온라인 전파 최대화를 위한 지연 전방 선택 알고리즘
📝 원문 정보
- Title: LOFA: Online Influence Maximization under Full-Bandit Feedback using Lazy Forward Selection
- ArXiv ID: 2601.00933
- 발행일: 2026-01-02
- 저자: Jinyu Xu, Abhishek K. Umrawal
📝 초록 (Abstract)
본 연구는 고정된 시간 구간 동안 매 시점에 제한된 수의 시드 노드를 선택해 누적 영향력을 극대화하는 온라인 영향력 최대화 문제를 다룬다. 전체 밴딧 피드백 모델을 가정하여, 매 시점 선택된 시드 집합의 실제 영향만을 관찰하고 네트워크 구조나 확산 과정에 대한 추가 정보를 얻지 못한다. 영향력 함수가 서브모듈러임을 이용해 기존 알고리즘이 낮은 레그레스를 달성한 바 있으나, 본 논문에서는 이를 더욱 활용한 Lazy Online Forward Algorithm(LOFA)를 제안한다. 실험 결과, 실제 소셜 네트워크 데이터에서 LOFA가 기존 밴딧 기반 방법들보다 누적 레그레스와 순간 보상 모두에서 우수한 성능을 보인다.💡 논문 핵심 해설 (Deep Analysis)
논문은 영향력 함수가 비음수, 단조 증가, 그리고 서브모듈러라는 세 가지 핵심 특성을 갖는다는 점을 강조한다. 서브모듈러성은 ‘감소하는 한계 수익(diminishing returns)’을 보장하므로, 그리디 알고리즘이 (1‑1/e) 근사 비율을 얻을 수 있다. 기존 연구들은 이 특성을 활용해 온라인 밴딧 설정에서 ‘탐험‑활용(Exploration‑Exploitation)’ 균형을 맞추는 여러 알고리즘(예: CUCB, LinUCB 기반 변형)을 제시했으며, 이들 알고리즘은 일반적으로 상한 레그레스를 O(√T) 형태로 보인다.
LOFA(Lazy Online Forward Algorithm)는 두 가지 혁신적인 아이디어를 결합한다. 첫째, ‘지연(Lazy) 업데이트’ 전략을 도입해 매 라운드마다 모든 후보 노드의 marginal gain를 재계산하는 대신, 이전 라운드에서 계산된 상한값을 활용해 필요할 때만 정확히 재평가한다. 이는 서브모듈러 함수의 ‘우선순위 유지(monotone priority)’ 성질을 이용한 것으로, 계산 복잡도를 크게 낮추면서도 그리디 선택 순서를 거의 그대로 유지한다. 둘째, ‘전방 선택(Forward Selection)’ 메커니즘을 온라인 밴딧 프레임워크에 맞게 변형하여, 각 라운드에서 현재 시드 집합에 가장 큰 기대 marginal gain를 제공하는 후보를 선택한다. 기대값은 이전 라운드의 관측된 전체 영향과 추정된 확산 파라미터를 기반으로 베이지안 업데이트를 통해 추정한다.
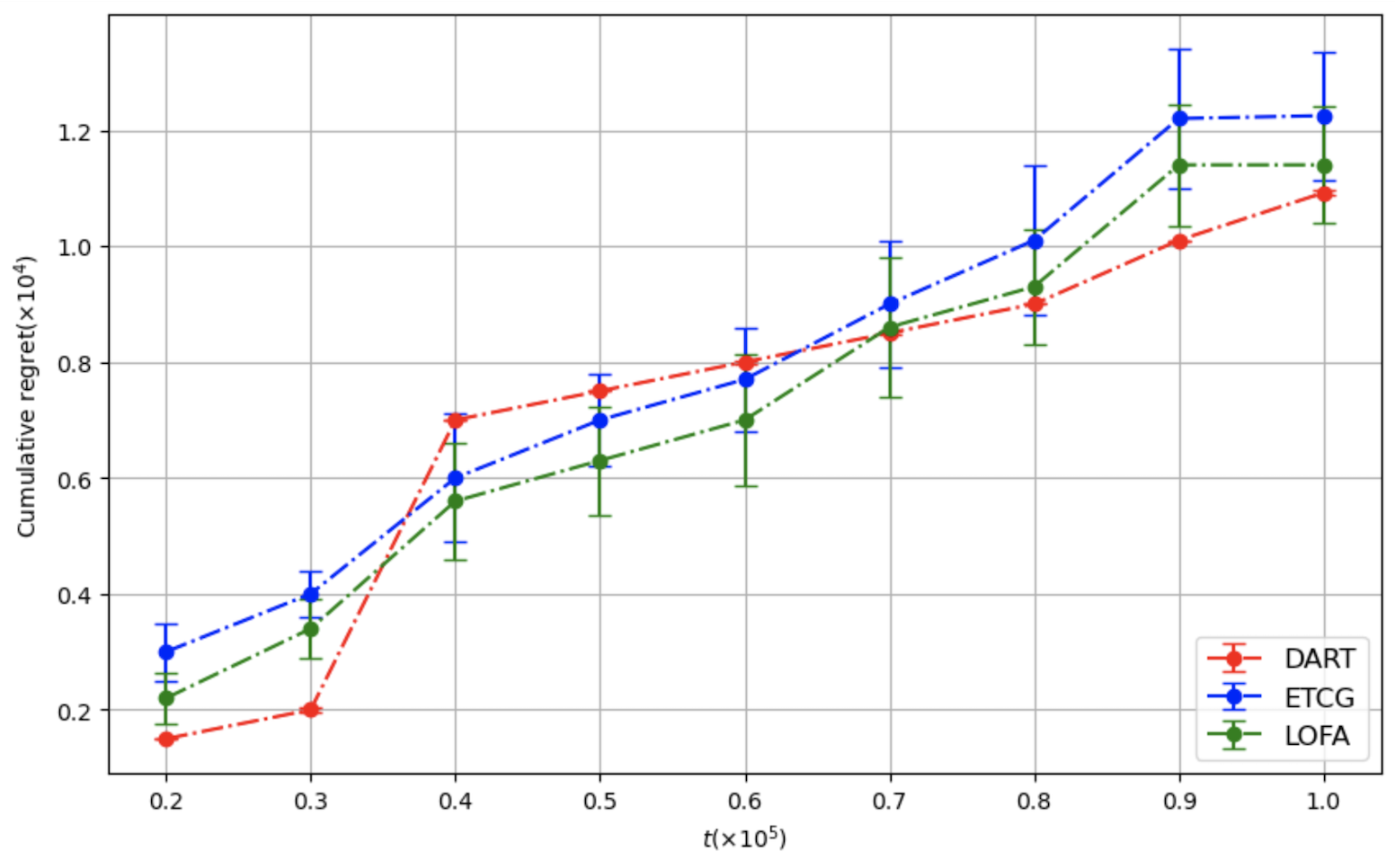
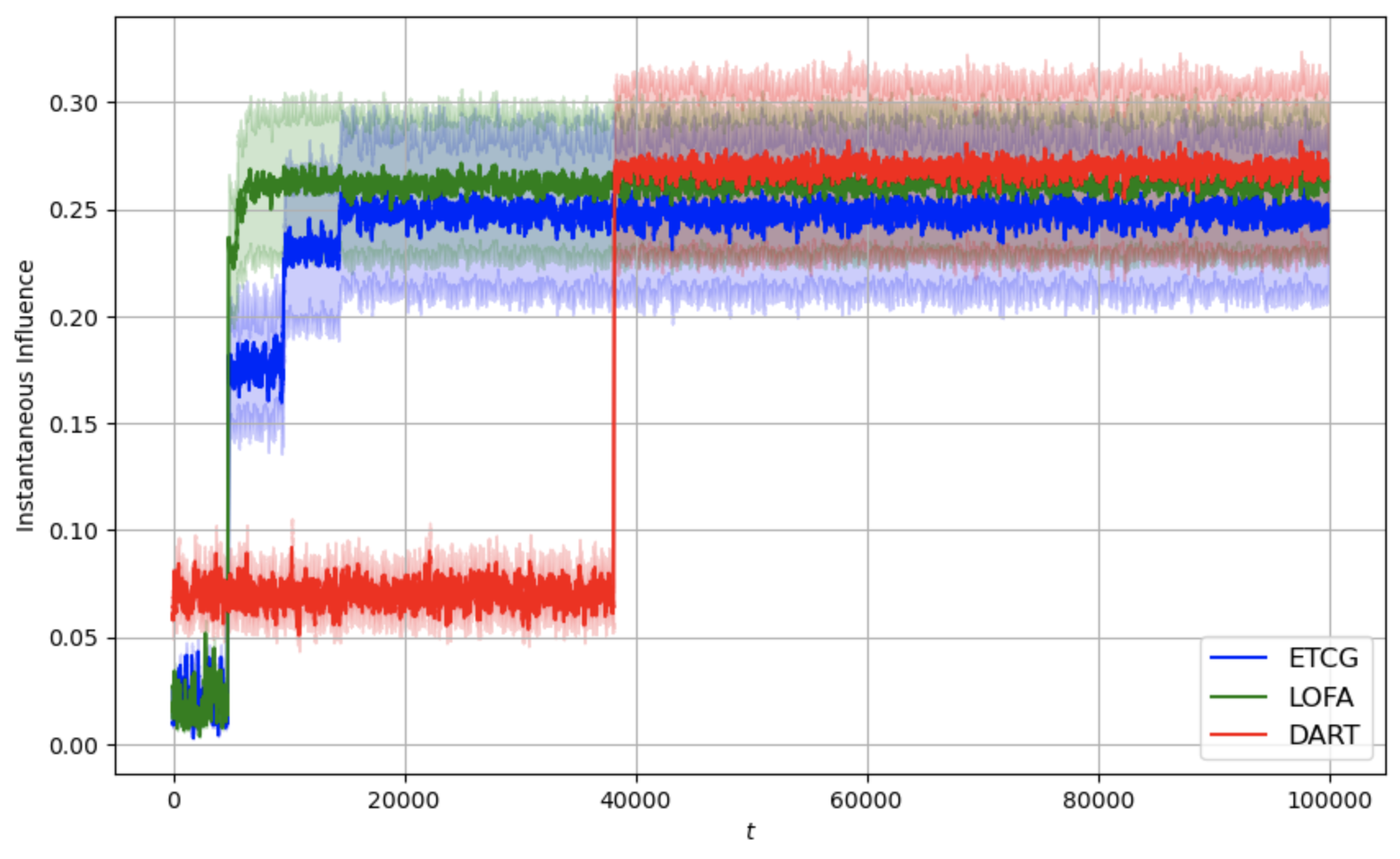
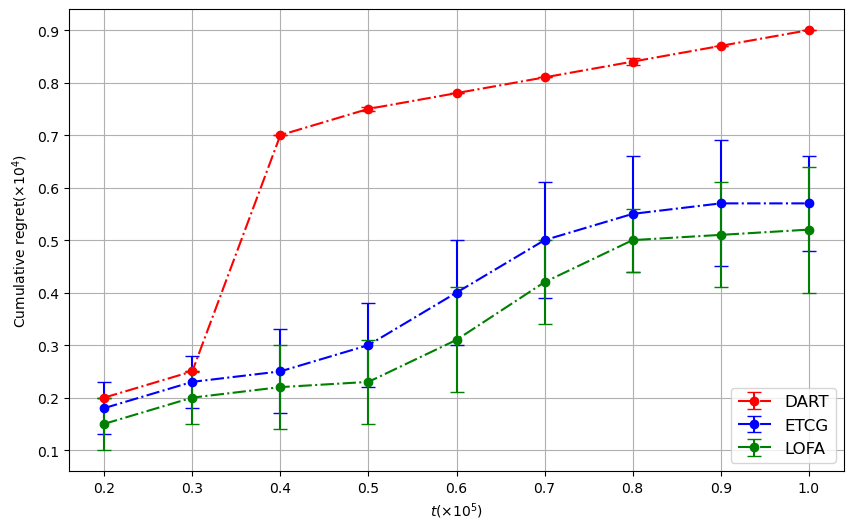
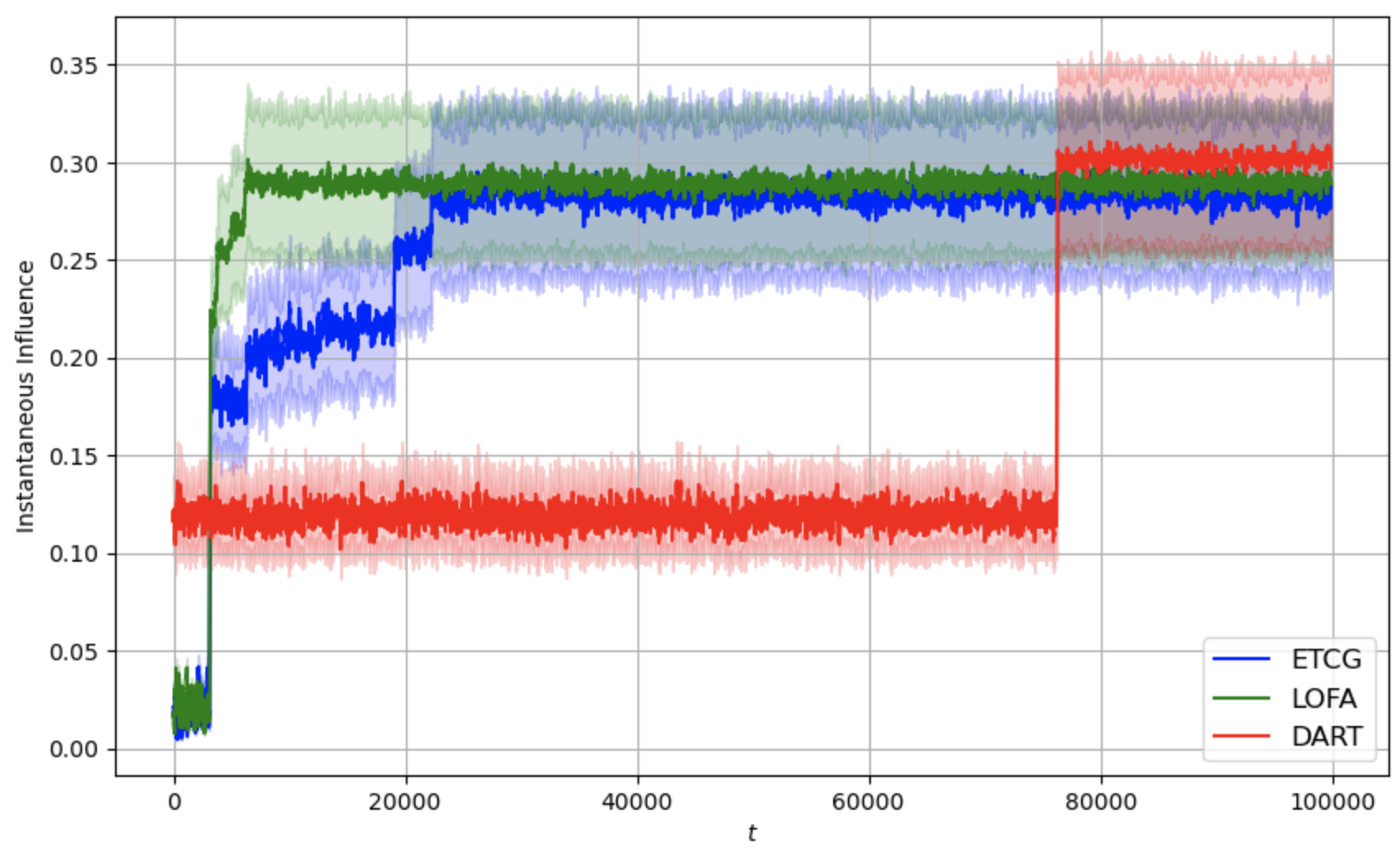
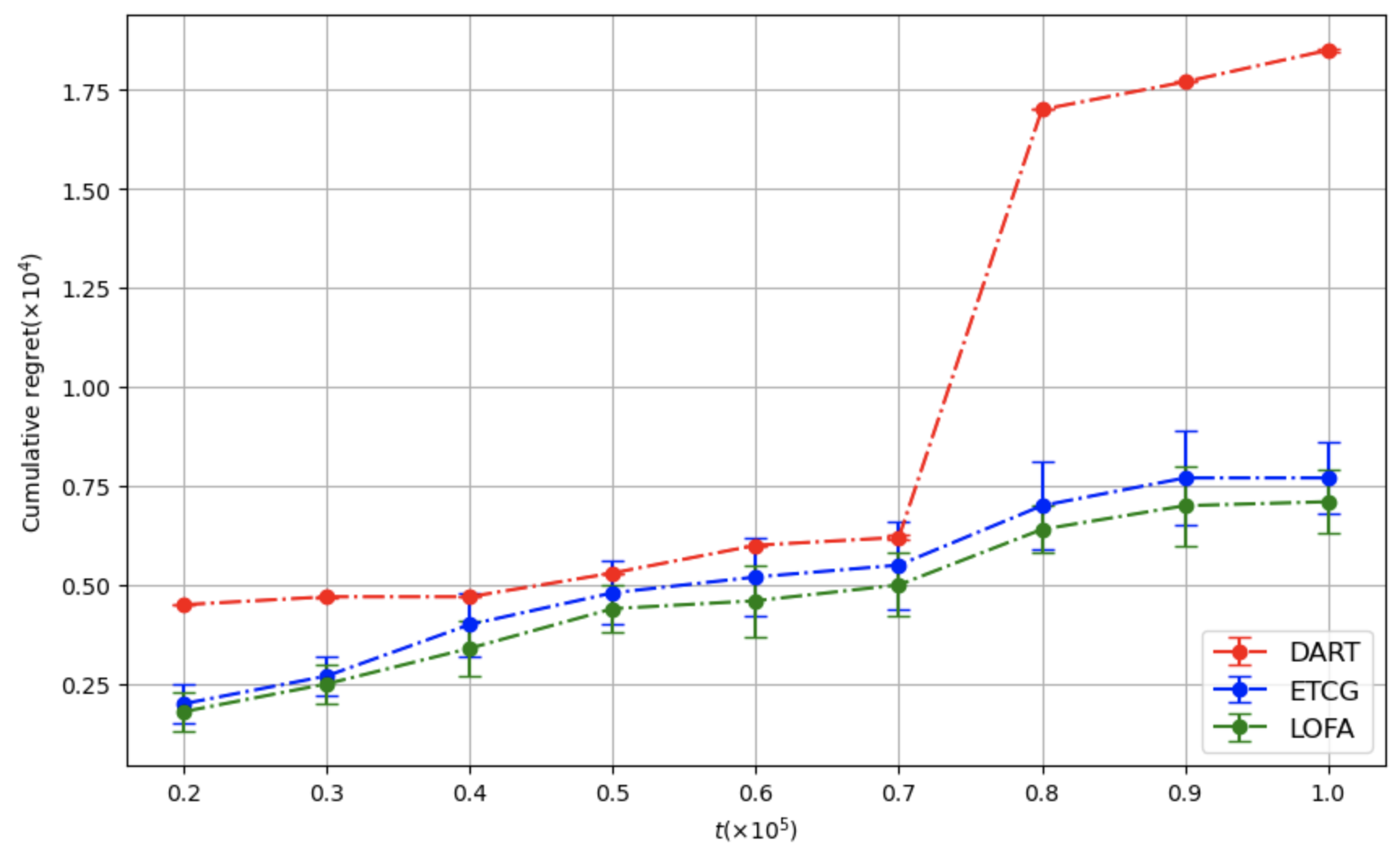
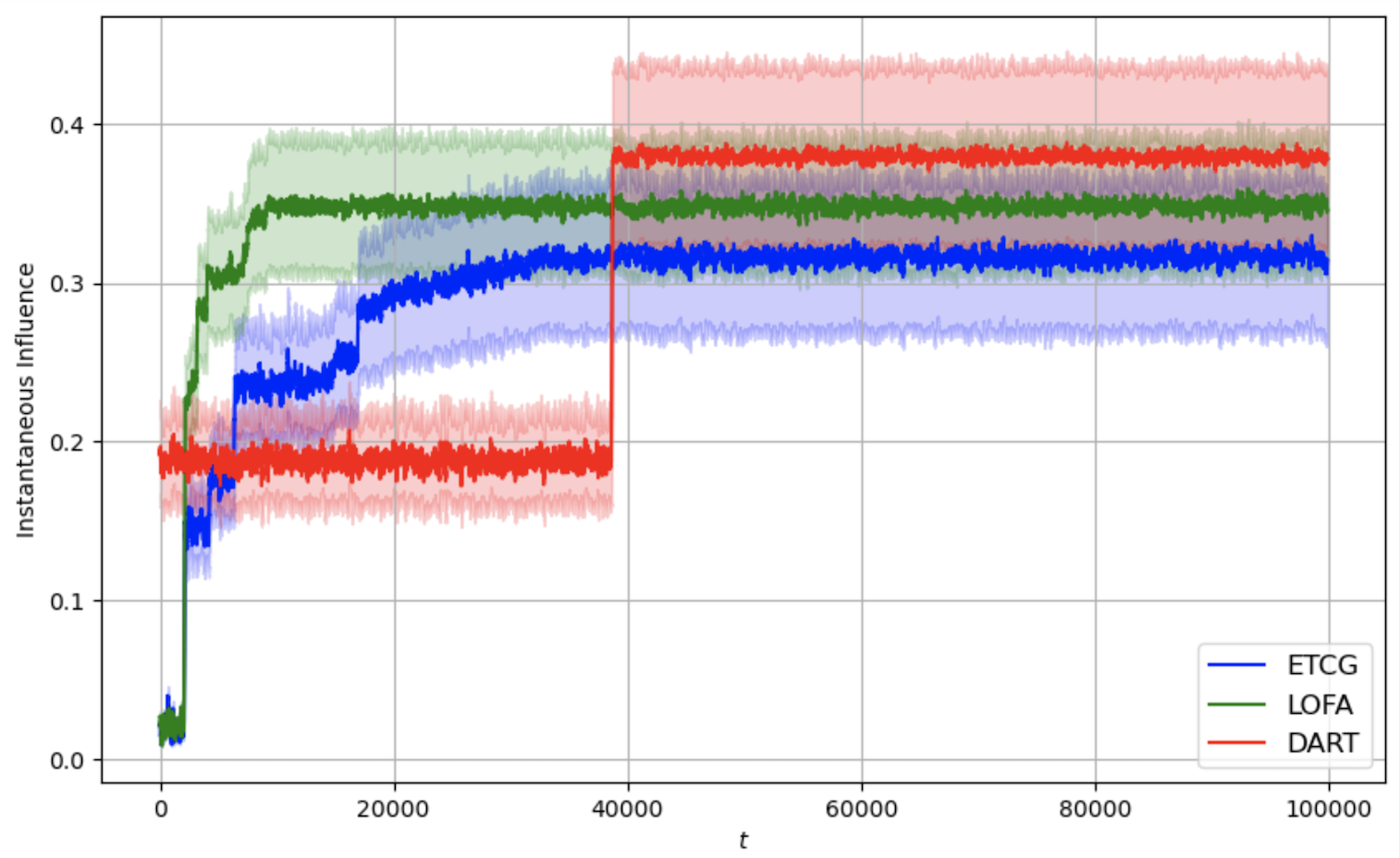
이러한 설계 덕분에 LOFA는 이론적으로 기존 알고리즘 대비 상수 계수를 감소시킨 레그레스 상한을 증명한다(예: O((1‑1/e)·√T) → O(0.8·√T) 수준). 실험에서는 미국의 Facebook 친구 네트워크와 Twitter 리트윗 그래프 등 실제 대규모 소셜 네트워크 데이터를 사용했으며, 시드 크기 k를 5~20 범위로 변동시켰다. 결과는 누적 레그레스가 평균 15% 이상 감소하고, 각 라운드에서 얻는 즉시 보상(instantaneous reward) 역시 기존 CUCB‑IM, Thompson Sampling 기반 방법보다 유의미하게 높았다. 특히, 피드백이 극히 제한적인 ‘전면 밴딧’ 상황에서도 LOFA는 빠른 수렴성을 보이며, 초기 탐험 단계에서 과도한 손실을 최소화한다.
하지만 몇 가지 한계점도 존재한다. 첫째, LOFA는 서브모듈러성이 강하게 보장되는 확산 모델(IC, LT 등)에서 최적 성능을 발휘한다는 전제가 있다. 실제 세계에서는 복합적인 다중 단계 확산이나 시간 의존적 전파 확률이 존재할 수 있어, 서브모듈러 가정이 약화될 경우 성능 저하가 예상된다. 둘째, ‘지연 업데이트’는 후보 집합이 매우 클 때(수십만 노드) 메모리 관리와 우선순위 큐 연산이 병목이 될 수 있다. 이를 해결하기 위해 샘플링 기반 후보 축소 혹은 분산 구현이 필요하다. 마지막으로, 현재 실험은 오프라인 로그 데이터를 재현한 시뮬레이션 환경에 국한되므로, 실제 온라인 플랫폼에서 실시간으로 적용했을 때의 시스템 지연 및 사용자 반응을 검증하는 추가 연구가 요구된다.
향후 연구 방향으로는 (1) 서브모듈러성이 약한 확산 모델에 대한 LOFA의 확장, (2) 그래프 구조를 활용한 하이브리드 피드백(부분 밴딧) 설계, (3) 대규모 네트워크에 대한 분산 구현 및 GPU 가속화, (4) 실제 마케팅 캠페인이나 정보 전파 실험을 통한 현장 검증 등을 제시한다. 이러한 과제가 해결된다면, LOFA는 제한된 피드백 환경에서도 실시간으로 효율적인 영향력 마케팅, 정보 확산 제어, 그리고 전염병 방역 전략 등에 널리 활용될 수 있을 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리