빅데이터 교육 실습 종합 보고서
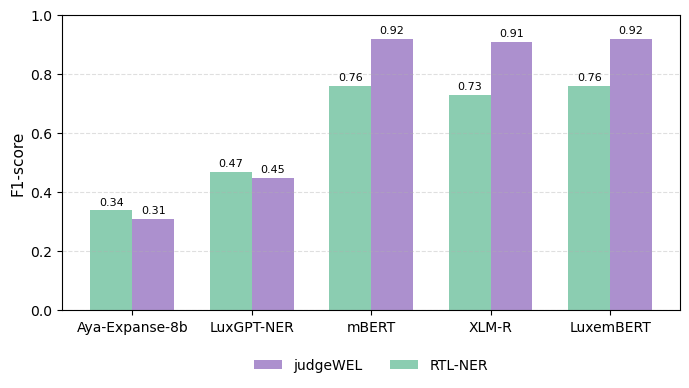
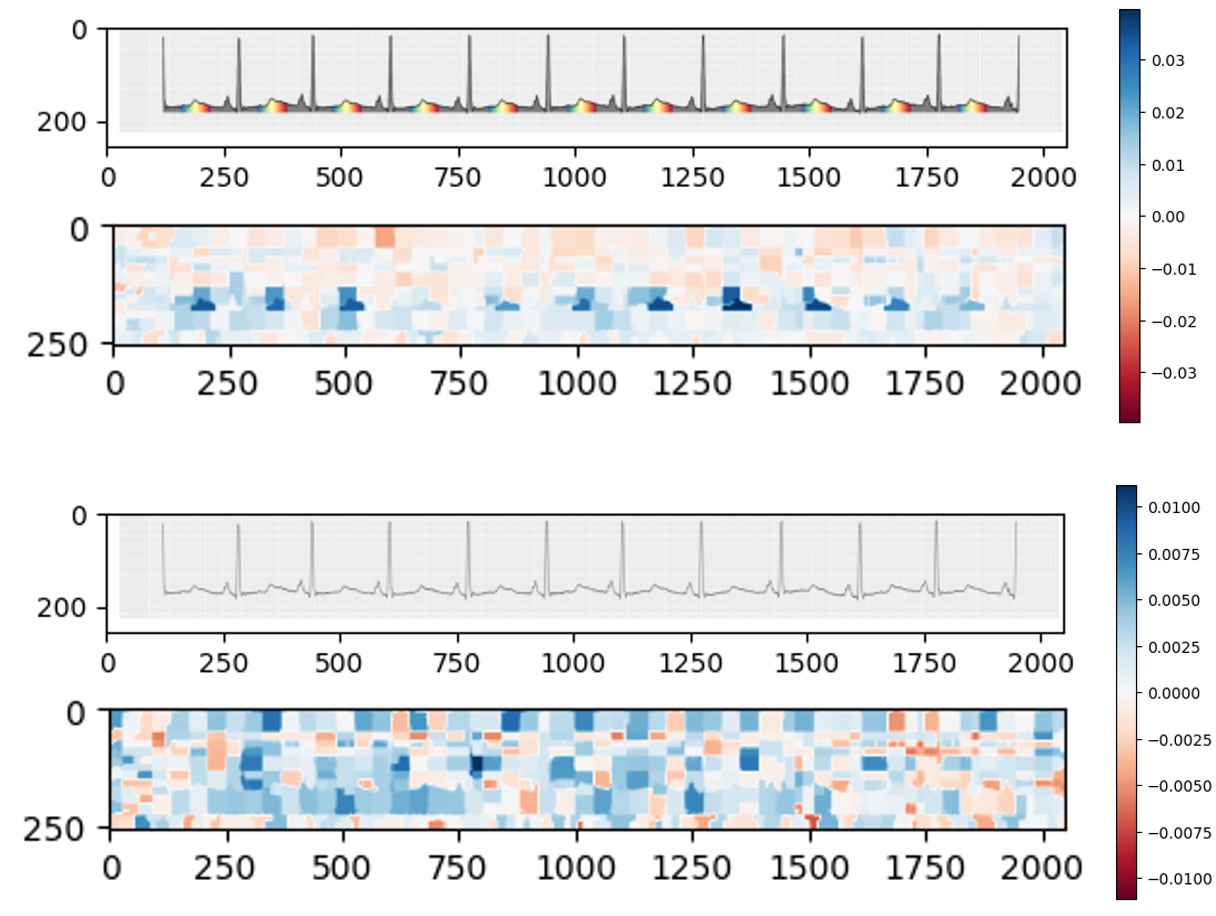
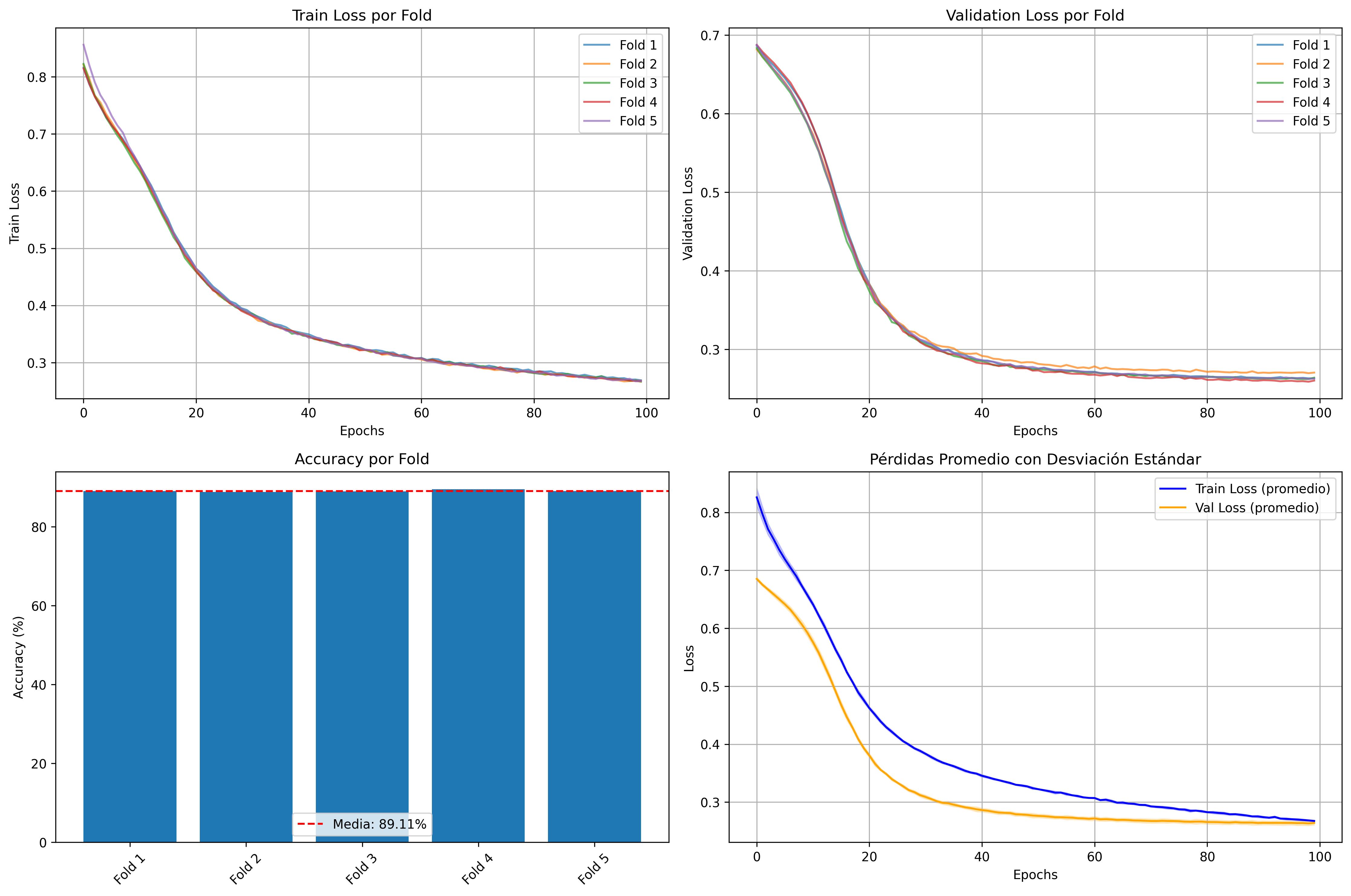
종합 분석: 빅데이터 교육 실습 보고서 1. 연구 개요와 방법론 본 연구는 빅데이터 프로젝트의 통합적 접근 방식을 취하며, 세 가지 사례를 통해 다양한 데이터 유형과 규모에 대한 분석 기법을 다룹니다. Epsilon 데이터셋 : 이진 분류 문제를 해결하기 위해 MLP 모델을 사용하여 2000개의 특징과 100,000개의 인스턴스로 훈련되었습니다. PyTorch와 GPU 가속(CUDA)을 활용해 88.98%의 정확도를 달성했습니다. Rest Mex 데이터셋 : 멕시코 관광 리뷰 데이터셋에 대해 감정 분석 파이프라인을 구현하였습니다.
Data
Learning