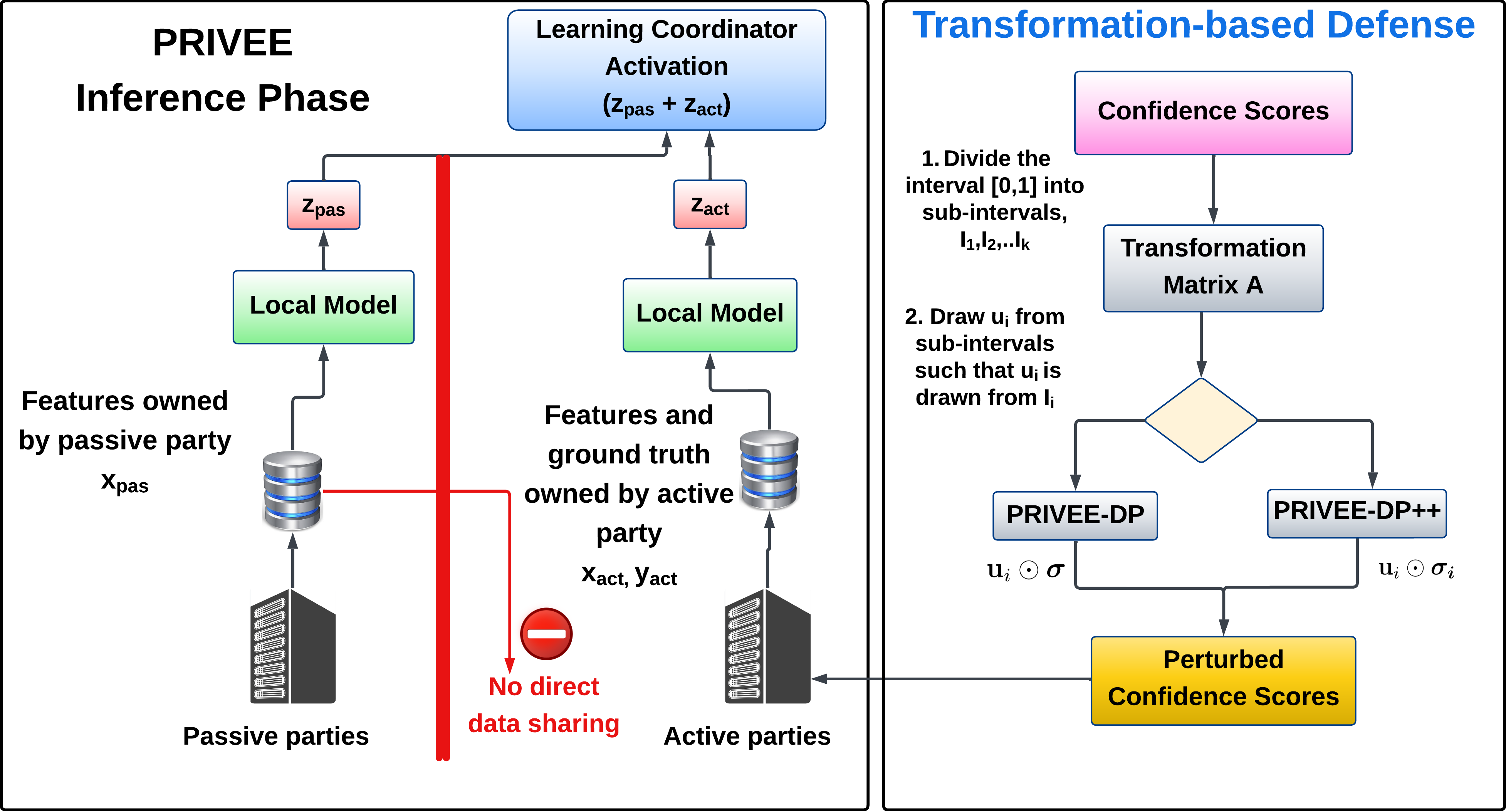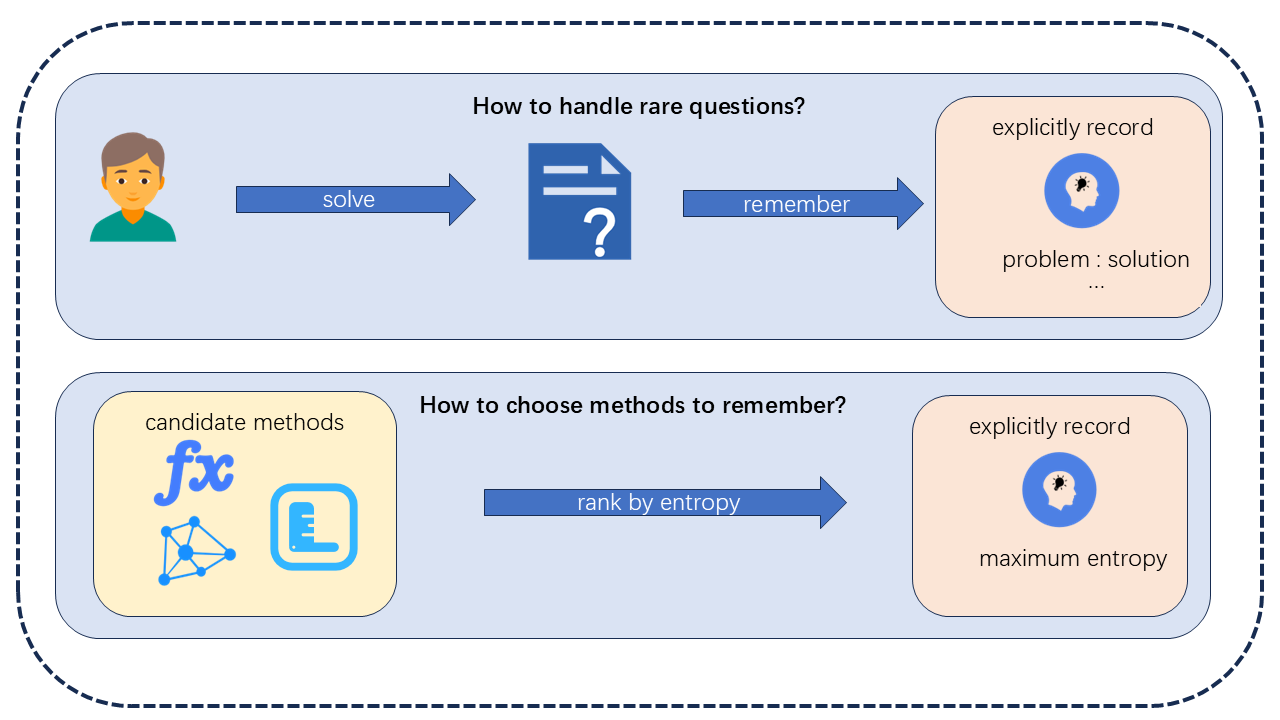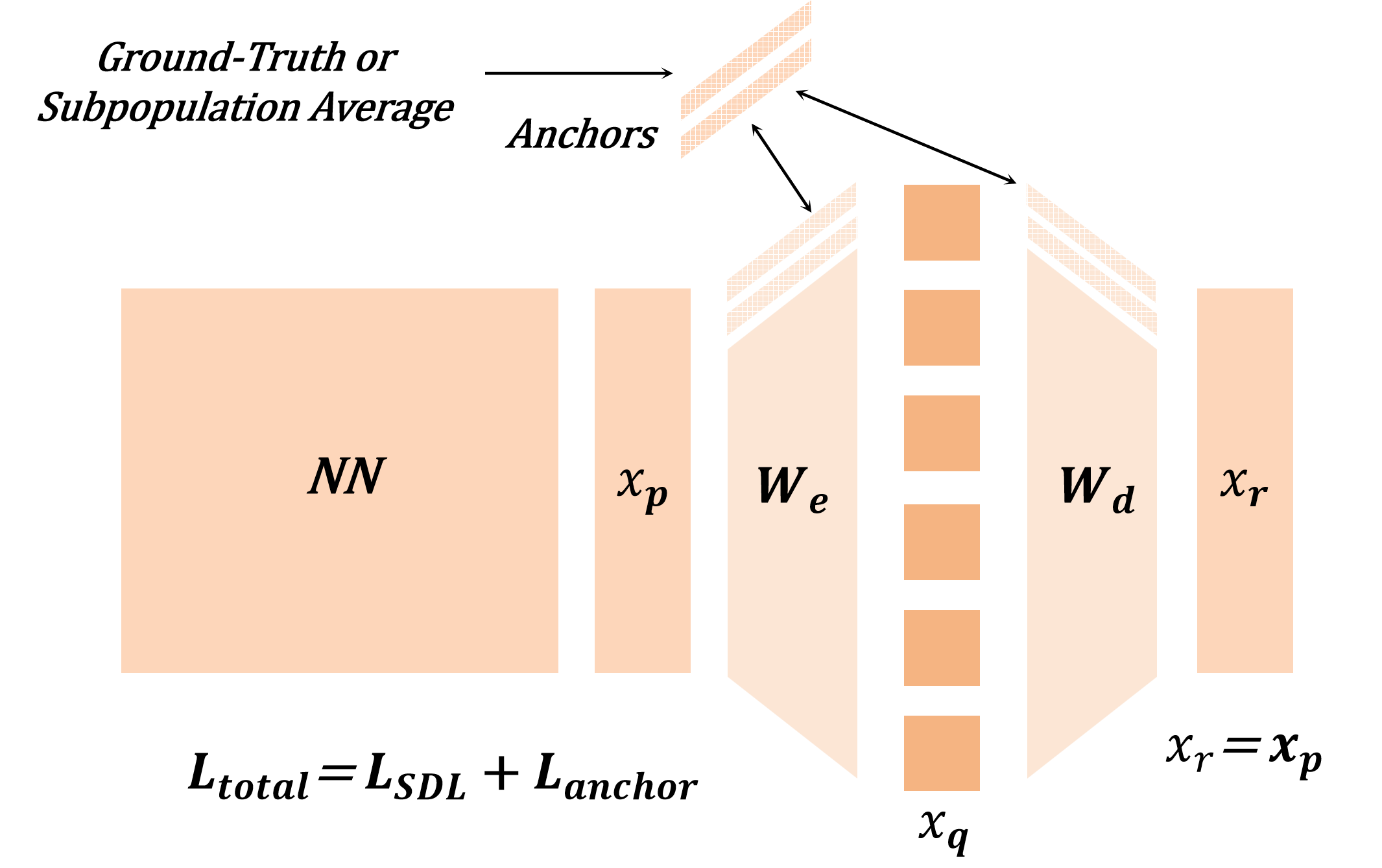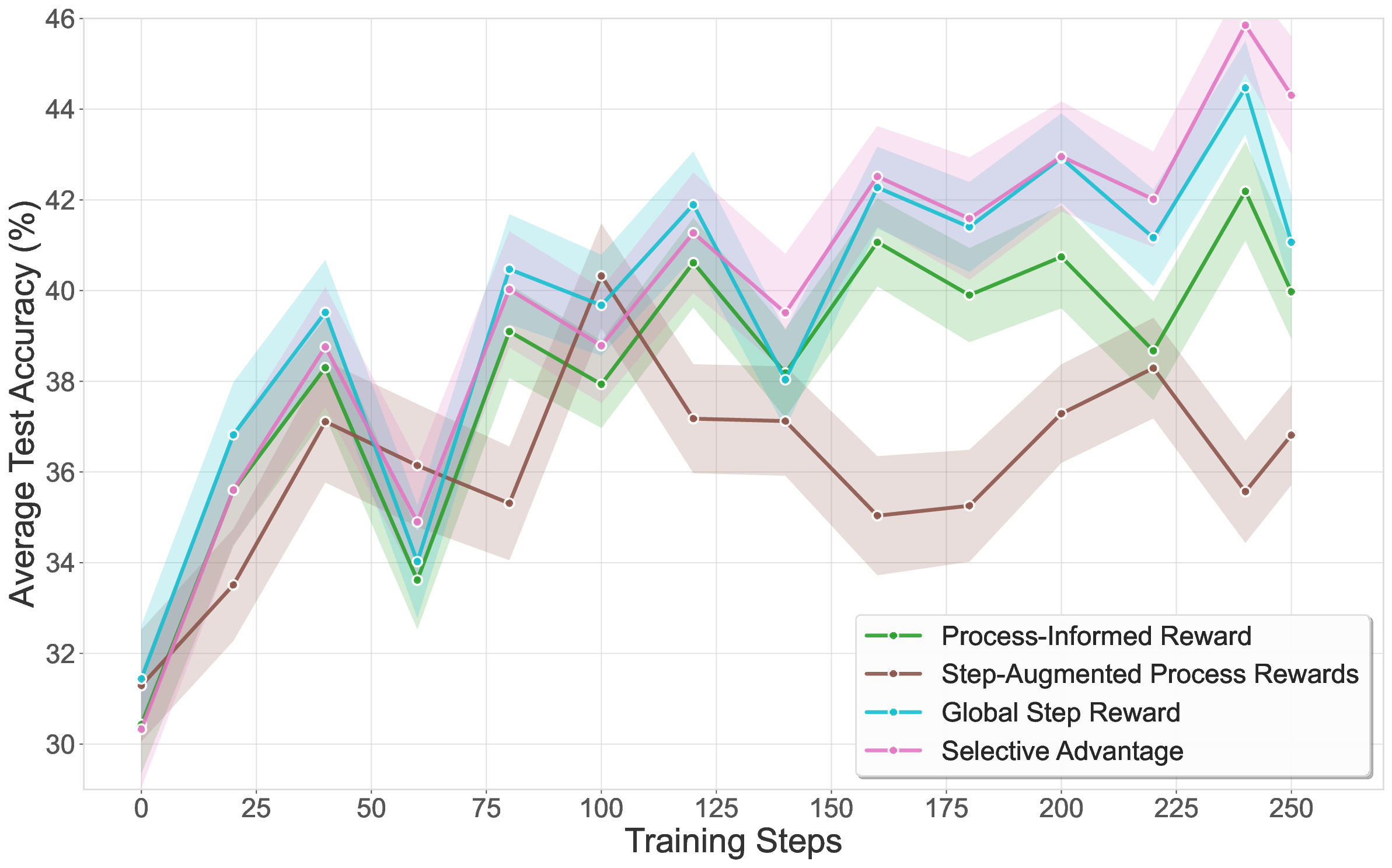
터널 결함 자동 검사 위한 새로운 데이터셋 소개
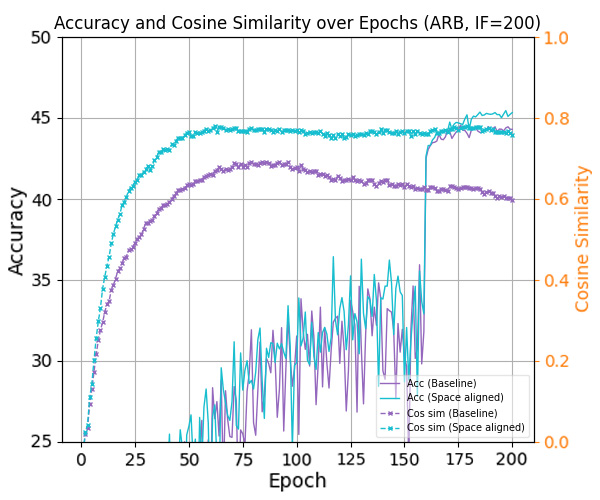
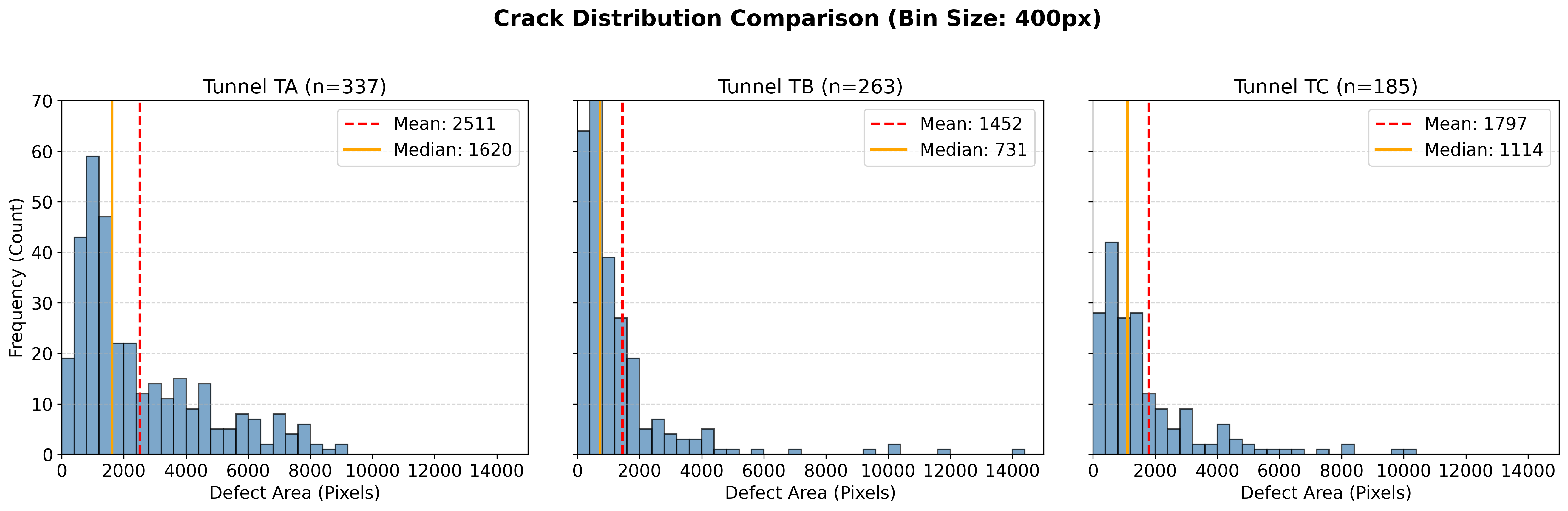
본 논문은 터널 결함 검사를 위한 새로운 데이터셋을 소개하며, 이는 딥러닝 모델의 학습과 성능 개선에 중요한 역할을 합니다. 터널은 교통 인프라의 주요 구성 요소로, 안전성을 유지하기 위해 정기적인 점검이 필수적입니다. 하지만 전통적인 수동 검사 방법은 시간 소모가 많고 비용이 높으며 주관적이어서 제한점이 있습니다. 모바일 매핑 시스템과 딥러닝의 발전으로 자동화된 시각 검사가 가능해졌지만, 이를 위한 충분한 데이터셋이 부족하여 그 효과가 제한되어 왔습니다. 본 논문에서 소개하는 새로운 데이터셋은 세 가지 다른 종류의 터널 라이닝에
Learning
Data
Detection