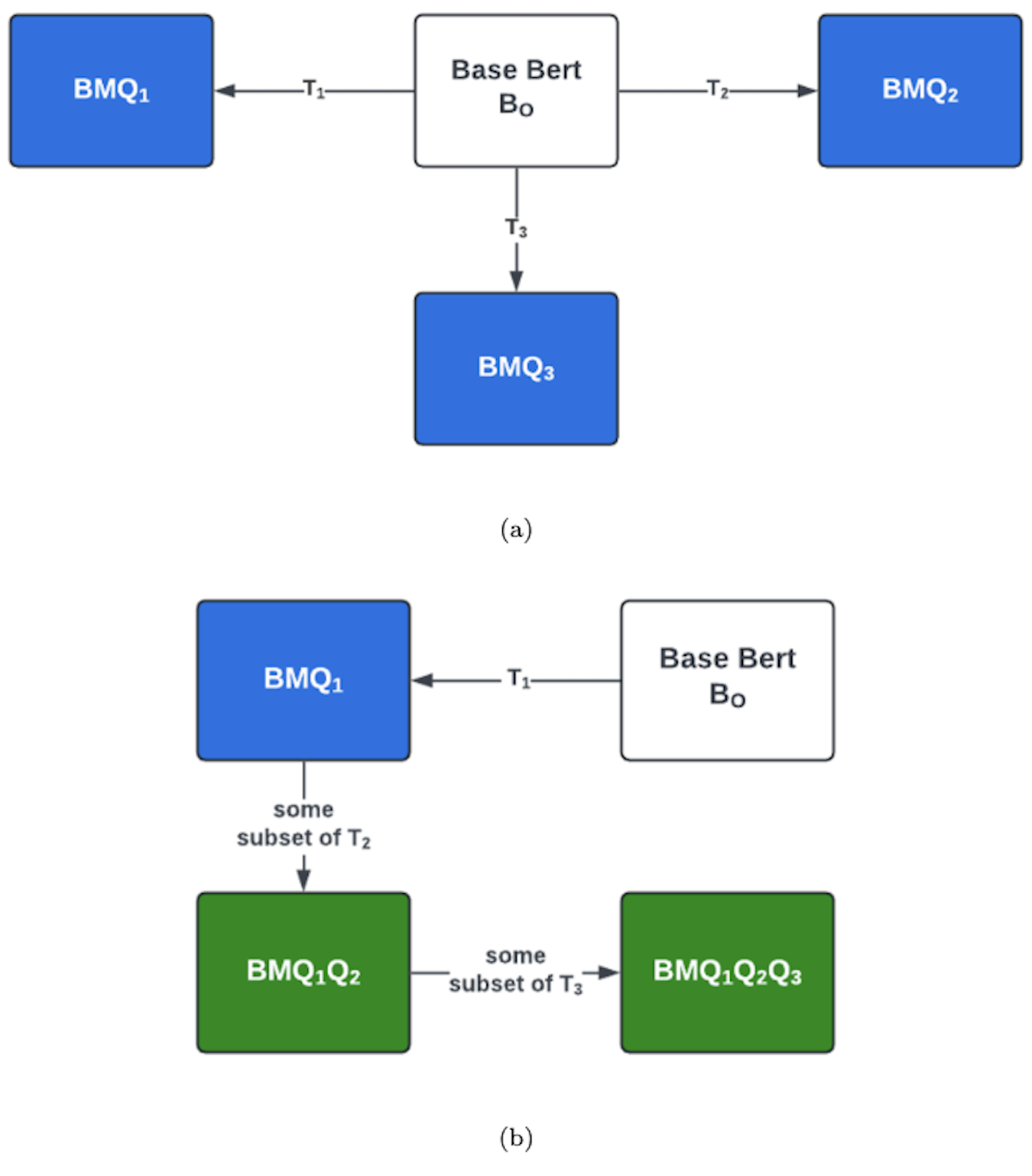
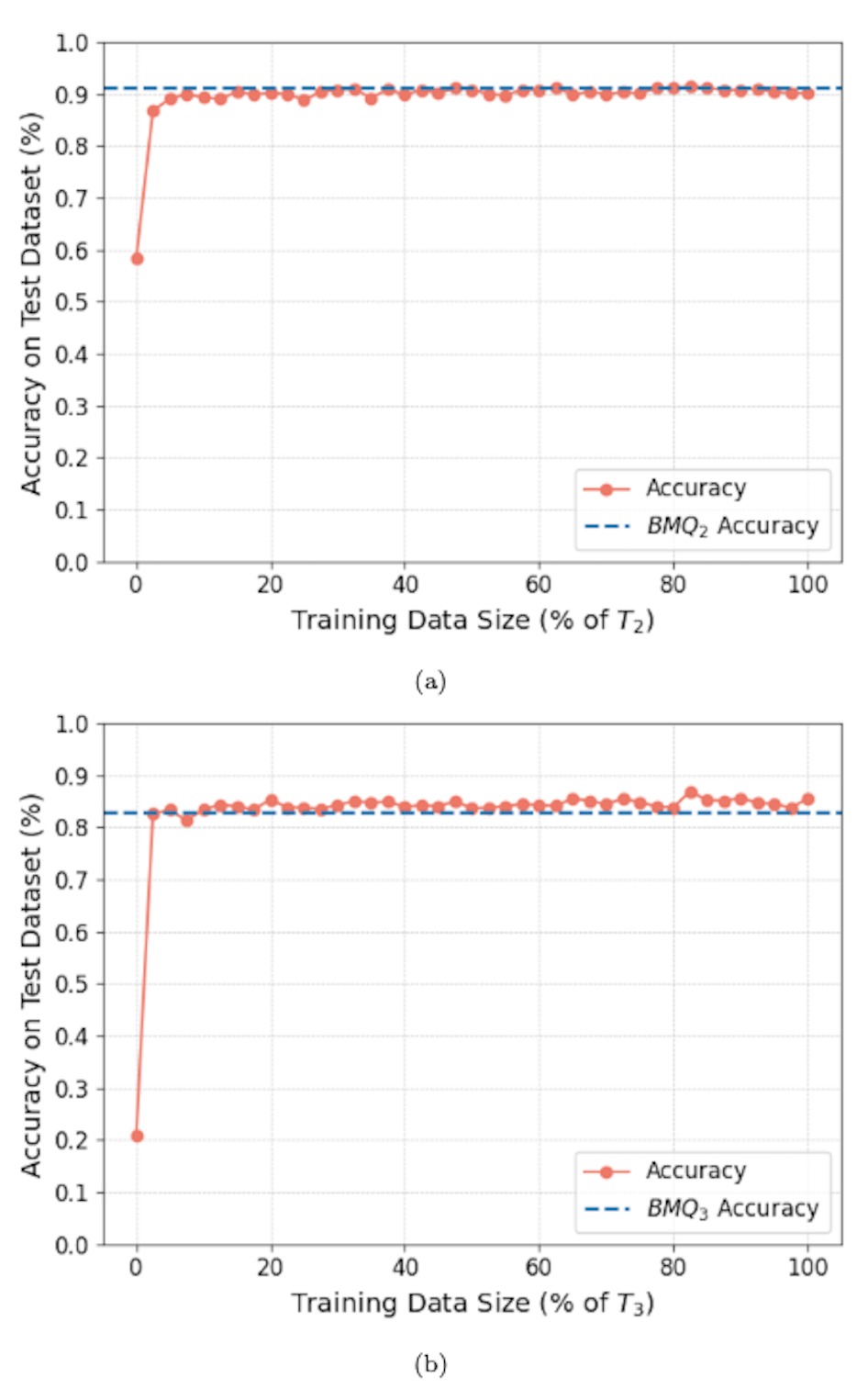
Constructed-response questions are crucial to encourage generative processing and test a learner's understanding of core concepts. However, the limited availability of instructor time, large class sizes, and other resource constraints pose significant challenges in providing timely and detailed evaluation, which is crucial for a holistic educational experience. In addition, providing timely and frequent assessments is challenging since manual grading is labor intensive, and automated grading is complex to generalize to every possible response scenario. This paper proposes a novel and practical approach to grade short-answer constructed-response questions. We discuss why this problem is challenging, define the nature of questions on which our method works, and finally propose a framework that instructors can use to evaluate their students' open-responses, utilizing near-domain data like data from similar questions administered in previous years. The proposed method outperforms the state of the art machine learning models as well as non-fine-tuned large language models like GPT 3.5, GPT 4, and GPT 4o by a considerable margin of over 10-20% in some cases, even after providing the LLMs with reference/model answers. Our framework does not require pre-written grading rubrics and is designed explicitly with practical classroom settings in mind. Our results also reveal exciting insights about learning from near-domain data, including what we term as accuracy and data advantages using human-labeled data, and we believe this is the first work to formalize the problem of automated short answer grading based on the near-domain data.
Assessments play a significant role in a student's learning outcomes. On one hand, they provide valuable information to students about where they are lacking and what improvements they can make. On the other hand, they can inform instructors about student progress and understanding of the various concepts being taught. Welldesigned assessments can also promote the development of students' logical aptitude, problem-solving, critical thinking, and other cognitive skills. Feedback from these assessments has a strong influence on their learning and achievement (Hattie and Timperley 2007). In fact, many historical works have identified the importance of feedback in either improving knowledge and acquiring skills (Azevedo and Bernard 1995;Bangert-Drowns et al. 1991;Corbett and Anderson 1989;Epstein et al. 2002;Moreno 2004;Pridemore and Klein 1995) or an essential factor in motivating the learning process (Lepper and Chabay 1985;Narciss and Huth 2004).
With an increasing demand for quality education, class sizes have grown considerably, while the availability of instructors and teaching assistants to assess student learning remain limited. This creates significant time constraints, increasing the need for efficient learning support that can provide timely feedback to the learners. Scaling this feedback has been a widely accepted challenge, often referred to as the “feedback” challenge (Wu et al. 2018).
To solve these problems, there have been efforts to leverage technology, especially AI models to automate feedback generation, addressing the existing constraints in education. Automated grading has emerged as the first step in this process because once we know which category the response falls in (correct or incorrect, for example), then it becomes easier to provide template-based feedback or more personalized feedback with some additional overhead work.
It is important to note that the challenge in the classification or evaluation of responses largely depends on the type of question being considered. Objective questions, such as multiple-choice, are relatively straightforward to grade since the possible response choices are limited. However, these questions do not provide much insight into a student’s learning journey. In contrast, constructed-response questions (CRQ) provide a great way to understand student thinking more deeply, serving as a powerful means of evaluating a learner’s understanding of concepts. These questions require learners to organize their thoughts, provide explanations, and demonstrate higher-level thinking skills which further requires an ability to reason through elaborate answers (Zhao et al. 2021). Short answers are a type of CRQ that asks learners to write their answers in a few sentences. The grading of these questions focuses on the content, instead of the writing quality. Despite their effectiveness, compared to objective questions, CRQs are significantly more challenging to grade due to the complexity and variability of student responses.
Although Automated Short Answer Grading (ASAG) is a widely studied problem, it has emerged to be a hard problem and the following challenges have been identified as the major causes for it and other human-centered AI tasks (Wu et al. 2018;Malik et al. 2021):
- Student work shows a great amount of diversity, with many responses being unique (long tail/zipf distribution). Thus, statistical supervised grading techniques would find it hard to produce promising results. 2. The manual labeling of responses is subjective, laborious, time-consuming and expensive. Thus, access to realtively large annotated datasets is difficult. 3. Grading is a domain where not only accuracy but also precision (reproducibility) is paramount due to the high stakes involved in misgrading. 4. The entire grading process must be transparent and justifiable to instructors and students alike.
ASAG has a strong literature background with people using many approaches, from traditional statistical ones to modern day neural networks (Zhai et al. 2020).
The choice of what approach to use mostly boils down to the availability of enough manually annotated dataset. If enough data is available to train the models, one would likely assume that high performance can be obtained by just using supervised learning techniques or statistical models. This is in part due to the ability to fine tune models to learn patterns present in domain specific tasks, like evaluating science explanations or reasoning (Jescovitch et al. 2021).
Various methods have been studied for this application. For short-answer grading, Heilman and Madnani (2013) took a domain adaptation approach with using word and character n-gram features. Sultan et al. (2016) employs supervised learning methods like linear regression, and Hou and Tsao (2011) uses support vector machines and incorporates POS tags and term frequency to get good results. Madnani et al. (2013) built a logistic regression classifier using simple featu
This content is AI-processed based on open access ArXiv data.