Title: Multi-granularity Interactive Attention Framework for Residual Hierarchical Pronunciation Assessment
ArXiv ID: 2601.01745
발행일: 2026-01-05
저자: Hong Han, Hao-Chen Pei, Zhao-Zheng Nie, Xin Luo, Xin-Shun Xu
📝 초록 (Abstract)
자동 발음 평가는 컴퓨터 지원 발음 훈련 시스템에서 핵심적인 역할을 수행하며, 다양한 측면과 수준의 발음을 동시에 평가하는 능력이 중요합니다. 기존 방법들은 인접한 수준 간의 일방향 의존성만 고려하여 음절, 단어, 구문 수준 간 상호작용을 충분히 포착하지 못했습니다. 이를 해결하기 위해 제안된 HIA(Hierarchical Interactive Attention)는 다양한 수준 간 상호 모델링을 가능하게 하는 혁신적인 접근법입니다. 이 프레임워크는 상호 주의 모듈을 통해 각 수준에서 언어적 특징을 효과적으로 포착하고, 1차원 컨볼루션 레이어를 사용하여 지역적 문맥 단서를 강화 추출합니다. 실험 결과, HIA는 기존 최첨단 방법보다 우수한 성능을 보여주었습니다.
💡 논문 핵심 해설 (Deep Analysis)
1. 연구 배경과 문제점
본 논문은 자동 발음 평가(APA)의 중요성을 강조하며, 특히 컴퓨터 지원 발음 훈련 시스템(CAPT)에서 핵심적인 역할을 수행하고 있음을 설명합니다. APA는 화자의 발음 품질을 평가하고 세부적인 피드백을 제공하여 외국어 학습을 지원하는 것을 목표로 합니다.
기존의 APA 연구들은 주로 단일 수준에서 발음을 평가하거나, 여러 수준 간 상호작용을 고려하지 못한 채 일방향 의존성을 모델링하였습니다. 이러한 접근 방식은 자연스러운 복잡성과 다수준 특성을 고려하지 못하는 한계를 가지고 있습니다.
2. HIA 프레임워크의 핵심 구성 요소
HIA는 다양한 수준 간 상호작용을 효과적으로 모델링하기 위해 설계되었습니다. 주요 구성 요소는 다음과 같습니다:
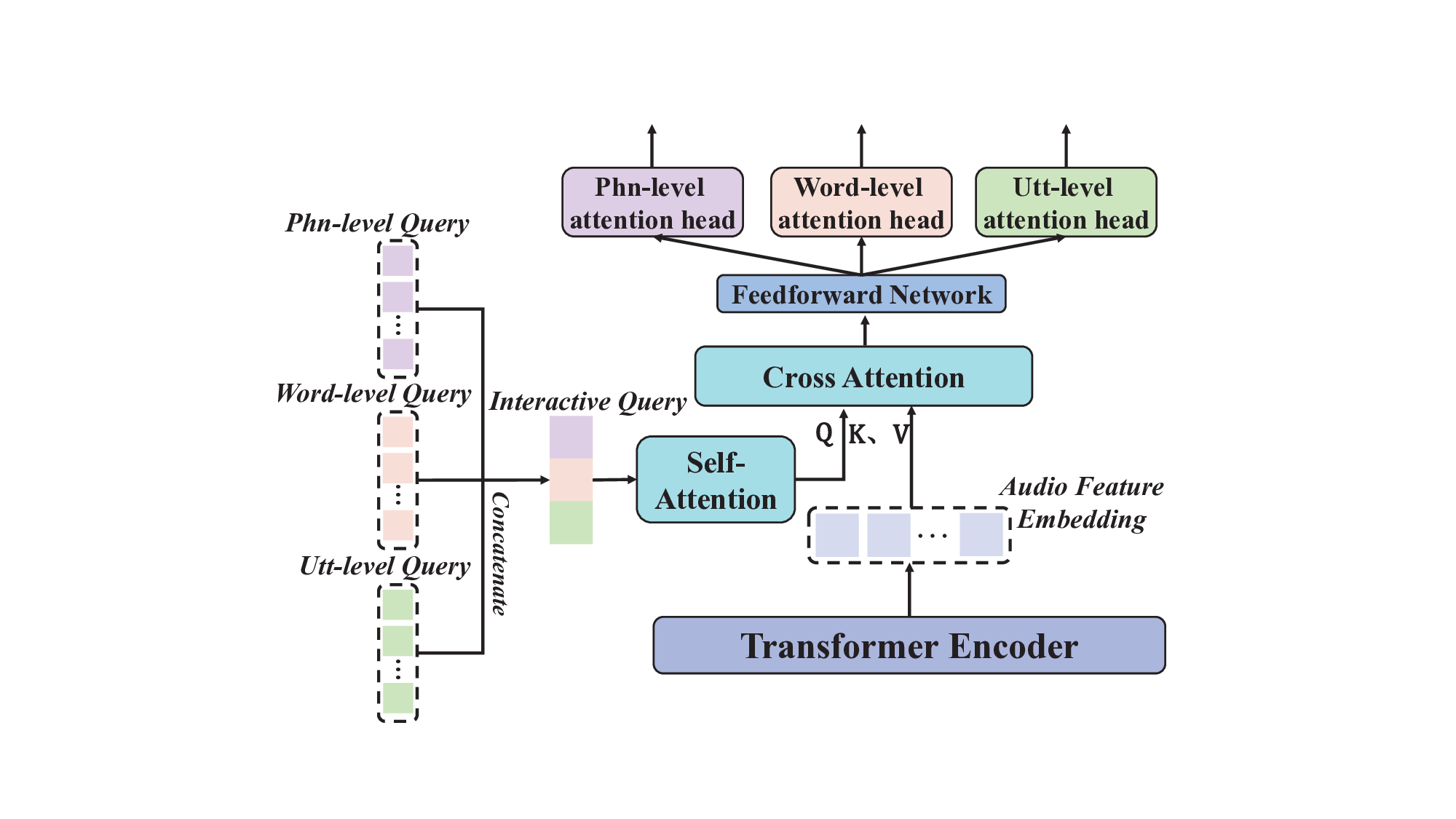
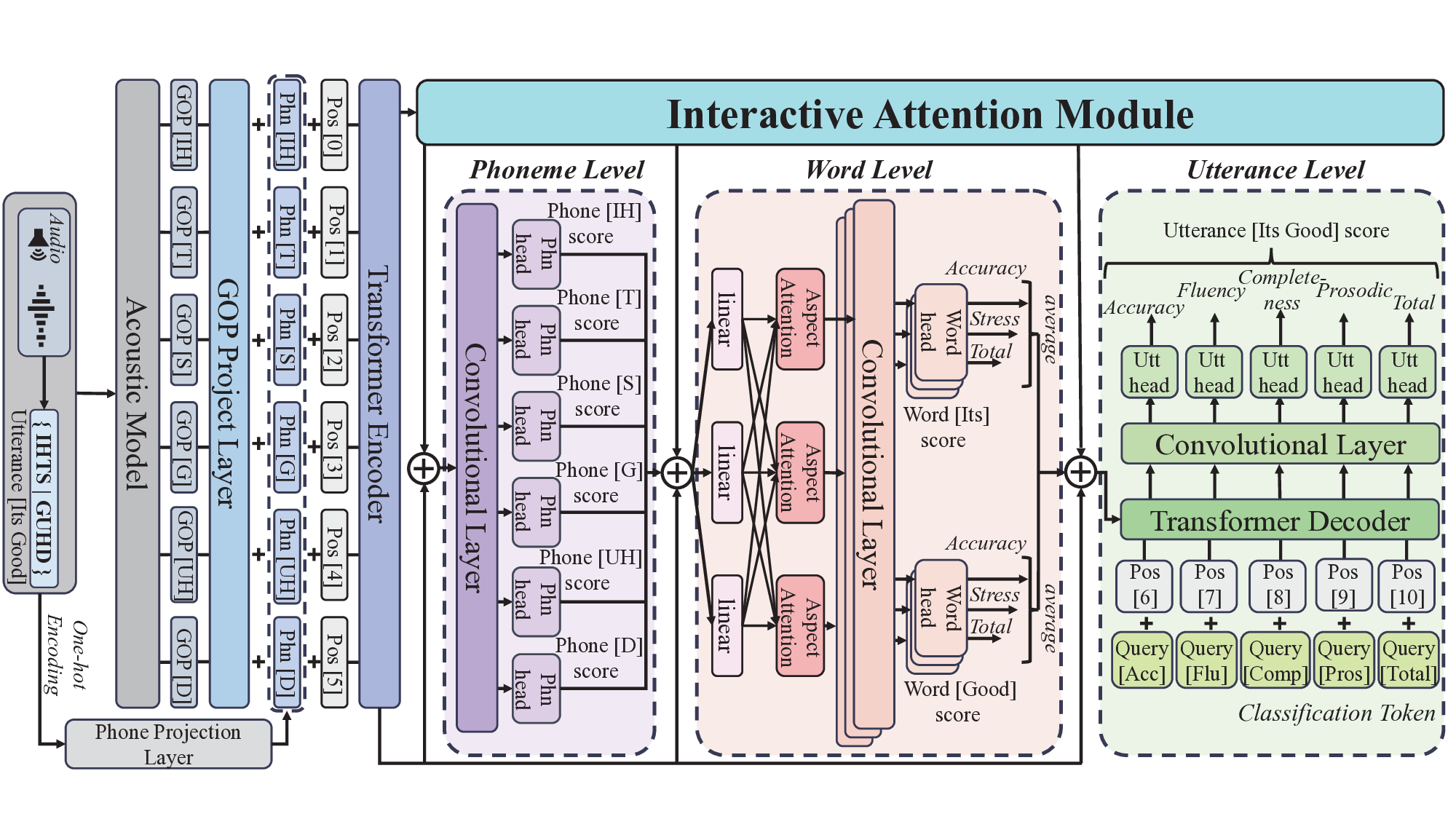
상호 주의 모듈 (Interactive Attention Module): 이 모듈은 각 수준에서 언어적 특징을 포착하고, 다른 수준 간의 상관관계를 통합합니다.
잔여 계층 구조 (Residual Hierarchical Structure): 초기 인코딩 특징을 잃지 않도록 설계되었습니다. 이를 통해 모델 깊이가 증가함에 따라 발생할 수 있는 문제를 완화합니다.
HIA는 SpeechOcean762 데이터셋에서 광범위한 실험을 통해 평가되었습니다. 실험 결과, HIA는 모든 지표에서 최첨단 성능을 달성하였습니다. 특히, 인적 전문가 평가와 비교했을 때 우수한 성능을 보여주었으며, 단일 수준 점수 방법에 비해 유의미하게 더 나은 결과를 얻었습니다.
모델 구성 및 실험 설정: HIA는 Transformer 인코더와 디코더 계층 각각 3개로 구성되었고, 임베딩 차원은 48이었습니다. 드롭아웃 비율은 0.1로 설정되었습니다.
성능 분석: 실험 결과, HIA는 모든 지표에서 우수한 성능을 보여주었으며, 특히 단어 강세와 발화 수준의 점수에 큰 영향을 미쳤습니다.
4. 모델의 장점과 한계
HIA의 주요 기여는 다음과 같습니다:
상호작용적 다중 측면 다중 계층 발음 평가: 다양한 수준 간 상호작용을 효과적으로 포착하여 발음 점수를 예측합니다.
잔여 연결과 1차원 컨볼루션 레이어의 활용: 초기 인코딩 특징을 잃지 않도록 하며, 지역적 문맥 단서를 강화 추출합니다.
그러나 HIA도 몇 가지 한계가 있습니다:
데이터셋 크기와 과적합 문제: 실험에서 컨볼루션 레이어의 수를 증가시키면 과적합 문제가 발생할 수 있었습니다.
모델 용량과 성능: 임베딩 크기를 증가시켜 모델 용량을 확대하면 성능 향상이 나타났지만, 이는 더 많은 학습 데이터와 계산 자원을 필요로 합니다.
5. 결론 및 미래 연구 방향
HIA는 다양한 수준 간 상호작용을 효과적으로 모델링하여 발음 평가의 정확성을 크게 향상시켰습니다. 실험 결과, HIA는 기존 방법보다 우수한 성능을 보여주었으며, 특히 인적 전문가 평가와 비교했을 때도 뛰어난 성과를 달성하였습니다.
미래 연구에서는 데이터셋의 크기를 확대하고, 모델 용량을 더욱 늘려 과적합 문제를 해결하는 방향으로 나아갈 필요가 있습니다. 또한, 다양한 언어와 발음 평가 시나리오에 대한 성능 테스트를 통해 HIA의 일반화 능력을 검증할 수 있을 것입니다.
자동 발음 평가는 컴퓨터 지원 발음 훈련 시스템에서 중요한 역할을 수행합니다. 여러 발음 과제를 동시에 처리할 수 있는 능력으로 인해, 다중 측면 다곡률 발음 평가 방법이 단일 수준 모델링 작업보다 더 나은 성능을 보여주며 점차 주목받고 있습니다. 그러나 기존 방법들은 인접한 곡률 수준 간의 일방향 의존성만 고려하여, 음절, 단어, 구문 수준 간 상호작용을 고려하지 못함으로써 음향 구조적 상관관계를 충분히 포착하지 못합니다. 이를 해결하기 위해, 우리는 잔류 계층적 상호 주의(HIA)라는 새로운 방법을 제안합니다. HIA는 다양한 곡률 간 상호 모델링을 가능하게 하는 혁신적인 접근법입니다. HIA의 핵심인 상호 주의 모듈은 주의를 통해 동적 일방향 상호작용을 달성하여 각 곡률에서 언어적 특징을 효과적으로 포착하고 다른 곡률 수준 간의 상관관계를 통합합니다. 또한, 우리는 음향 계층 구조를 제안하여 모델이 다양한 곡률 수준에서 특징을 잊는 문제를 완화합니다. 더 나아가, 1차원 컨볼루션 레이어를 사용하여 각 곡률에서 지역적 문맥 단서를 강화 추출합니다. 광범위한 실험 결과, 우리 모델은 기존 최첨단 방법보다 우수한 성능을 보여주었습니다.
서론
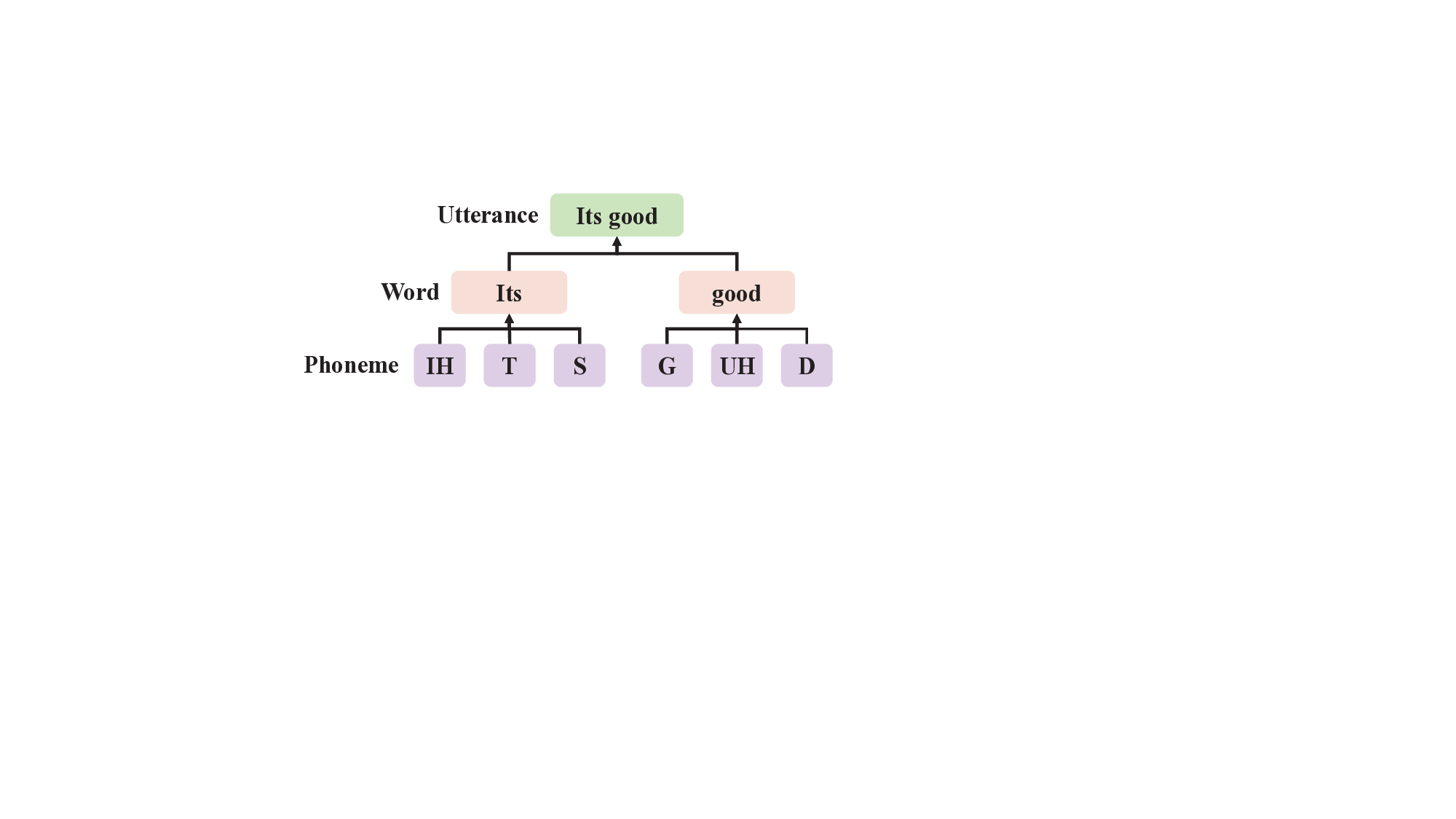
언어 학습 분야에서 컴퓨터 지원 발음 훈련 시스템(CAPT) (Eskenazi 2009; Tejedor-García 등 2020)은 컴퓨터 기술을 활용하여 언어 학습자들이 발음 능력을 향상시킬 수 있도록 상호작용 훈련 방법을 제공하며 즉각적인 피드백을 제공합니다. CAPT의 핵심 구성 요소인 자동 발음 평가(APA) (Li, Wu, & Meng 2017; Kheir, Ali, & Chowdhury 2023)는 화자의 발음 품질을 평가하고 세부적인 피드백을 제공하여 외국어 학습을 지원하는 것을 목표로 합니다. 초기 APA 연구는 주로 음성 데이터의 신호 곡률에 집중했습니다. 예를 들어, 발음 정확도를 음절 수준에서 평가 (Wang & Lee 2012)하거나 단어 또는 구문 수준에서 다양한 측면을 감지 (Tepperman & Narayanan 2005; Arias 등 2010)하는 방법이 연구되었습니다. 이러한 단일 곡률 평가 방법은 특정 과제에 대한 성능이 우수하지만 여러 한계가 있습니다. 특히, 이들은 자연스러운 복잡성과 다곡률 특성을 고려하지 않습니다 (Lin 등 2020). 발음 평가 과제 간의 곡률은 서로 분리되지 않으며, Fig. 1에 보여지듯 간접적인 상관관계가 존재합니다. 음성 신호는 일반적으로 계층적 구조를 가지며, 낮은 수준의 발음 결과가 상위 수준의 발음을 영향을 미칩니다 (Al-Barhamtoshy, Abdou, & Jambi 2014). 그러나 단일 곡률 수준을 모델링하는 것은 이러한 다양한 곡률 수준 간의 간접적인 관계들을 완전히 드러내지 못합니다.
최근, 읽기 소리 내기 시나리오에서 여러 수준의 곡률에 대한 음성 특징을 포괄적으로 분석하기 위해 연구자들은 다중 측면 다곡률 발음 평가 과제를 단일 모델에 통합하여 동시에 여러 측면을 평가하는 접근 방식을 시도하고 있습니다.
발음 평가: 상호작용적 다중 측면 다중 계층 프레임워크 (HIA)
서론
기존의 발음 평가 방법들은 정확성, 유창성, 운율 및 완전성 등 다양한 측면을 단일 모델 내에서 통합하지 못하고, 각 계층(음소, 단어, 구문) 간 상호작용을 고려하지 못한다는 한계가 있습니다. GOPT (Gong et al., 2022)는 다중 계층 과제를 병렬로 모델링하여 다양한 계층 점수를 효과적으로 처리하지만, 계층 간의 상호작용이 부족하여 복잡한 계층 간 상관관계를 포착하는 데 제한적입니다. HiPAMA (Do, Kim, & Lee, 2023)는 계층 의존성을 포착하기 위해 계층적 구조를 사용하지만, 정보 흐름이 일방향이라 양방향 상호작용을 고려하지 못합니다. Gradformer (Pei et al., arXiv:2601.01745v1 [cs.CL] 5 Jan 2026, 2024)는 구문 모델링에 집중하여 음소와 단어 수준 간의 상관관계를 포착하지 못하며, Hier-GAT (Yan & Chen, 2024)는 그래프 신경망을 사용하여 계층적 모델링을 수행하지만, 고정된 그래프 구조로 인해 다양한 계층 간 동적 상호작용을 제한합니다.
문제점
위 방법들은 주로 인접한 계층 간의 일방향 관계만 고려하며, 음소, 단어 및 구문 수준 간의 상호작용 모델링이 부족하여 양방향 상호작용을 달성하지 못합니다. 또한 계층적 모델링 방법의 경우, 계층 수준이 증가함에 따라 모델 깊이가 증가하여 초기 인코딩 특징을 잊어버리는 문제가 발생할 수 있습니다.