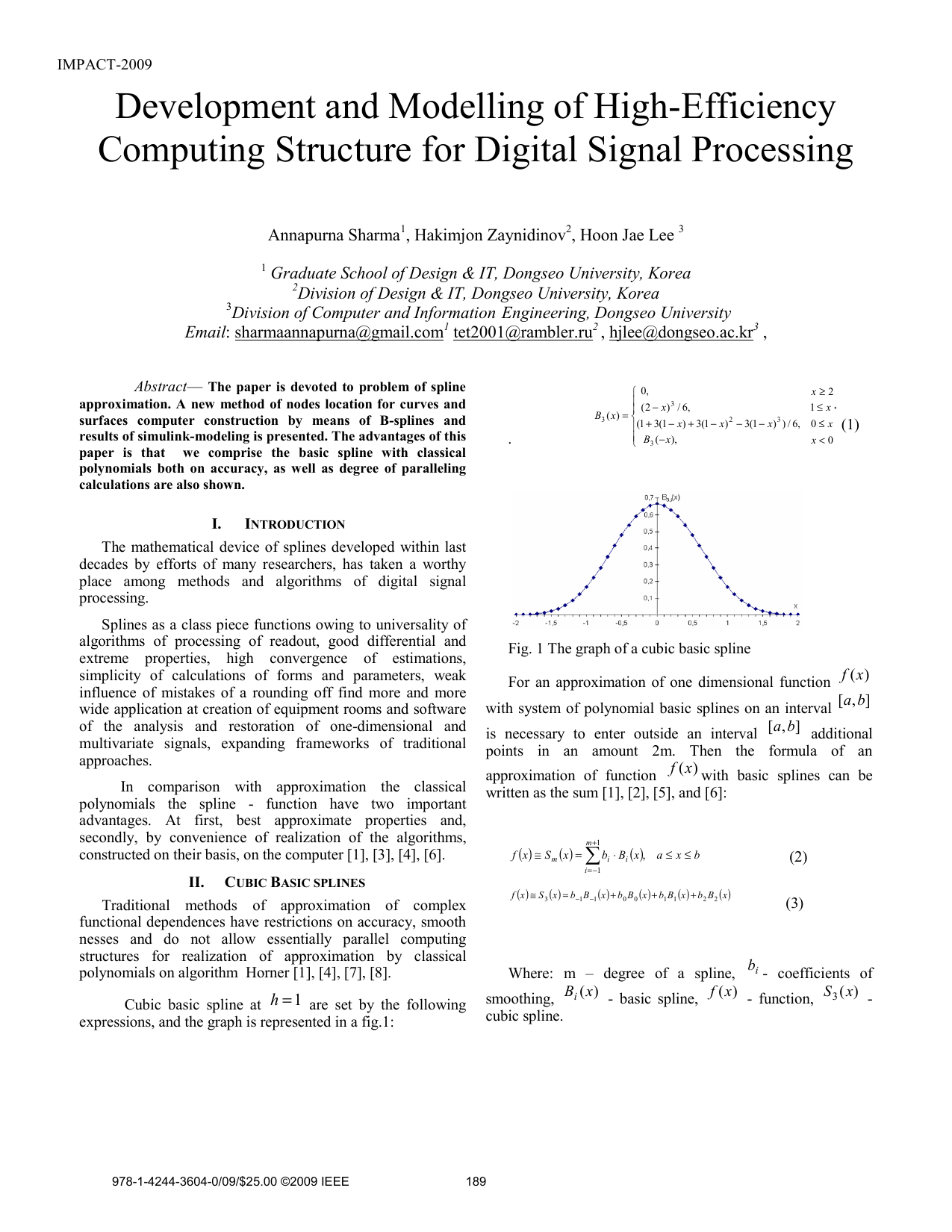
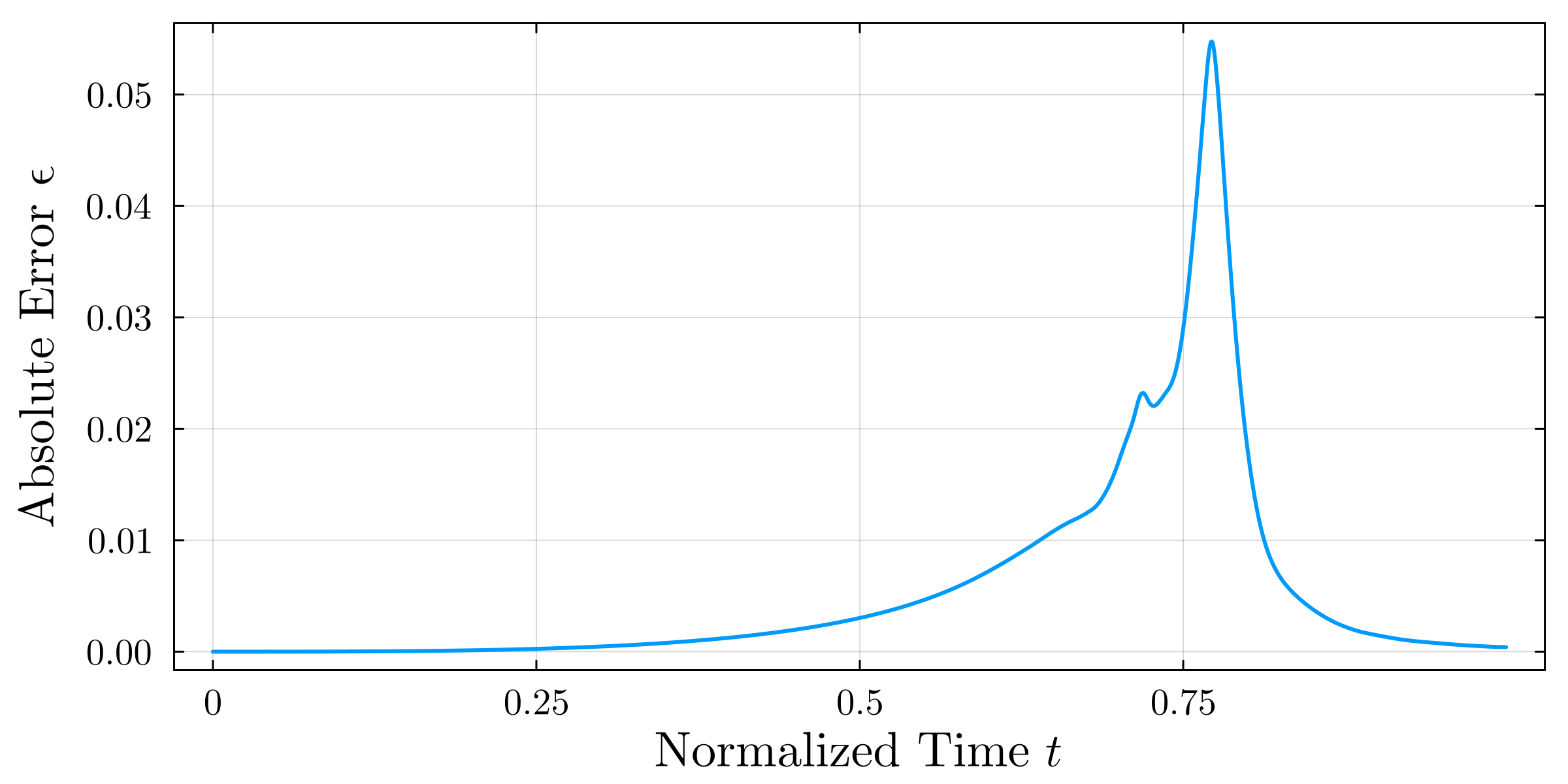
페트리넷과 생물학적 모델링: 상호작용으로부터 얻는 이점
: 본 논문은 페트리넷과 생물학적 시스템 간의 상호작용을 통해 얻을 수 있는 이점을 탐구합니다. 페트리넷은 동시성과 분산 계산을 위한 강력한 도구로, 행동 특성을 분석하고 검증하는 데 사용됩니다. 생물학적 과정을 이해하기 위해 제안된 막 시스템과 반응 시스템은 세포 내 화학 반응을 추상화한 모델입니다. 페트리넷의 원인과 동시성 의미론에 대한 이해는 페트리넷이 어떻게 생물학적 과정을 정확히 모델링할 수 있는지 설명하는 데 중요합니다. 막 시스템은 세포 내 화학 반응에서 영감을 받아 개발되었으며, 이는 페트리넷과 유사한 다중 집합 재구
Formal Languages
Distributed Computing
Model
Computer Science