대형 언어 모델 사실 생성의 강인한 불확실성 정량화
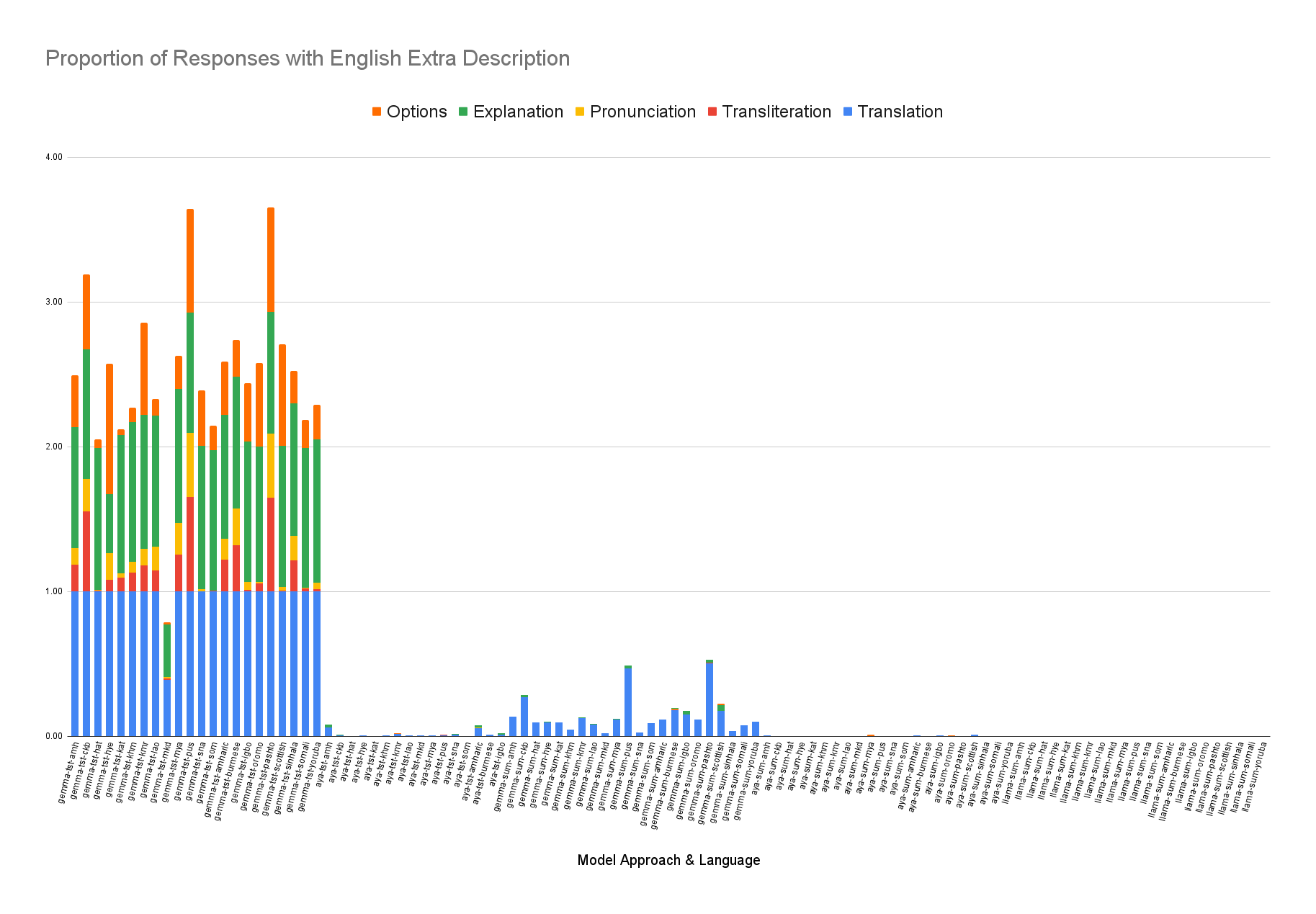
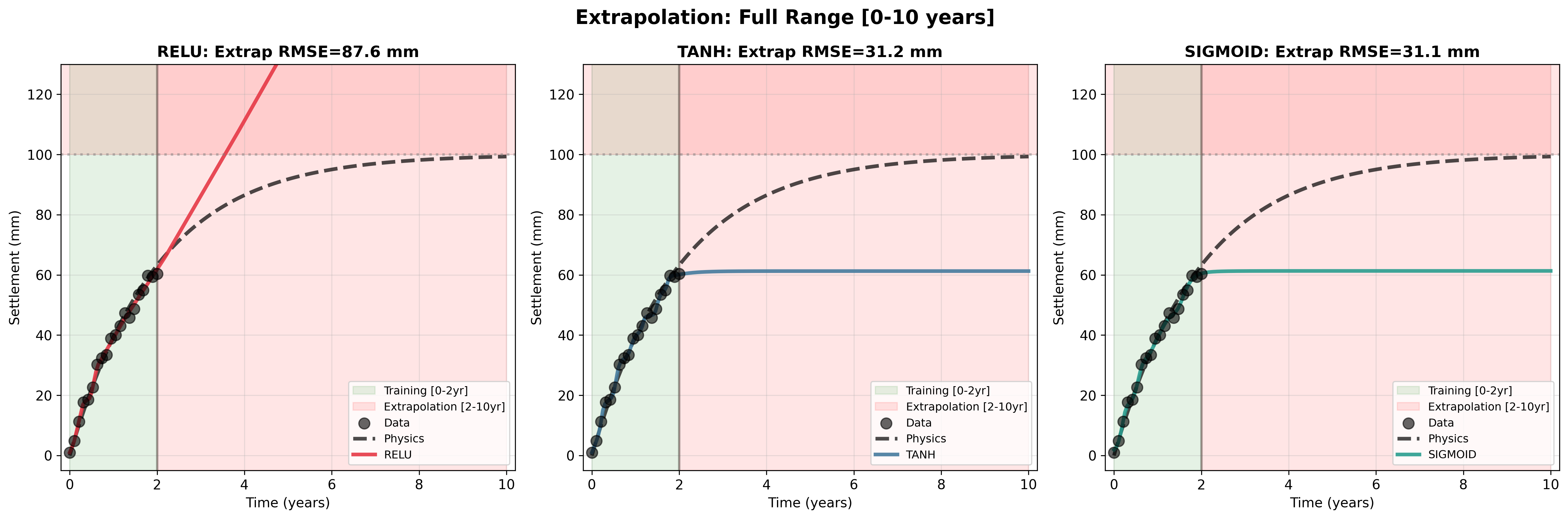
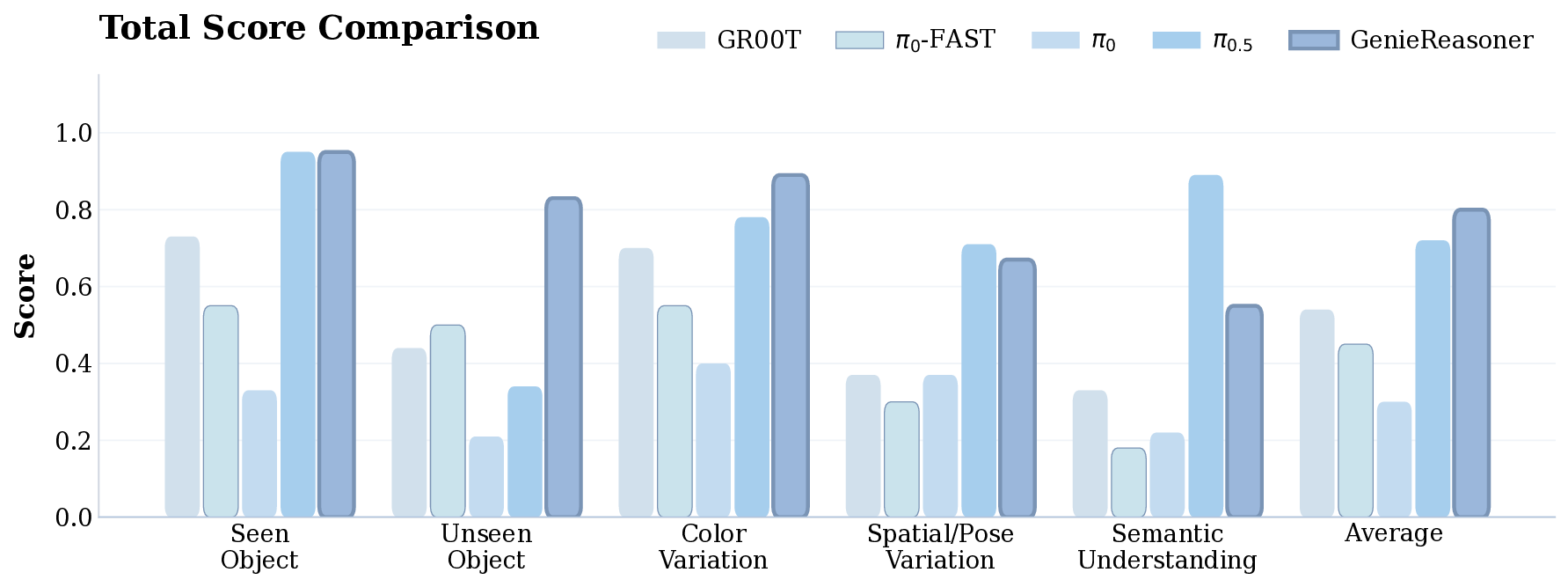
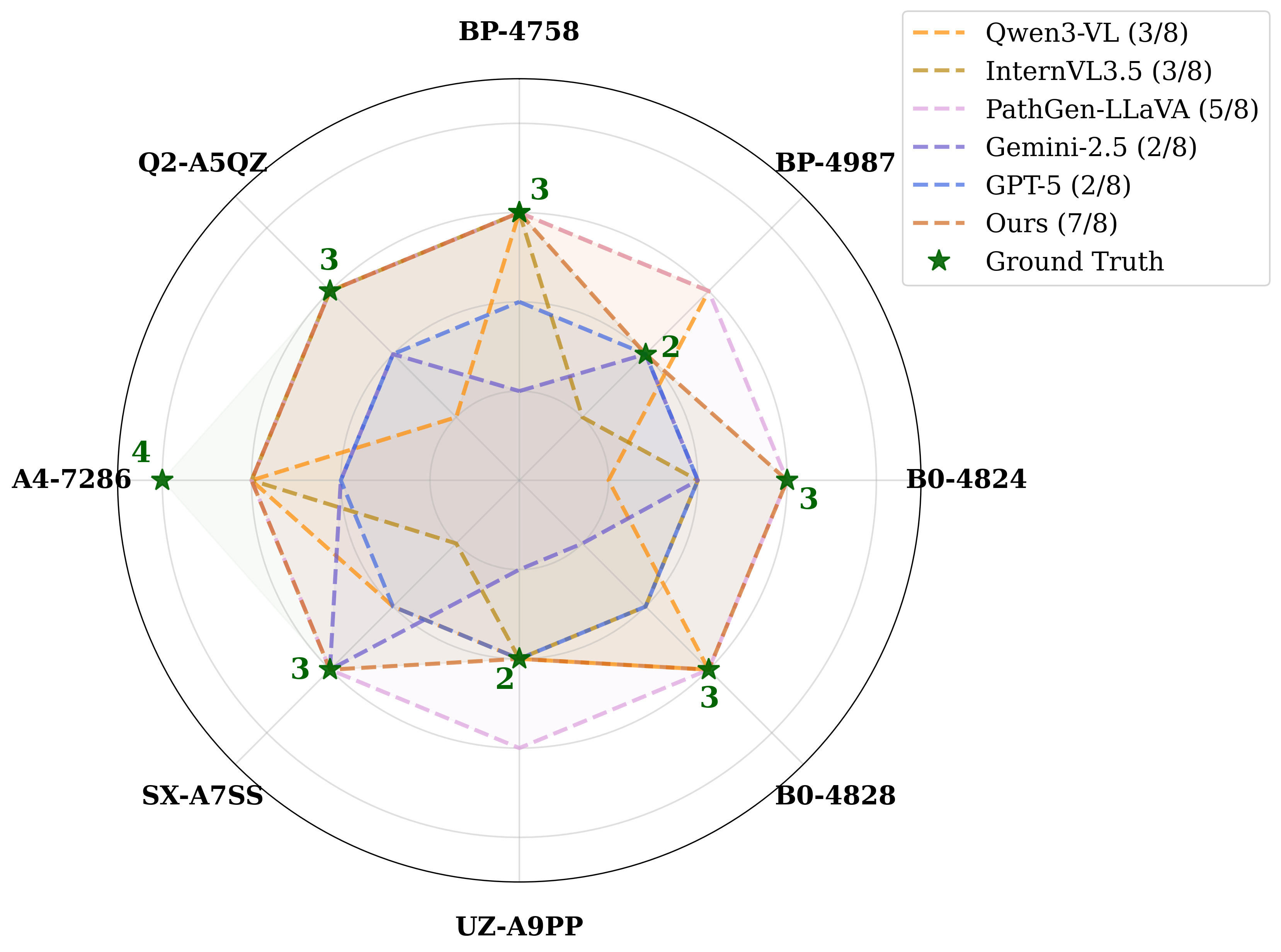
이 논문은 LLM의 ‘환각’ 문제를 불확실성 정량화라는 관점에서 접근한다는 점에서 의미가 크다. 기존의 불확실성 추정 기법—예를 들어 베이지안 신경망, MC‑Dropout, 엔삼블 방법—은 주로 정형화된 QA 데이터셋에서 검증되었으며, 질문이 의도적으로 혼동을 주는 형태일 때는 신뢰도 점수가 급격히 왜곡되는 한계를 보였다. 저자들은 이러한 한계를 극복하기 위해 ‘함정 질문(trap question)’이라는 새로운 평가 도구를 설계했는데, 여기에는 실제 존재하지 않는 인물명이나 허위 사실이 삽입되어 모델이 사실을 생성하도록 유도한다.
Computer Science
NLP
Model