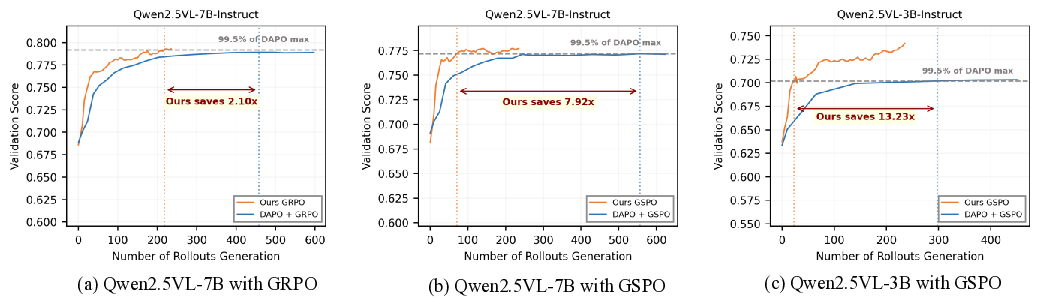
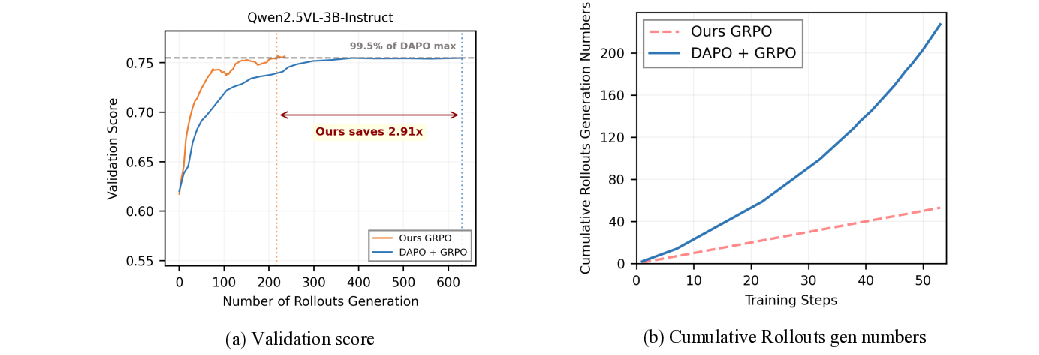
Group-based policy optimization methods like GRPO and GSPO have become standard for training multimodal models, leveraging group-wise rollouts and relative advantage estimation. However, they suffer from a critical \emph{gradient vanishing} problem when all responses within a group receive identical rewards, causing advantage estimates to collapse and training signals to diminish. Existing attempts to mitigate this issue fall into two paradigms: filtering-based and sampling-based methods. Filtering-based methods first generate rollouts broadly and then retroactively filter out uninformative groups, leading to substantial computational overhead. Sampling-based methods proactively select effective samples before rollout but rely on static criteria or prior dataset knowledge, lacking real-time adaptability. To address these issues, we propose \textbf{VADE}, a \textbf{V}ariance-\textbf{A}ware \textbf{D}ynamic sampling framework via online sample-level difficulty \textbf{E}stimation. Our framework integrates three key components: online sample-level difficulty estimation using Beta distributions, a Thompson sampler that maximizes information gain through the estimated correctness probability, and a two-scale prior decay mechanism that maintains robust estimation under policy evolution. This three components design enables VADE to dynamically select the most informative samples, thereby amplifying training signals while eliminating extra rollout costs. Extensive experiments on multimodal reasoning benchmarks show that VADE consistently outperforms strong baselines in both performance and sample efficiency, while achieving a dramatic reduction in computational overhead. More importantly, our framework can serves as a plug-and-play component to be seamlessly integrated into existing group-based RL algorithms. Code and models are available at https://VADE-RL.github.io.
Recent advancements in Reinforcement Learning (RL) have markedly improved the performance of large language models (LLMs) and multimodal large language models (MLLMs) on complex tasks involving mathematical reasoning, code generation, and scientific problem-solving [1,2,3,4] . Reinforcement Learning with Verifiable Rewards (RLVR) [5] plays a central role in these developments and group-based policy optimization algorithms (e.g. GRPO [6], GSPO [7]) have gained widespread adoption due to their efficiency and scalability. These methods generate multiple response rollouts for each training sample and compute relative advantages within the group for policy optimization, eliminating the need for additional value function approximation.
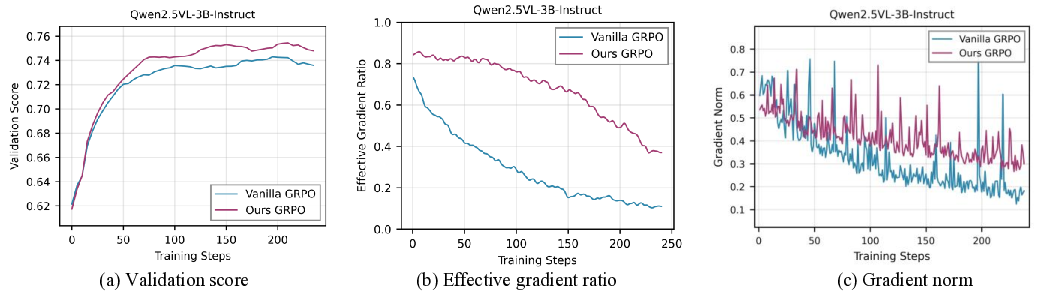
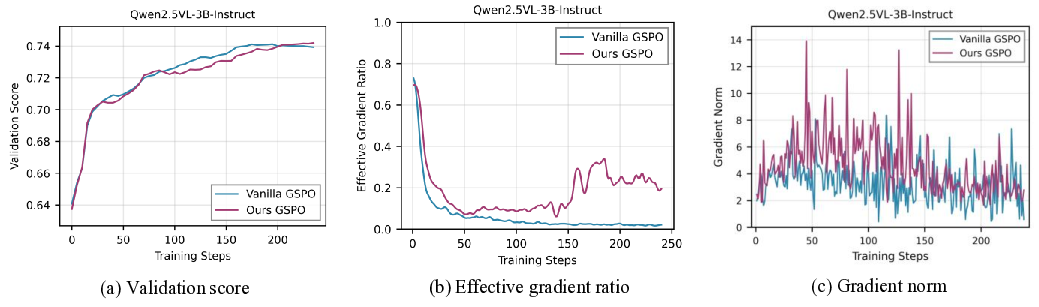
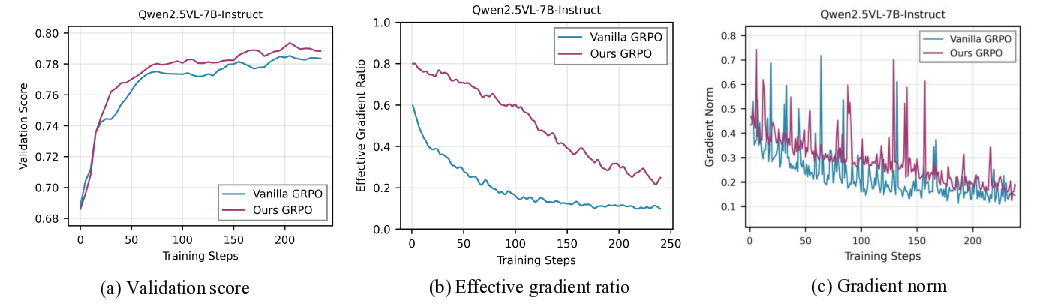
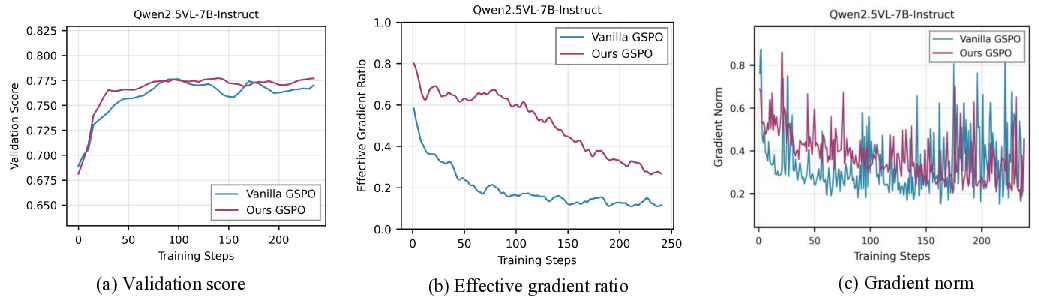
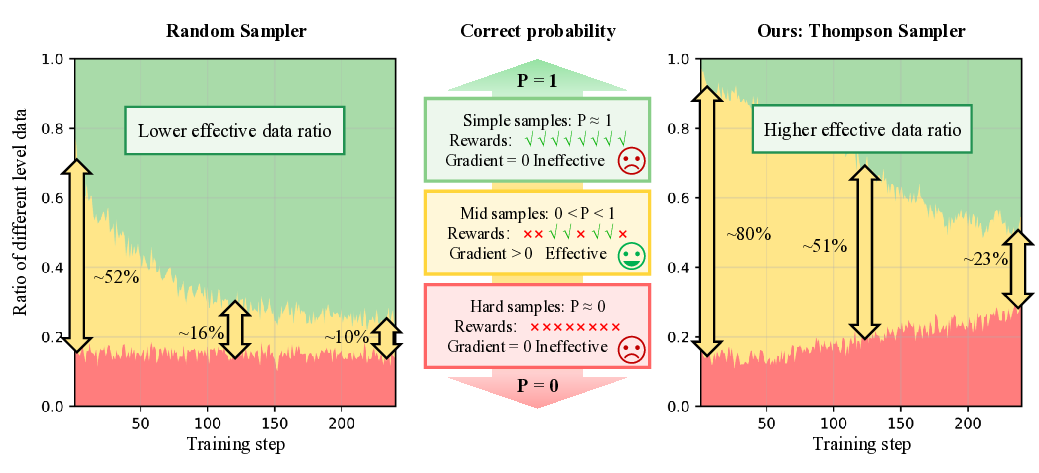
Despite their success, group-based RL methods suffer from a critical limitation known as the gradient vanishing problem [8]: when all responses within a group receive identical rewards-a common scenario when the model either solves all problems correctly or fails entirely-the relative advantages collapse to zero. This effectively eliminates the training signal for the entire group, severely degrading sample efficiency. As illustrated in the left half of Figure 1, during standard GRPO training with random sampling, the proportion of data yielding effective gradients progressively decreases, with zero-gradient groups dominating the training batches. In later stages, only around 10% of samples provide useful learning signals, creating a fundamental bottleneck for efficient training. Existing attempts to mitigate this issue can be categorized into two paradigms: filtering-based and samplingbased methods, both of which exhibit critical limitations. Filtering-based methods, such as DAPO [9] and VCRL [10], first generate rollouts for a broad set of samples and then retroactively filter out groups with uninformative reward signals. This “generate-then-filter” approach inevitably leads to substantial computational waste and requires costly mechanisms like repeated rollouts or replay buffers to assemble valid batches. In contrast, sampling-based methods, such as SEC [11] and MMR1 [12], aim to proactively select samples of appropriate difficulty before rollout generation. However, they rely on static criteria or prior dataset knowledge: SEC depends on pre-defined, coarse-grained difficulty categories, while MMR1 requires periodic and expensive re-rollouts to refresh its sample-level estimates. Consequently, both strategies lack the fine-grained, real-time adaptability necessary to keep pace with an evolving policy, leaving an open need for a dynamic and efficient sample selection mechanism.
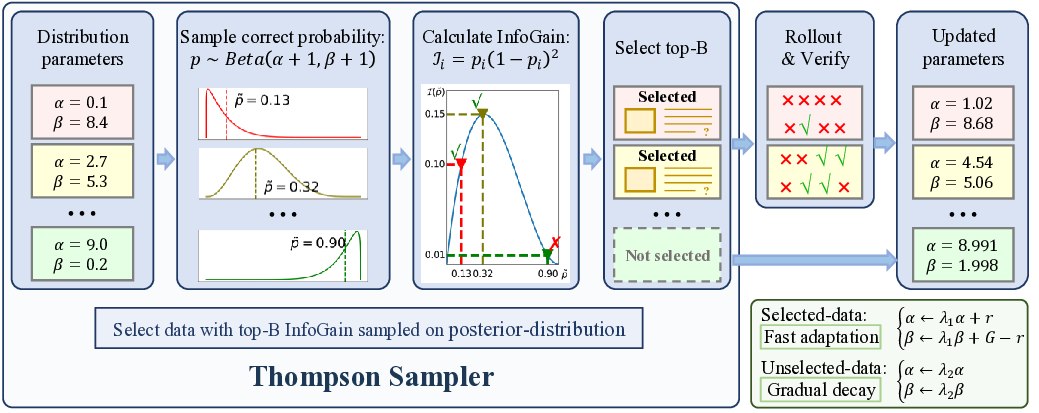
To address these limitations, we propose VADE, a Variance-Aware Dynamic sampling framework via online difficulty Estimation, designed to overcome the gradient vanishing problem in group-based RL. VADE introduces an efficient, sample-level data selection mechanism that operates without additional rollout inference overhead. We formulate data selection as a non-stationary Multi-Armed Bandit problem and solve it with a dynamic Thompson sampling strategy that continuously adapts to the policy’s evolution. Our framework integrates three key components: an online sample-level difficulty estimation module that employs a Beta distribution as the posterior estimate of each sample’s correctness probability; a Thompson sampler which leverages these estimates to maximize information gain and balance exploration with exploitation; and a two-scale prior decay mechanism that robustly maintains estimation accuracy under policy evolution. This integrated approach enables VADE to proactively identify the most informative samples, thereby maximizing the proportion of data yielding effective gradients, as visualized in the right half of Figure 1. Notably, VADE requires no prior difficulty annotations, incurs no extra rollout cost, and serves as a plug-and-play component that can be seamlessly integrated into existing group-based RL algorithms such as GRPO and GSPO. Comprehensive experiments on multimodal reasoning benchmarks across various model scales and policy optimization algorithms show that VADE consistently achieves higher sample efficiency and better evaluation performance compared to strong baselines, demonstrating its robustness and generalization. Furthermore, ablation studies validate the effectiveness of each component in our framework.
Our main contributions are summarized as follows:
• We propose VADE, a novel and efficient framework designed to tackle the gradient vanishing problem in group-based RL. It enables dynamic selection of highly informative samples during training without introducing extra rollouts, thereby achieving higher performance and training efficiency.
• We establish a theoretical formulation by modeling data selection as a non-stationary Multi-Armed Bandit problem and then solve it using a dynamic Thompson Sampling strategy. This formulation requires no prior difficulty knowledge or an
This content is AI-processed based on open access ArXiv data.