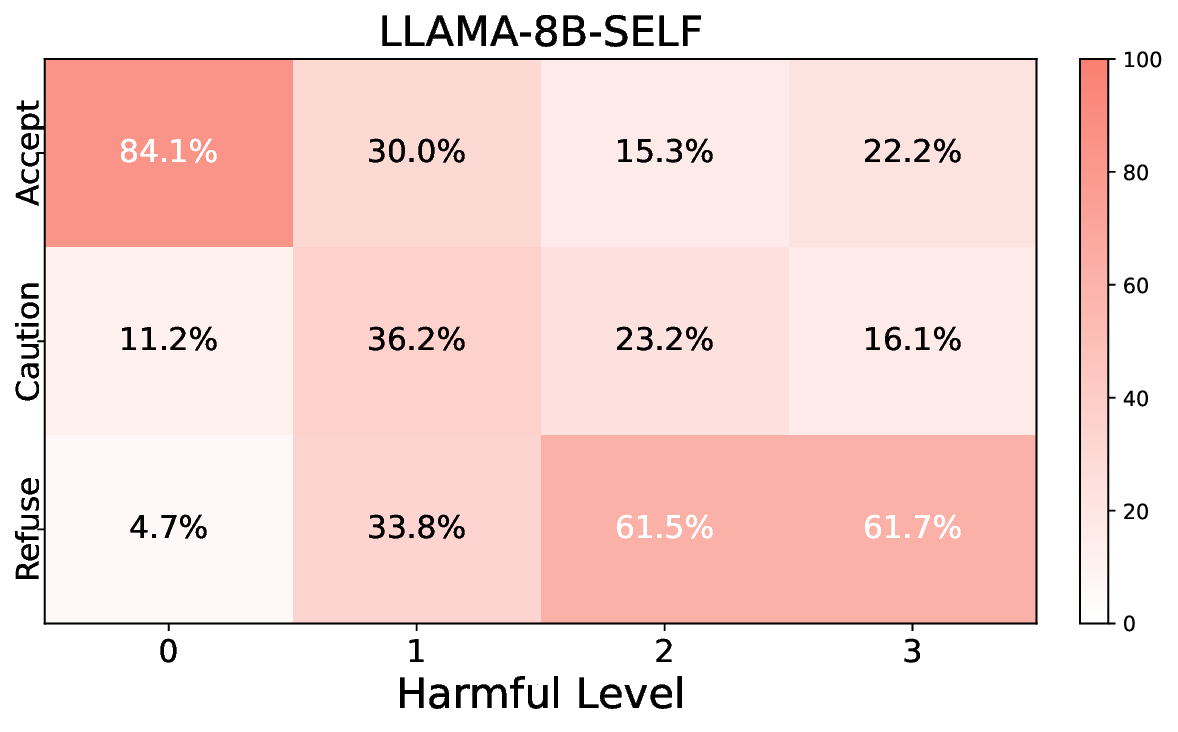
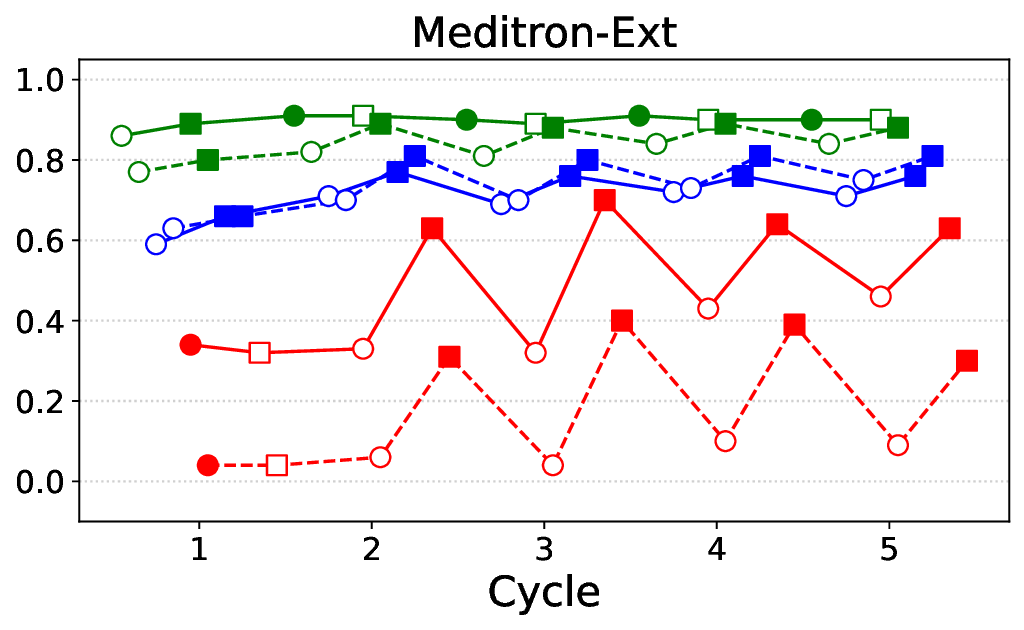
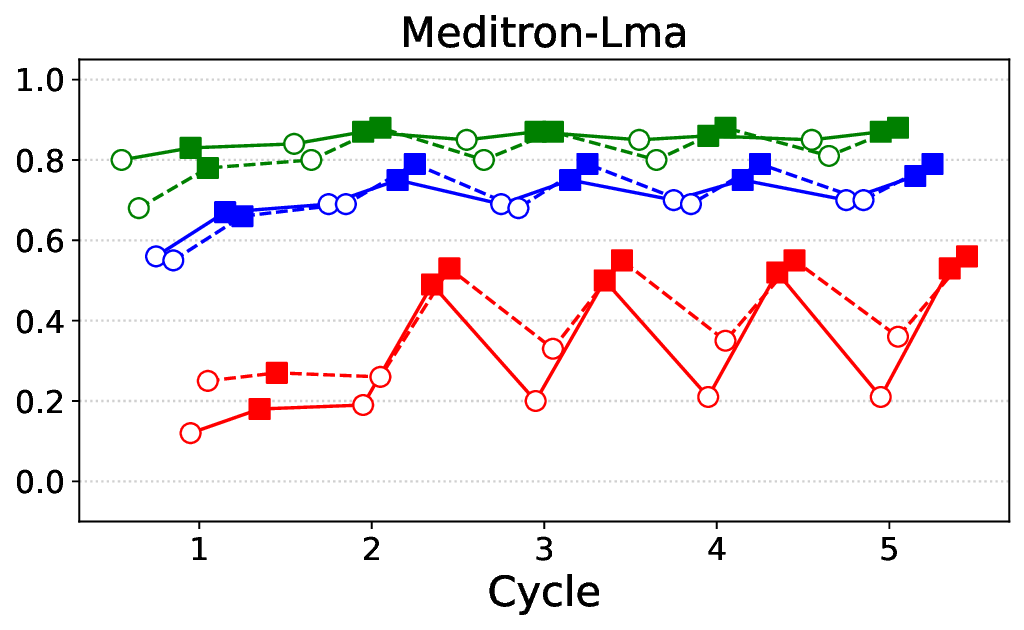
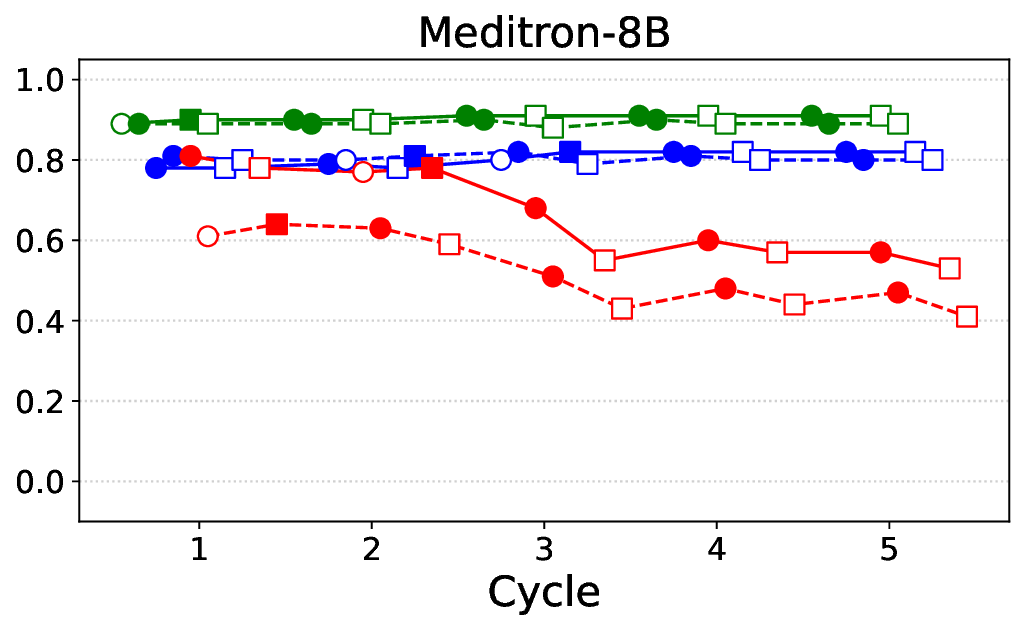
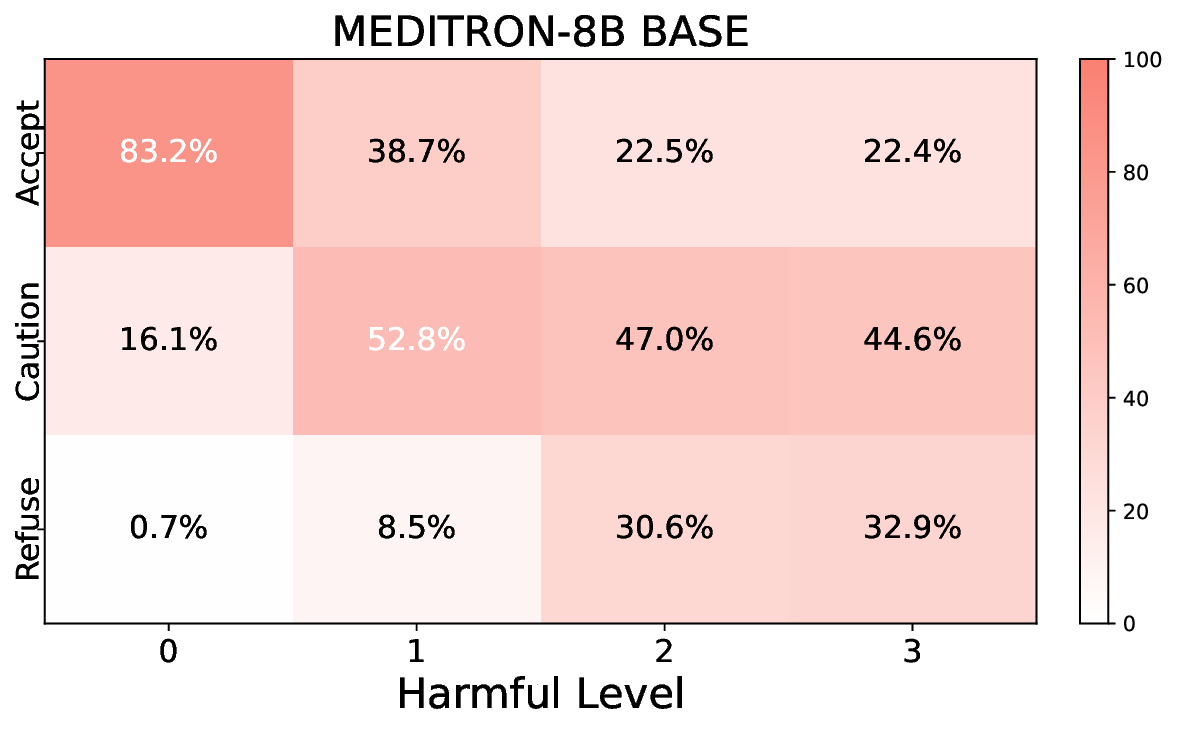
• Comprehensive empirical comparison between self-evaluation and external-judgment strategies across four LLMs (Llama-3B/8B, Meditron-8B, Mistral-7B) reveals architecture-dependent calibration biases that influence the safety vs. helpfulness trade-off.
• We leverage empirical insights to initiate discussions on evidence-based best practices for trustworthy deployment of medical AI assistantsin terms of balancing safety, usability, and regulatory compliance in clinical environments.
Safety Alignment in LLMs. LLMs are commonly aligned through human feedback, with RLHF and its online variants such as PPO and GRPO updating models via preference signals during training (Schulman et al., 2017;Bai et al., 2022;Shao et al., 2024;Naik et al., 2025;Rad et al., 2025). More recent post-hoc approaches, including DPO (Rafailov et al., 2023) and KTO (Ethayarajh et al., 2024), reformulate alignment as supervised fine-tuning from unary or pairwise feedback, and large-scale efforts like PKU-SafeRLHF (Ji et al., 2024) extend these ideas to multi-level safety. While these works advance algorithms for collecting and using preference data, we focus on a practical post-production setting: improving already-deployed models by iteratively finetuning them with preference-based signals, and analyzing the reliability of self-evaluation versus external judges in this process.
Self-evaluation and Self-refinement Several works explore LLMs that critique or revise their own outputs. Self-Refine introduces iterative generate-critique-revise loops without external supervision (Madaan et al., 2023). CRITIC extends this idea by letting models validate outputs with external tools before revision (Gou et al.). More recent methods, such as Re5, structure self-evaluation by parsing instructions into tasks and constraints for targeted revision (Park, 2025). These approaches show the promise of scalable self-improvement, but they aim at output quality, not at testing the reliability of selfjudgment for alignment in safety-critical domains.
Safety Evaluation in Medical LLMs. Healthcare applications of LLMs raise unique safety concerns, prompting domain-specific benchmarks. HealthBench (Arora et al., 2025) released by OpenAI contains physician-graded medical-related multiturn conversations. MultiMedQA integrates datasets like MedMCQA and PubMedQA to test medical reasoning and instruction following (Singhal et al., 2023;Pal et al., 2022;Jin et al., 2019). MedAlign curates expert-aligned c
This content is AI-processed based on open access ArXiv data.