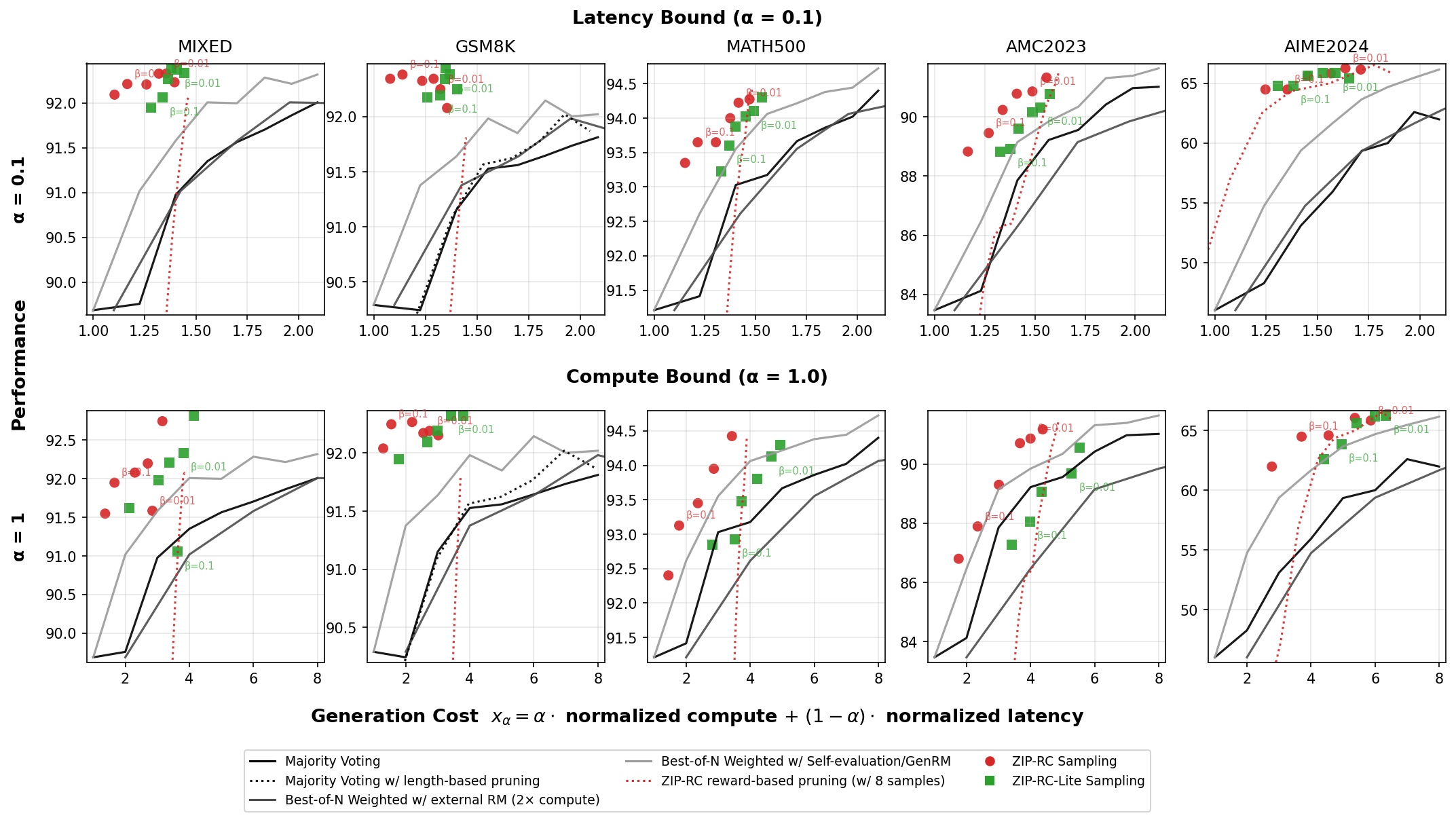
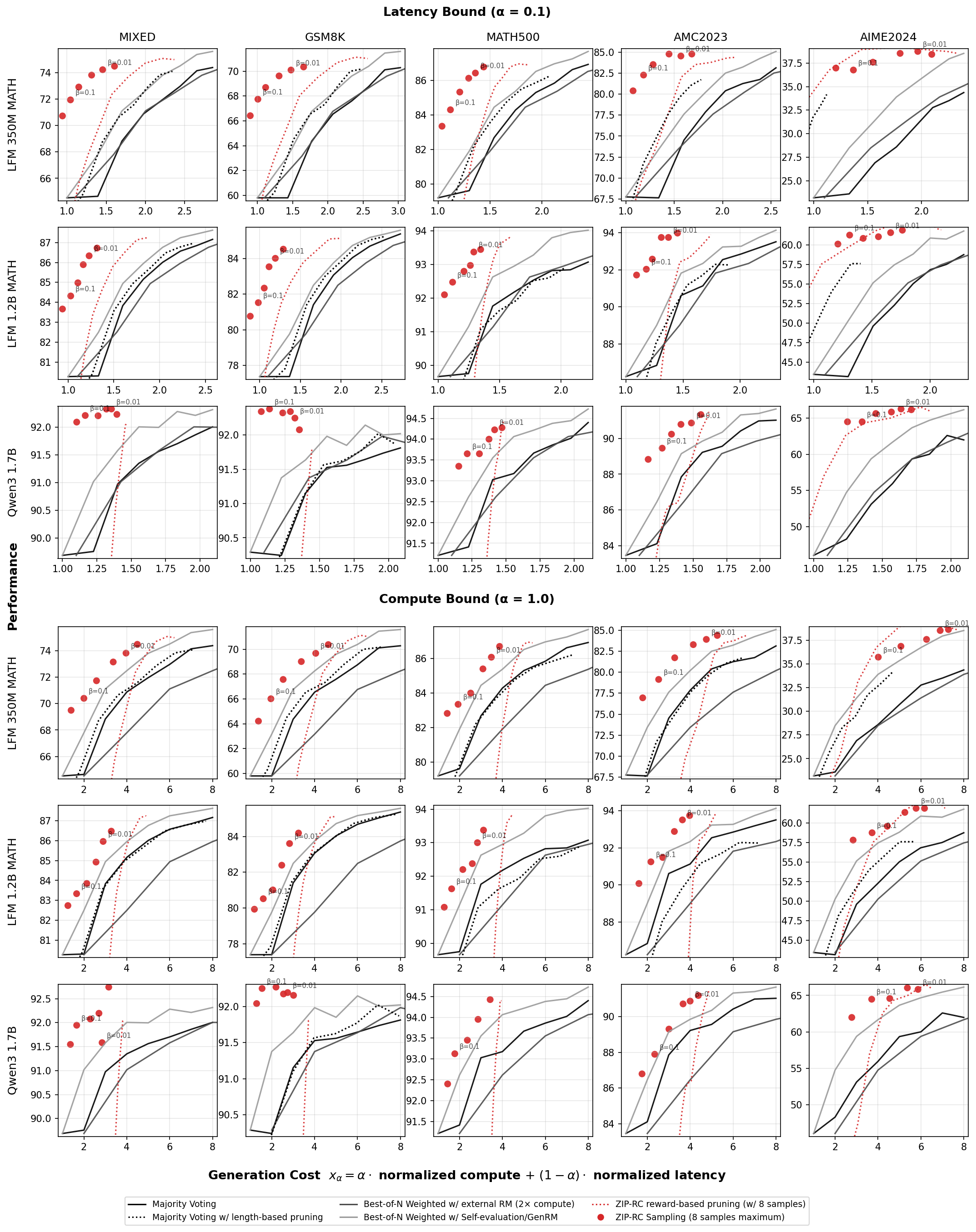
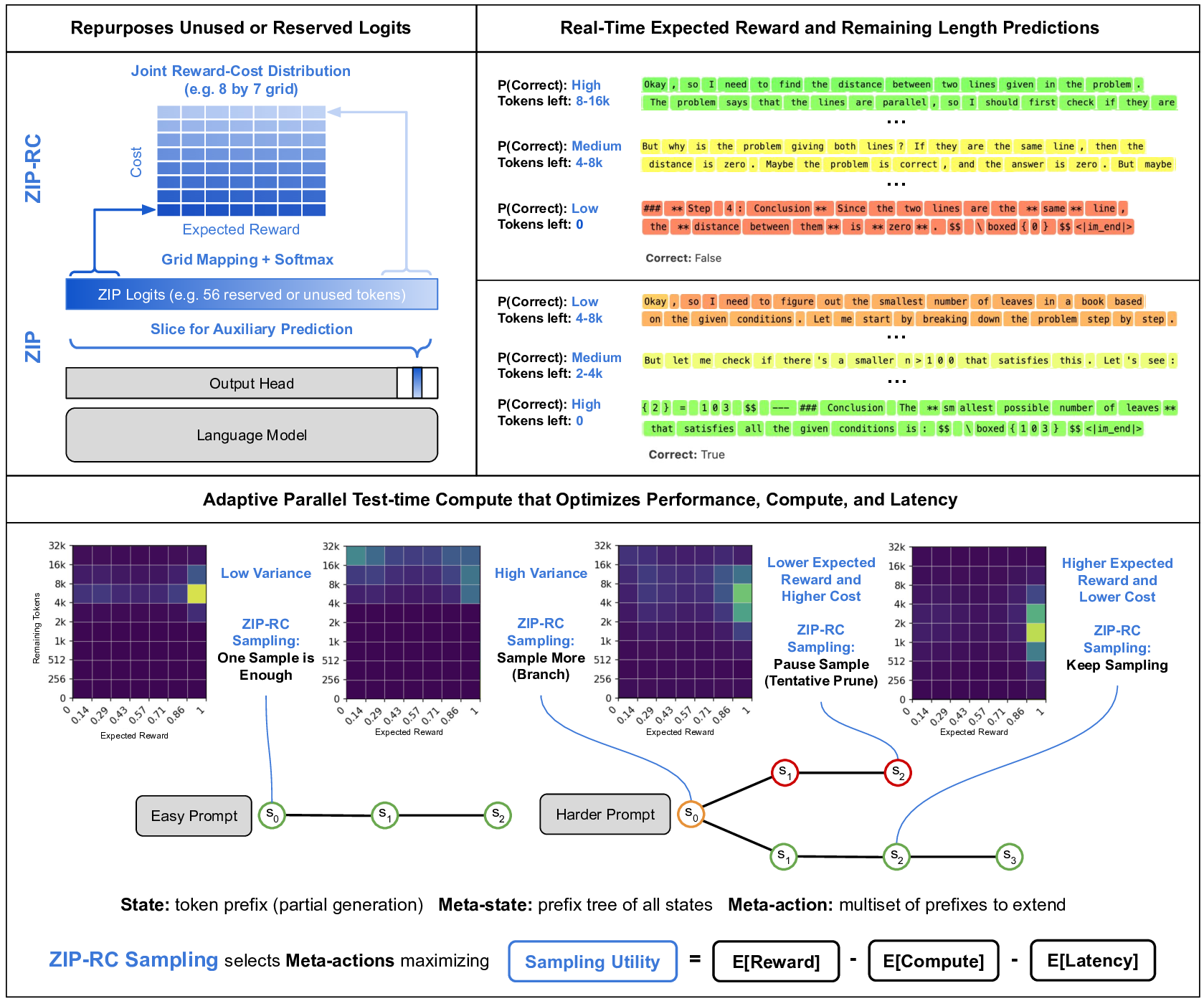
Large language models excel at reasoning but lack key aspects of introspection, including anticipating their own success and the computation required to achieve it. Humans use real-time introspection to decide how much effort to invest, when to make multiple attempts, when to stop, and when to signal success or failure. Without this, LLMs struggle to make intelligent meta-cognition decisions. Test-time scaling methods like Best-of-N drive up cost and latency by using a fixed budget of samples regardless of the marginal benefit of each one at any point in generation, and the absence of confidence signals can mislead people, prevent appropriate escalation to better tools, and undermine trustworthiness. Learned verifiers or reward models can provide confidence estimates, but do not enable adaptive inference and add substantial cost by requiring extra models or forward passes. We present ZIP-RC, which equips models with zero-overhead introspective predictions of reward and cost. At every token, ZIP-RC reuses reserved or unused logits in the same forward pass as next-token prediction to output a joint distribution over final reward and remaining length -- no extra models, architecture change, or inference overhead. This full joint distribution is used to compute a sampling utility which is the linear combination of the expected maximum reward, total compute, and latency of set of samples if generated to completion. During inference, we maximize this utility with meta-actions that determine which prefix of tokens to continue or initiate sampling from. On mixed-difficulty mathematical benchmarks, ZIP-RC improves accuracy by up to 12% over majority voting at equal or lower average cost, and traces smooth Pareto frontiers between quality, compute, and latency. By providing real-time reward-cost introspection, ZIP-RC enables adaptive, efficient reasoning.
The rapid evolution of large language models (LLMs) has enabled unprecedented capabilities in complex tasks ranging from general question-answering to automated coding and mathematical reasoning (Brown et al., 2020;Kojima et al., 2022;Wei et al., 2022). To become truly reliable, however, LLMs must develop a capacity for introspection: the ability to assess their own progress and anticipate the effort required to succeed. Humans can be instrospective and can effectively act upon this information to make better decisions. If a model could predict its future success (reward) and the resources needed to achieve it (cost), it could allocate compute more effectively, expose likely failure modes before they occur, and provide transparent signals about confidence and anticipated "thinking time." A key obstacle has been that such introspection typically requires auxiliary mechanisms that add nontrivial computational overhead and complexity.
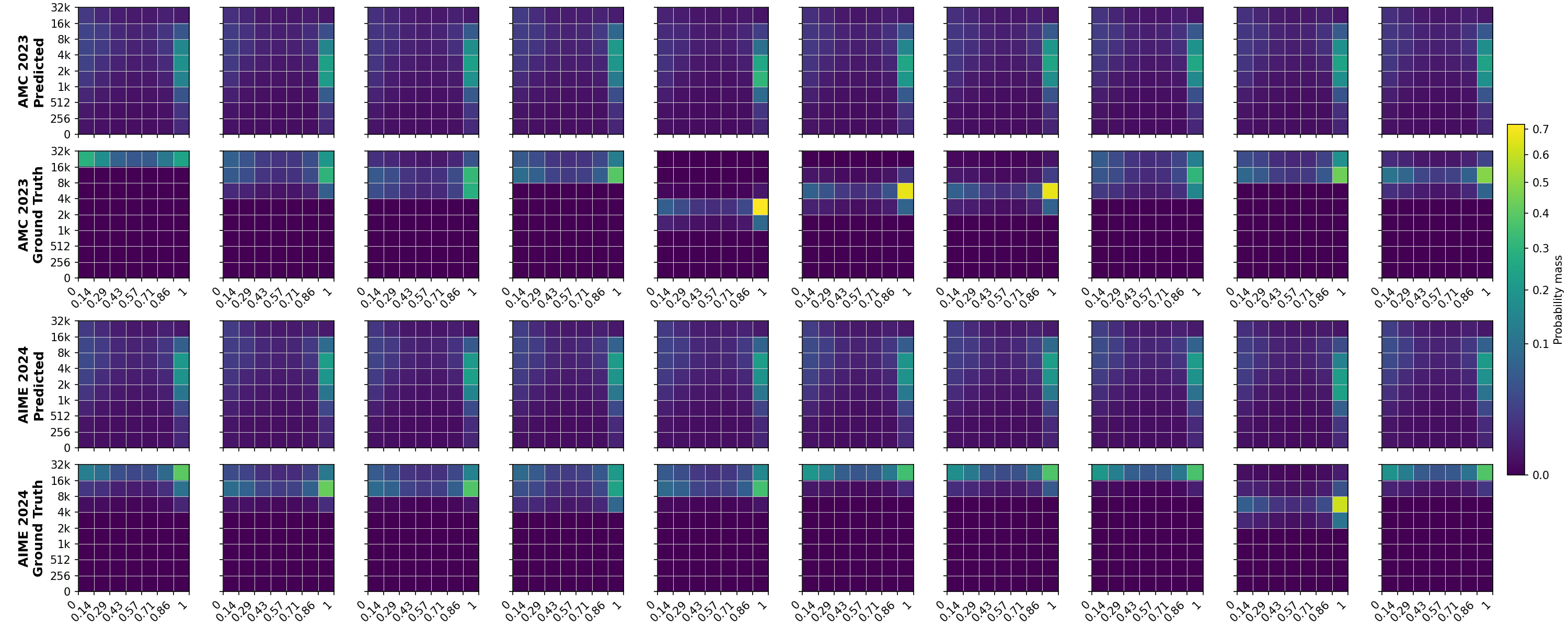
The need for introspection is growing more urgent as reasoning traces continue to lengthen. Recent work shows that scaling test-time compute through reasoning often yields larger performance gains Finally, the bottom shows the joint distributions from ZIP-RC and how they indicate optimal sampling strategies. ZIP-RC sampling uses these joint distributions to calculate a sampling utility to autonomously select meta-actions for optimal test-time compute allocation.
than simply increasing model size (Wang et al., 2023b;Yao et al., 2023;Jaech et al., 2024;Snell et al., 2024;Guo et al., 2025). But performance has scaled only logarithmically with additional computation, forcing models to produce ever longer chains of thought-sometimes tens of thousands of tokens today and plausibly orders of magnitude more in the future (Wu et al., 2024). With time as a fundamental limiting resource, a critical question is how to use a fixed wall-clock budget to achieve the highest performance possible.
A promising approach is the canonical test-time scaling method Best-of-N (BoN) sampling, which generates N candidates and selects the best using a learned verifier, reward model, or majority vote (Cobbe et al., 2021;Zheng et al., 2023;Kwon et al., 2023;Lightman et al., 2023b;Wang et al., 2023b). While appealing in theory due to its parallelism, BoN is not adaptive: every trajectory is carried to completion regardless of promise. On easy tasks this wastes computation, and on hard tasks it inflates latency, since wall-clock time is governed by the longest generation and both length and total compute grow with N (Leviathan et al., 2023). What is missing is a way for models to anticipate which samples are worth continuing and which should be paused or abandoned, so that parallel effort is concentrated on trajectories most likely to succeed and fastest to complete.
Early-stopping and pruning methods aim to reduce BoN’s inefficiency by terminating unpromising samples mid-generation (Fu et al., 2025;Huang et al., 2025). These approaches are valuable first steps toward adaptivity, but they typically rely on scalar signals-such as a confidence score from a classifier-or on simple heuristics. This creates two limitations. First, a scalar cannot capture the central reward-cost trade-off: a low-confidence trajectory may be worthwhile if nearly finished, while a high-confidence one may be impractical if it implies a long, costly continuation. Second, these methods do not quantify the marginal benefit of drawing more samples, which depends on the entire reward distribution rather than its expectation. As a result, such strategies can reduce compute in some cases but often fail to improve wall-clock time, falling short of the broader goal of enabling models to allocate compute adaptively-expending more effort on difficult queries and less on easy ones (Manvi et al., 2024;Graves, 2016).
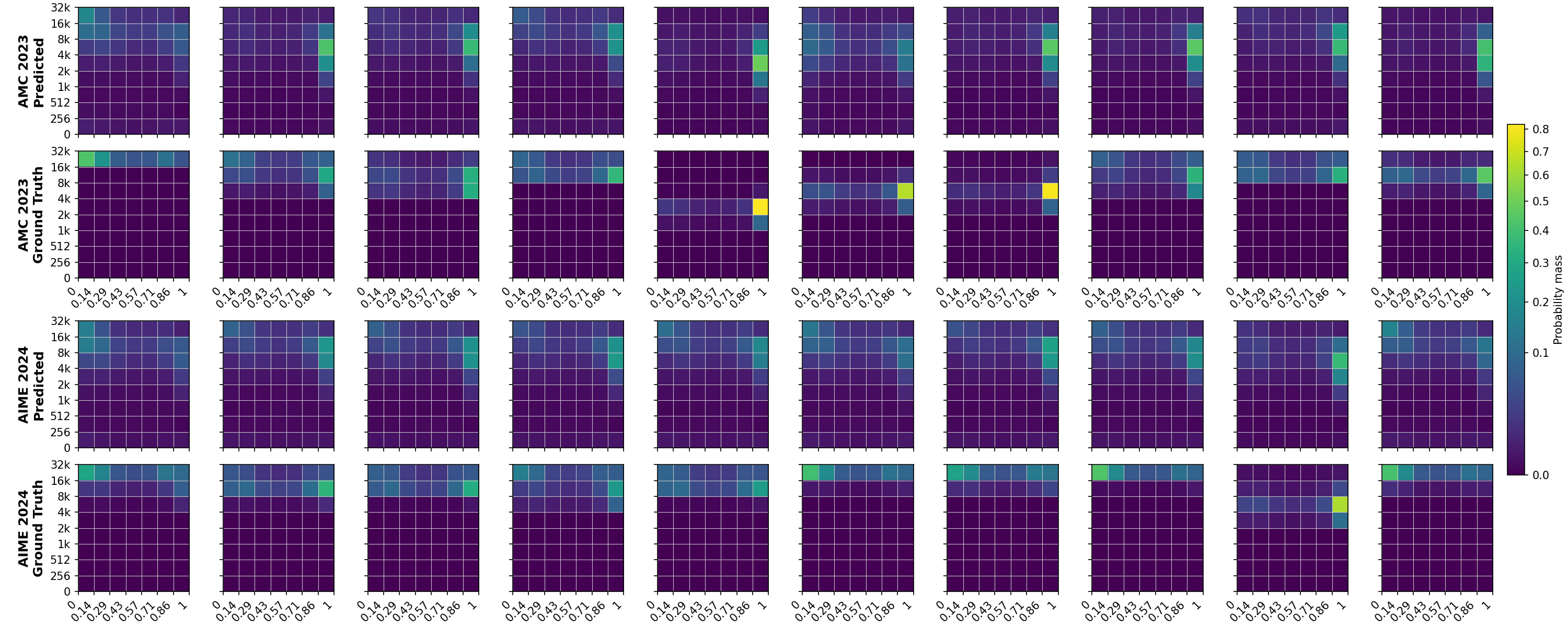
We introduce ZIP-RC, which addresses these limitations by training language models to provide zero-overhead introspective predictions of the joint distribution over reward and cost. At each decoding step, unused vocabulary logits parameterize a joint distribution over final reward and remaining generation length (see fig. 1). Access to the full joint-not just a scalar-enables order-statistic calculations that quantify the marginal utility of continuing partial samples or spawning additional samples. For example, when the predicted reward distribution has high variance, allocating more samples can substantially increase the expected maximum reward. We maximize a sampling utility that explicitly balances accuracy, compute, and latency through a linear combination of their expectations. The coefficients of the linear combination can be tuned to the desired balance of reward, compute, and latency. Optimizing this utility produces the behaviors observed in our experiments: when latency is prioritized, ZIP-RC spawns larger pools of samples and schedules early pruning to chase an early finisher; when compute is prioritized, it deprioritiz
This content is AI-processed based on open access ArXiv data.