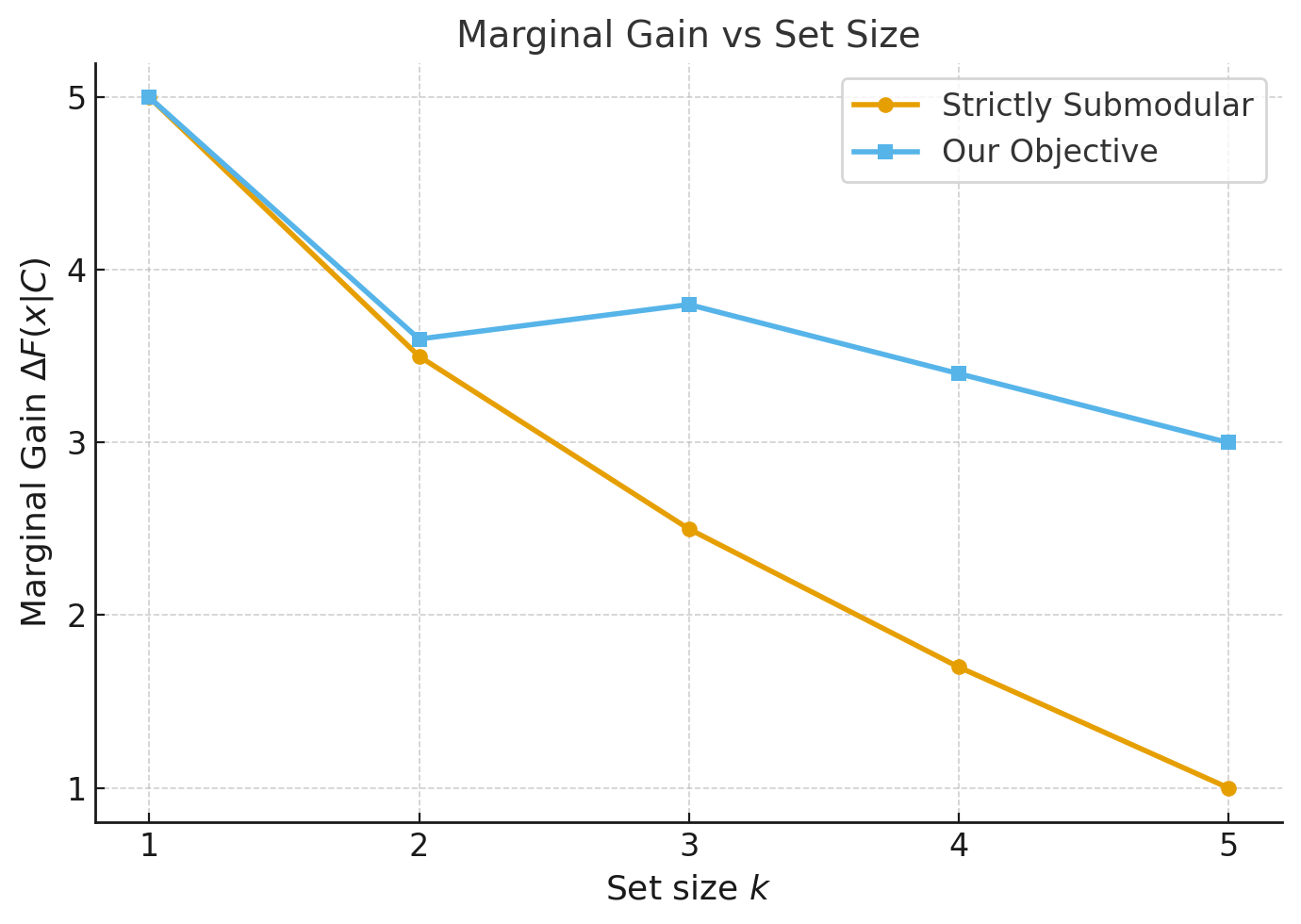
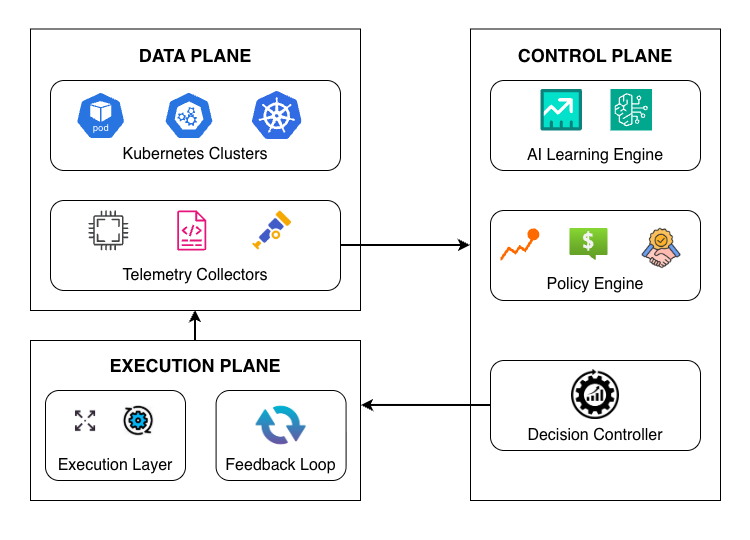
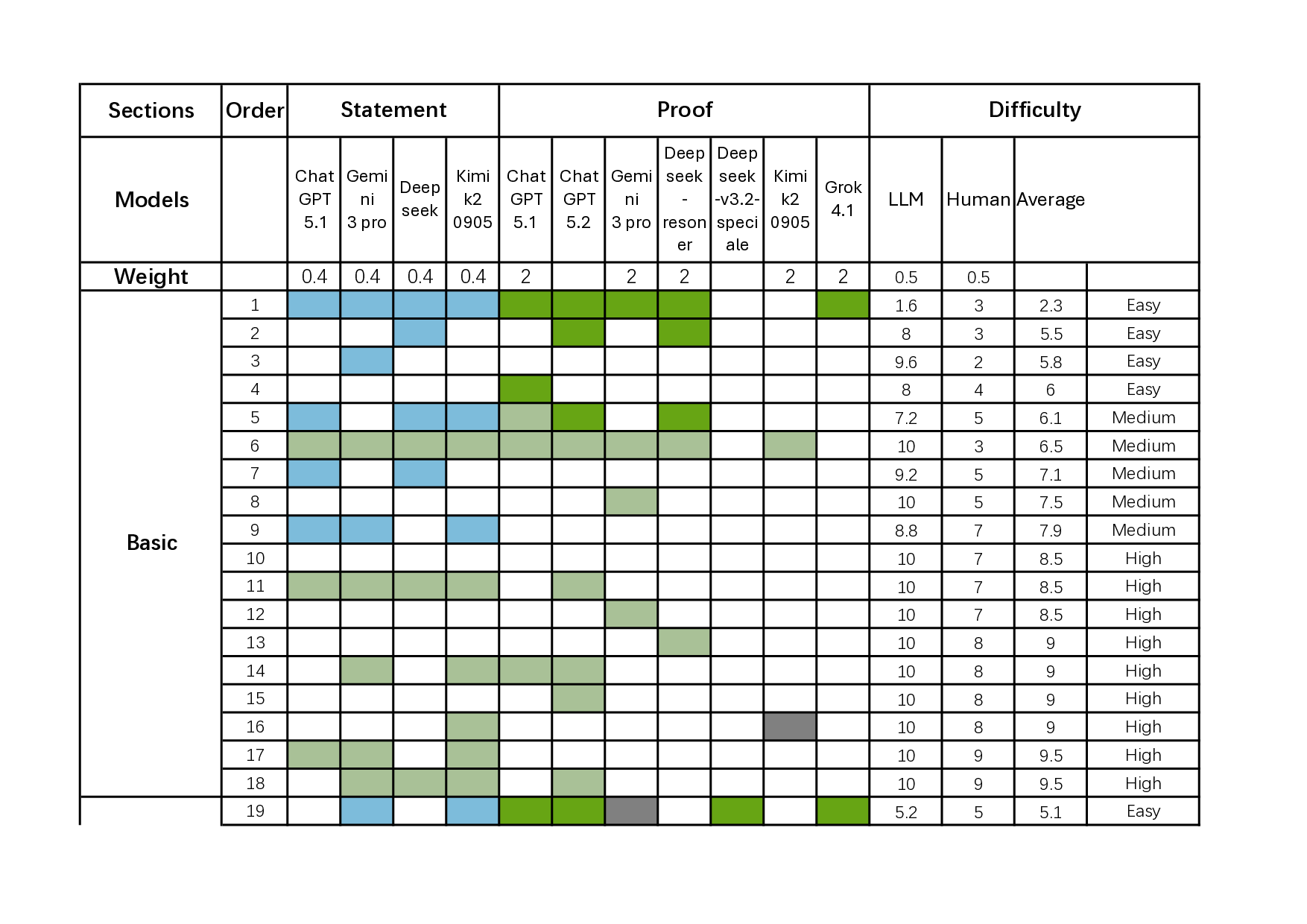
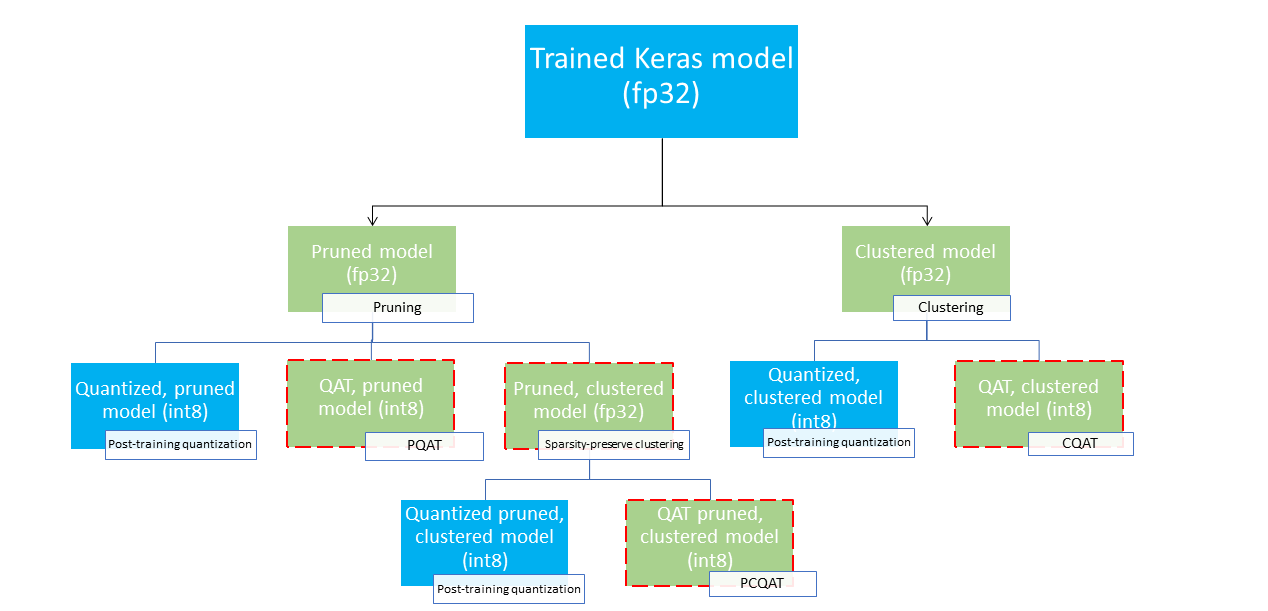
에셔버스 물리·동역학·의도 기반 텔레오스페이셜 인텔리전스 오픈월드 벤치마크
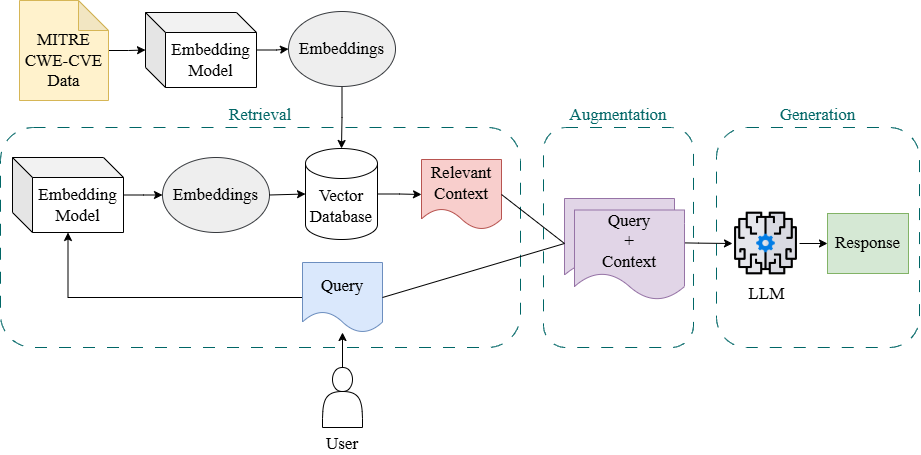
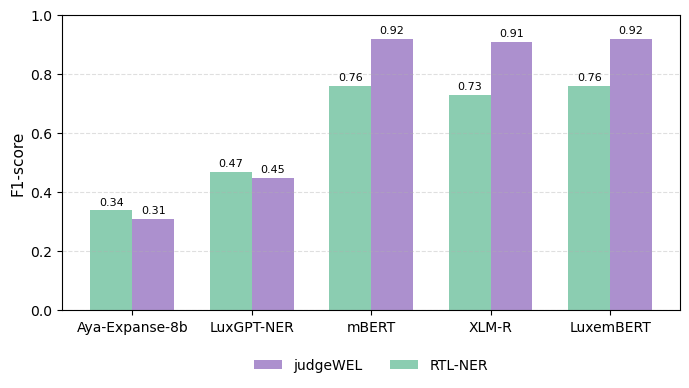
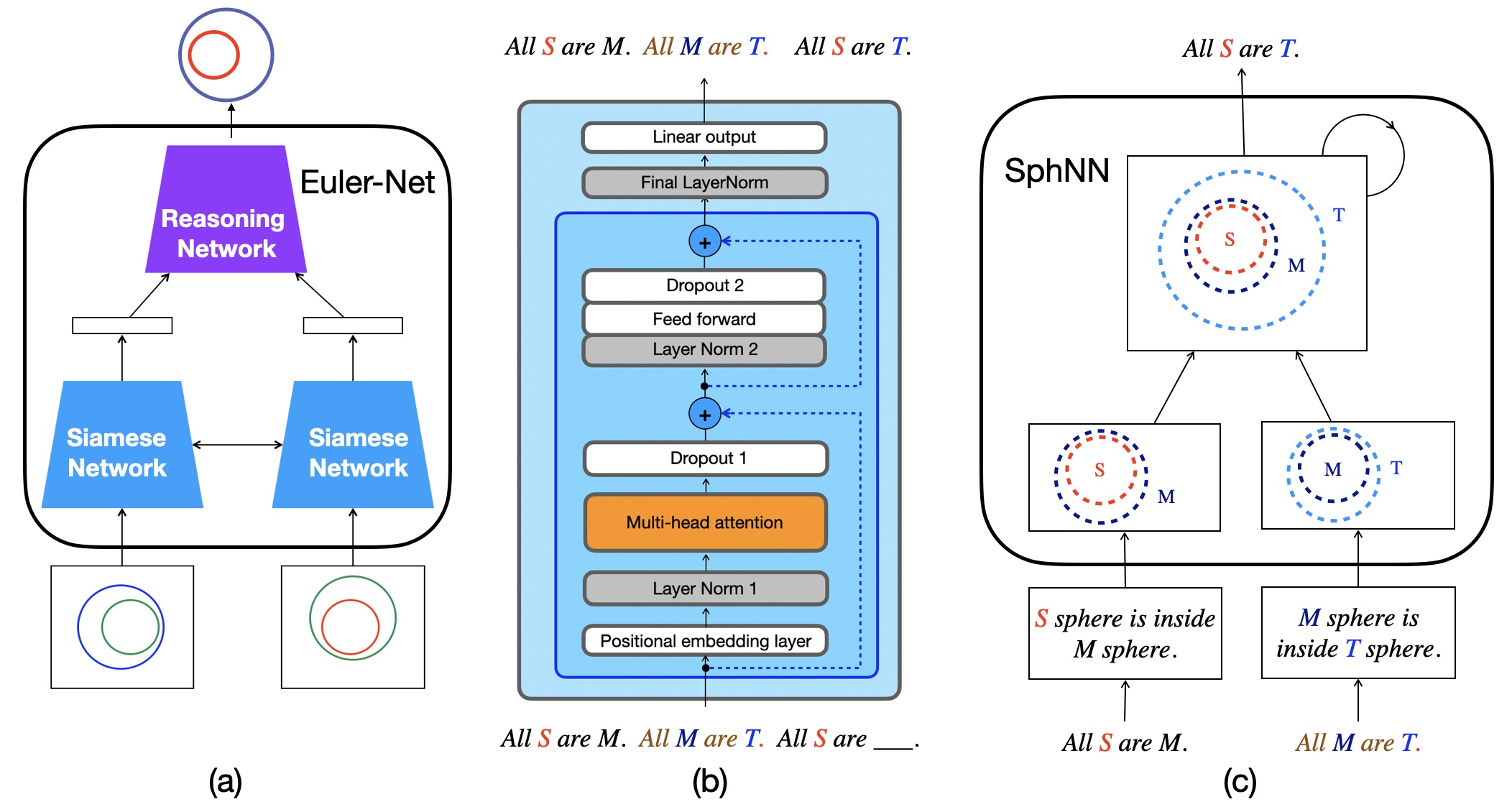
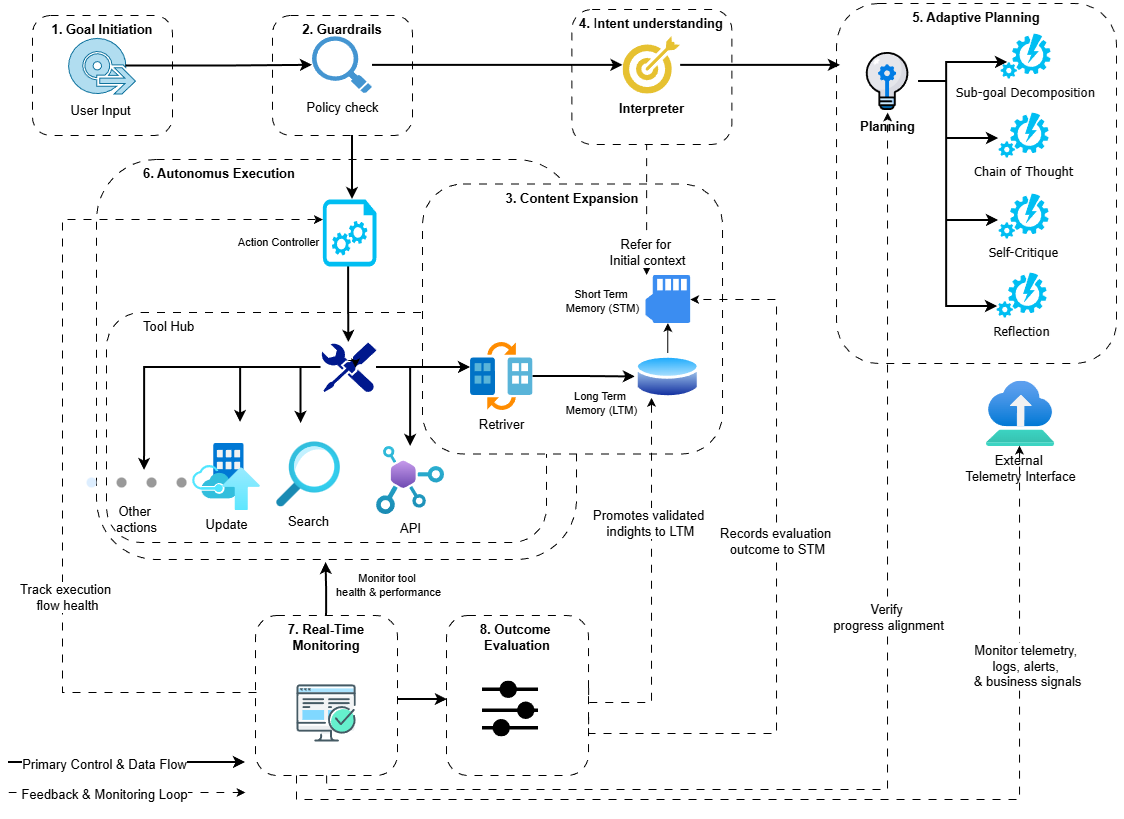
본 논문은 인공지능·로보틱스 분야에서 최근 주목받고 있는 “텔레오‑스페이셜 인텔리전스(TSI)”라는 새로운 개념을 제시한다. 기존의 대부분 연구는 물체‑중심(object‑centric) 접근을 취해, 물리‑동역학(Physical‑Dynamic) 모델링에 집중한다. 예컨대, 물체의 질량·마찰·충돌 법칙을 이용해 시뮬레이션하거나, 비전 기반 트래킹을 통해 움직임을 예측한다. 이러한 방법은 정량적 정확도에서는 뛰어나지만, 인간이 물체를 조작하거나 배치하는 근본적인 ‘의도’를 파악하지 못한다는 한계가 있다. TSI는 이러한 한계를 극복하기
Computer Vision
Computer Science
Data