Logics STEM 실패 기반 사후 학습과 문서 지식 강화로 LLM 추론력 극대화
📝 원문 정보
- Title: Logics-STEM: Empowering LLM Reasoning via Failure-Driven Post-Training and Document Knowledge Enhancement
- ArXiv ID: 2601.01562
- 발행일: 2026-01-04
- 저자: Mingyu Xu, Cheng Fang, Keyue Jiang, Yuqian Zheng, Yanghua Xiao, Baojian Zhou, Qifang Zhao, Suhang Zheng, Xiuwen Zhu, Jiyang Tang, Yongchi Zhao, Yijia Luo, Zhiqi Bai, Yuchi Xu, Wenbo Su, Wei Wang, Bing Zhao, Lin Qu, Xiaoxiao Xu
📝 초록 (Abstract)
우리는 Logics‑STEM이라는 최신 추론 모델을 소개한다. 이 모델은 720만 건 규모의 고품질·다양한 데이터셋인 Logics‑STEM‑SFT‑Dataset으로 미세조정되었으며, 현재 공개된 가장 큰 장기 사고 사슬 코퍼스 중 하나이다. Logics‑STEM은 과학·기술·공학·수학(STEM) 분야의 추론 과제에 특화되어 8B 파라미터 규모 모델 중 평균 4.68%의 성능 향상을 달성한다. 성능 향상의 핵심은 데이터‑알고리즘 공동 설계 엔진으로, 금표준 추론 분포에 맞추어 최적화한다. 데이터 측면에서는 주석, 중복 제거, 오염 방지, 증류, 층화 샘플링의 5단계 파이프라인을 통해 품질·다양성·확장성을 확보하였다. 알고리즘 측면에서는 실패 영역을 중심으로 목표 지식 검색 및 데이터 합성을 수행하는 실패‑주도 사후 학습 프레임워크를 도입해 두 번째 SFT 단계 혹은 강화학습(RL) 단계에서 목표 분포에 더 잘 맞추도록 유도한다. 실험 결과 Logics‑STEM이 대규모 오픈소스 데이터와 정교하게 설계된 합성 데이터를 결합했을 때 추론 능력이 크게 향상됨을 보여주며, 데이터‑알고리즘 공동 설계가 사후 학습을 통한 추론 강화에 핵심적임을 강조한다. 우리는 8B와 32B 두 버전의 모델과 공개 가능한 530만 건(전체 720만 건 중) 및 160만 건 다운샘플 버전의 데이터셋을 공개하여 향후 연구에 기여한다.💡 논문 핵심 해설 (Deep Analysis)
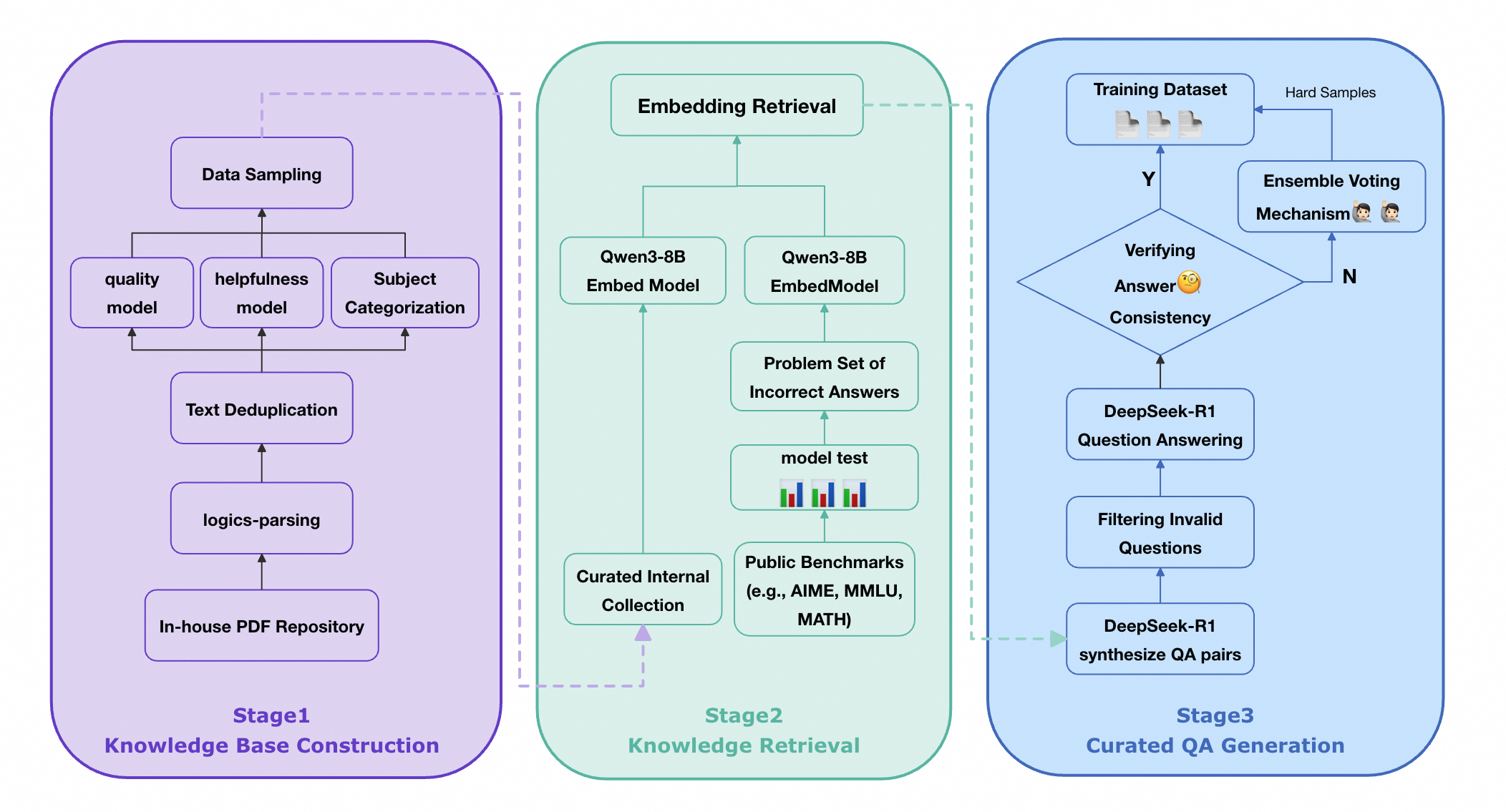
![]()
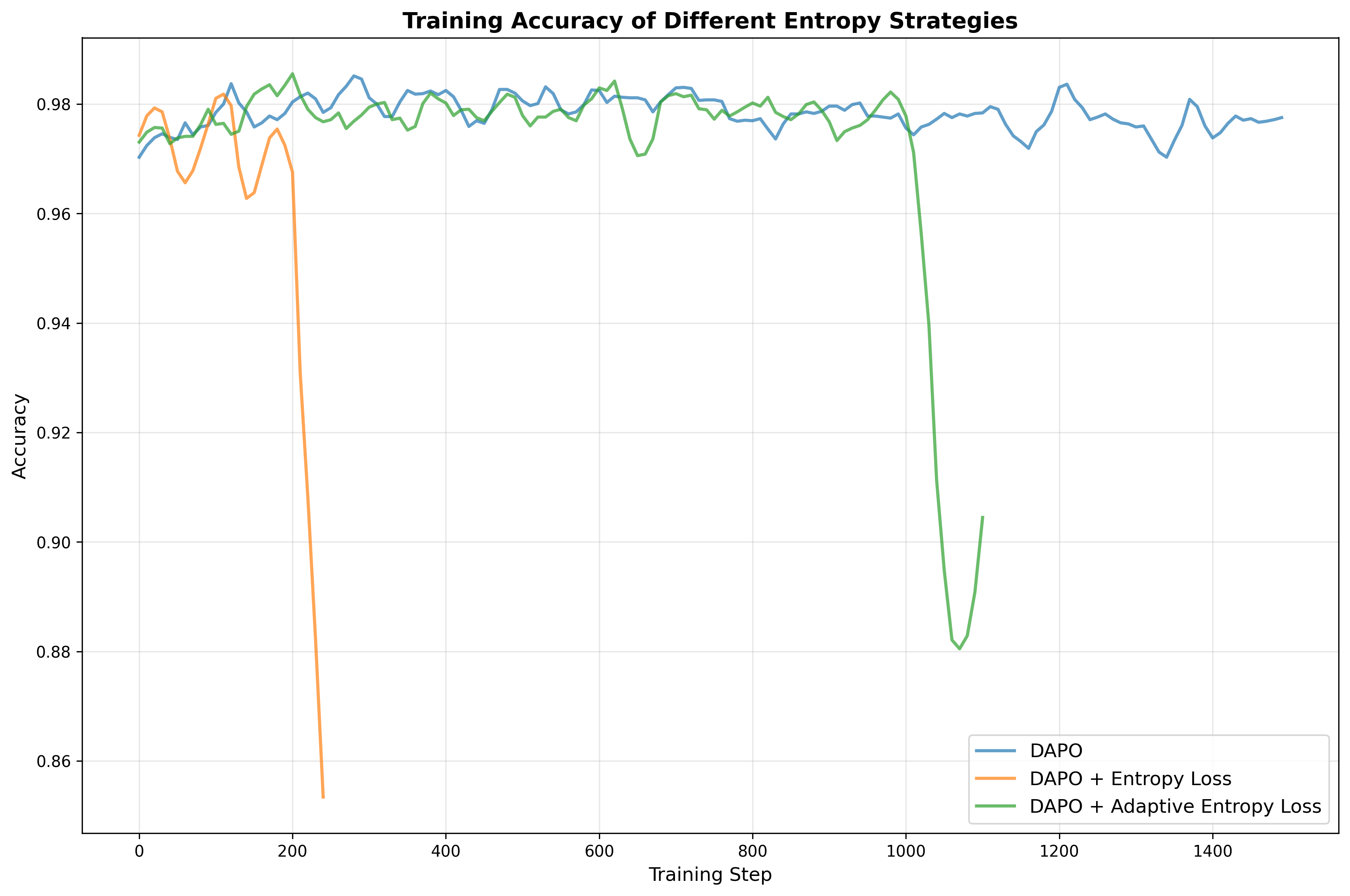
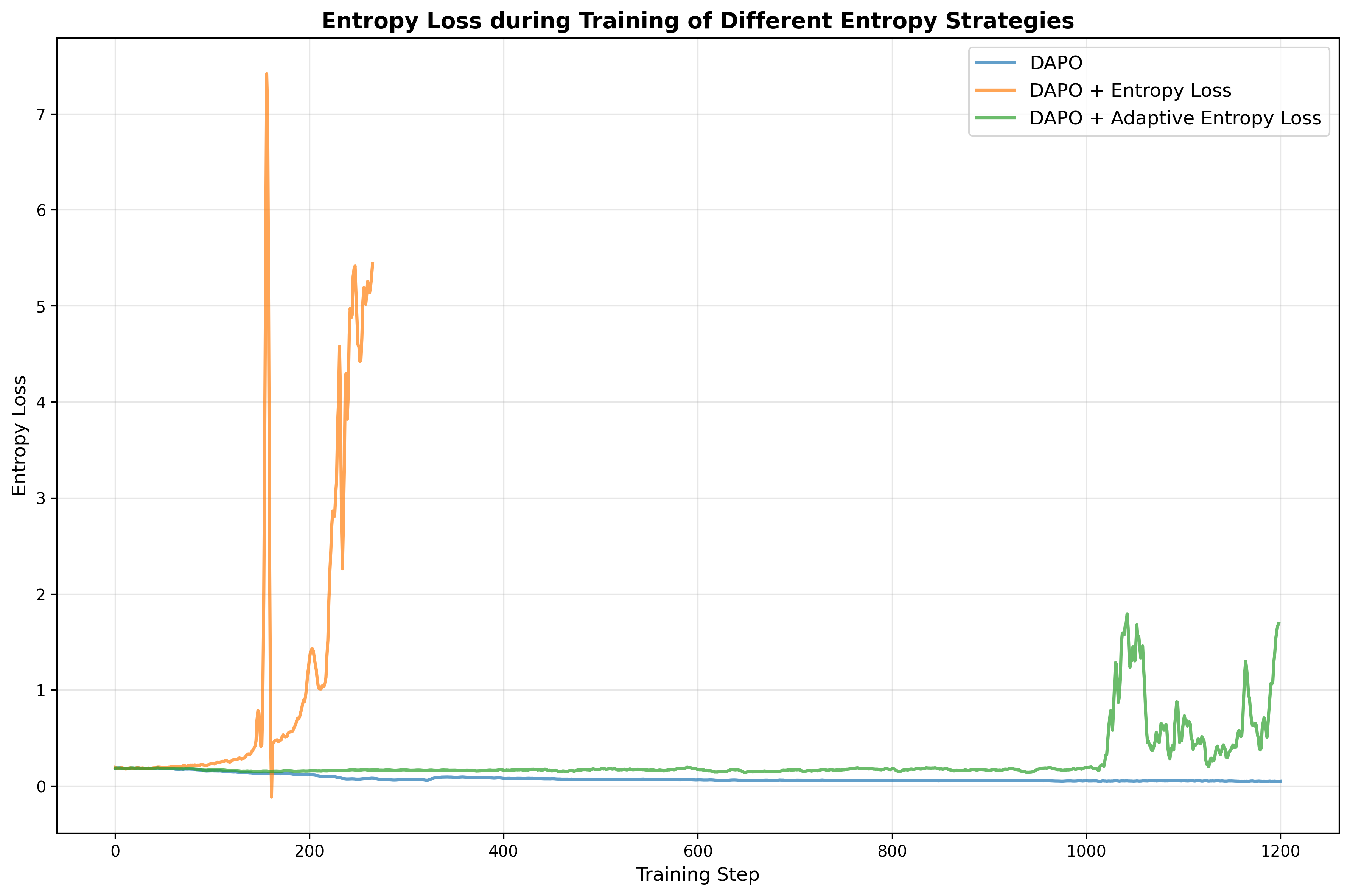
알고리즘 측면에서는 “실패‑주도(Failure‑Driven) 사후 학습”이라는 새로운 프레임워크를 도입한다. 기존 SFT 단계에서 모델이 자주 틀리는 영역을 식별하고, 해당 영역에 대한 외부 지식 검색(예: 위키피디아, 과학 논문)과 합성 데이터를 추가 생성한다. 이렇게 생성된 “실패‑보강 데이터”는 두 번째 SFT 혹은 강화학습(RL) 단계에서 재학습에 사용된다. 결과적으로 모델은 약점이었던 부분을 집중적으로 보완하게 되며, 전체적인 추론 분포가 금표준(gold‑standard)과 더 가까워진다.
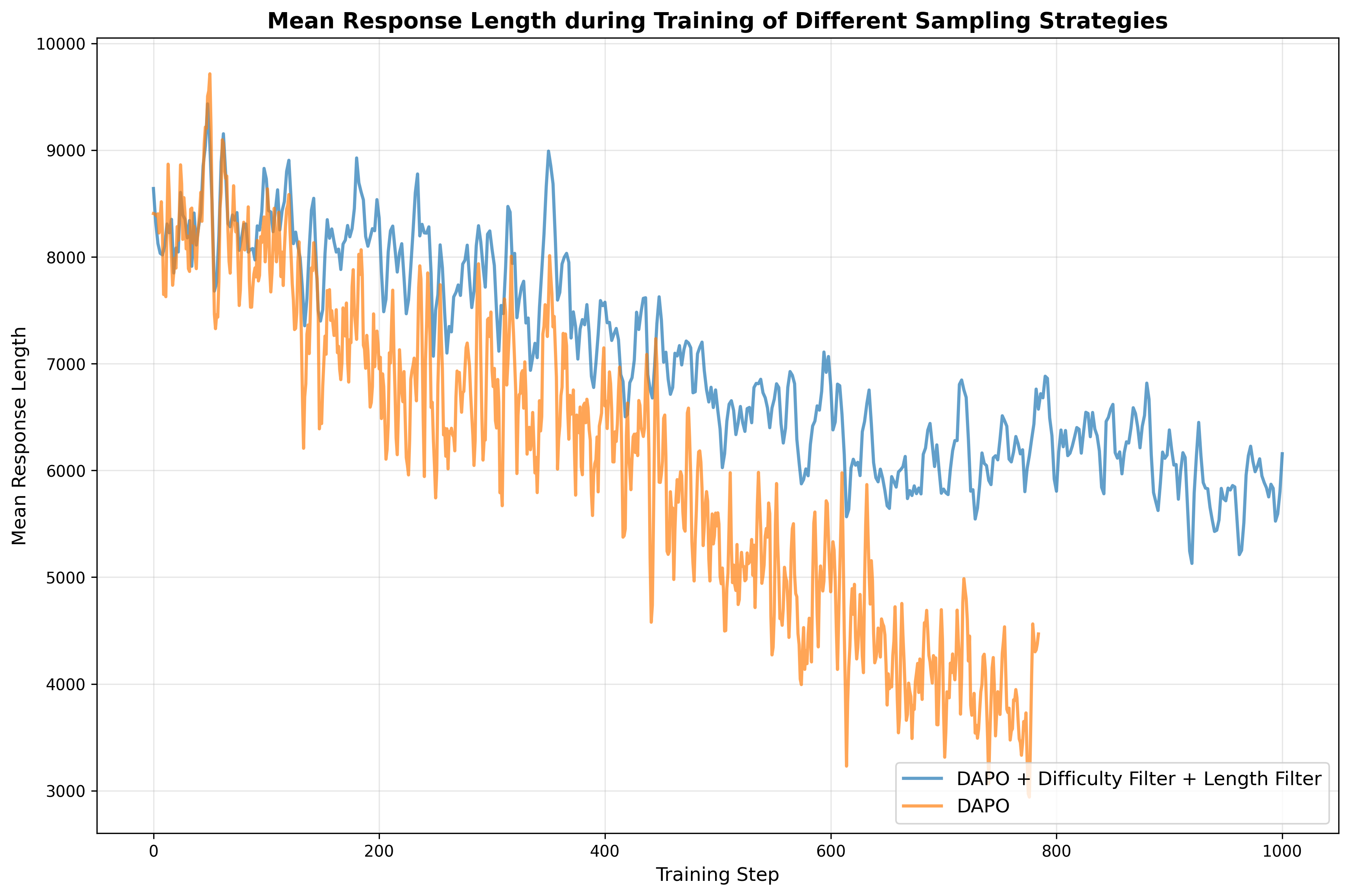
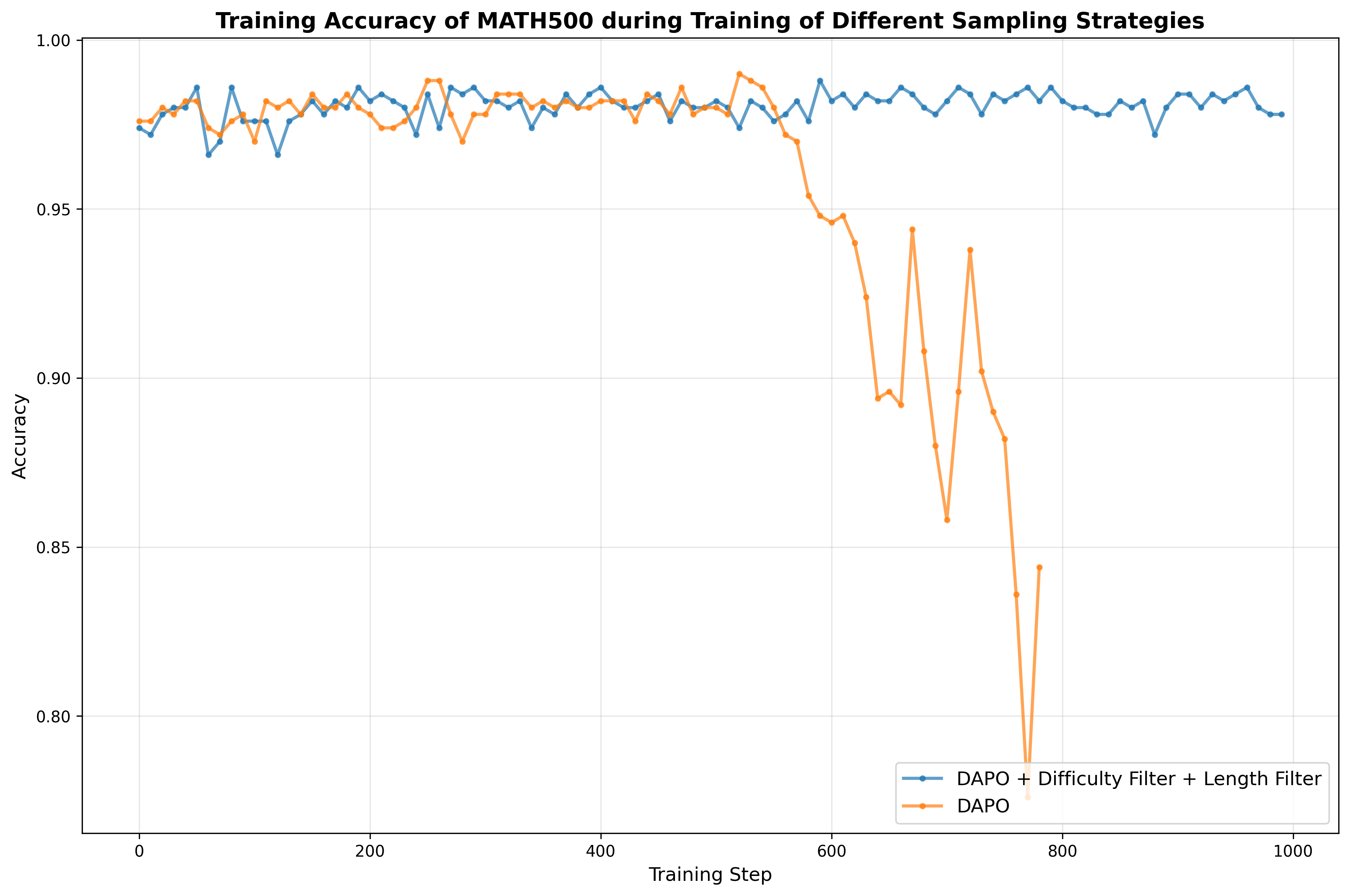
성능 평가에서는 8 B 파라미터 모델 기준으로 기존 최고 성능 모델 대비 평균 4.68 %의 향상을 기록했으며, 특히 복잡한 수학 증명, 물리 실험 설계, 공학 설계 문제 등 장기 추론이 요구되는 태스크에서 두드러진 개선을 보였다. 이는 단순히 파라미터 수를 늘리는 것이 아니라, 목표 도메인에 특화된 데이터와 실패‑보강 학습이 추론 능력에 미치는 영향을 실증적으로 보여준다.
또한 저자들은 모델과 데이터셋을 오픈소스로 공개한다는 점에서 커뮤니티에 큰 가치를 제공한다. 전체 7.2 M 중 5.3 M(공개 버전)과 1.6 M(다운샘플 버전)을 제공함으로써, 연구자들이 동일한 베이스라인 위에서 추가 실험을 수행하거나, 자체 도메인에 맞는 데이터 증강을 시도할 수 있다.
종합하면, Logics‑STEM은 (1) 고품질·다양성·확장성을 갖춘 대규모 STEM 사전학습 데이터, (2) 모델 실패 영역을 정밀하게 파악·보강하는 사후 학습 메커니즘, (3) 데이터와 알고리즘을 공동 설계함으로써 목표 추론 분포에 최적화된 학습 파이프라인이라는 세 축을 성공적으로 결합하였다. 이러한 접근은 향후 LLM이 전문 분야, 특히 복합적인 논리·수학·공학 문제를 다룰 때 필수적인 설계 원칙이 될 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리