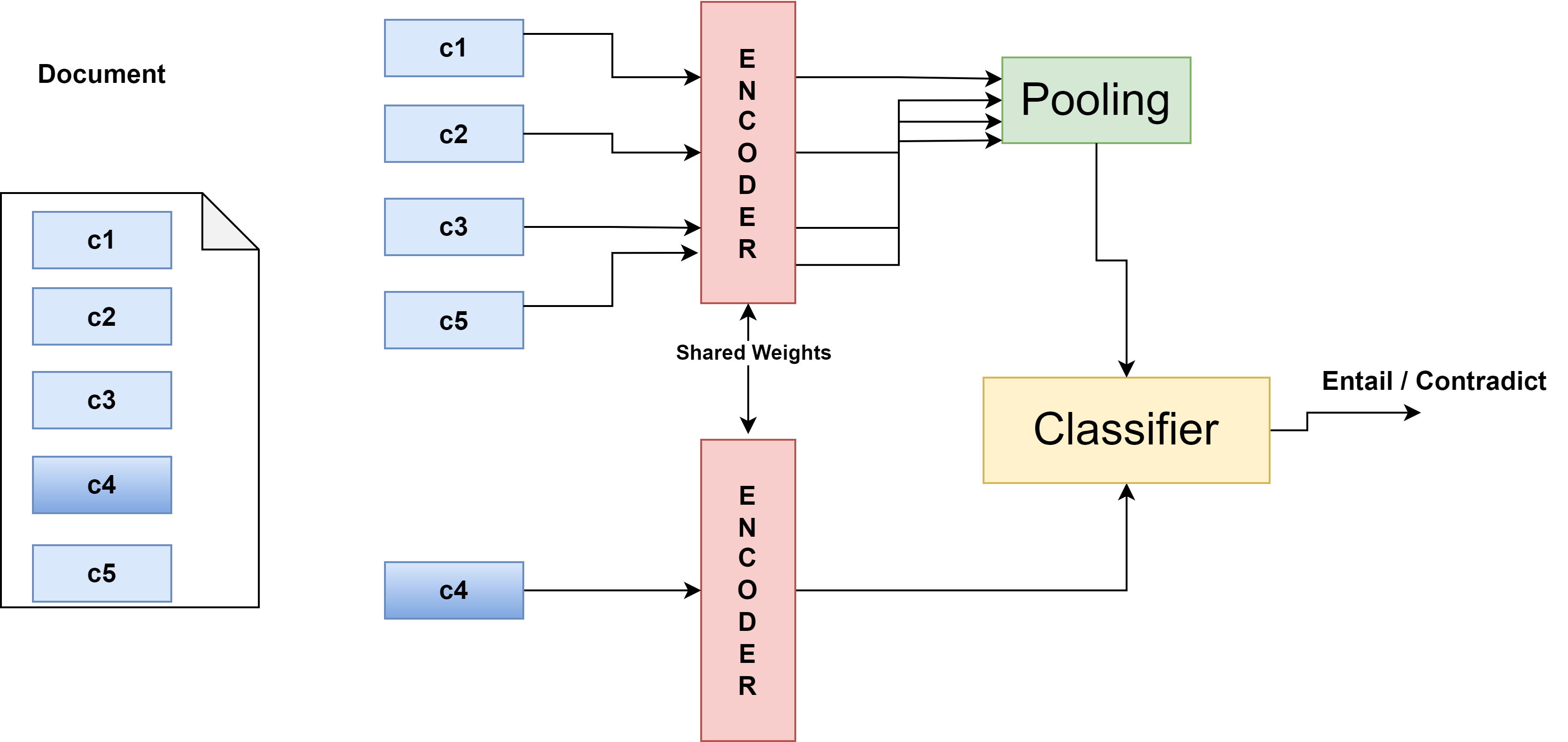
무작위 짧은 청크로 긴 법률 문서 분류
이 논문은 법률 문서와 같이 텍스트 길이가 수천 토큰에 달하는 도메인에서 Transformer 모델의 입력 제한을 우회하기 위한 실용적인 접근법을 제시한다. 기존 연구들은 보통 전체 문서를 슬라이딩 윈도우 방식으로 나누거나, 핵심 문장을 추출하는 전처리 단계에 의존한다. 그러나 슬라이딩 윈도우는 연산량이 급증하고, 핵심 문장 추출은 도메인 특화된 요약 모델이 필요해 추가 비용이 발생한다. 저자들은 이러한 문제를 “무작위 청크 샘플링”이라는 간단하지만 효과적인 전략으로 해결한다. 48개의 청크를 무작위로 선택함으로써 문서 전체의 다양
Computer Science
NLP