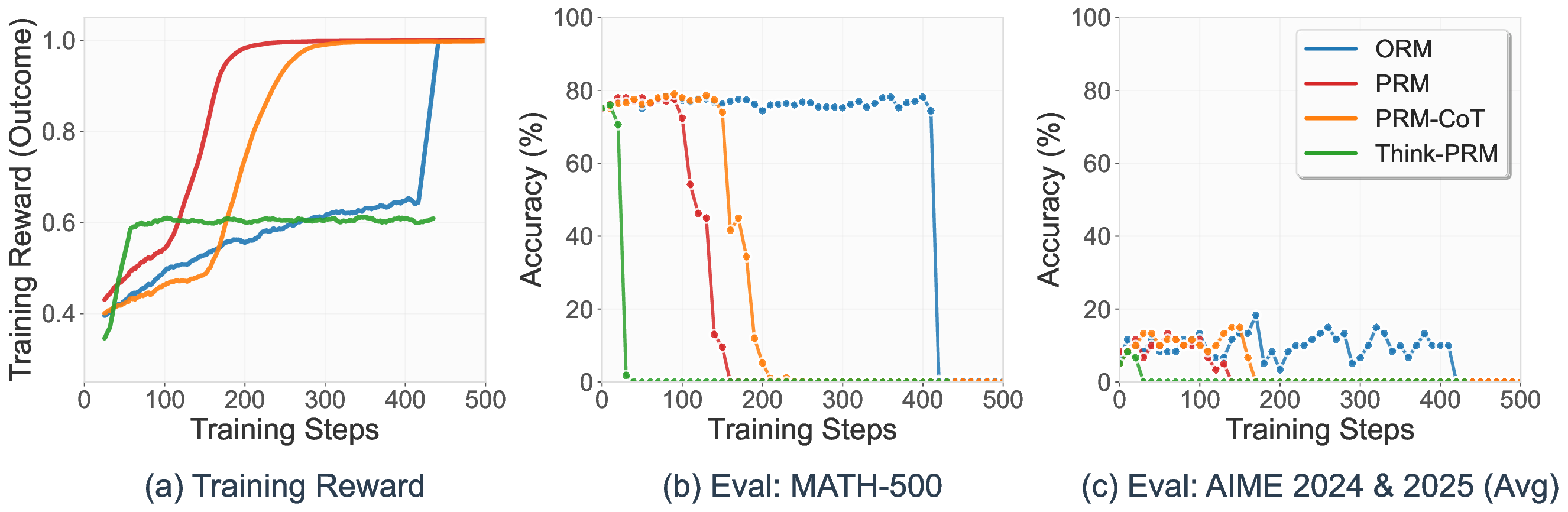
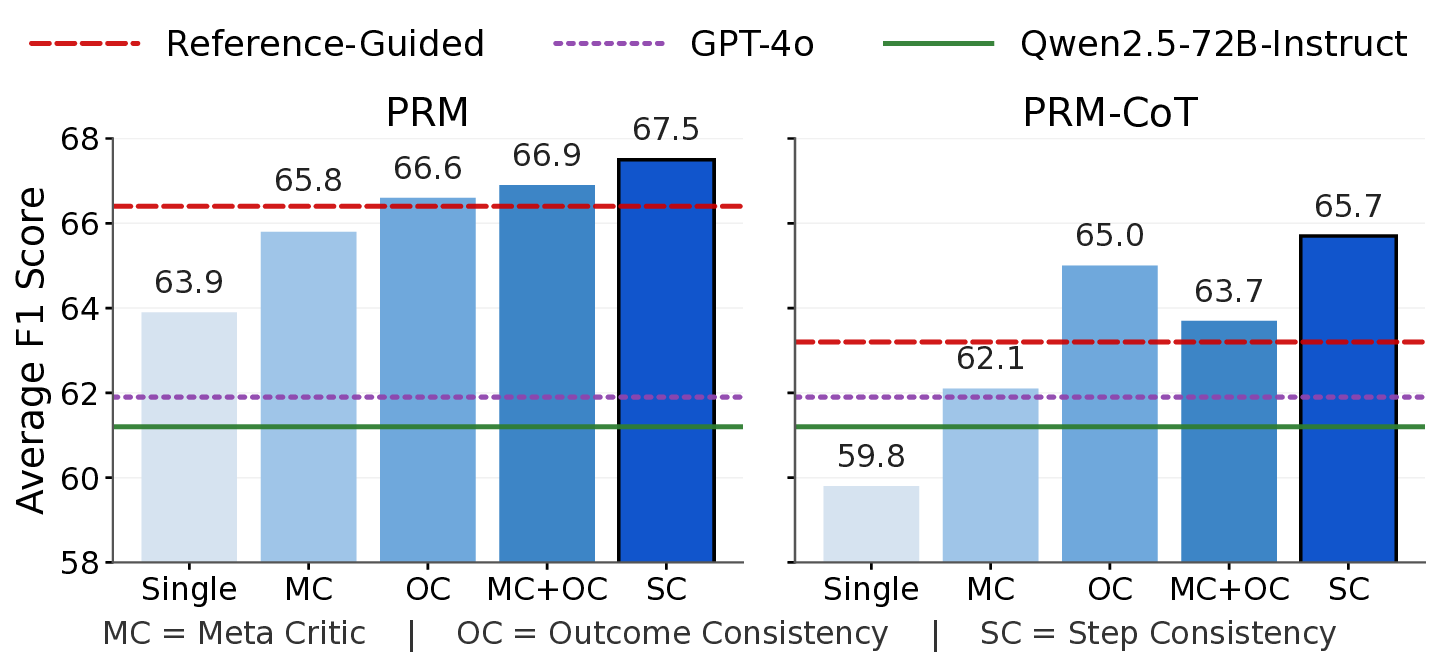
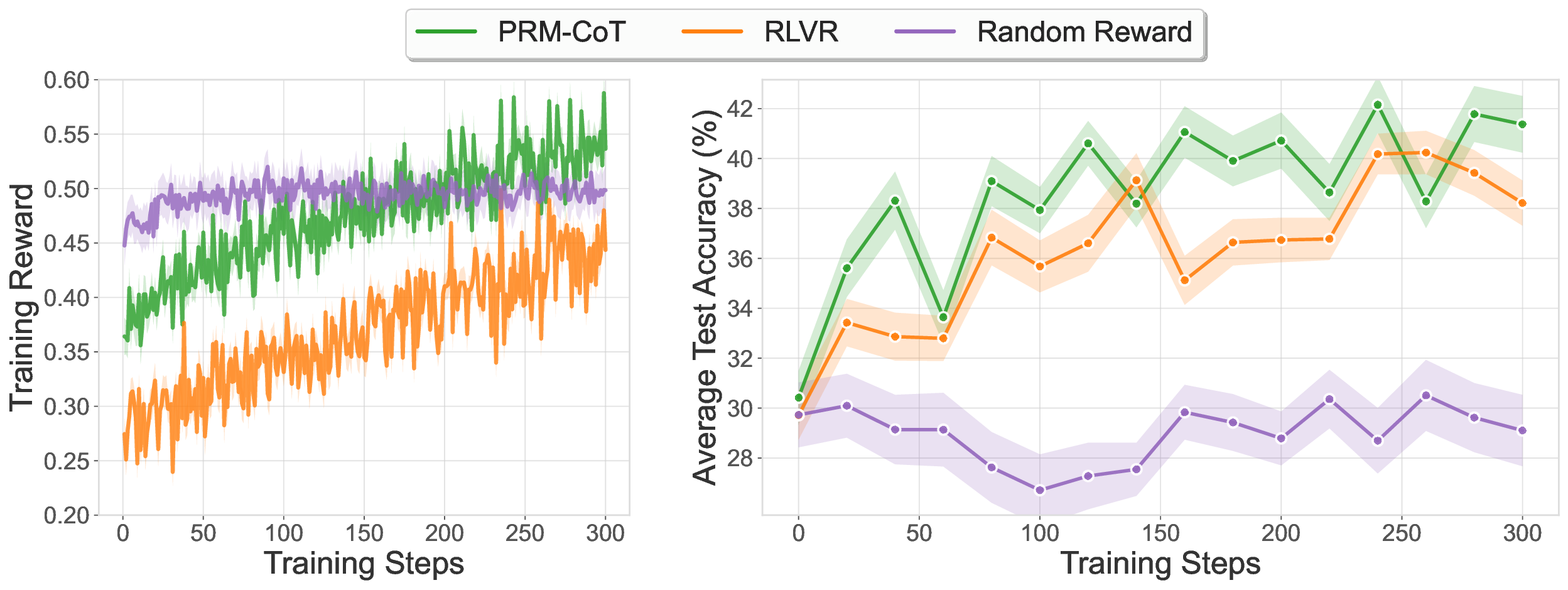
Process reward models (PRMs) that provide dense, step-level feedback have shown promise for reinforcement learning, yet their adoption remains limited by the need for expensive step-level annotations or ground truth references. We propose SPARK: a three-stage framework where in the first stage a generator model produces diverse solutions and a verifier model evaluates them using parallel scaling (self-consistency) and sequential scaling (meta-critique). In the second stage, we use these verification outputs as synthetic training data to fine-tune generative process reward models, which subsequently serve as reward signals during training. We show that aggregating multiple independent verifications at the step level produces training data for process reward models that surpass ground-truth outcome supervision, achieving 67.5 F1 on ProcessBench (a benchmark for identifying erroneous steps in mathematical reasoning) compared to 66.4 for reference-guided training and 61.9 for GPT-4o. In the final stage, we apply our generative PRM with chain-of-thought verification (PRM-CoT) as the reward model in RL experiments on mathematical reasoning, and introduce format constraints to prevent reward hacking. Using Qwen2.5-Math-7B, we achieve 47.4% average accuracy across six mathematical reasoning benchmarks, outperforming ground-truth-based RLVR (43.9%). Our work enables reference-free RL training that exceeds ground-truth methods, opening new possibilities for domains lacking verifiable answers or accessible ground truth.
Large language models (LLMs) have demonstrated impressive capabilities across diverse tasks, from achieving gold-medal performance at the International Mathematical Olympiad to autonomous agentic coding (Castelvecchi, 2025;Luong & Lockhart, 2025;Yang et al., 2024b;Hurst et al., 2024;Anthropic, 2025). Despite these achievements, LLMs still struggle with complex multi-step reasoning and long-horizon problem solving (Kambhampati et al., 2024;Yao et al., 2024;Valmeekam et al., 2024). Recent breakthroughs like OpenAI's o1 and DeepSeek's R1 demonstrate that reinforcement learning (RL) post-training can significantly enhance reasoning capabilities beyond supervised finetuning alone (Jaech et al., 2024;Guo et al., 2025), as RL enables models to explore diverse solution paths and learn from feedback rather than imitation (Chu et al., 2025).
While RL post-training shows promise, current approaches rely on verifiers that require ground truth references. Traditional methods rely on either discriminative verifiers that provide binary correctness signals (Cobbe et al., 2021) or rule-based verifiers using exact answer matching (RLVR) (Guo et al., 2025;Hu et al., 2025), both offering only sparse, outcome-level rewards. Recent advances introduce Process Reward Models (PRMs) that provide denser, step-level feedback to improve training stability and credit assignment (Lightman et al., 2023;Wang et al., 2024;Uesato et al., 2022), including co-evolving approaches like TANGO (Zha et al., 2025) and PRIME (Yuan et al., 2024) that jointly train the verifier alongside the policy model. However, these approaches fundamentally depend on ground truth references-TANGO trains its verifier using gold standard solutions, while PRIME requires outcome-level correctness labels to train its PRM (Zha et al., 2025;Yuan et al., 2024). This dependency severely limits RL’s applicability to domains where ground truth is unavailable, requires expensive expert annotation, or lacks clear verification criteria, such as creative writing, research ideation, long-horizon planning, or complex agentic tasks (Bowman et al., 2022). The challenge becomes: How can we train effective process reward models that provide dense, steplevel feedback without requiring any ground truth references, enabling RL to scale beyond domains with verifiable answers?
The recent success of inference-time scaling methods offers a promising direction for addressing this challenge. These approaches improve LLM reasoning by allocating additional computation at test time rather than during training (Ke et al., 2025;Snell et al., 2025;Brown et al., 2024). Parallel scaling methods like self-consistency demonstrate that aggregating multiple independent reasoning paths through majority voting significantly improves accuracy over single-path generation (Wang et al., 2023). Sequential scaling methods, such as self-refinement approaches, show that LLMs can iteratively critique and improve their own outputs without external supervision (Madaan et al., 2023;Saunders et al., 2022). These inference-time techniques have proven highly effective, with recent work showing that optimal test-time compute scaling can outperform simply increasing model parameters (Snell et al., 2025). This raises a critical insight: if LLMs can improve reasoning by aggregating multiple solution attempts (self-consistency) or iteratively refining outputs (self-critique) at inference time without ground truth, can we leverage the same capabilities to generate synthetic verification data for training generative process reward models?
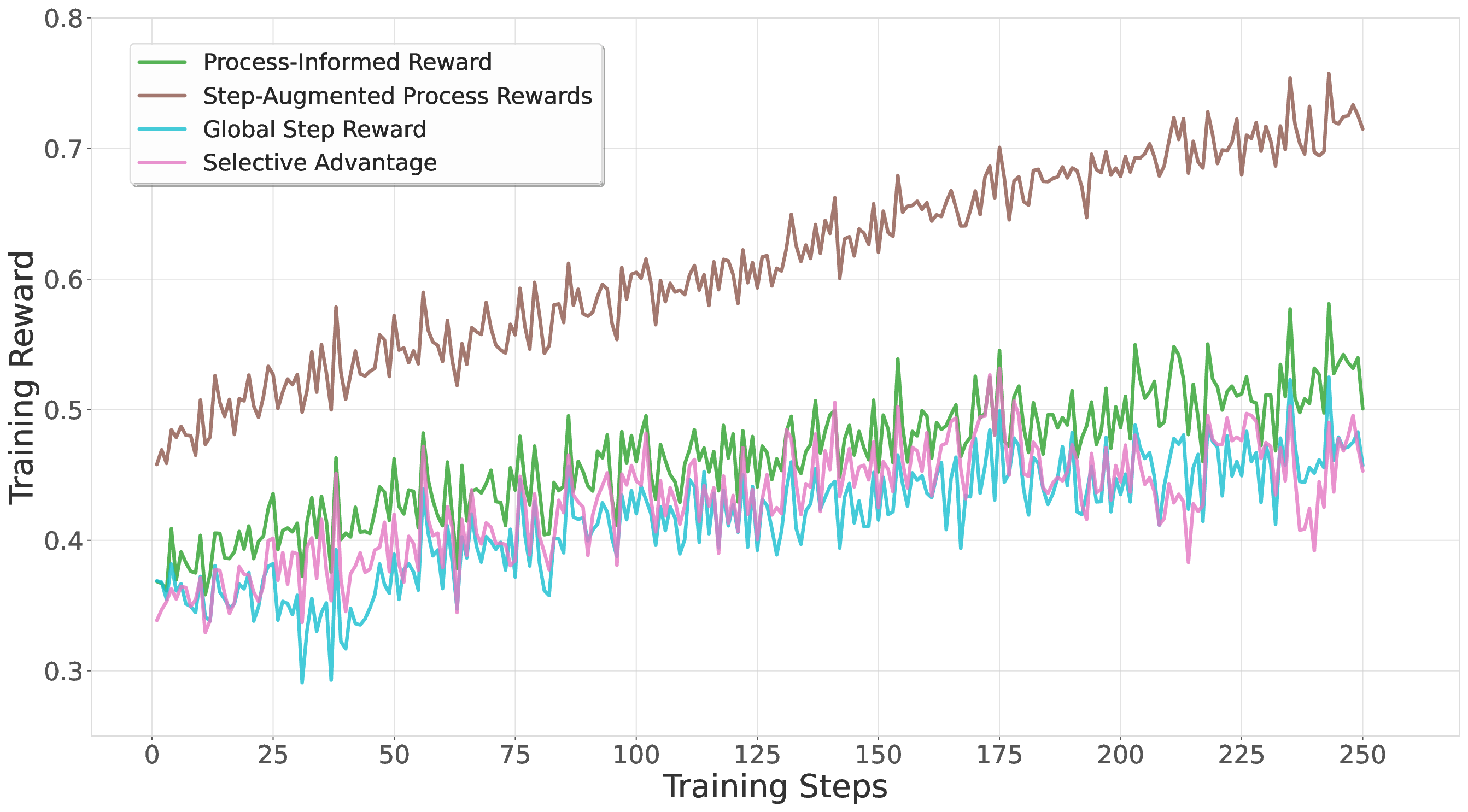
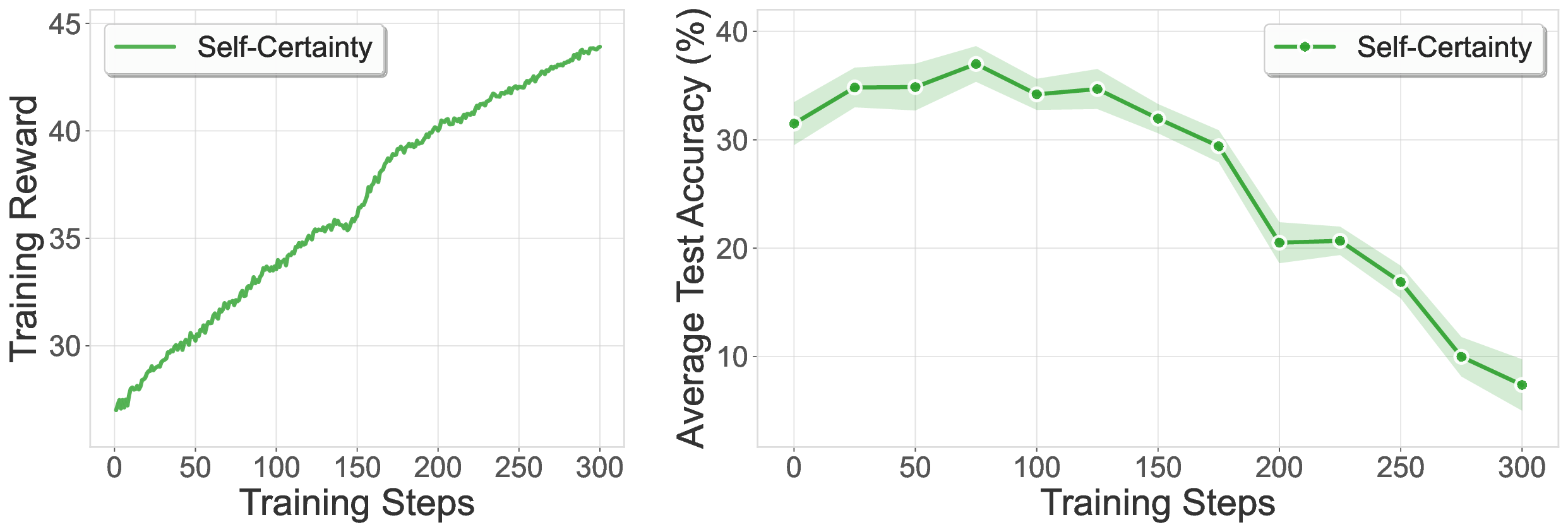
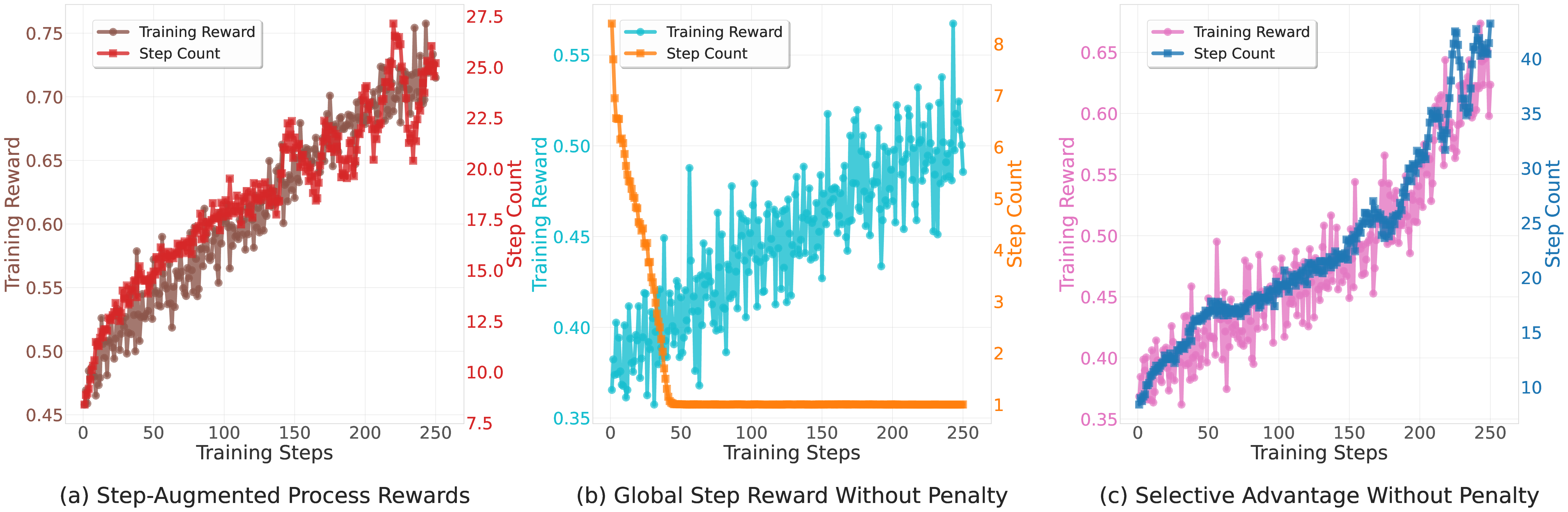
In this work, we propose SPARK, a reference-free framework that leverages inference-time scaling methods to generate synthetic step-level verification data without any ground truth references (see Figure 1). We employ a multi-scale generator-verifier framework where a generator model produces diverse solution attempts and a verifier model evaluates them using parallel (self-consistency) and sequential (meta-critique) scaling techniques. Our key insight is that aggregating multiple independent verifications at the step level can produce training data that rivals or exceeds ground-truth supervision quality. We demonstrate that PRMs trained using this approach enable stable RL training while systematically identifying and addressing multiple reward exploitation patterns that emerge when using generative PRMs as reward signals-challenges that prior work has not comprehensively explored (Zha et al., 2025;Cui et al., 2025). The contributions of our SPARK framework include:
(1) A reference-free framework for generating high-quality step-level verification data using inference-time scaling, eliminating the need for ground truth or human annotation (Section 2).
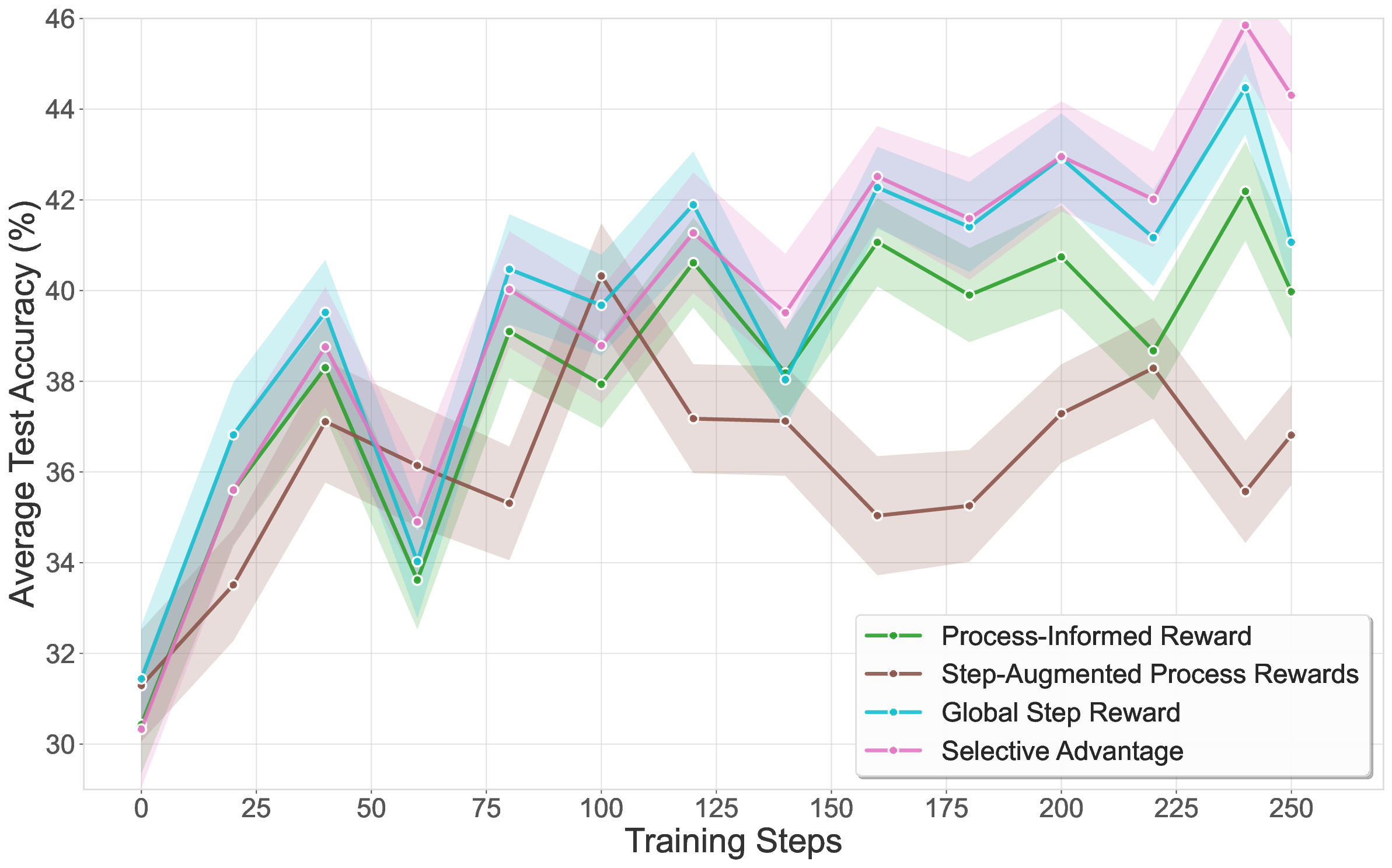
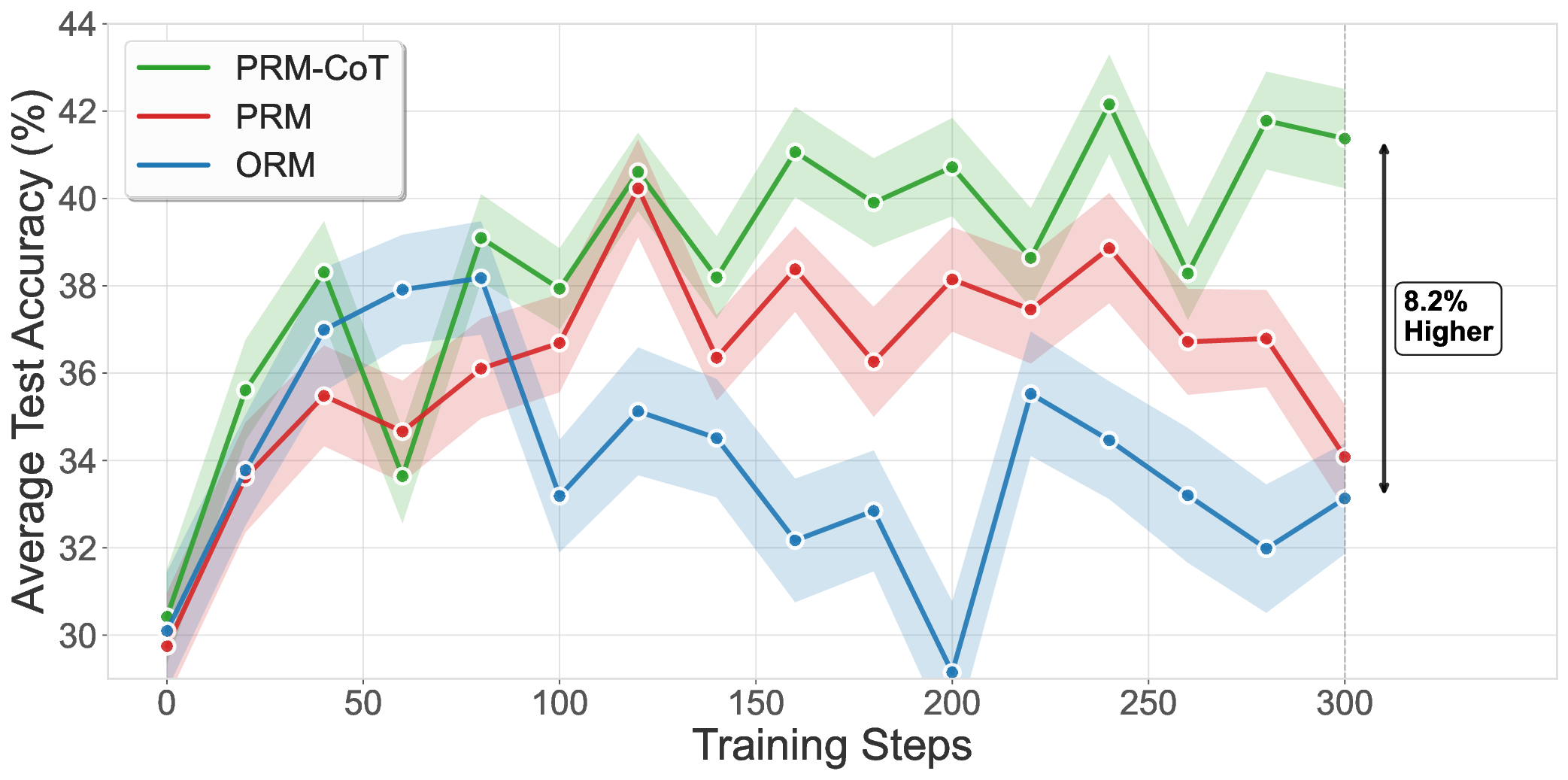
(2) Comprehensive evaluation on ProcessBench (Zheng et al., 2025), a benchmark for identifying erroneous steps in mathematical reasoning, showing that PRMs trained with our synthetic data achieve 67.5 F1, outperforming those trained with outc
This content is AI-processed based on open access ArXiv data.