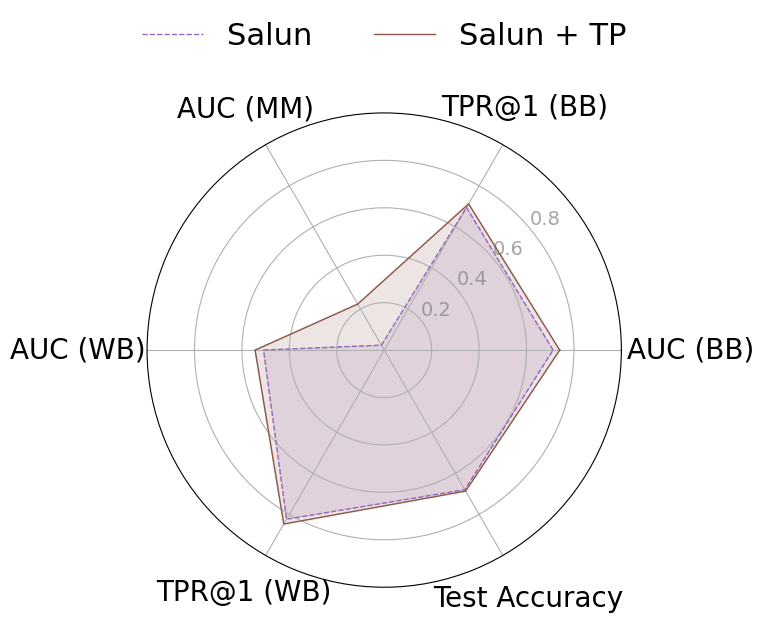
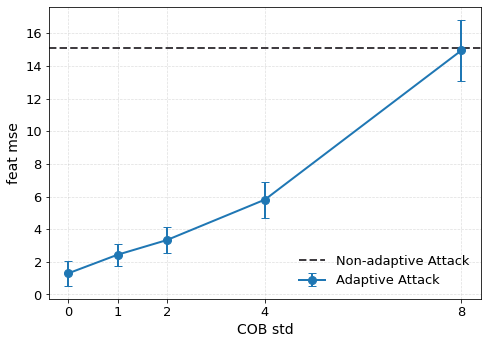
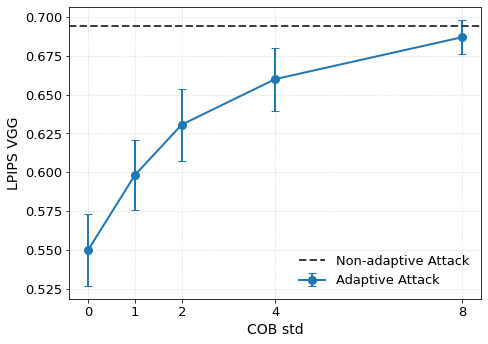
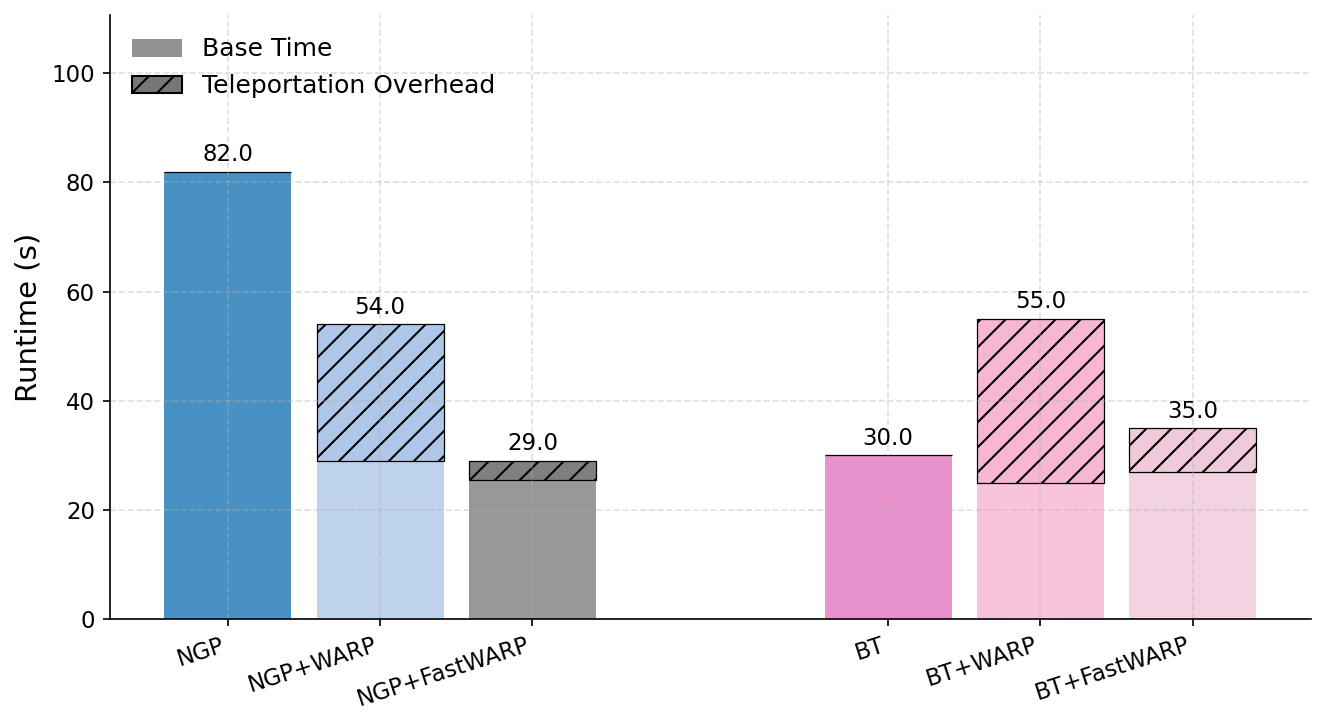
Approximate machine unlearning aims to efficiently remove the influence of specific data points from a trained model, offering a practical alternative to full retraining. However, it introduces privacy risks: an adversary with access to pre- and post-unlearning models can exploit their differences for membership inference or data reconstruction. We show these vulnerabilities arise from two factors: large gradient norms of forget-set samples and the close proximity of unlearned parameters to the original model. To demonstrate their severity, we propose unlearning-specific membership inference and reconstruction attacks, showing that several state-of-the-art methods (e.g., NGP, SCRUB) remain vulnerable. To mitigate this leakage, we introduce WARP, a plug-and-play teleportation defense that leverages neural network symmetries to reduce forget-set gradient energy and increase parameter dispersion while preserving predictions. This reparameterization obfuscates the signal of forgotten data, making it harder for attackers to distinguish forgotten samples from non-members or recover them via reconstruction. Across six unlearning algorithms, our approach achieves consistent privacy gains, reducing adversarial advantage (AUC) by up to 64% in black-box and 92% in white-box settings, while maintaining accuracy on retained data. These results highlight teleportation as a general tool for reducing attack success in approximate unlearning.
Machine unlearning (MU) aims to enforce the "right to be forgotten" by updating a trained model so that a designated forget-set has no influence Bourtoule et al. [2021], Zhao et al. [2024]. The ideal outcome matches retraining from scratch on the remaining retain-set, with both the model's parameters and predictions unaffected by the forgotten data, and without degrading generalization. A primary motivation for machine unlearning is to ensure privacy compliance for sensitive information Wang et al. [2025a]. Once personal data is used for training, models may memorize specific details Ravikumar et al. [2024a], creating risks of privacy breaches Bourtoule et al. [2021], Carlini et al. [2022b]. Unlearning addresses this by eliminating such traces, preventing exposure. The most direct solution is retraining from scratch without the forget set, but this is computationally prohibitive. Exact Unlearning methods such as SISA Bourtoule et al. [2021] reduce cost by modifying training to allow provable deletion, but they require proactive deployment and add overhead. To avoid full retraining, Approximate Unlearning methods finetune the original model to forget the target data while preserving utility Kurmanji et al. [2023], Chundawat et al. [2023a], Golatkar et al. [2020], Thudi et al. [2022], trading computational efficiency against formal guarantees.
At the same time, ML models are vulnerable to privacy attacks Rigaki and Garcia [2023]. In Membership Inference Attacks (MIA), an adversary determines whether a given sample was part of the training set Shokri et al. [2017]. In Data Reconstruction Attacks (DRA), the adversary seeks to recover raw data (or a close approximation) from model outputs or parameters Yin et al. [2021], Li et al. [2022], Jeon et al. [2021], Fang et al. [2023]. These attacks have been demonstrated in both black-box (access to outputs) and white-box (access to weights) settings Nasr et al. [2019].
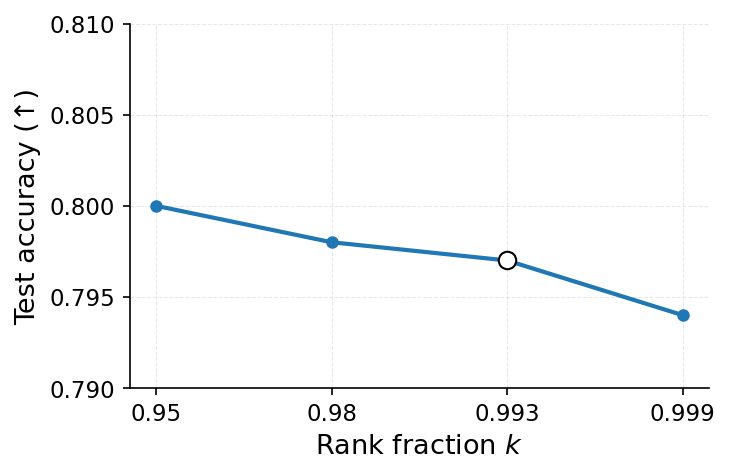
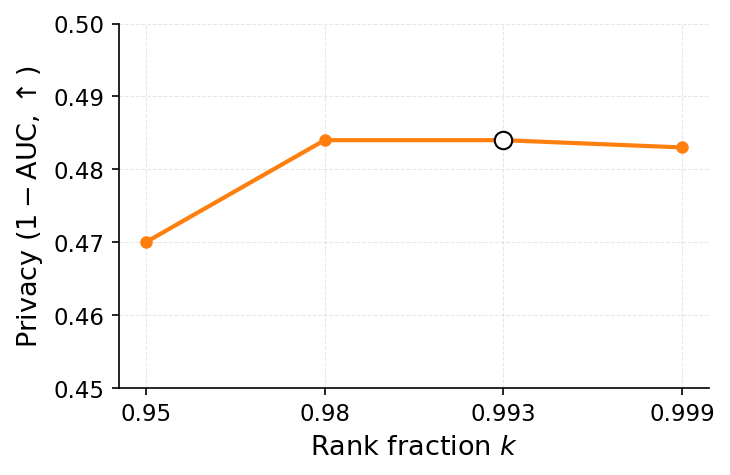
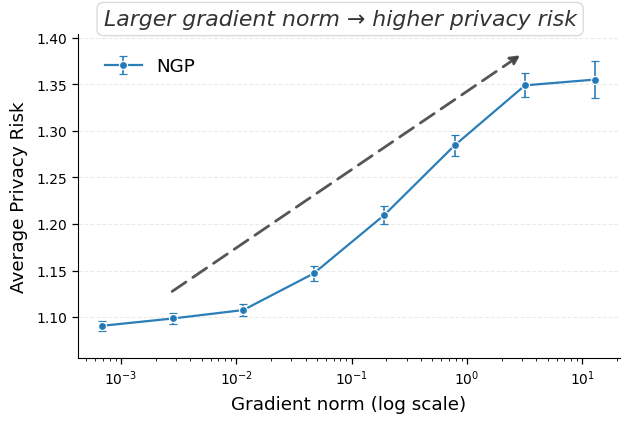
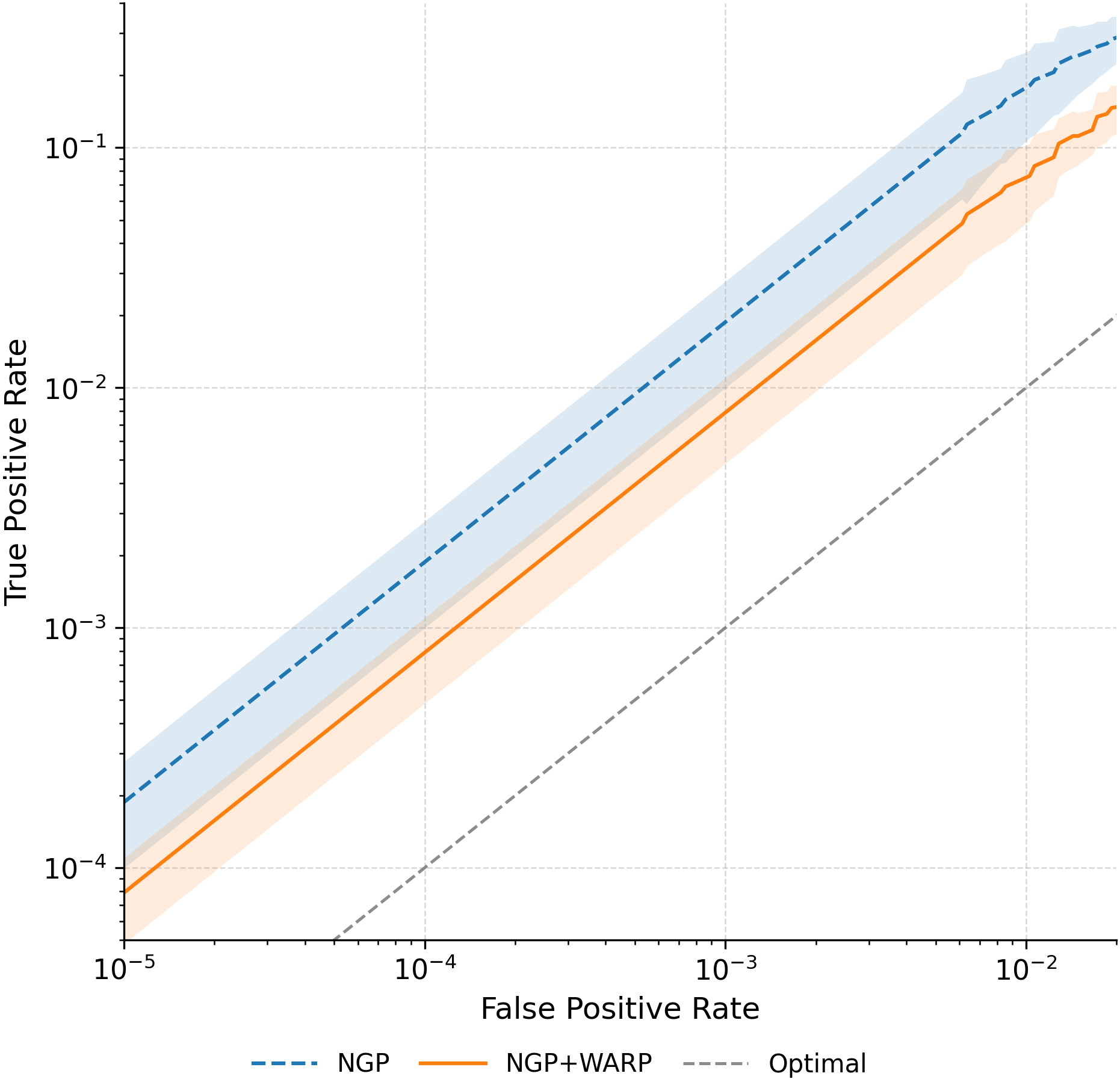
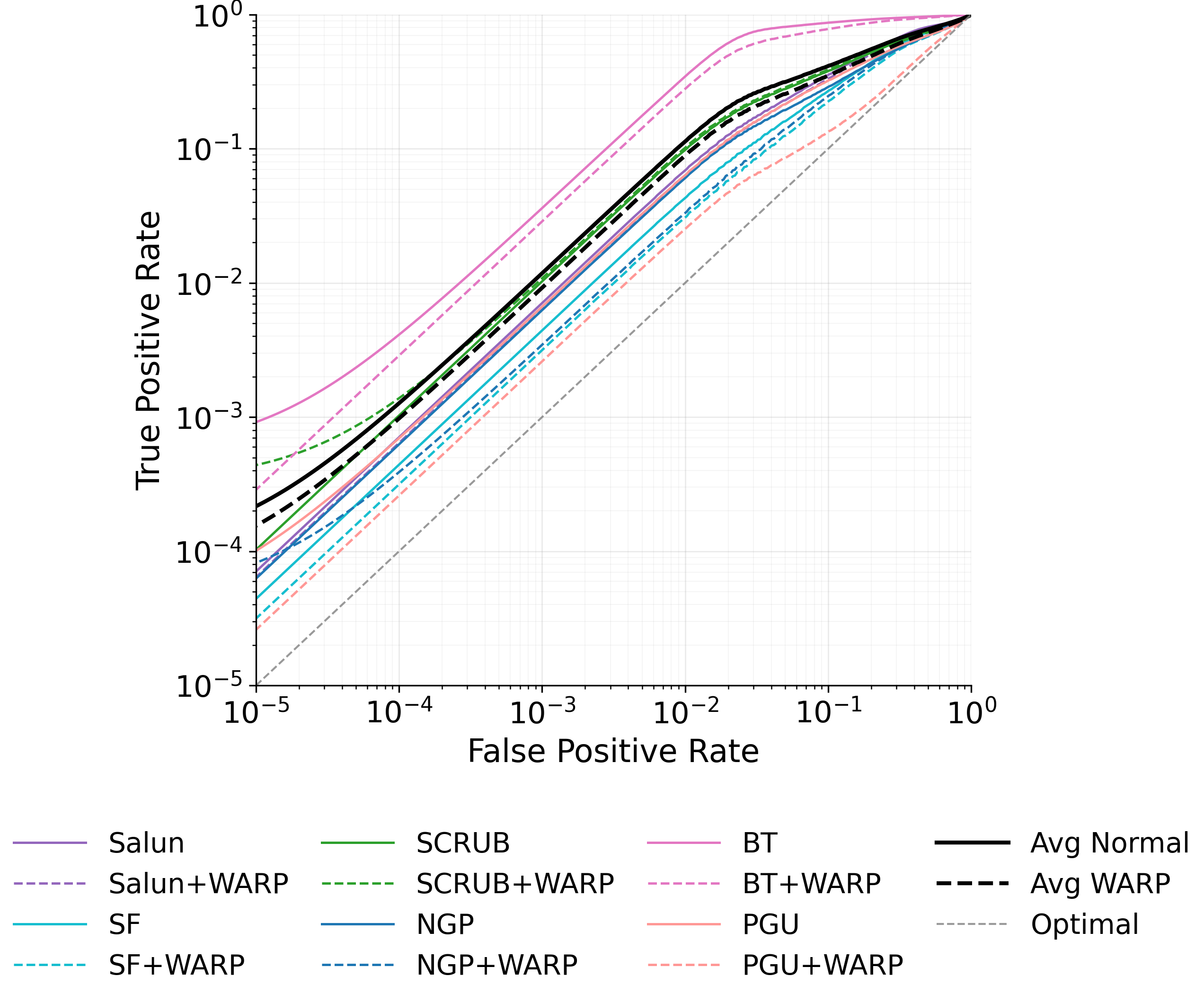
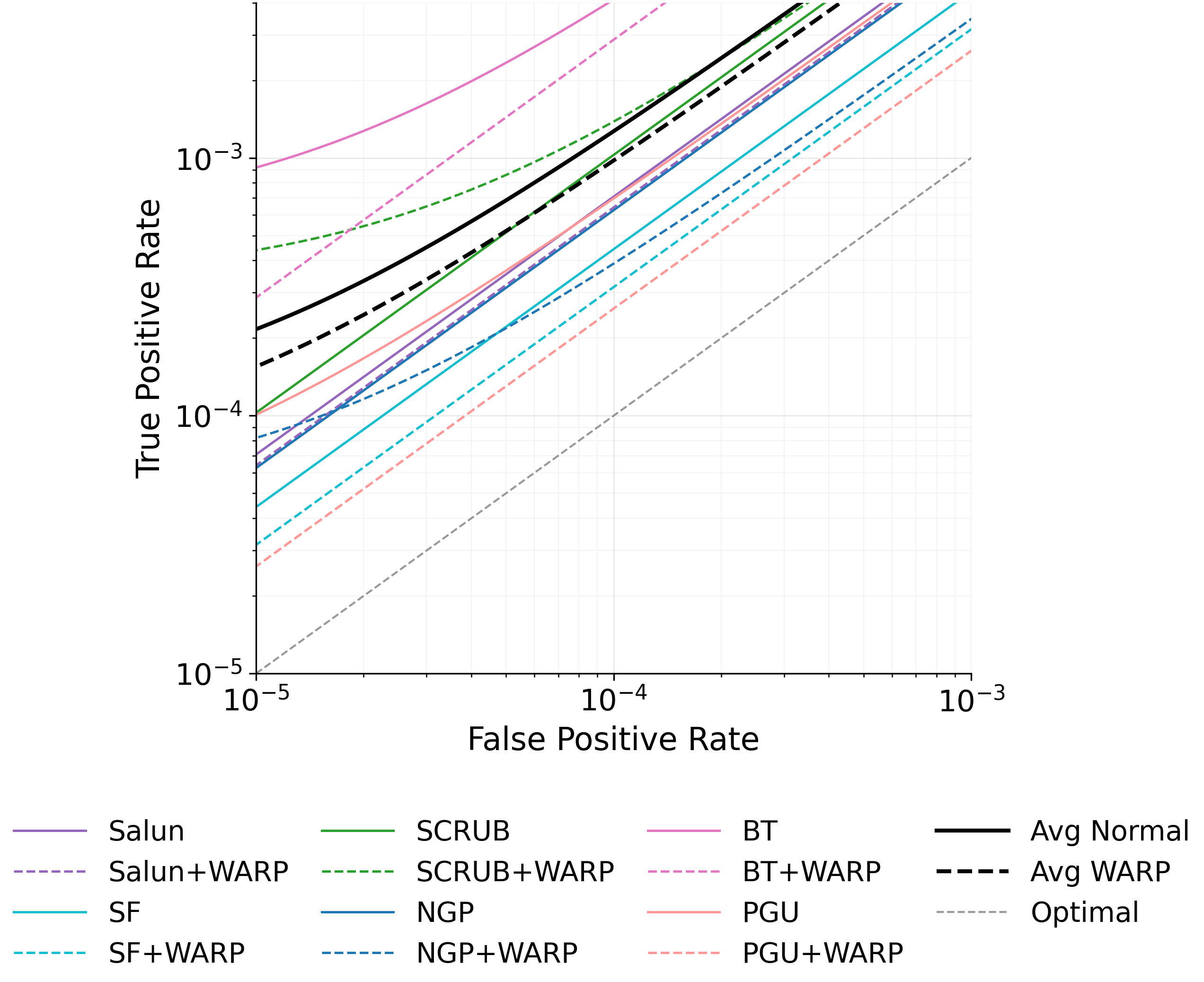
Ironically, MU itself can leak the very data it aims to erase. Given access to both the original and unlearned models, an adversary can mount differencing attacks Hu et al. [2024], Bertran et al. [2024], which substantially improve reconstruction success. Even models previously resistant to MIAs can become vulnerable once deletion is performed Bertran et al. [2024], Chen et al. [2021]. The key observation is that the parameter difference between the two models approximates the gradient of the forgotten sample (up to second-order terms), effectively releasing it to the adversary. Geiping et al. [2020], can then reconstruct the forgotten data. Thus, approximate unlearning methods, especially gradient-ascent variants Kurmanji et al. [2023], can inadvertently compromise privacy instead of ensuring it. In this work, we aim to strengthen MU against privacy attacks by characterizing two key factors driving leakage. The first, illustrated in Figure 1, is that a forgotten sample’s privacy risk correlates with its gradient norm in the original model. Intuitively, samples with large gradient magnitudes during training or finetuning induce stronger parameter changes when removed, making them more detectable via MIA and more exploitable for reconstruction Ye et al. [2023].
Second, as shown in prior work Thudi et al. [2022], Kurmanji et al. [2023], most approximate unlearning methods make minor parameter updates, typically by maximizing the forgetset loss while keeping retain-set accuracy stable. This keeps the unlearned model close to the original, so the parameter difference encodes information about the forgotten data. In gradient-ascent-based methods Kurmanji et al. [2023], Chundawat et al. [2023a], this difference is essentially the forget-set gradient. Recent studies confirm that such updates expose information equivalent to a single gradient step on the forgotten sample Bertran et al. [2024], which attackers can invert to reconstruct it.
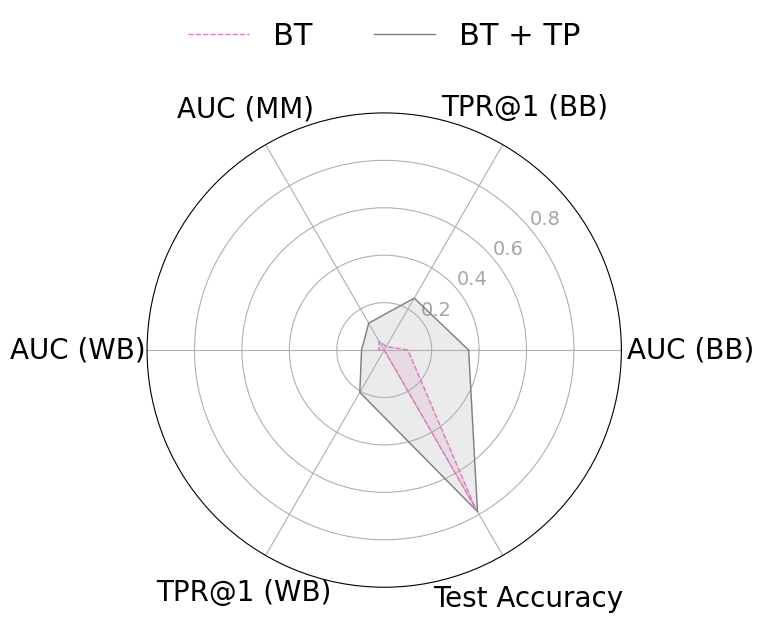
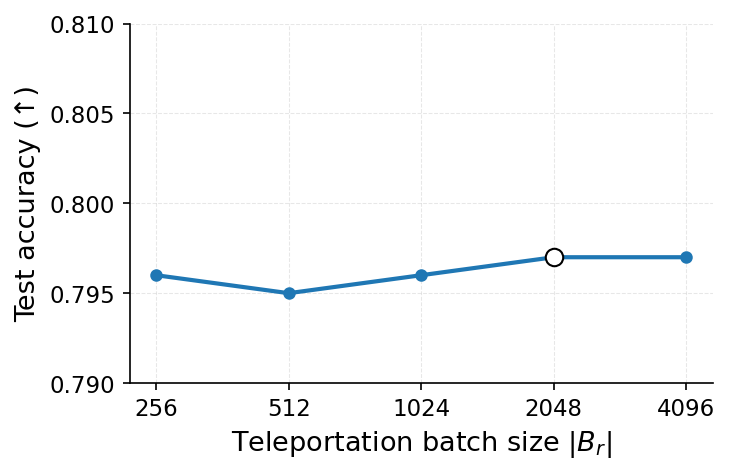
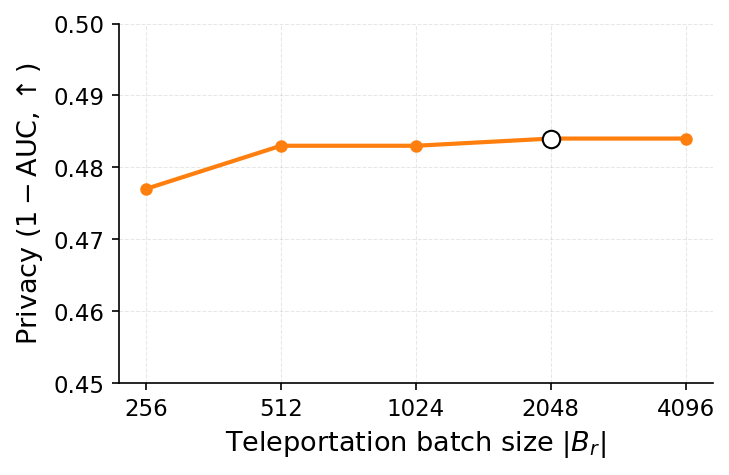
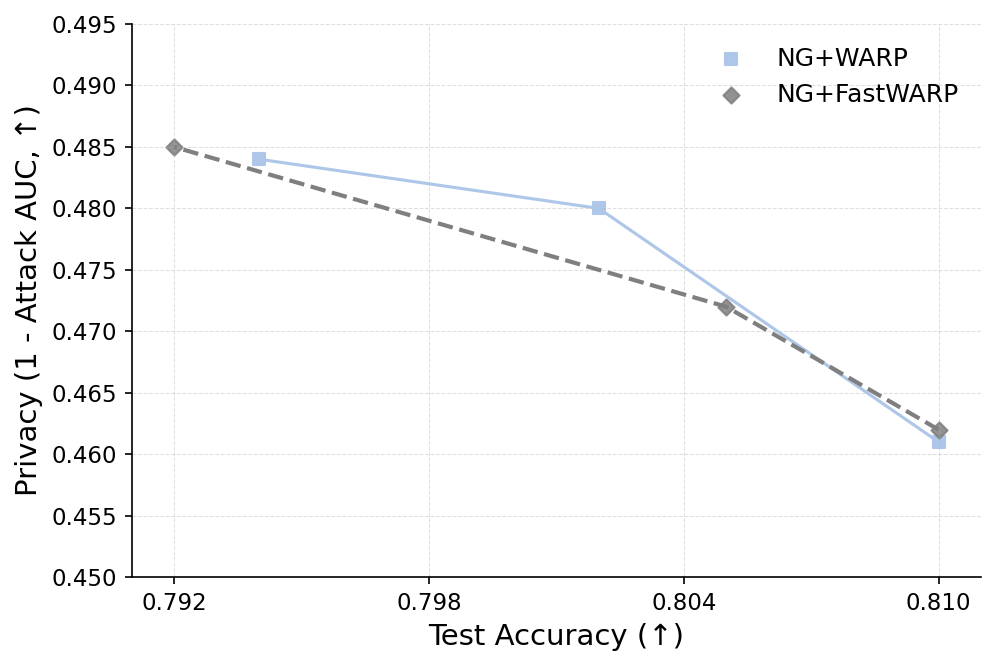
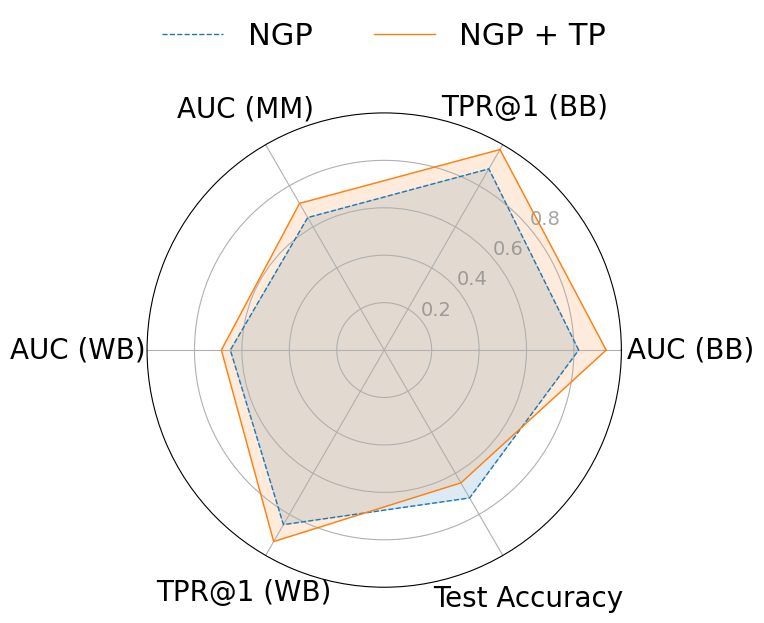
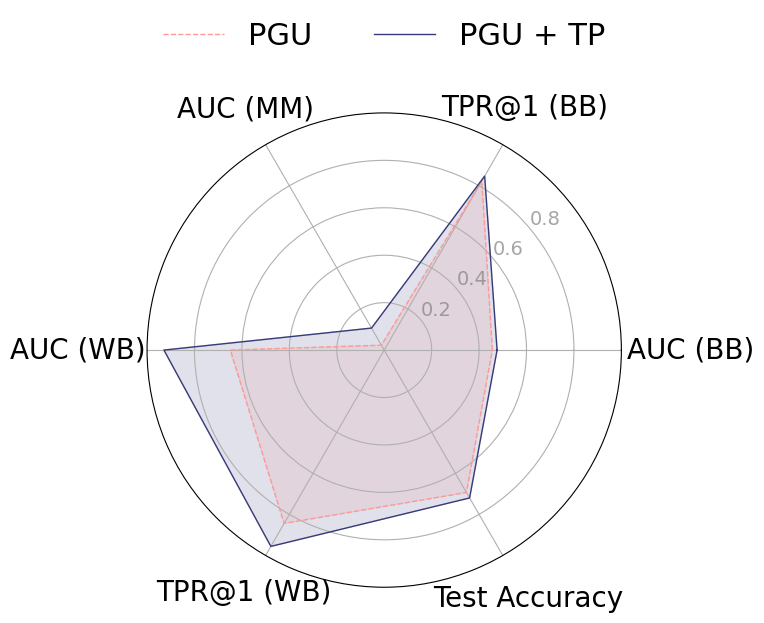
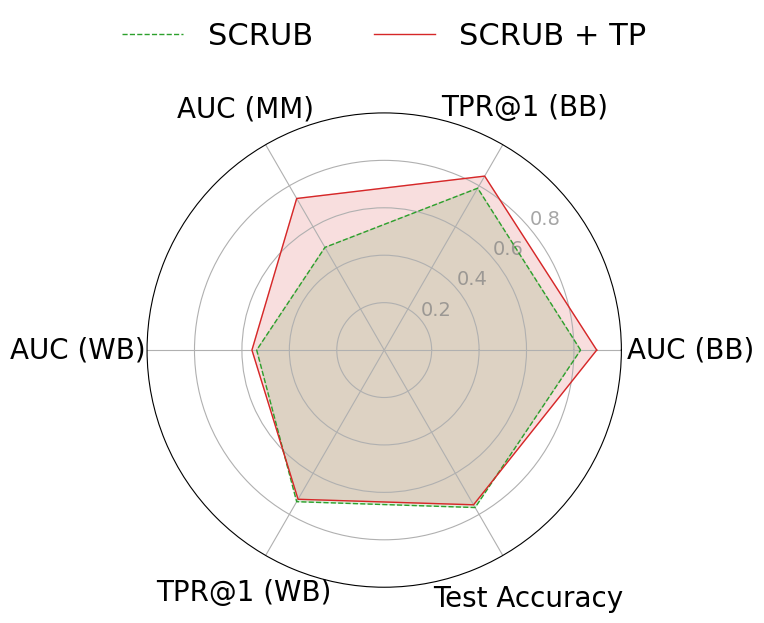
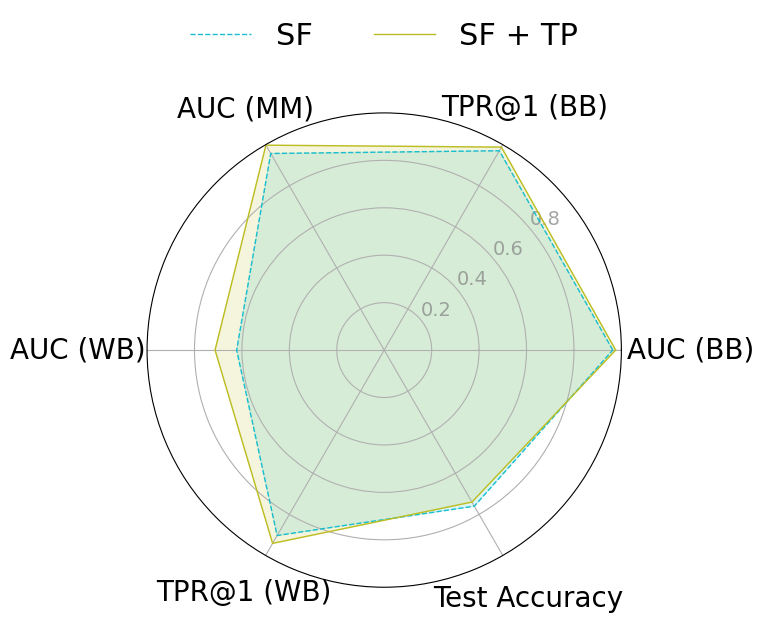
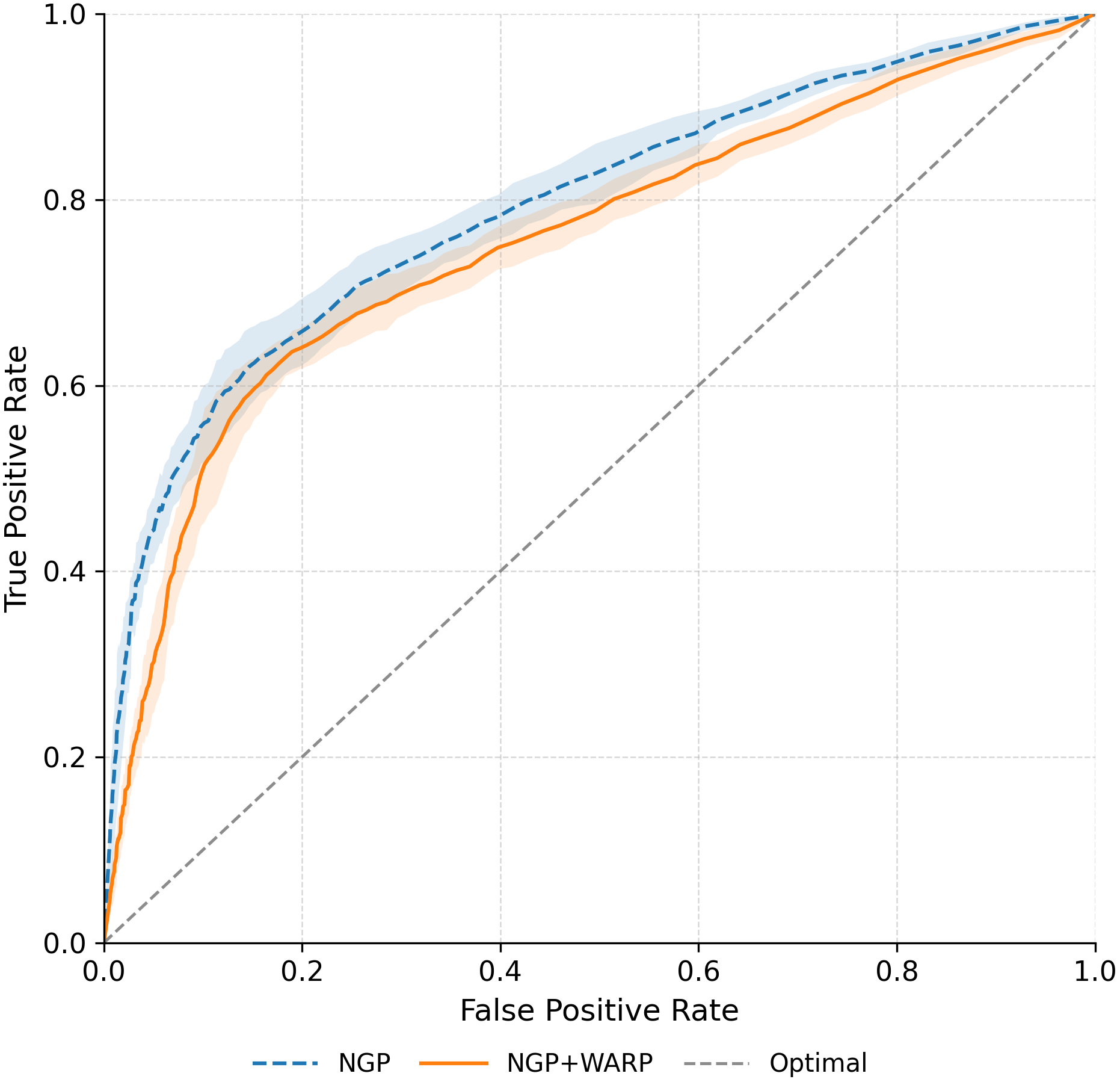
To mitigate these risks, we propose WARP, a plug-and-play defense that integrates into existing unlearning algorithms without training-time statistics. Our method leverages neural network teleportation Armenta et al. [2023], exploiting parameter-space symmetries (e.g., rescaling or permutation) that preserve predictions. By applying selective teleportation steps before or during unlearning, we reduce forget-set gradient norms while injecting symmetry-preserving randomness. This yields unlearned models that retain accuracy yet are displaced in parameter space, making it harder for an attacker to disentangle forgetting from teleportation. Consequently, membership inference and reconstruction attacks are significantly weakened, as shown in Sections 4.2, 4.3, and 4.4.
Our contributions are summarized as follows:
• Tailored privacy attacks. We design MIA and DRA for the unlearning setting, where the adversary compares preand post-unlearning models. These attacks show that leading methods remain vulnerable, as parameter updates still expose information about the forget-set.
•
This content is AI-processed based on open access ArXiv data.