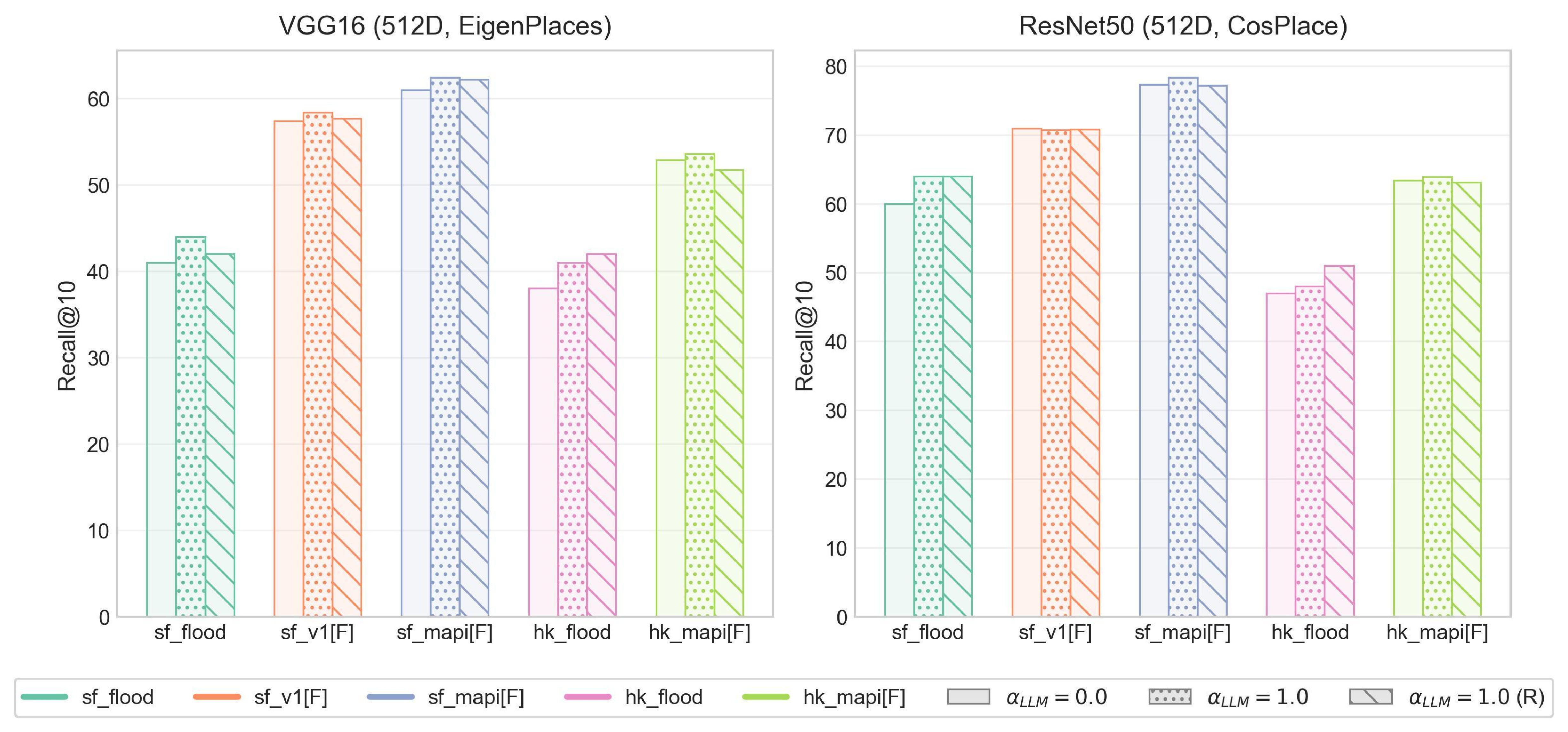
Crowdsourced street-view imagery from social media provides real-time visual evidence of urban flooding and other crisis events, yet it often lacks reliable geographic metadata for emergency response. Existing image geo-localization approaches, also known as Visual Place Recognition (VPR) models, exhibit substantial performance degradation when applied to such imagery due to visual distortions and domain shifts in cross-source scenarios. This paper presents VPR-AttLLM, a model-agnostic framework that integrates the semantic reasoning and geo-knowledge of Large Language Models (LLMs) into established VPR pipelines through attention-guided descriptor enhancement. By leveraging LLMs to identify location-informative regions within the city context and suppress visual noise, VPR-AttLLM improves retrieval performance without requiring model retraining or additional data. Comprehensive evaluations are conducted on extended benchmarks including SF-XL enriched with real social-media flood images, synthetic flooding scenarios over established query sets and Mapillary photos, and a new HK-URBAN dataset capturing morphologically distinct cityscapes. Integrating VPR-AttLLM with three state-of-the-art VPR models-CosPlace, EigenPlaces, and SALAD-consistently improves recall performance, yielding relative gains typically between 1-3% and reaching up to 8% on the most challenging real flood imagery. Beyond measurable gains in retrieval accuracy, this study establishes a generalizable paradigm for LLM-guided multimodal fusion in visual retrieval systems. By embedding principles from urban perception theory into attention mechanisms, VPR-AttLLM bridges human-like spatial reasoning with modern VPR architectures. Its plug-and-play design, strong cross-source robustness, and interpretability highlight its potential for scalable urban monitoring and rapid geo-localization of crowdsourced crisis imagery.
Street View Imagery (SVI) has become an essential source for urban observation and analysis because it enables detailed, ground-level perspectives on built environments (Gebru et al., 2017;Naik et al., 2017). While platforms such as Google Street View (GSV) provide standardized and extensive spatial coverage, they lack high-frequency temporal updates and cannot capture ephemeral or crisis-related changes in urban scenes-such as flash floods and hurricanes.
Consequently, crowdsourced street-view imagery (SVI) collected through social media and citizen-reporting platforms has emerged as a valuable complement for timely urban sensing and monitoring (Goodchild, 2007;Biljecki and Ito, 2021), enhancing cities’ capacity to assess and respond to rapidly evolving situations, particularly during emergencies (Qin et al., 2025).
Accurately locating crowdsourced street images is vital for integrating them into spatial decision systems for emergency response and urban resilience planning. This remains challenging because most contributors omit precise geotags for privacy or lack of geospatial literacy for precise locations (Croitoru et al., 2013;Tavra et al., 2021).
Although many cities have deployed official reporting platforms such as New York’s 311 system, persistent reporting friction and limited public awareness constrain participation, leading to biased and incomplete representations of urban issues (Kontokosta and Hong, 2021;Boxer et al., 2015). During disruptive events such as sudden flooding, citizens often share unstructured photos or videos on social media-data that lack geographic metadata yet offer rich, real-time visual evidence of urban disruptions (Figure 1). Such imagery complements formal reporting systems by capturing transient, on-the-ground scenes that enhance situation awareness. However, current municipal workflows still depend on manual verification, or cross-referencing by local agencies and journalists, which delays response and limits scalability. Furthermore, this lack of real-time ground verification disconnects dynamic Urban Digital Twins from the physical reality they aim to simulate, rendering them less effective during rapidly unfolding crises.
Geo-localization, also known as Visual Place Recognition (VPR), aims to infer the geographic location of an image by matching it to a geo-tagged reference database. VPR lies at the intersection of computer vision, urban morphology, and environmental perception. Foundational urban perception theories, such as the “Image of the City” (Lynch, 2008), “Scale and Psychologies of Space” (Montello, 1993), highlight the role of legibility and structural coherence in spatial recognition, while later computational works have quantified discriminative urban visual elements-demonstrating, for instance, “What makes Paris look like Paris?” (Doersch et al., 2012).
Modern VPR approaches fall broadly into two categories. Retrieval-based methods treat VPR as an image retrieval problem, building city-specific reference databases and retrieving the most similar reference image for a given query-exemplified by NetVLAD (Arandjelović et al., 2016), CosPlace (Berton et al., 2022), and more recent SALAD (Izquierdo and Civera, 2024). Classification-based VPR models instead predict a coarse geographic region or city category, allowing global coverage at lower spatial resolution, as demonstrated in PlaNet (Weyand et al., 2016), The emergence of multimodal Large Language Models (LLMs)-such as GPT-4o, Gemini 2.5, and Qwen-VL-creates new opportunities for resolving these limitations. Beyond text understanding, modern LLMs demonstrate sophisticated scene reasoning and spatial awareness derived from large-scale cross-modal training. They can identify and interpret urban components (e.g., building façades, vegetation, signage, or street furniture) and contextual cues that human observers use to infer place identity. Recent project like GeoIntel (Atiilla, 2024) show that LLMs can perform coarse geo-reasoning and recognize landmark-rich scenes; however, without integration into established retrieval-based pipelines, such models often lack street-level precision for city-scale VPR tasks.
To address this gap, this paper proposes a VPR enhancement framework with LLM-guided attention (VPR-AttLLM). By treating crowdsourced imagery as a sensor network, this framework serves as a robust data assimilation mechanism for Urban Digital Twins, leveraging LLMs’ semantic reasoning and general geo-knowledge to enhance retrieval-based VPR pipelines under challenging conditions. The central idea is to guide existing pre-trained VPR models with LLM-derived attention map extracted from query images, thereby emphasizing salient regions containing strong location cues (e.g., architectural structure, signage, or horizon geometry) and suppressing noisy regions like flooding street surface (Figure 1). This integration does not require additional training or supporting data, making it model-agnostic an
This content is AI-processed based on open access ArXiv data.