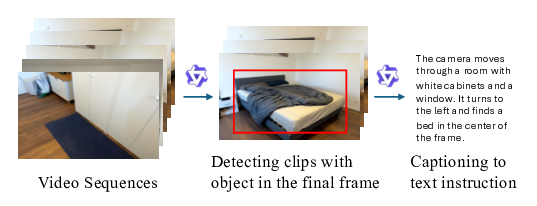
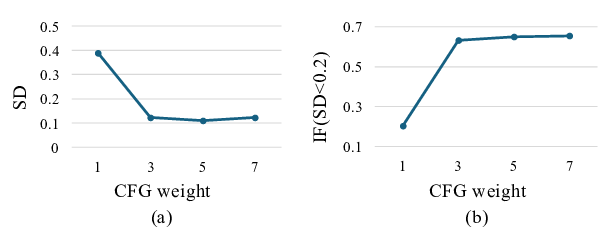We investigate whether video generative models can exhibit visuospatial intelligence, a capability central to human cognition, using only visual data. To this end, we present Video4Spatial, a framework showing that video diffusion models conditioned solely on video-based scene context can perform complex spatial tasks. We validate on two tasks: scene navigation - following camera-pose instructions while remaining consistent with 3D geometry of the scene, and object grounding - which requires semantic localization, instruction following, and planning. Both tasks use video-only inputs, without auxiliary modalities such as depth or poses. With simple yet effective design choices in the framework and data curation, Video4Spatial demonstrates strong spatial understanding from video context: it plans navigation and grounds target objects end-to-end, follows camera-pose instructions while maintaining spatial consistency, and generalizes to long contexts and out-of-domain environments. Taken together, these results advance video generative models toward general visuospatial reasoning.
Figure 1. Our method generates videos that fulfill instructional spatial tasks while remaining geometrically consistent with the provided video context. (a) We demonstrate two tasks: video-based object grounding, where the model follows text instructions (the second and the third row) to navigate and locate a target object (e.g., "a green plant" or "a guitar" ). Navigation paths and final locations are implicitly planned with diversity by model during generation to achieve the same goal (third row); and scene navigation (top-right), where the model generates a video that adheres to a specified camera trajectory (denoted by camera logos) and aligns with ground truth videos (green boxes) (b) Although trained on indoor datasets, our model generalizes well to out-of-domain scenarios, such as an outdoor park. Orange boxes denote context frames. Blue boxes denote generated frames. Please note that red bounding boxes are generated by the video model itself. Frames are subsampled for visualization. Project page at https://xizaoqu.github.io/video4spatial.
We investigate whether video generative models can exhibit visuospatial intelligence, a capability central to hu-man cognition, using only visual data. To this end, we present VIDEO4SPATIAL, a framework showing that video diffusion models conditioned solely on video-based scene context can perform complex spatial tasks. We validate on two tasks: scene navigation -following camera-pose instructions while remaining consistent with 3D geometry of the scene, and object grounding -which requires se-
Humans excel at remembering, understanding, and acting within spatial environments-a hallmark of high-level spatial reasoning capability. A long line of research has sought to endow neural networks with similar capabilities. Recently, rapidly advancing video generative models [22,48,63] have begun to address this challenge, exhibiting general-purpose perceptual and reasoning abilities [74], echoing the trajectory of Large Language Models [3,46]. Because video generation is inherently sequential and temporally coherent, these models are particularly well-suited to visuospatial-related tasks: by rolling out future frames that preserve scene geometry and appearance, they can simulate plausible futures. For example, in maze navigation, a model can “imagine” progress by generating frames that maintain the maze’s topology while ensuring smooth transitions [61,74].
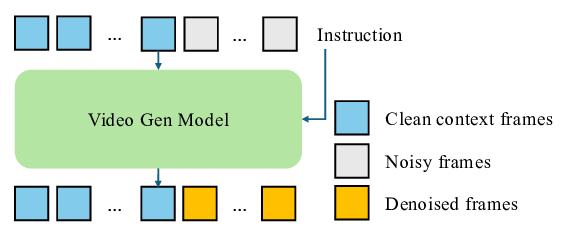
Humans primarily perceive spatial information visually. We aim to endow models with the same capability by using video as a simple, general, and scalable modality. However, learning spatial understanding solely from RGB video is challenging, and many recent methods still rely on auxiliary signals (e.g., depth maps, camera poses, point clouds) for supervision or augmentation [73,75,80,92,103]. In this paper, we present VIDEO4SPATIAL and show that video generative models that rely solely on video context of a spatial environment can exhibit strong spatial intelligence. Our framework is intentionally simple: a standard video diffusion architecture trained only with the diffusion objective. The inputs are a video context (several frames from the same environment) and instructions; the output is a video that completes the instructed spatial task while maintaining scene geometry and temporal coherence.
The core spatial abilities our framework aims to achieve include (i) implicitly inferring 3D structure [34,102], (ii) controlling viewpoint with geometric consistency (scale, occlusion, layout) [27,72], (iii) understanding semantic layout [38], (iv) planning toward goals [2], and (v) maintaining long-horizon temporal coherence. We introduce two tasks to probe these abilities: video-based scene navigation and object grounding. In scene navigation, the model follows camera-pose instructions and produces a video whose trajectory is consistent with both the instructions and the scene geometry. In object grounding, a text instruction asks the model to reach and visibly localize a target object, thereby testing semantic layout understanding and plausible planning (Fig. 1). Together, the tasks evaluate whether VIDEO4SPATIAL can infer and act on scene structure using video alone.
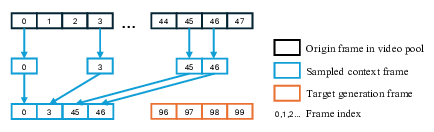
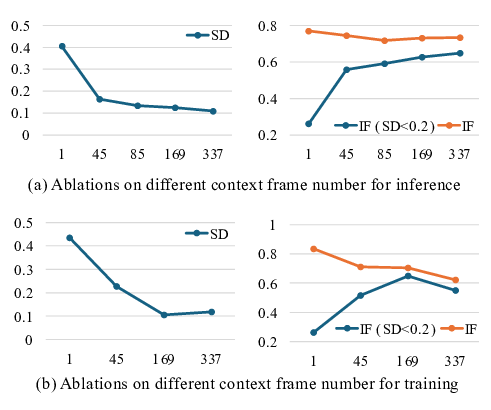
Beyond the base architecture, our central design choice is how to model conditions on video context. In line with DiT [50], we process context and target frames through the same transformer stack, while setting the diffusion timestep of context frames to t = 0. Inspired by History Guidance [55], we extend classifier-free guidance [28] to video context, which we find significantly improves contextual coherence. To reduce redundancy in continuous footage in context, we subsample non-contiguous frames during training and inference and apply non-contiguous RoPE [57] over the corresponding subsampled indices. This index sparsity also enables extrapolation to much longer contexts at inference. For visuospatial tasks, we find that explicit reasoning patterns [20]
This content is AI-processed based on open access ArXiv data.