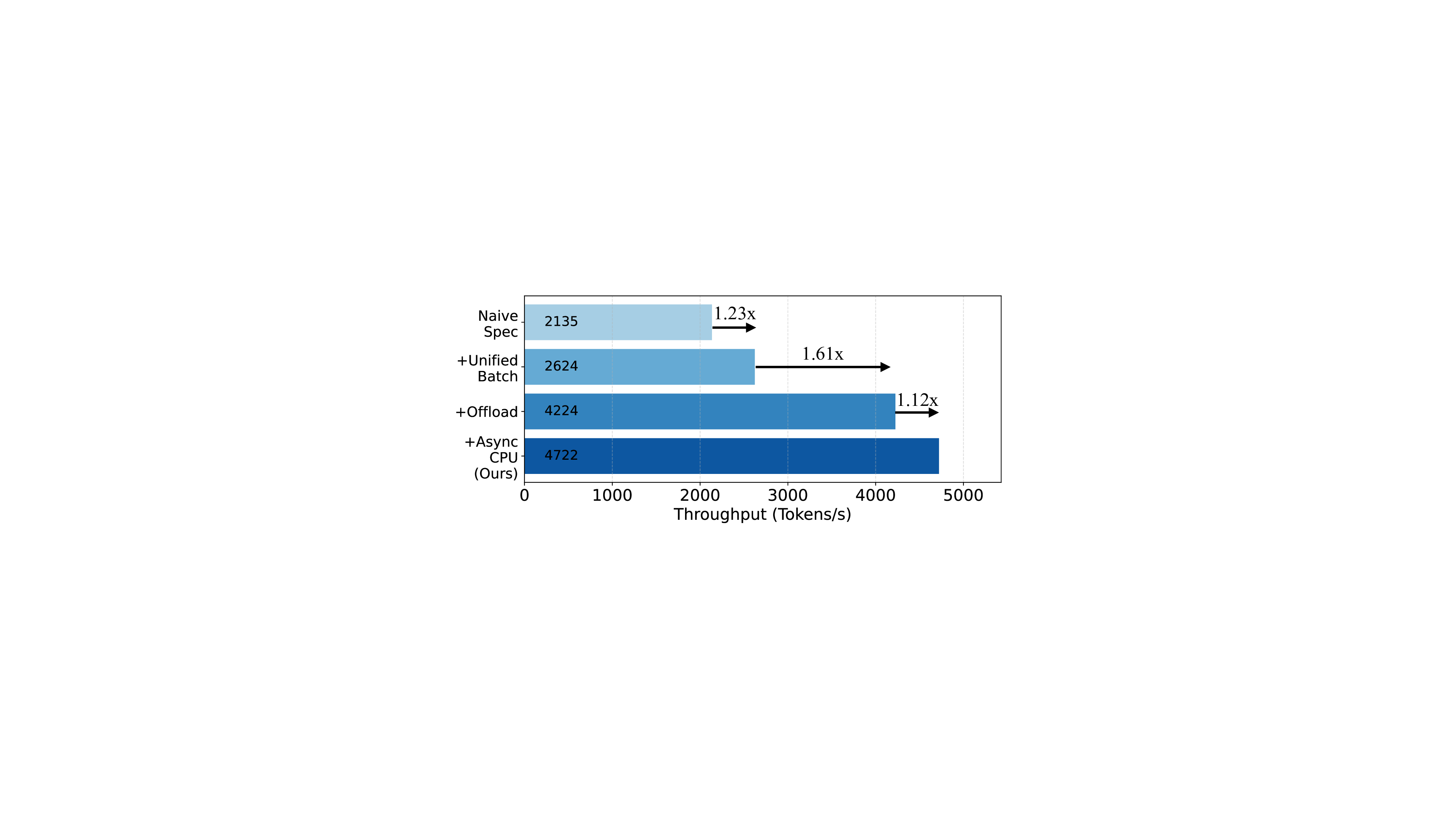Title: Accelerating Large-Scale Reasoning Model Inference with Sparse Self-Speculative Decoding
ArXiv ID: 2512.01278
Date: 2025-12-01
Authors: Yilong Zhao, Jiaming Tang, Kan Zhu, Zihao Ye, Chi-Chih Chang, Chaofan Lin, Jongseok Park, Guangxuan Xiao, Mohamed S. Abdelfattah, Mingyu Gao, Baris Kasikci, Song Han, Ion Stoica
📝 Abstract
Reasoning language models have demonstrated remarkable capabilities on challenging tasks by generating elaborate chain-of-thought (CoT) solutions. However, such lengthy generation shifts the inference bottleneck from compute-bound to memory-bound. To generate each token, the model applies full attention to all previously generated tokens, requiring memory access to an increasingly large KV-Cache. Consequently, longer generations demand more memory access for every step, leading to substantial pressure on memory bandwidth.
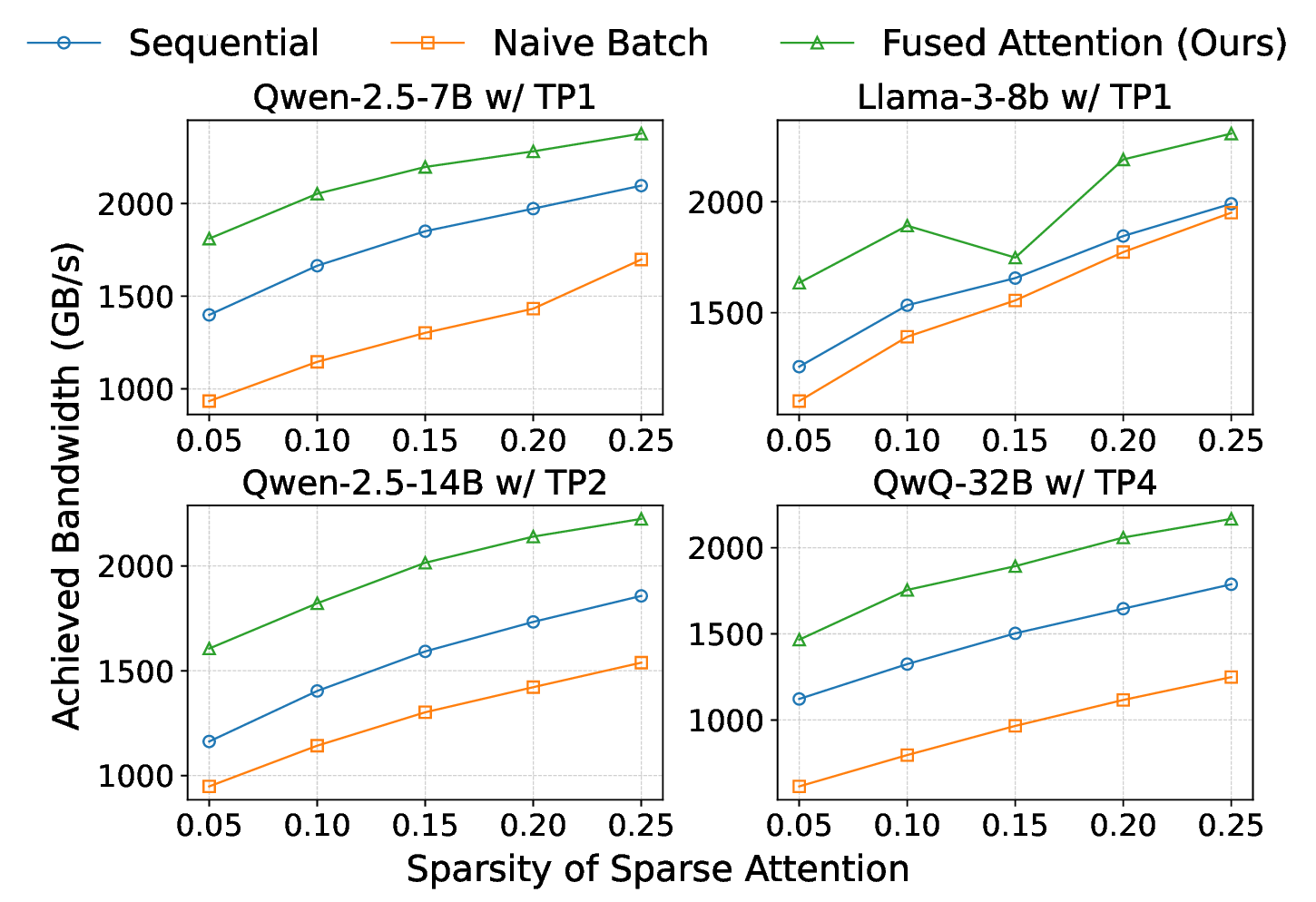
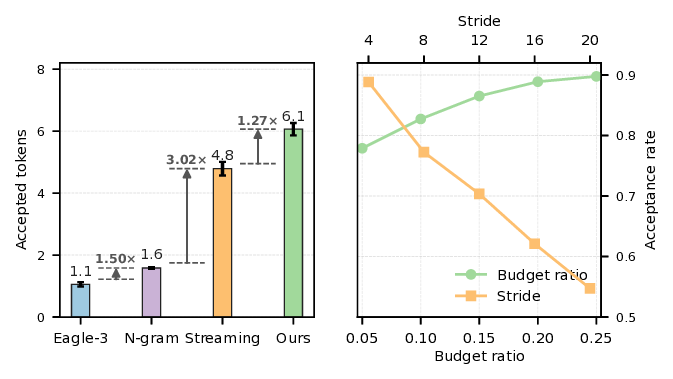
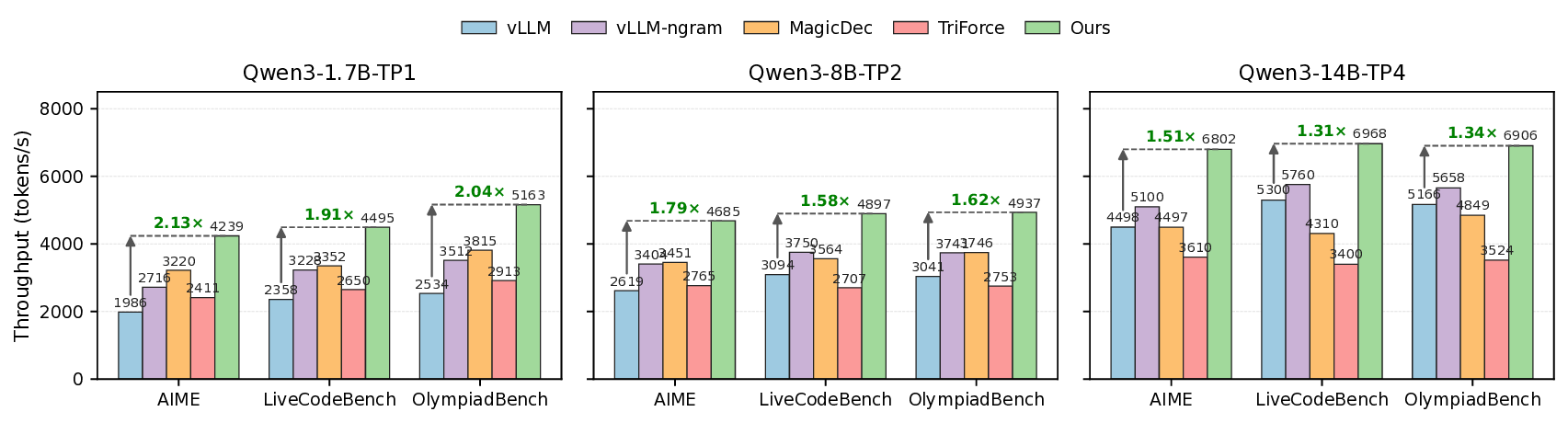
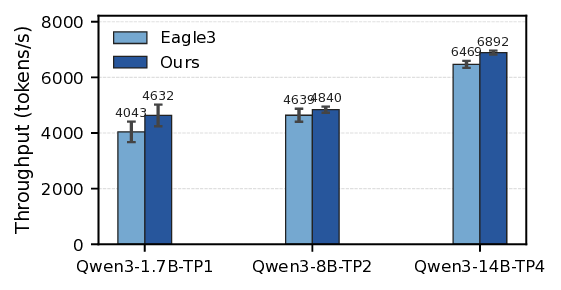
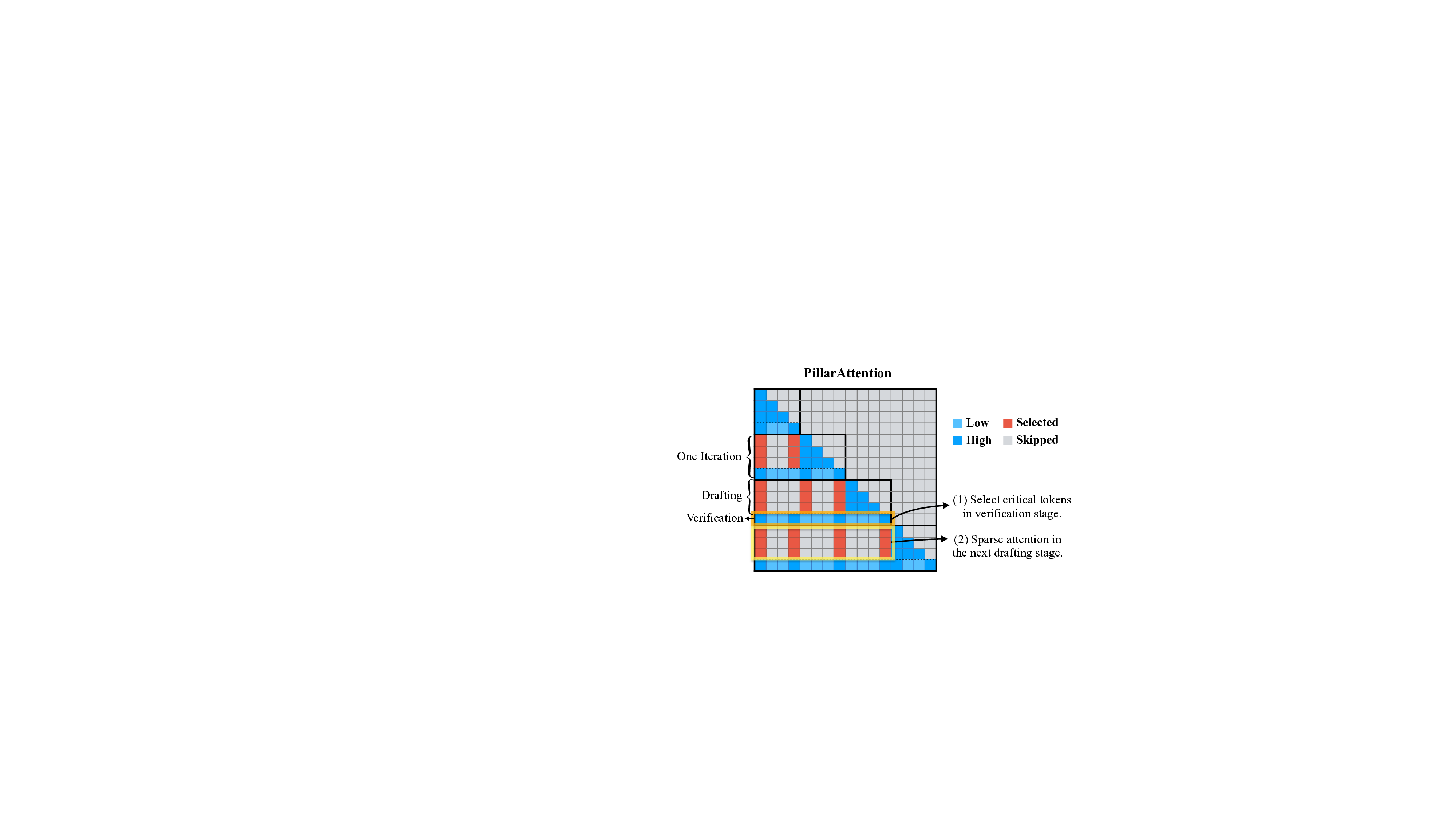
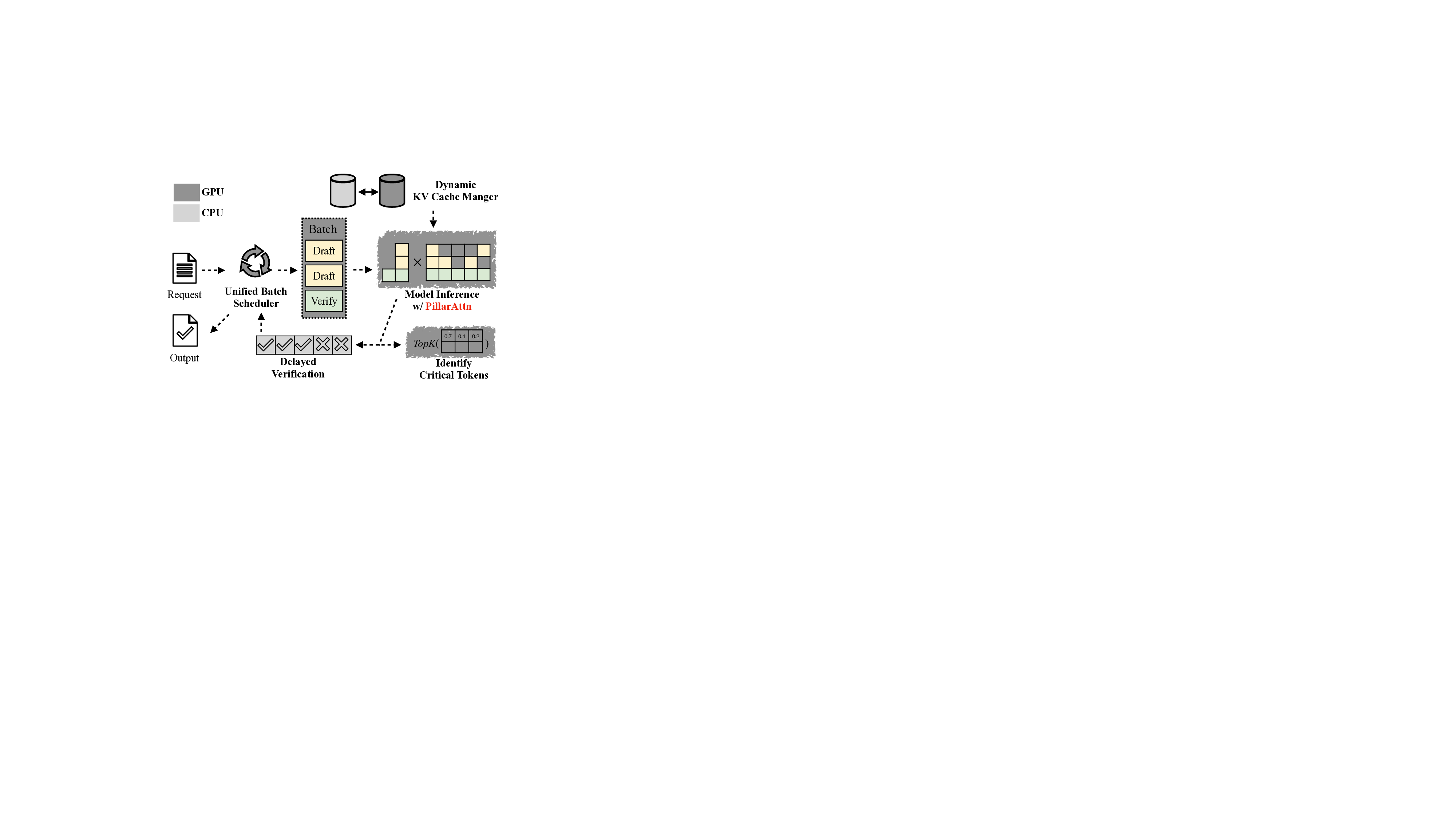
To address this, we introduce SparseSpec, a speculative decoding framework that reuses the same model as the draft and target models (i.e., self-speculation). SparseSpec features a novel sparse attention mechanism, PillarAttn, as the draft model, which accurately selects critical tokens via elegantly reusing information from the verification stage. Furthermore, SparseSpec co-designs self-speculation with three system innovations: (1) a unified scheduler to batch token drafting and verification, (2) delayed verification for CPU/GPU overlap, and (3) dynamic KV-Cache management to maximize memory utilization. Across various models and datasets, SparseSpec outperforms state-of-the-art solutions, with an up to 2.13x throughput speedup.
💡 Deep Analysis
📄 Full Content
ACCELERATING LARGE-SCALE REASONING MODEL INFERENCE:
SELF-SPECULATIVE DECODING WITH SPARSE ATTENTION
Yilong Zhao 1 * Jiaming Tang 2 * Kan Zhu 3 Zihao Ye 4 Chi-Chih Chang 5 Chaofan Lin 6 Jongseok Park 1
Guangxuan Xiao 2 Mohamed S. Abdelfattah 5 Mingyu Gao 6 Baris Kasikci 3 Song Han 2 4 Ion Stoica 1
ABSTRACT
Reasoning language models have demonstrated remarkable capabilities on challenging tasks by generating
elaborate chain-of-thought solutions. However, such lengthy generation shifts the inference bottleneck from
compute-bound to memory-bound. To generate each token, the model applies full attention to all previously
generated tokens, requiring memory access to an increasingly large KV-Cache. Consequently, longer generations
demand more memory access for every step, leading to substantial pressure on memory bandwidth.
To address this, we introduce SparseSpec, a speculative decoding framework that reuses the same model as both
the draft and target models (i.e., self-speculation). SparseSpec features a novel sparse attention mechanism,
PillarAttn, as the draft model, which accurately selects critical tokens via elegantly reusing information from the
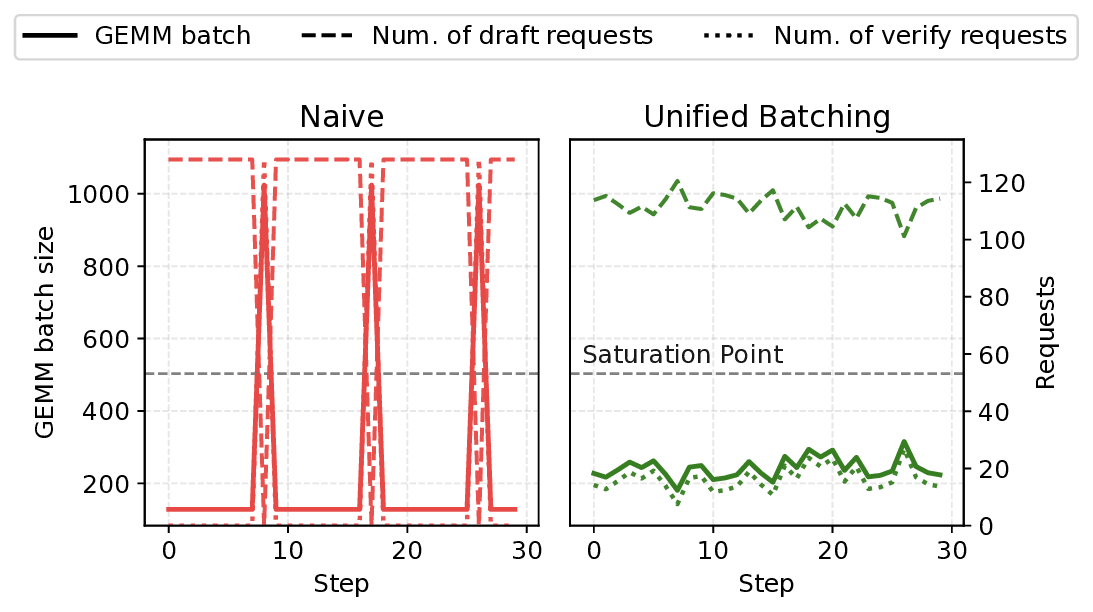
verification stage. Furthermore, SparseSpec co-designs self-speculation with three system optimizations: (1) a
unified scheduler to batch both draft and verification phases to maximize parallelism, (2) delayed verification for
CPU/GPU overlap, and (3) dynamic KV-Cache management to enable host memory offload to maximize GPU
memory utilization. Across various models and datasets, SparseSpec outperforms state-of-the-art solutions, with
an up to 2.13× throughput gain. Code is open-sourced at github.com/sspec-project/SparseSpec.
1
INTRODUCTION
Recent advances in reasoning language models (RLMs),
such as OpenAI-o1 (OpenAI, 2024), have demonstrated re-
markable capabilities in solving complex reasoning tasks.
These models typically generate tens of thousands of to-
kens from problems described in only hundreds of tokens
through extensive chain-of-thought (CoT) (Snell et al., 2024;
DeepSeek-AI, 2025a). This lengthy, deliberate reasoning
paradigm shifts the performance bottleneck of inference
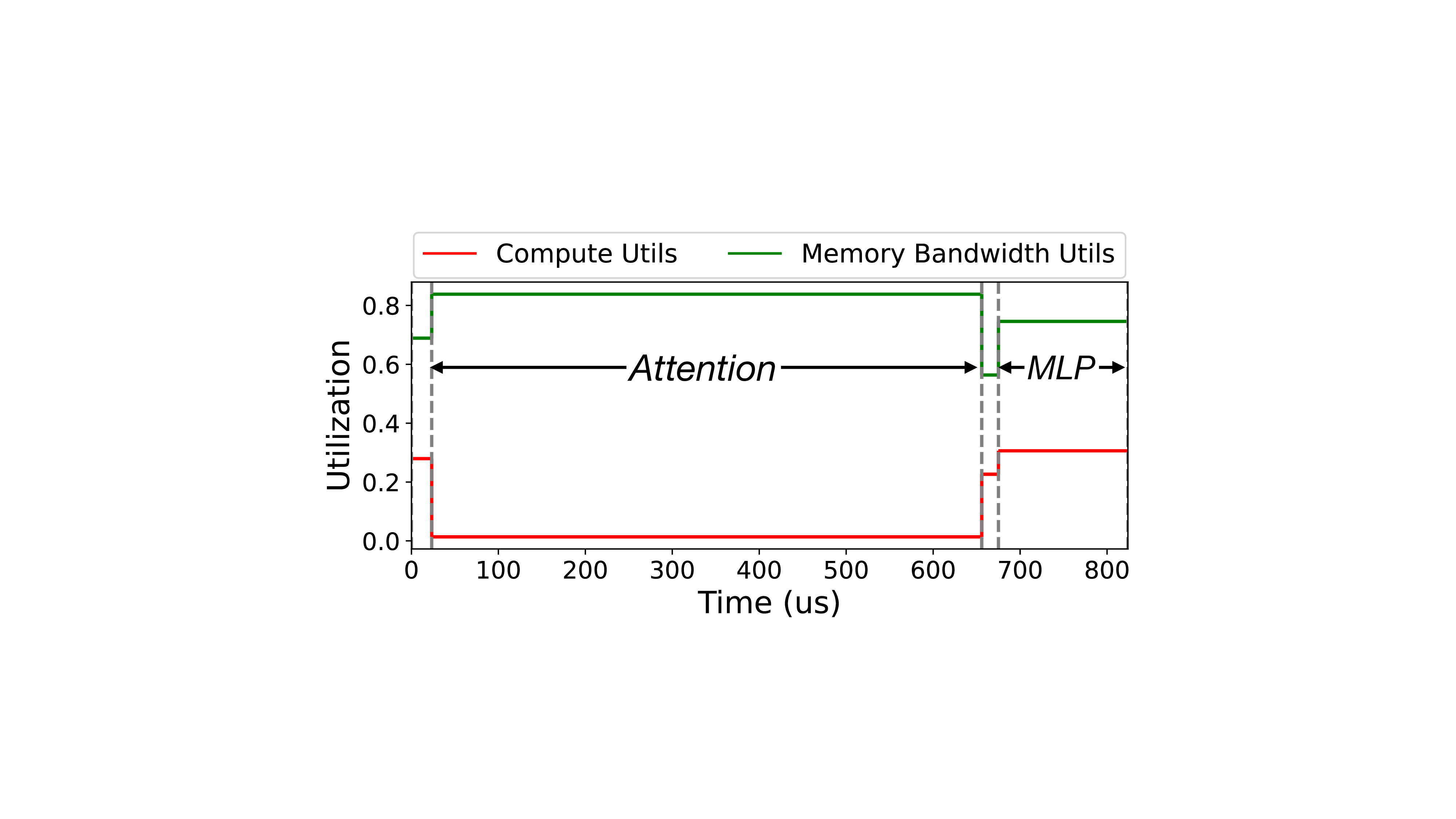
from compute-bound to memory-bound (Zhao et al., 2024b).
Due to the auto-regressive nature of RLMs, generating each
token requires loading all previously generated key-value
vectors (KV-Cache), making long-output tasks memory-
bound. In fact, the total amount of KV-Cache that needs to
be loaded increases quadratically with output length (Tang
et al., 2024). For example, when serving Qwen3-8B (Qwen,
2025) on an H100 with a batch size of 128 and an output
of 8192, loading the KV-Cache takes on average 21 ms per
step, accounting for over 70% of the end-to-end latency.
To mitigate the memory bandwidth bottleneck, researchers
have proposed a lossless technique, speculative decod-
*Equal contribution by coin flip.
1University of California,
Berkeley 2Massachusetts Institute of Technology 3University of
Washington 4NVIDIA 5Cornell University 6Tsinghua University.
Preprint, under review.
ing (Chen et al., 2023). In a nutshell, speculative decoding
employs a smaller and faster draft model to generate mul-
tiple candidate tokens sequentially. These candidates are
then verified in parallel by the original target model. This
requires reading the large KV-Cache only once. In contrast,
without speculation, the entire KV-Cache needs to be loaded
for every token. As a result, speculative decoding substan-
tially reduces memory access and improves throughput.
However, existing speculative decoding methods require
additional training or modification for each target model,
limiting their applicability. Specifically, some solutions re-
quire training a separate standalone draft model (Chen et al.,
2023); others modify the model architecture by adding de-
coder layers (Li et al., 2025a). These additional steps in-
crease the complexity of real-world deployment. For ex-
ample, training a small draft model requires careful data
curation for a specific workload and may not generalize (Liu
et al., 2024b). Moreover, deployment also needs to redesign
the inference framework to orchestrate both models effi-
ciently (Miao et al., 2024). Ultimately, this creates signifi-
cant barriers to adoption (Zhang et al., 2024).
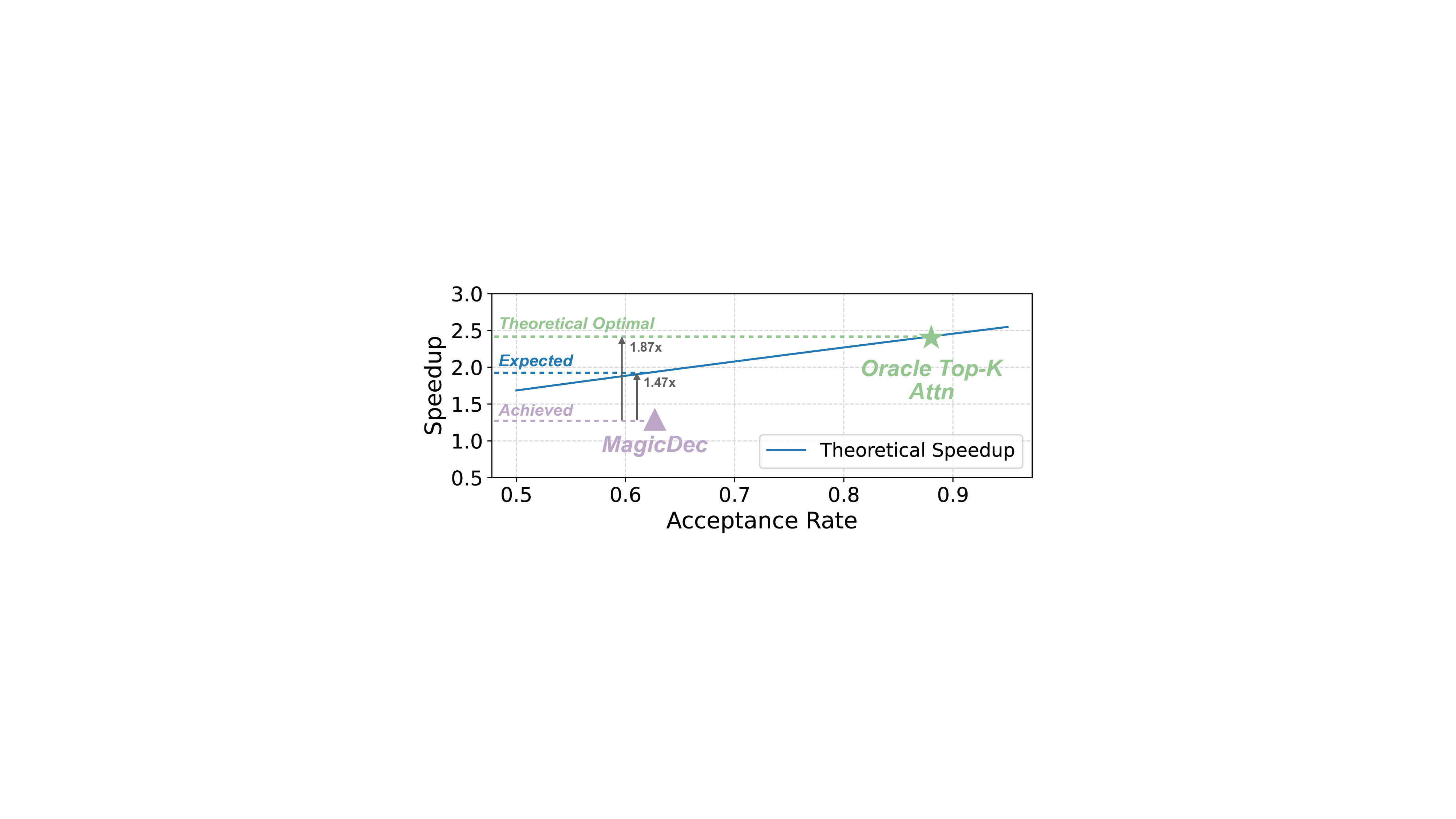
Other work explores training-free methods, which either em-
ploy rule-based heuristics (e.g., N-Gram (Fu et al., 2024))
or leverages the model itself via self-speculation (Liu et al.,
2024a; Sun et al., 2024). For example, MagicDec (Chen
et al., 2024) adopts the full model with a sliding window
arXiv:2512.01278v1 [cs.LG] 1 Dec 2025
Accelerating Large-Scale Reasoning Model Inference with Sparse Self-Speculative Decoding
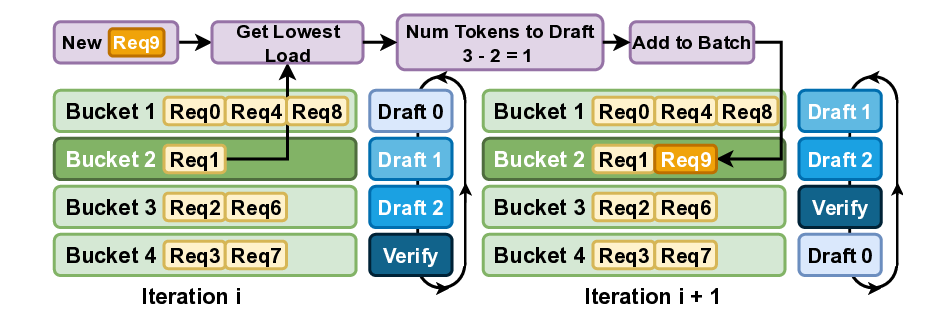
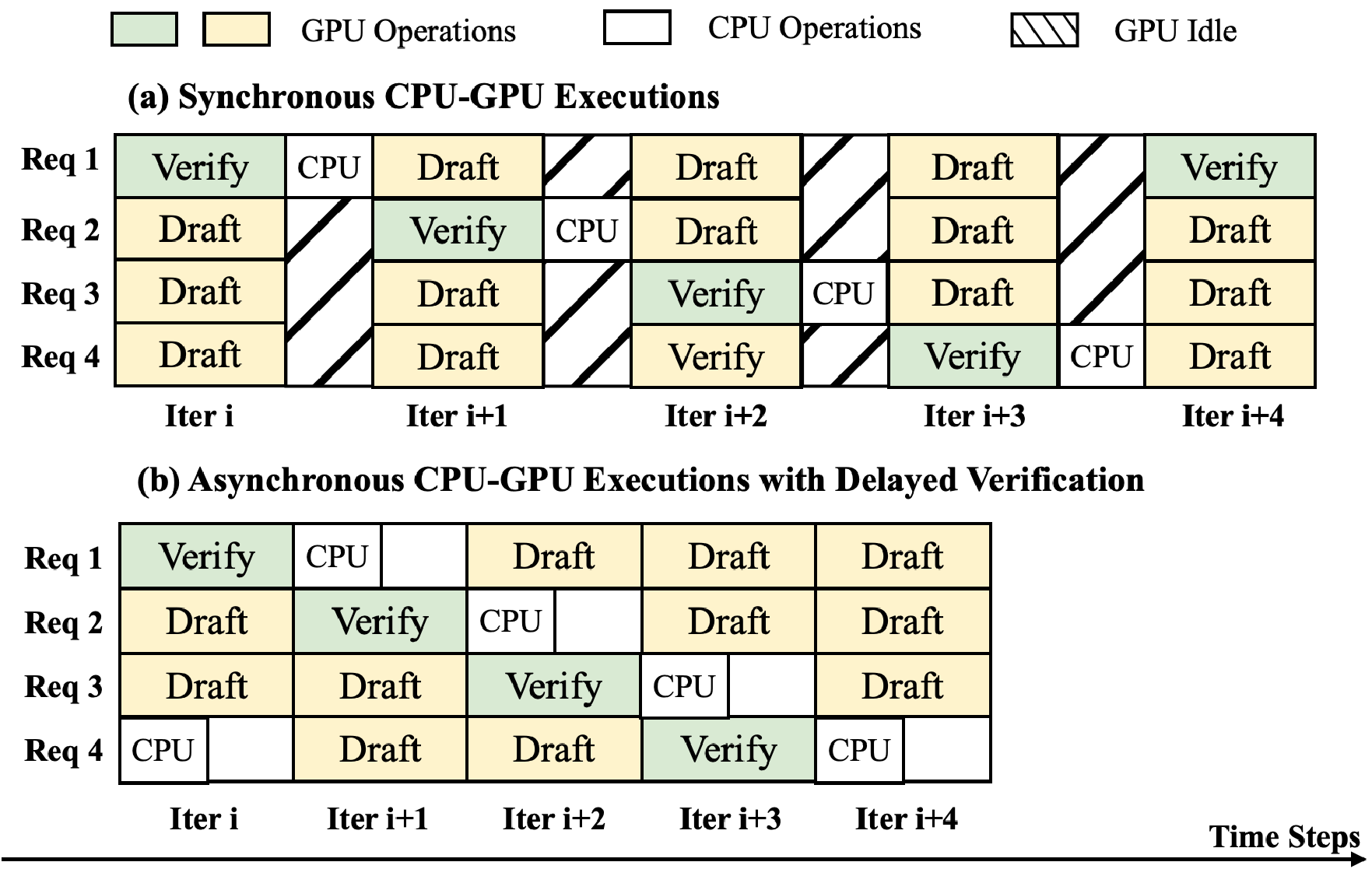
Figure 1. Comparison between autoregressive generation (a), draft model-based speculative decoding (b), and SparseSpec. SparseSpec
identifies the KV-Cache loading as the key bottleneck during token generation, and uses the same model weights with dynamic sparse
attention as the draft