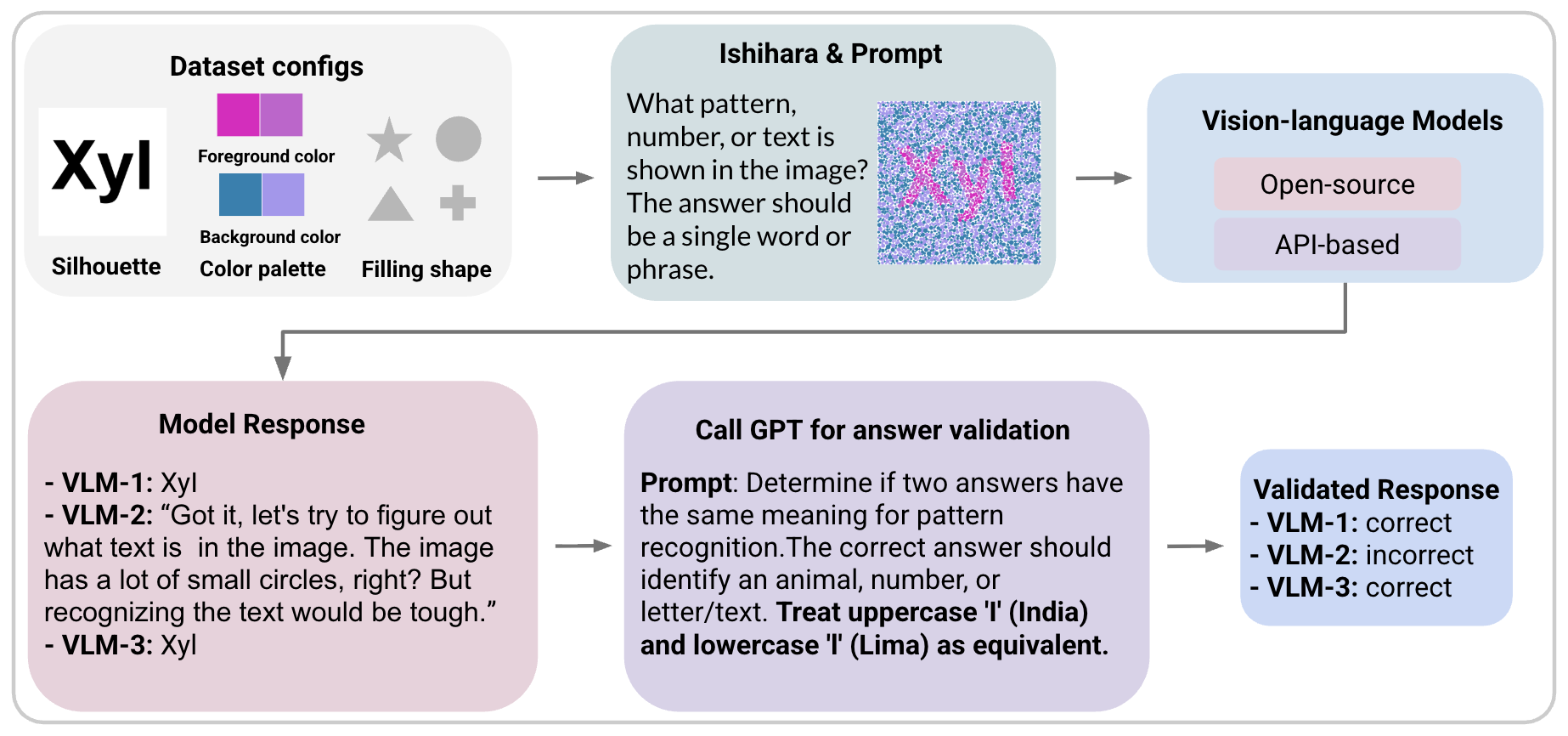
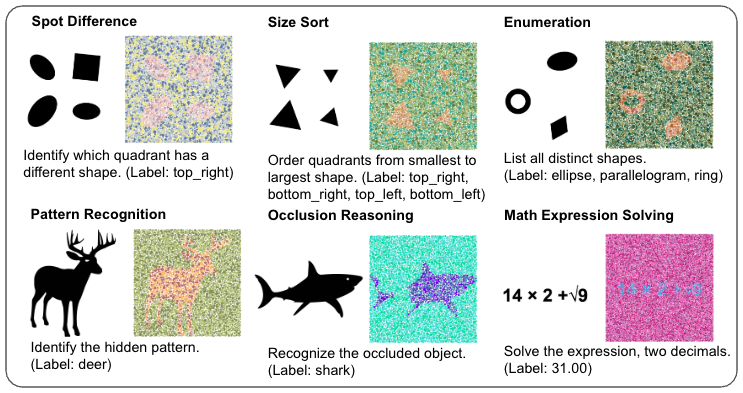
Vision-Language Models (VLMs) have advanced multimodal understanding, yet still struggle when targets are embedded in cluttered backgrounds requiring figure-ground segregation. To address this, we introduce ChromouVQA, a large-scale, multi-task benchmark based on Ishihara-style chromatic camouflaged images. We extend classic dot plates with multiple fill geometries and vary chromatic separation, density, size, occlusion, and rotation, recording full metadata for reproducibility. The benchmark covers nine vision-question-answering tasks, including recognition, counting, comparison, and spatial reasoning. Evaluations of humans and VLMs reveal large gaps, especially under subtle chromatic contrast or disruptive geometric fills. We also propose a model-agnostic contrastive recipe aligning silhouettes with their camouflaged renderings, improving recovery of global shapes. ChromouVQA provides a compact, controlled benchmark for reproducible evaluation and extension. Code and dataset are available at https://github.com/Chromou-VQA-Benchmark/Chromou-VQA.
Vision-Language Models (VLMs) have made rapid progress, demonstrating impressive performance across a wide range of multimodal tasks such as image and video captioning [1,2], visual question answering [3,4], and open-domain reasoning [5,6]. In addition, the broader literature on language and multimodal modeling continues to expand across diverse tasks [7,8,9,10,11,12,13,14,15,16]. On many established benchmarks, modern models even approach or surpass human-level accuracy.
Most existing benchmarks emphasize clean, high-contrast images where objects are easily distinguishable from their surroundings. Yet visual information can remain accessible to humans but challenging for models when foreground and background share similar colors and textures, causing local cues to fail. For example, safety-critical settings such as aviation use cockpit displays and warning icons that may appear against patterned or color-similar backdrops; humans can still recognize these signals once the figure emerges, but current VLMs often misidentify or overlook them. This gap raises a central question: can VLMs reliably perceive and ground content when chromatic camouflage disrupts local cues?
We introduce ChromouVQA, a benchmark for systematic evaluation of VLMs under chromatic camouflage. We draw inspiration from Ishihara-style designs, not for their medical use in color-vision testing, but because they offer several properties that make them particularly well-suited for controlled benchmarking. First, camouflage difficulty can be precisely tuned by adjusting color distance, dot density, and pattern geometry, allowing interpretable performance curves. Second, recognition requires integrating subtle chromatic differences across the entire image, which stresses models that rely heavily on local patches rather than global structure. Third, the synthetic generator enables scalability and reproducibility, producing large-scale data with complete metadata while avoiding confounds from uncontrolled natural imagery such as lighting or clutter. Finally, Ishihara-style patterns offer a consistent human reference, serving as a strong baseline.
The dataset contains 70,200 camouflaged renderings derived from 17,100 silhouettes, spanning 61 palette-shape configurations and paired with nine question-answer tasks. These tasks extend beyond recognition to include reasoning skills such as counting, comparison, and arithmetic, all under camouflage conditions. Human baselines show near-ceiling accuracy, while state-of-the-art VLMs struggle, with gaps that widen under subtle chromatic contrast and non-dot fills. To mitigate this, we propose a contrastive adaptation framework in which clean silhouettes act as anchors and negatives, encouraging models to recover hidden patterns. This improves performance across different backbones and establishes a reference baseline for future study.
Our contributions are as follows: (1) We introduce Chro-mouVQA, a large-scale, multi-task dataset of Ishihara-style camouflaged images for vision-language tasks, together with a novel, highly flexible and controllable image generation pipeline. (2) We conduct a comprehensive empirical study across a wide range of open-source and proprietary VLMs, highlighting significant performance gaps between current models and human perception on camouflaged image tasks.
(3) We propose a contrastive training framework that leverages silhouette-camouflage pairs to enhance global shape recovery, providing a strong baseline for this domain.
Vision-Language Models. Vision-Language Models (VLMs) have advanced rapidly in recent years. LLaVA [17] demonstrates the effectiveness of instruction tuning, while Qwen2.5-VL [5] introduces dynamic resolution. Other models, such as InternVL [18], LLaMA 3 [19], and Video-LLaMA [20], rely on large-scale pretraining across diverse modalities. Proprietary systems including GPT-4V [21] and Gemini [22] report near-human performance on vision tasks. Despite these advances, existing models have not been systematically evaluated on their ability to extract abstract patterns in complex or noisy settings-particularly in chromatic camouflage images. Visual Question Answering. Visual Question Answering (VQA) is a rapidly developing research area in which models generate text answers to questions grounded in images.
Early work [3] introduced a large-scale benchmark that established VQA as a core multimodal task. Subsequent datasets expanded the scope: OK-VQA [23] emphasizes knowledgebased reasoning requiring external information; VAGUE [24] evaluates models’ ability to resolve ambiguous queries through visual context; and PMC-VQA [25] provides diverse medical images with curated question-answer pairs across multiple modalities and diseases. However, no existing VQA benchmark comprehensively evaluates models’ ability to interpret chromatic camouflage images. Vision Illusion and Hallucination. Visual illusion and hallucination remain key challenges for VLMs. Spo
This content is AI-processed based on open access ArXiv data.