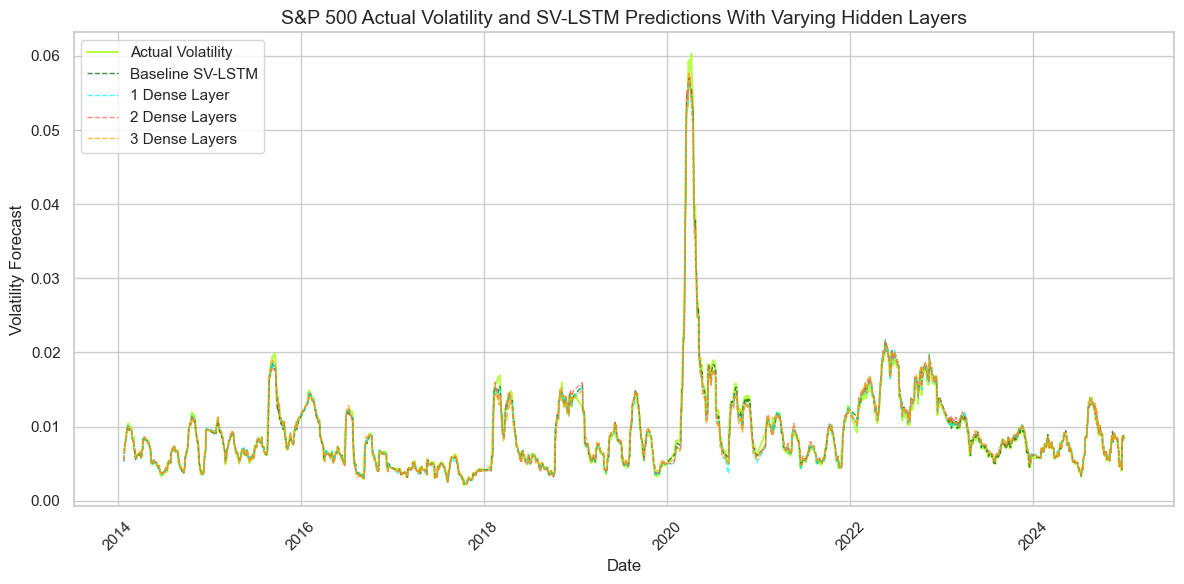
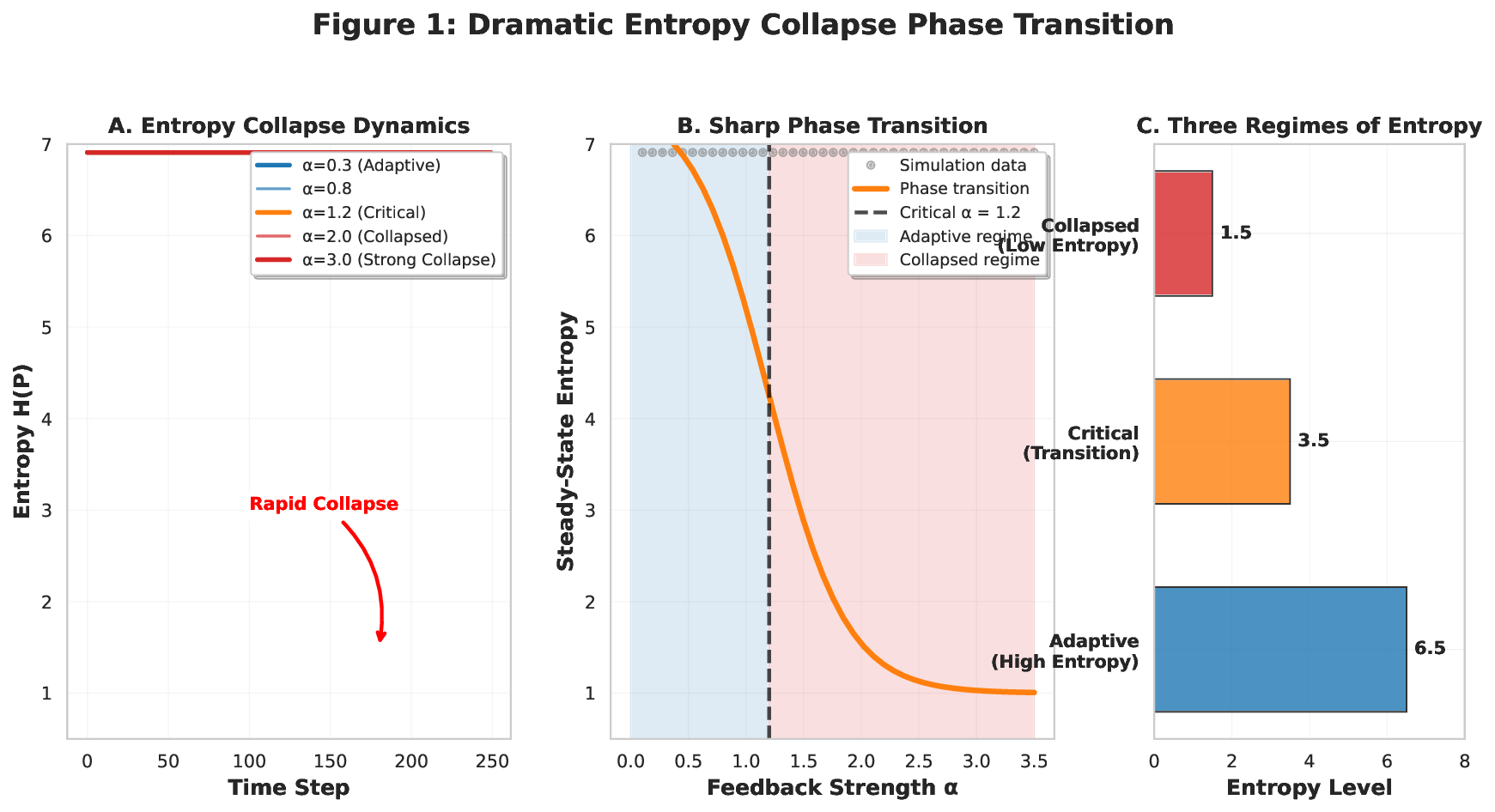
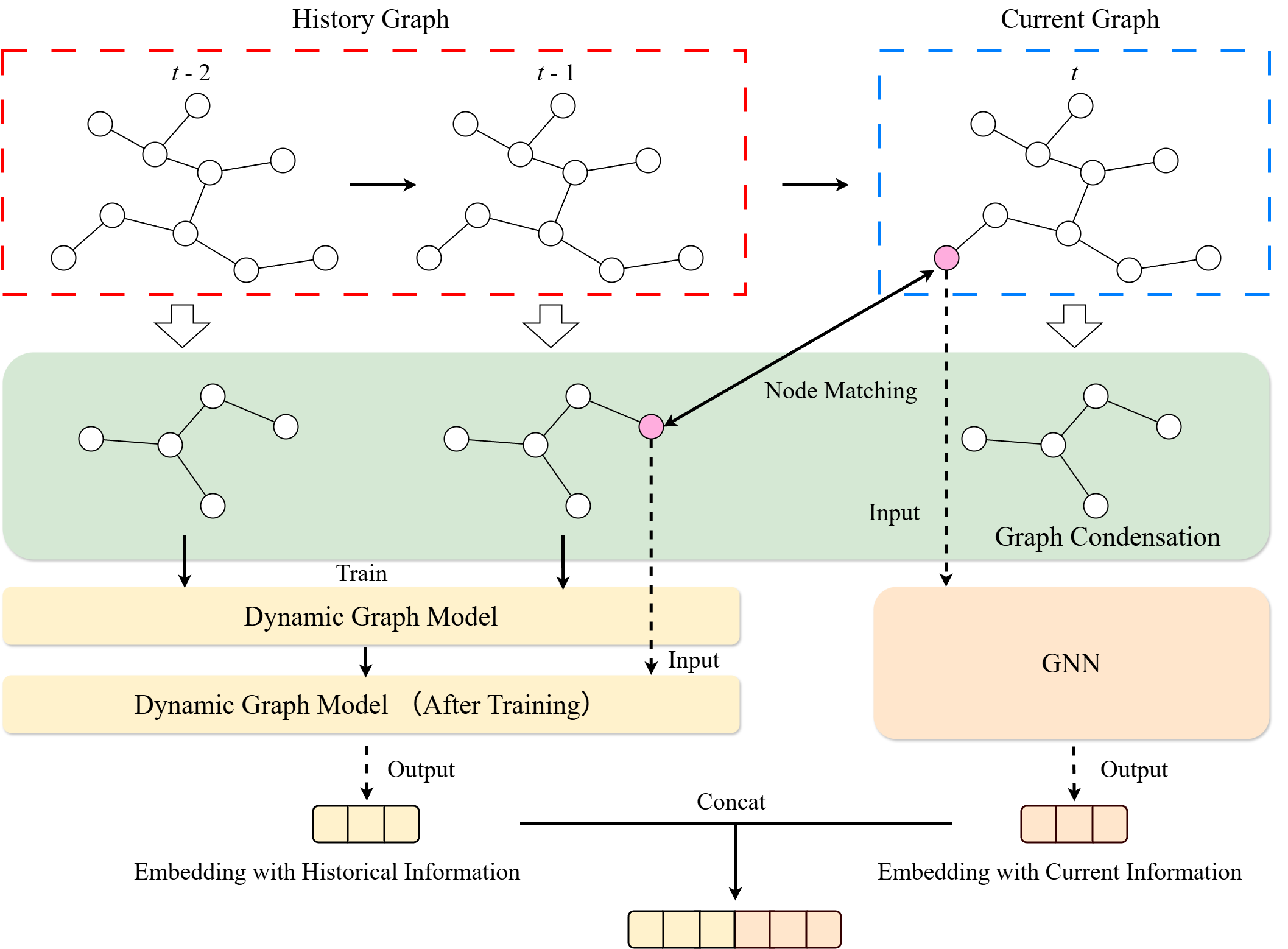
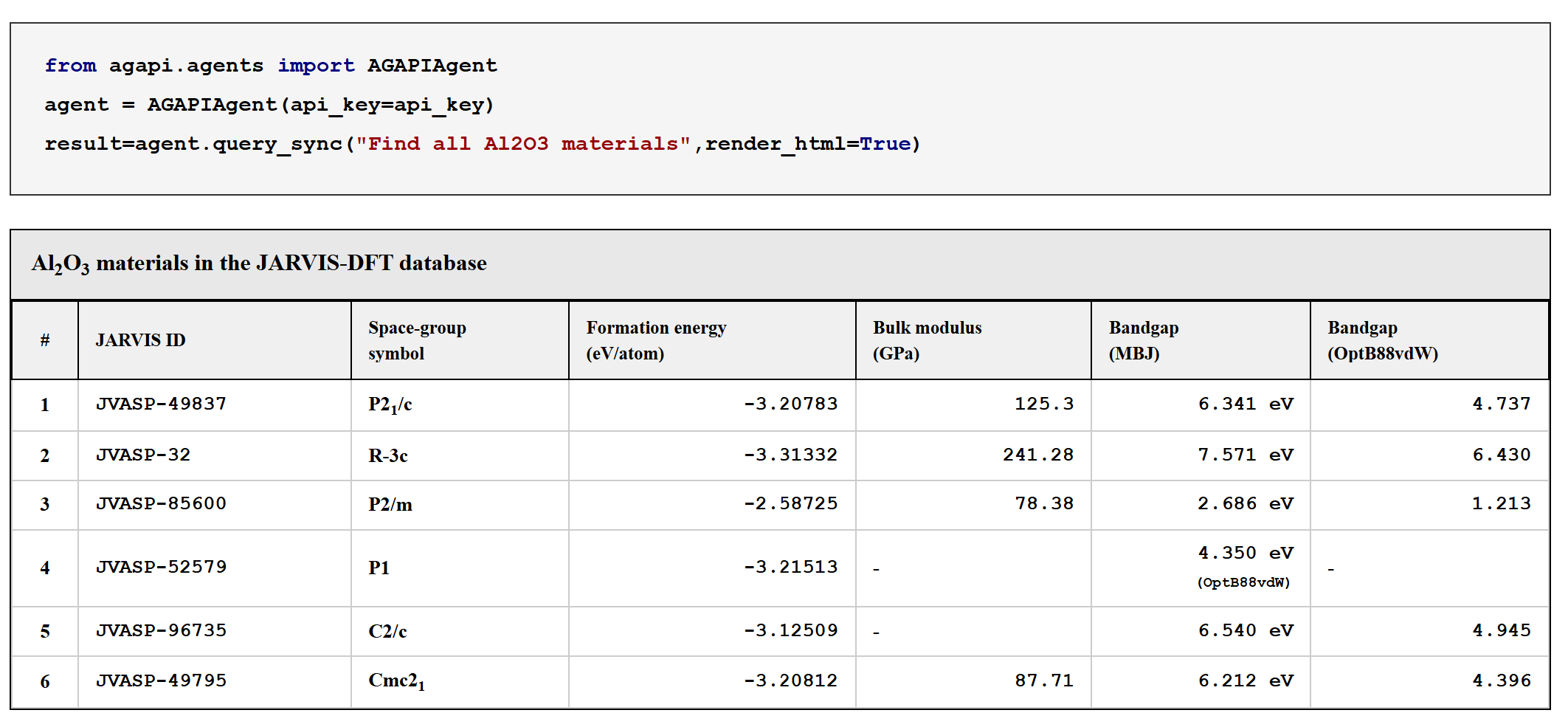
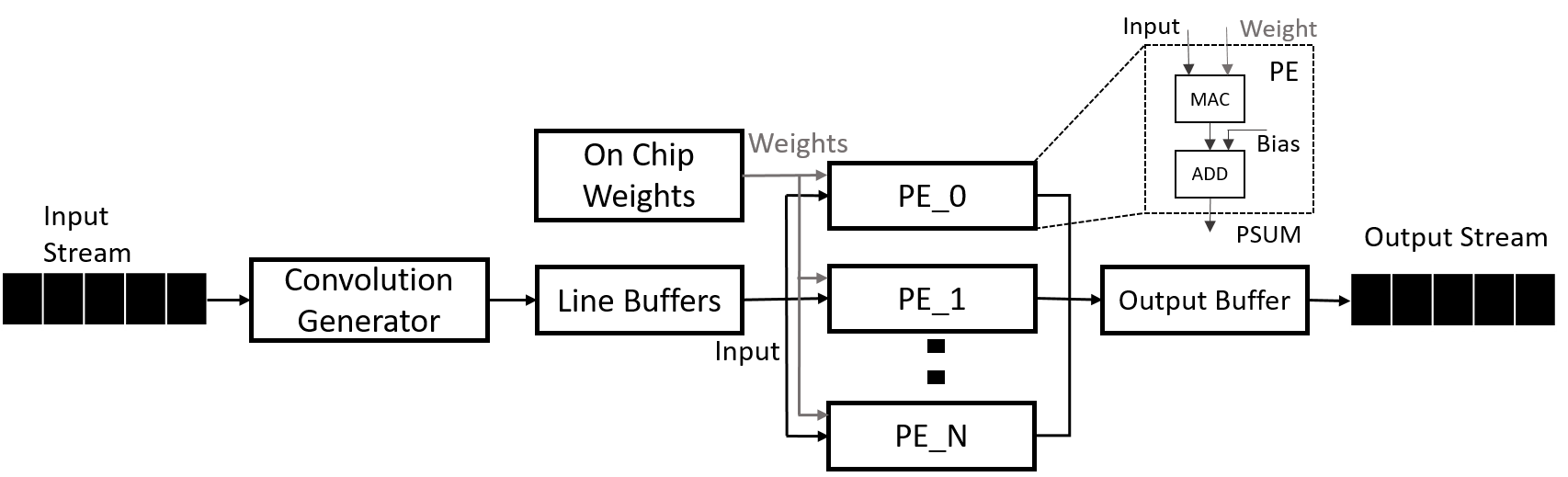
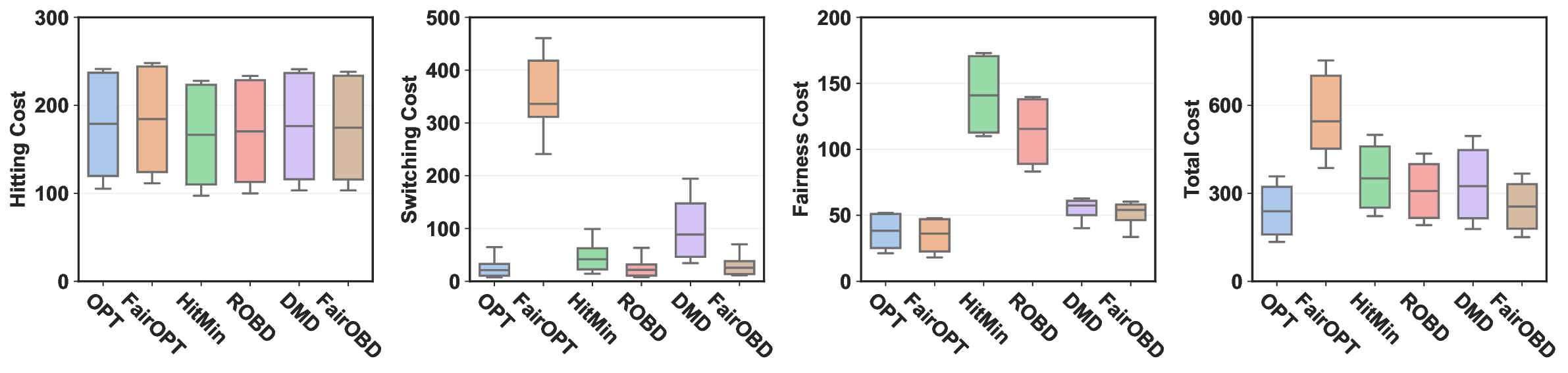
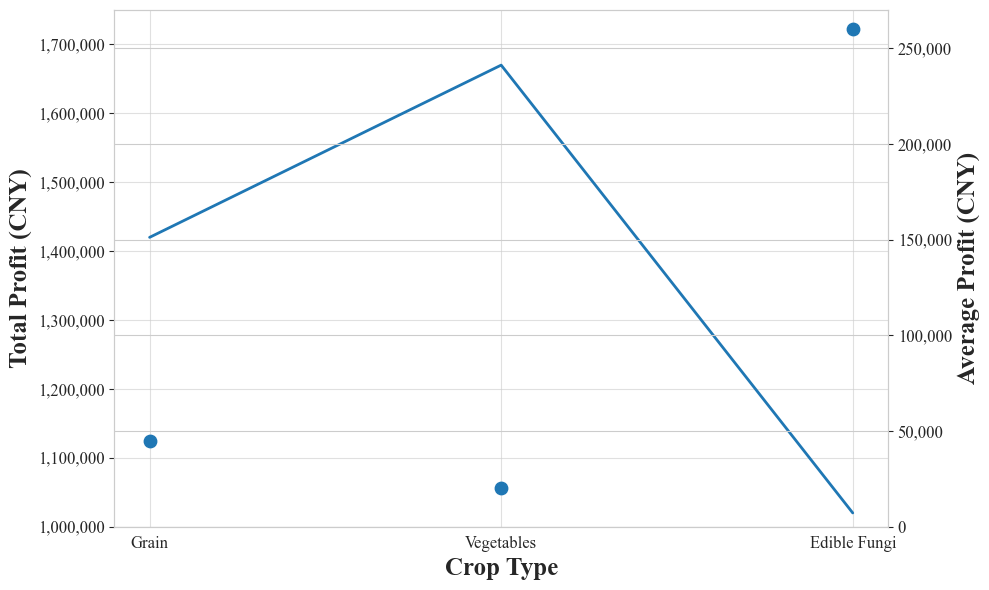
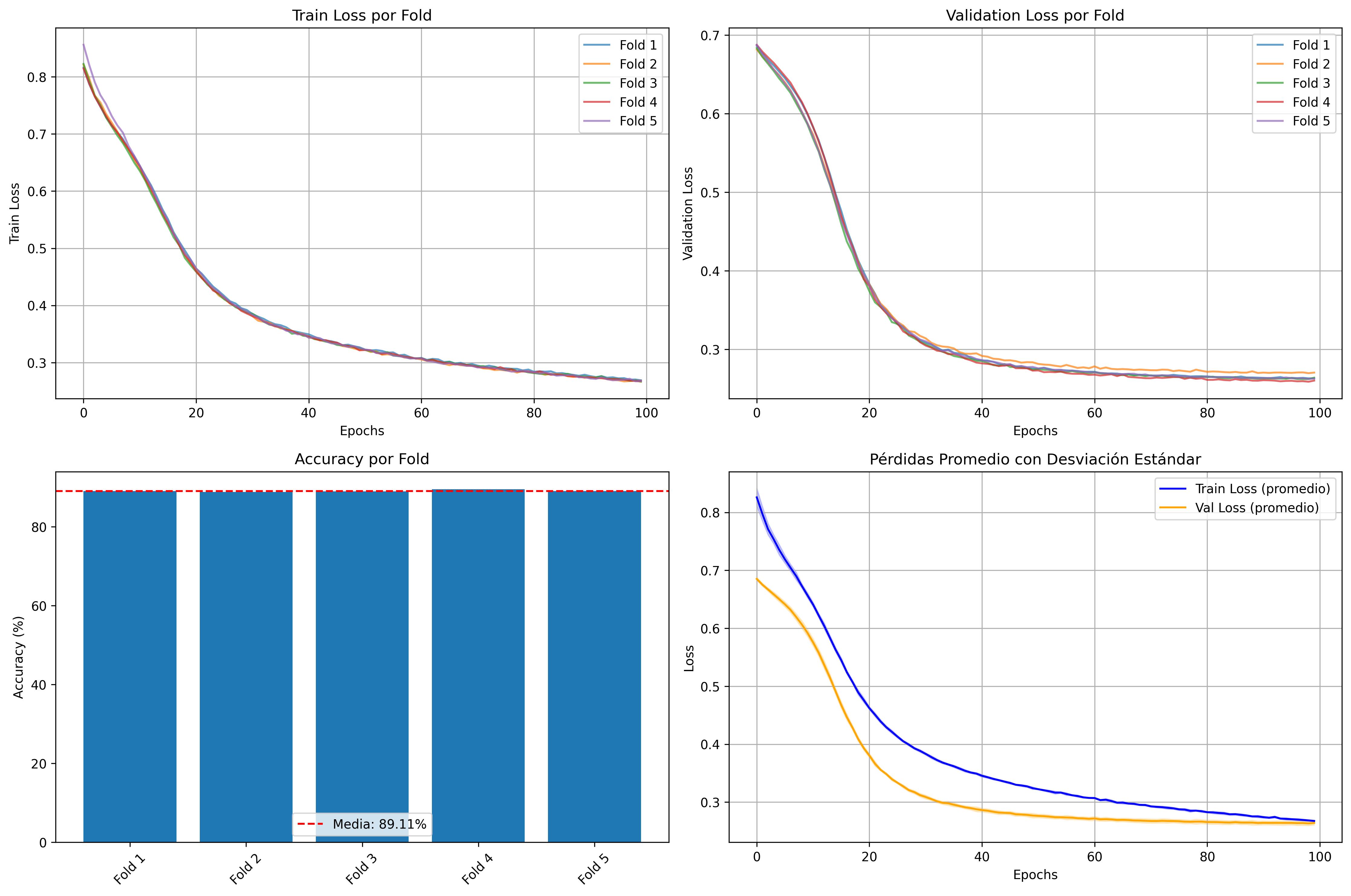
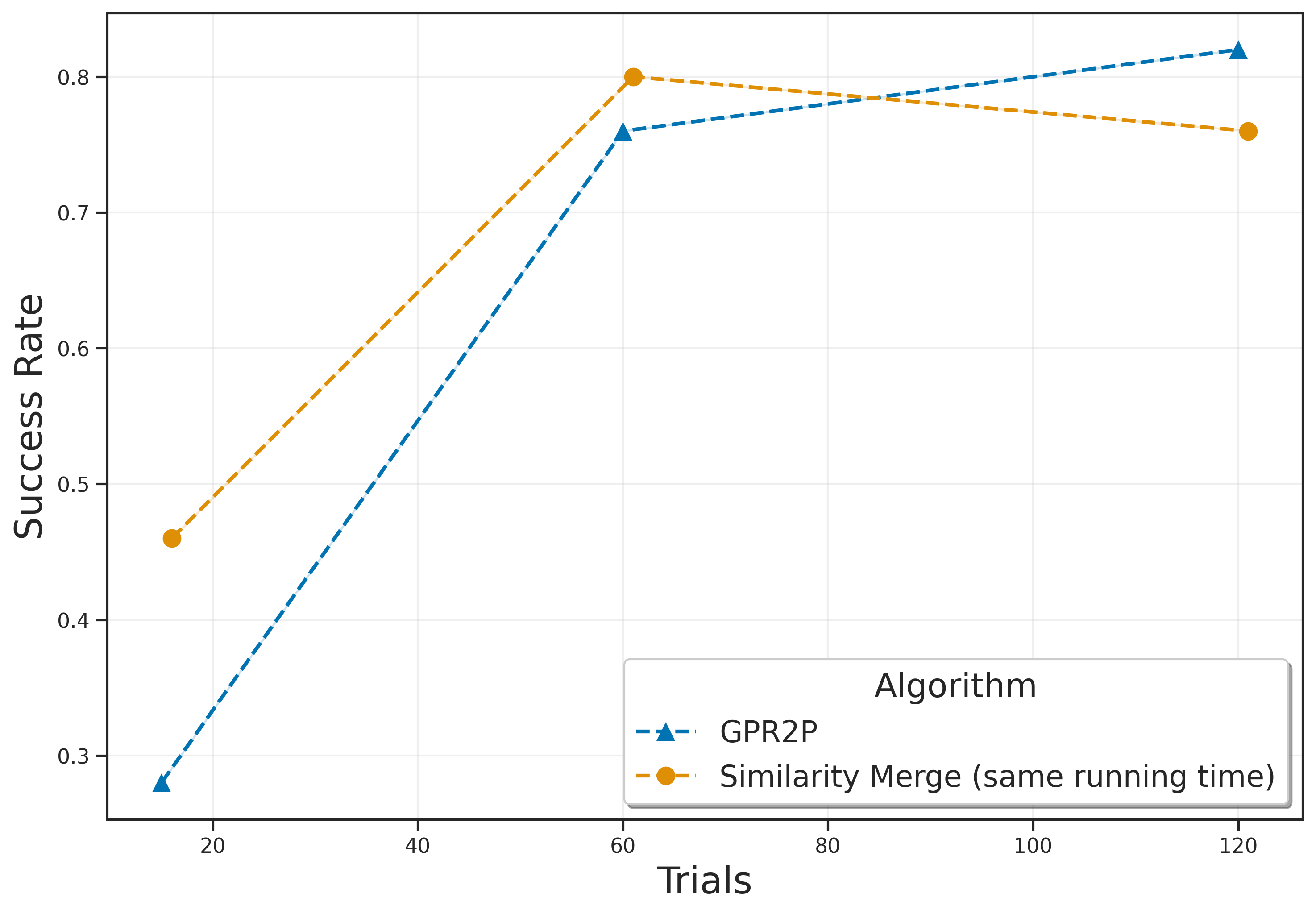
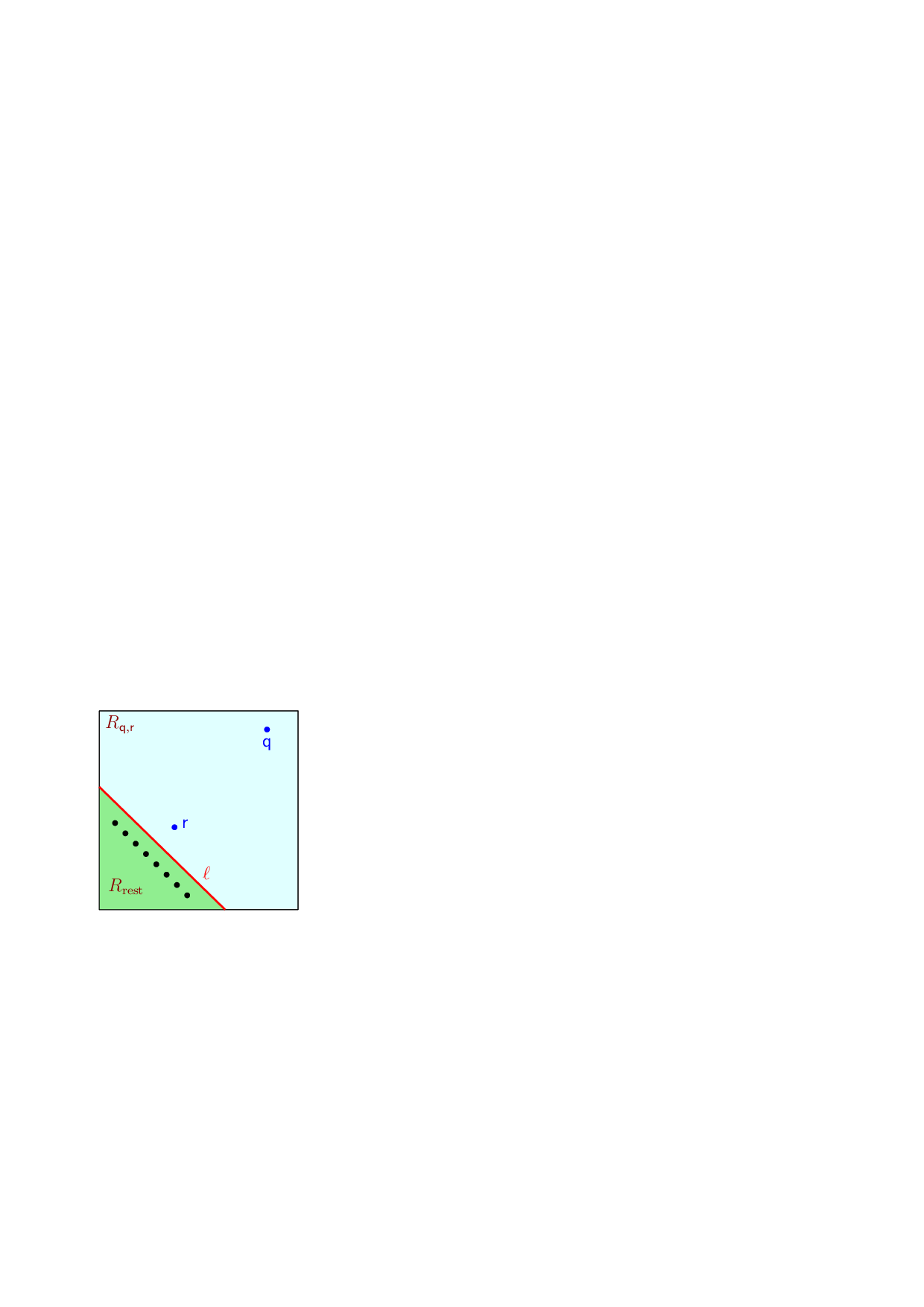
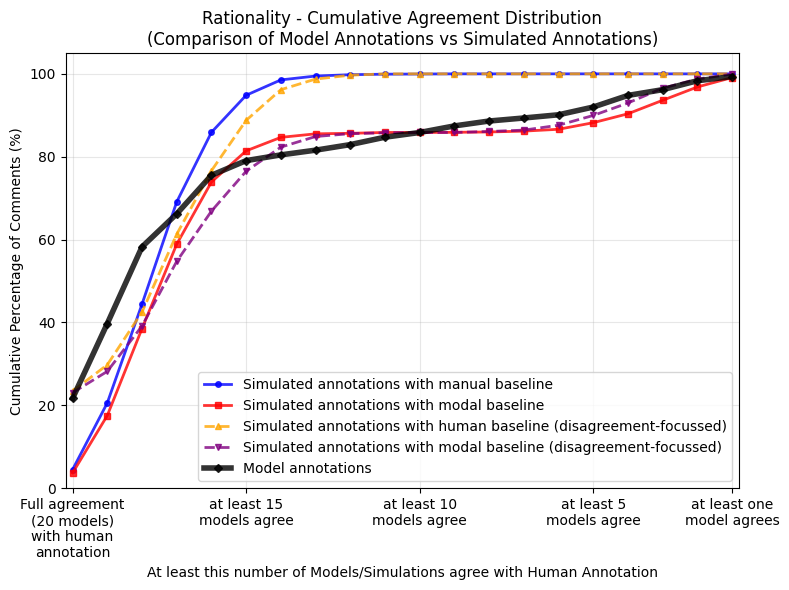
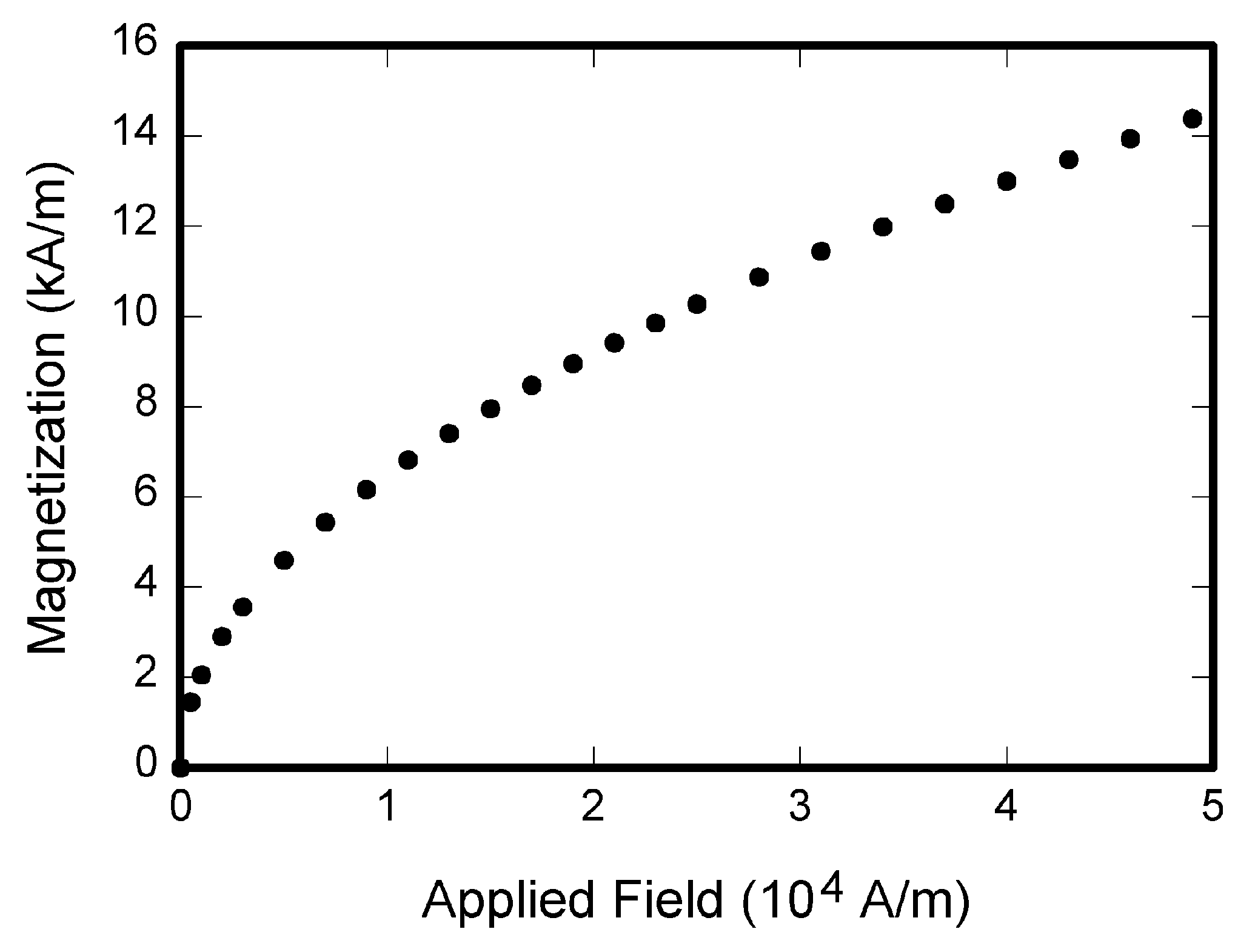
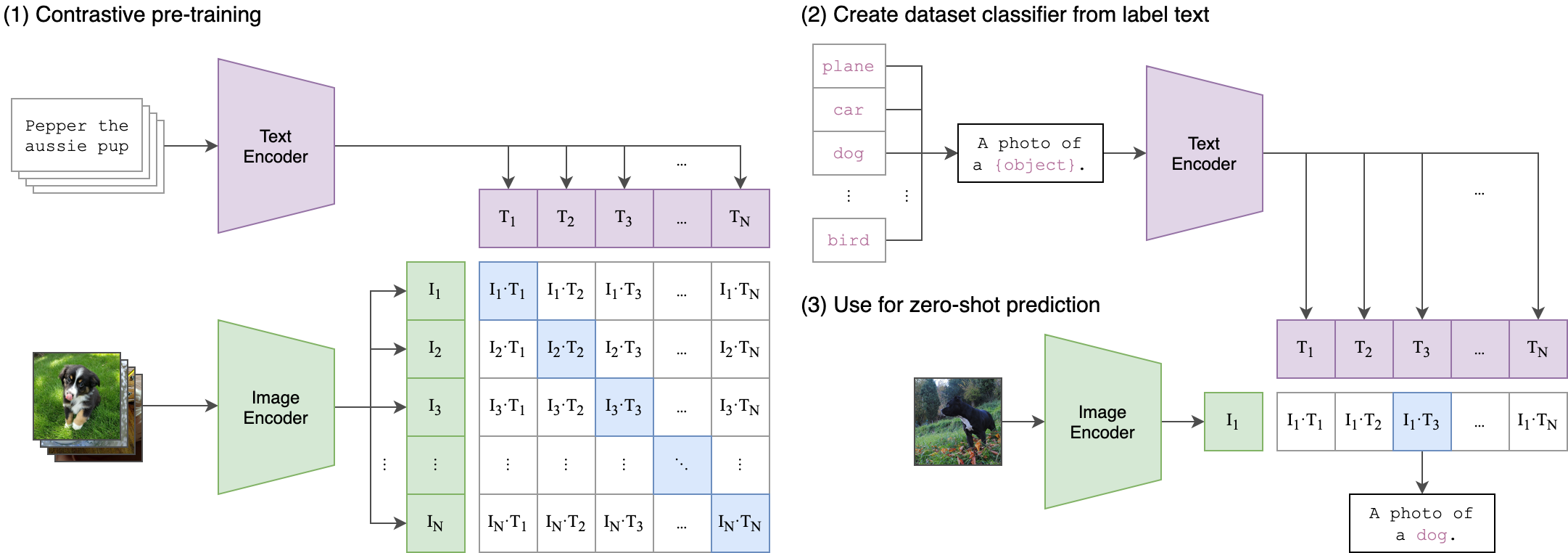
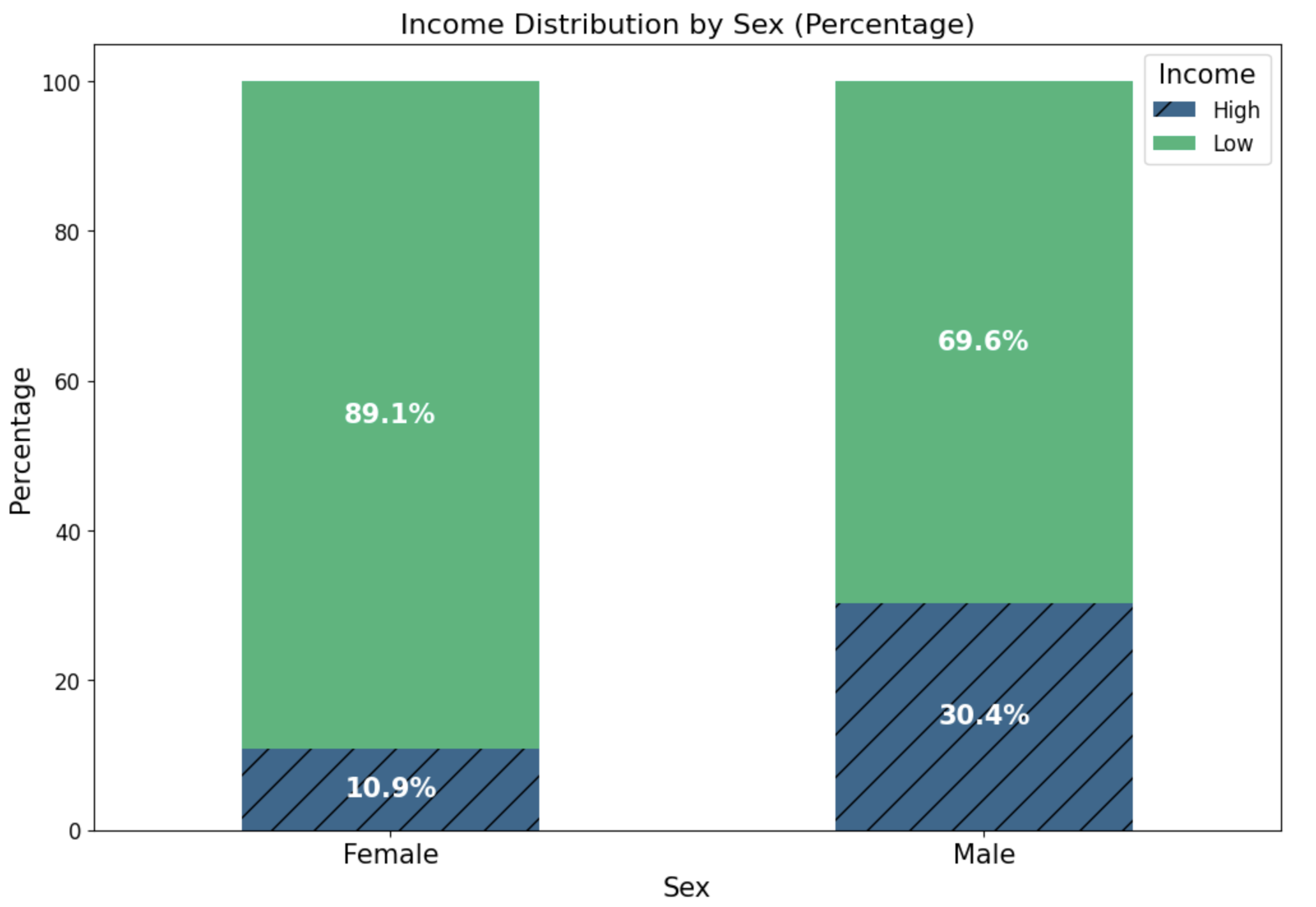
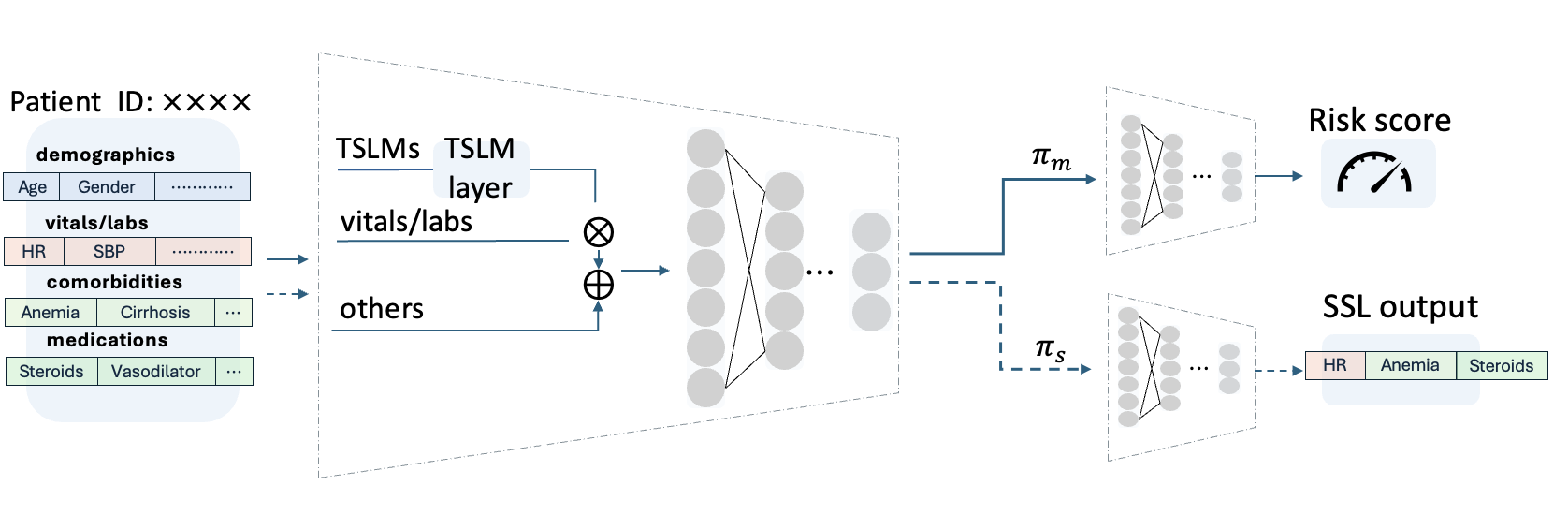
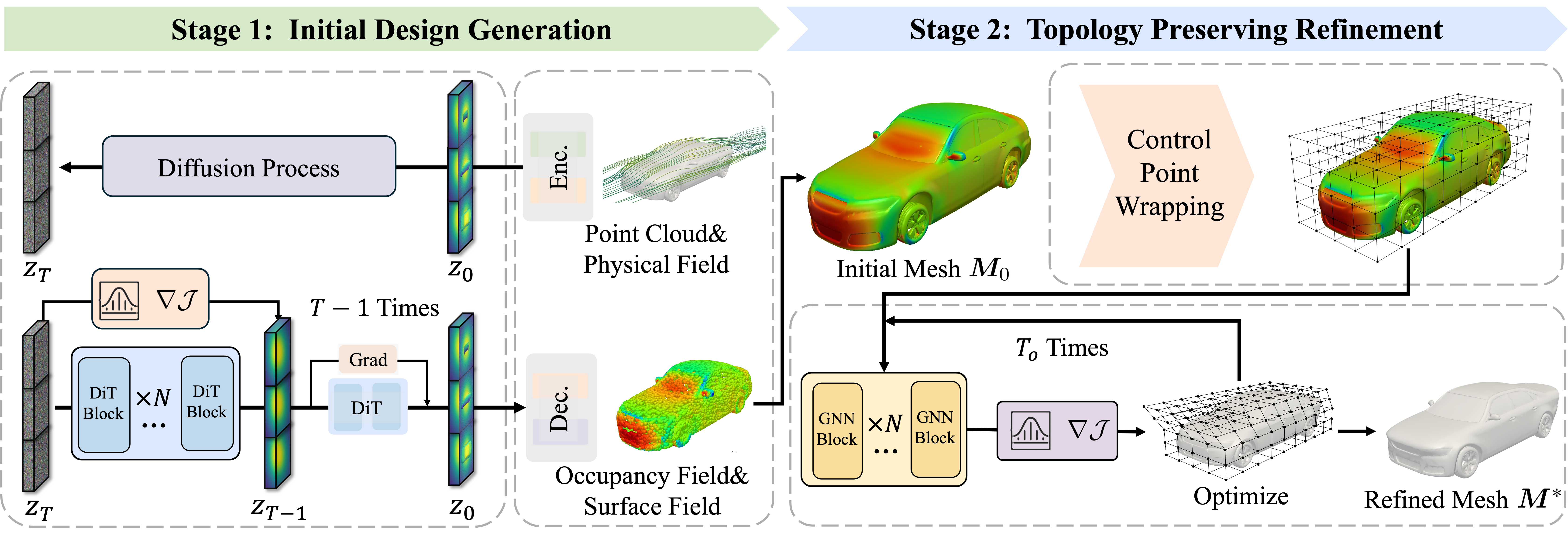
No Image
인공지능의 미래: 데이터 분석을 통한 예측
이 논문은 인공지능(AI) 기술이 데이터 분석을 통해 미래 예측에 어떻게 활용되는지를 탐구한다. AI와 머신러닝 알고리즘의 발전은 다양한 산업에서 혁신적인 변화를 가져왔지만, 동시에 새로운 도전 과제도 제기하고 있다. 특히, 이 연구는 AI가 데이터 분석을 통해 미래 트렌드를 예측하는 데 얼마나 효과적일 수 있는지를 평가한다. 이를 위해 다양한 머신러닝 모델과 알고리즘의 성능을 비교하며, 실제 사례와 함께 그 결과를 분석한다. 이러한 연구는 AI 기술이 더욱 발전함에 따라 미래 예측의 정확도를 높이는 방법론을 제시하는 동시에, 데이