흐름을 타라 에이전트 제작과 록앤롤 그리고 오픈 에이전트 학습 생태계 내 ROME 모델 구축
📝 원문 정보
- Title: Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
- ArXiv ID: 2512.24873
- 발행일: 2025-12-31
- 저자: Weixun Wang, XiaoXiao Xu, Wanhe An, Fangwen Dai, Wei Gao, Yancheng He, Ju Huang, Qiang Ji, Hanqi Jin, Xiaoyang Li, Yang Li, Zhongwen Li, Shirong Lin, Jiashun Liu, Zenan Liu, Tao Luo, Dilxat Muhtar, Yuanbin Qu, Jiaqiang Shi, Qinghui Sun, Yingshui Tan, Hao Tang, Runze Wang, Yi Wang, Zhaoguo Wang, Yanan Wu, Shaopan Xiong, Binchen Xu, Xander Xu, Yuchi Xu, Qipeng Zhang, Xixia Zhang, Haizhou Zhao, Jie Zhao, Shuaibing Zhao, Baihui Zheng, Jianhui Zheng, Suhang Zheng, Yanni Zhu, Mengze Cai, Kerui Cao, Xitong Chen, Yue Dai, Lifan Du, Tao Feng, Tao He, Jin Hu, Yijie Hu, Ziyu Jiang, Cheng Li, Xiang Li, Jing Liang, Xin Lin, Chonghuan Liu, ZhenDong Liu, Zhiqiang Lv, Haodong Mi, Yanhu Mo, Junjia Ni, Shixin Pei, Jingyu Shen, XiaoShuai Song, Cecilia Wang, Chaofan Wang, Kangyu Wang, Pei Wang, Tao Wang, Wei Wang, Ke Xiao, Mingyu Xu, Tiange Xu, Nan Ya, Siran Yang, Jianan Ye, Yaxing Zang, Duo Zhang, Junbo Zhang, Boren Zheng, Wanxi Deng, Ling Pan, Lin Qu, Wenbo Su, Jiamang Wang, Wei Wang, Hu Wei, Minggang Wu, Cheng Yu, Bing Zhao, Zhicheng Zheng, Bo Zheng
📝 초록 (Abstract)
에이전트 제작은 단순 과제에 대한 일회성 응답 생성과 달리, 대형 언어 모델이 실제 환경에서 여러 차례의 행동‑관찰‑수정 과정을 반복하며 복합 요구를 충족시켜야 한다. 이러한 에이전트 제작은 코드에 국한되지 않고, 모델이 계획·실행·신뢰성을 유지해야 하는 도구·언어 기반 워크플로 전반으로 확장된다. 이를 위해서는 에이전트 생태계라는 기반이 필요하며, 최종적으로는 에이전트 모델 자체가 완성된다. 현재 오픈소스 커뮤니티는 이러한 종합 생태계가 부족해 실용적 개발과 상용화가 지연되고 있다. 본 논문은 에이전트 학습 생태계(ALE)를 제안한다. ALE는 가중치 최적화 프레임워크인 ROLL, 환경 관리·궤적 생성용 샌드박스인 ROCK, 그리고 환경과의 효율적 컨텍스트 엔지니어링을 제공하는 iFlow CLI 로 구성된다. 우리는 ALE 위에 구축된 오픈소스 에이전트 ROME(ROME is Obviously an Agentic ModEl)을 공개하고, 100만 이상의 궤적을 사용해 학습하였다. 또한 정적 스니펫부터 동적 복합 행동까지를 포괄하는 데이터 합성 프로토콜과 안전·보안·유효성 검증을 포함한다. 새로운 정책 최적화 알고리즘 IPA는 토큰이 아닌 의미적 상호작용 청크에 크레딧을 할당해 장기 시계열 학습의 안정성을 높인다. 실험 결과 ROME는 Terminal‑Bench 2.0에서 24.72 %, SWE‑bench Verified에서 57.40 % 정확도를 기록해 동등 규모 모델을 앞서고 100 B 파라미터 모델에 근접한다. 또한 평가용으로 규모·도메인·오염 제어가 강화된 Terminal Bench Pro를 소개한다. ROME은 유사 규모 오픈소스 모델 중 경쟁력을 유지하며 실제 서비스에 적용돼 ALE의 실효성을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
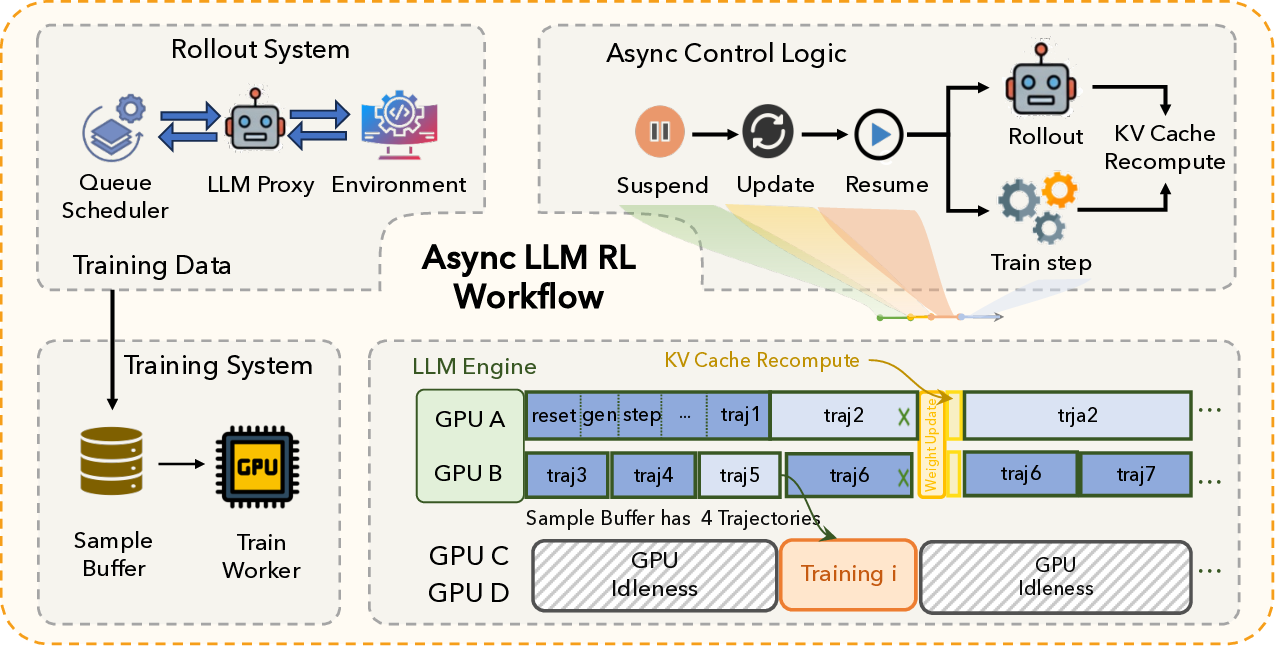
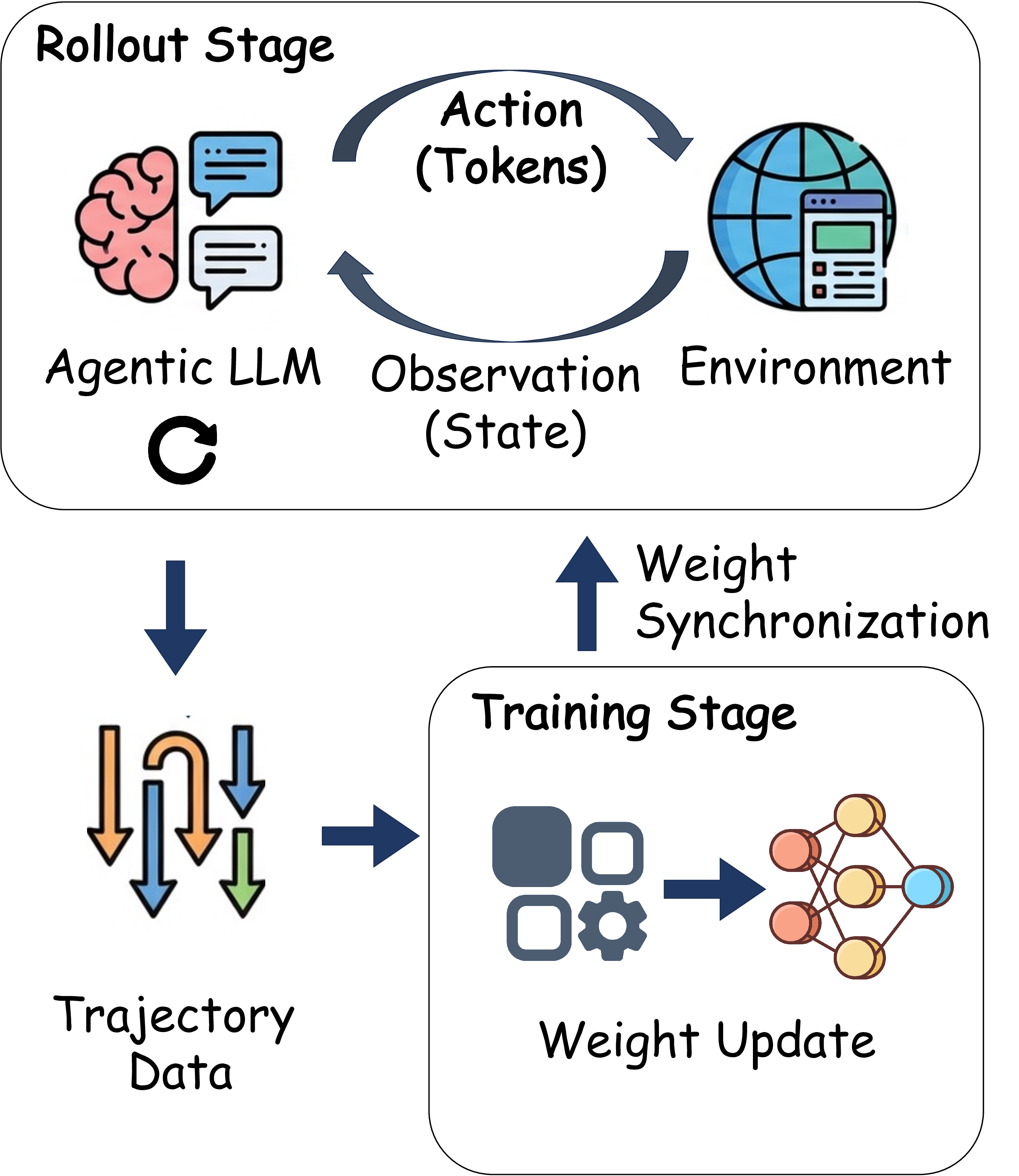
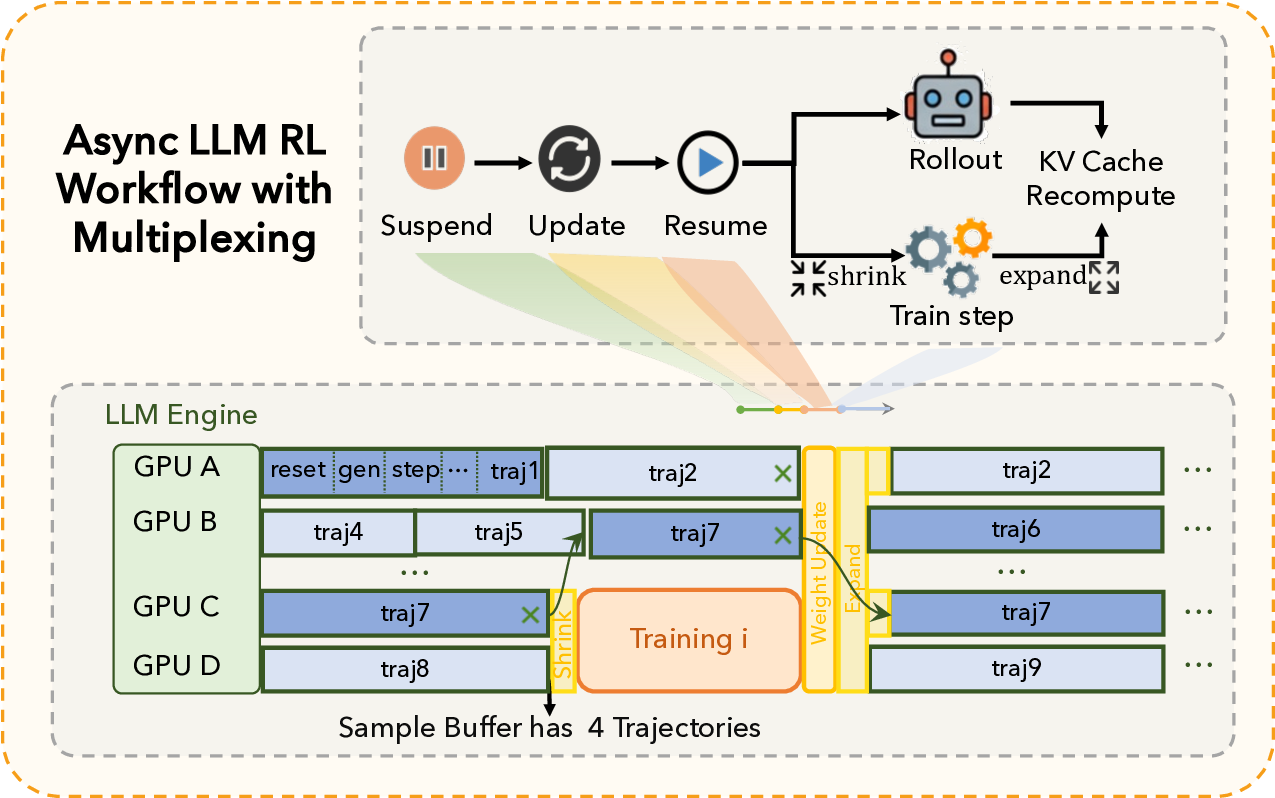
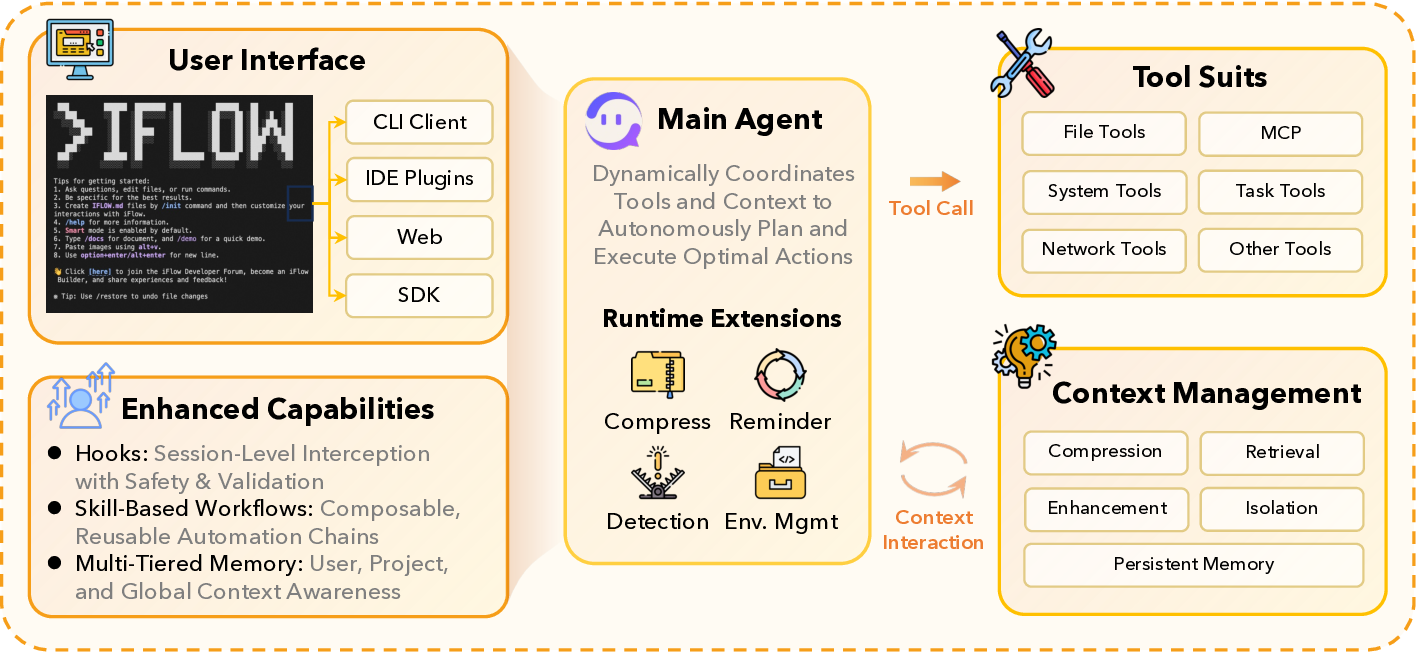
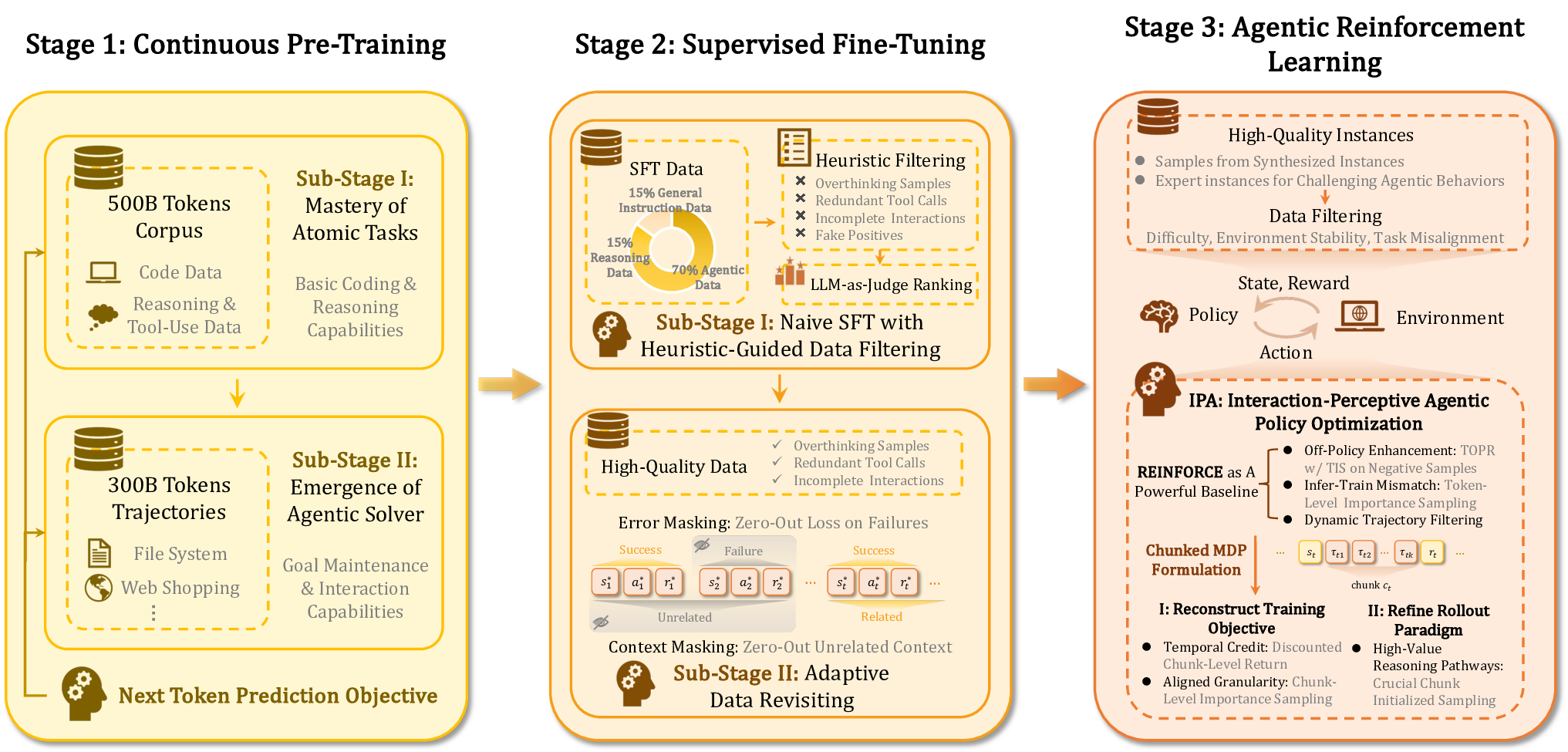
ALE는 세 가지 핵심 모듈로 구성된다. 첫째, ROLL은 사후 학습 단계에서 가중치를 미세조정하는 프레임워크로, 기존 파인튜닝 방식보다 효율적인 파라미터 업데이트를 제공한다. 둘째, ROCK은 샌드박스형 환경 관리자로, 다양한 시뮬레이션 환경을 자동으로 배포·제어하고, 에이전트가 생성한 행동 궤적을 대규모로 수집한다. 셋째, iFlow CLI는 에이전트와 환경 간 인터페이스를 표준화하고, 컨텍스트 엔지니어링을 모듈화함으로써 복잡한 프롬프트 설계와 상태 관리 비용을 크게 낮춘다.
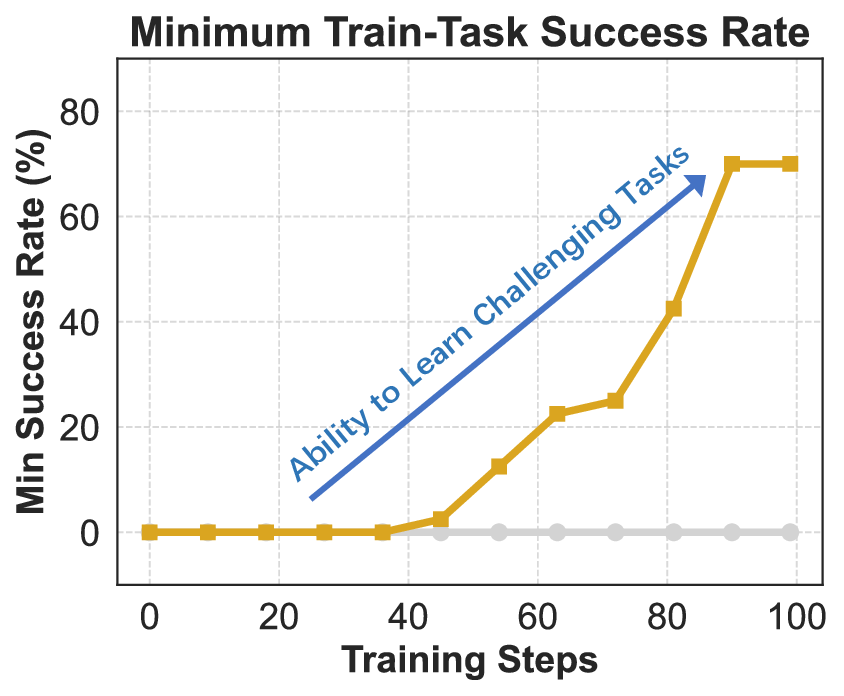
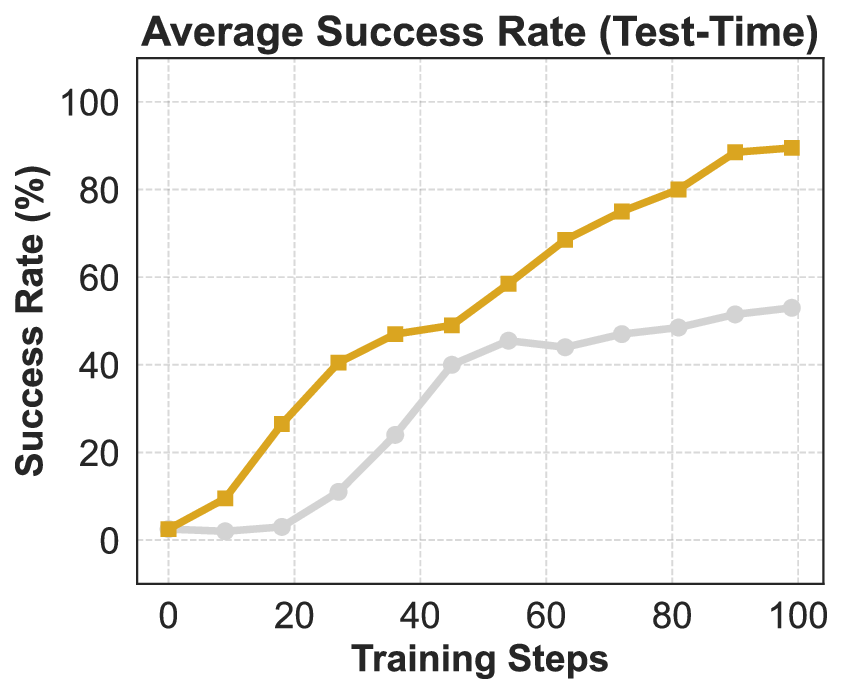
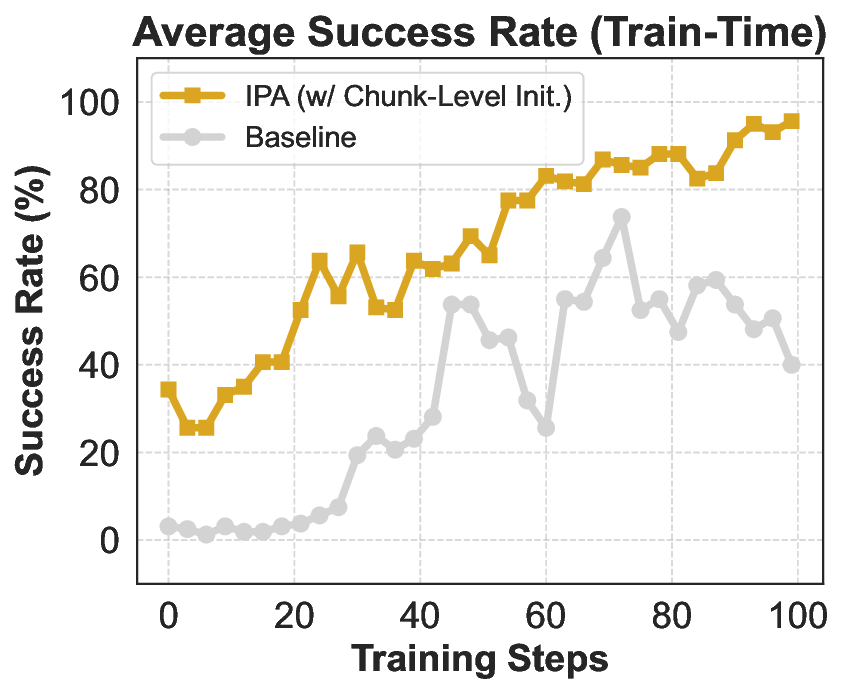
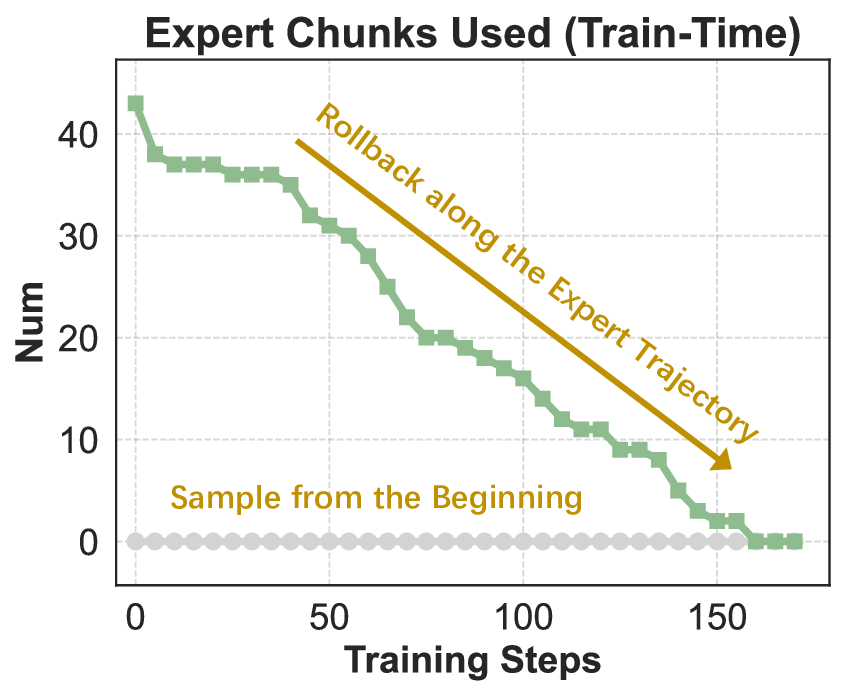
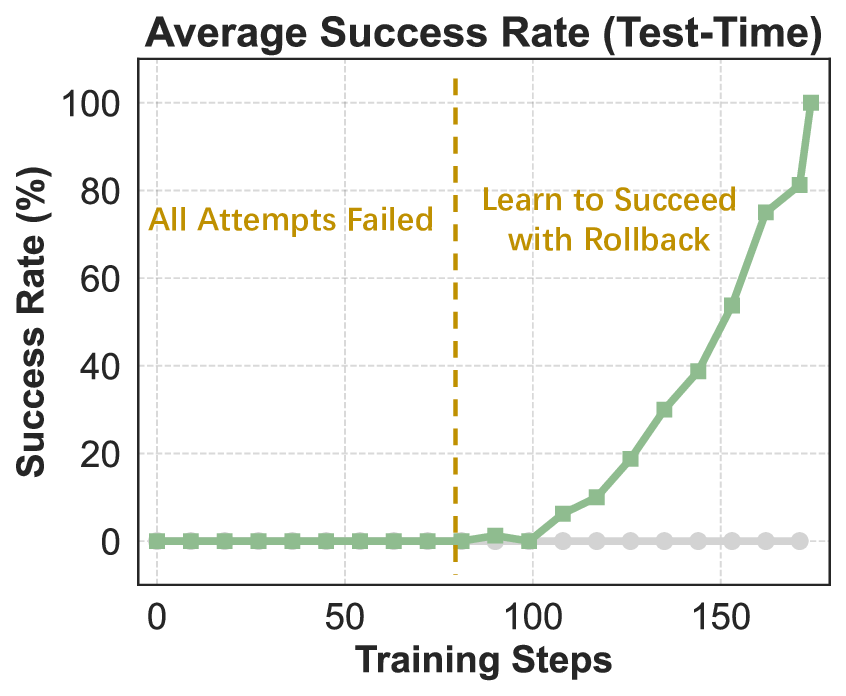
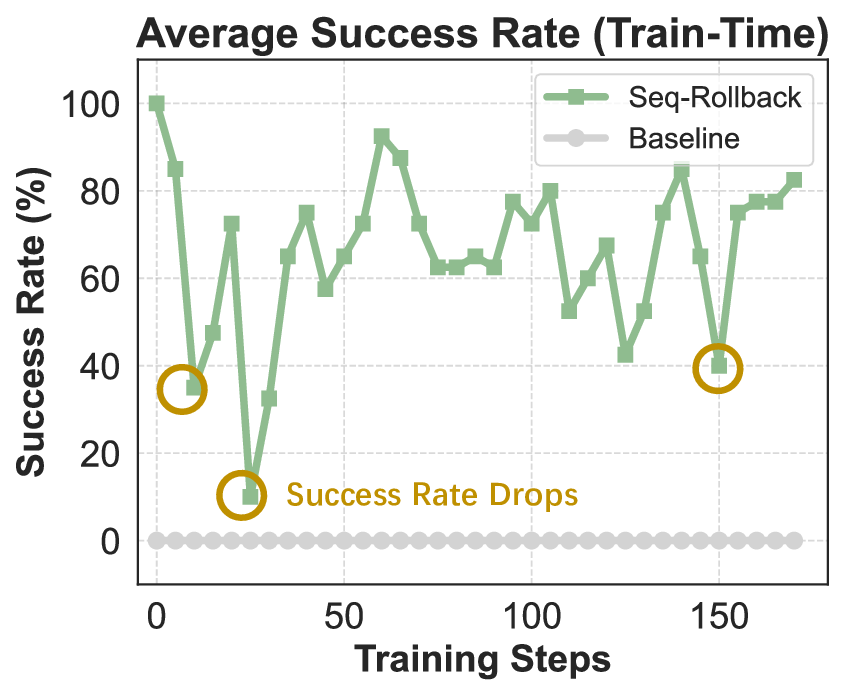
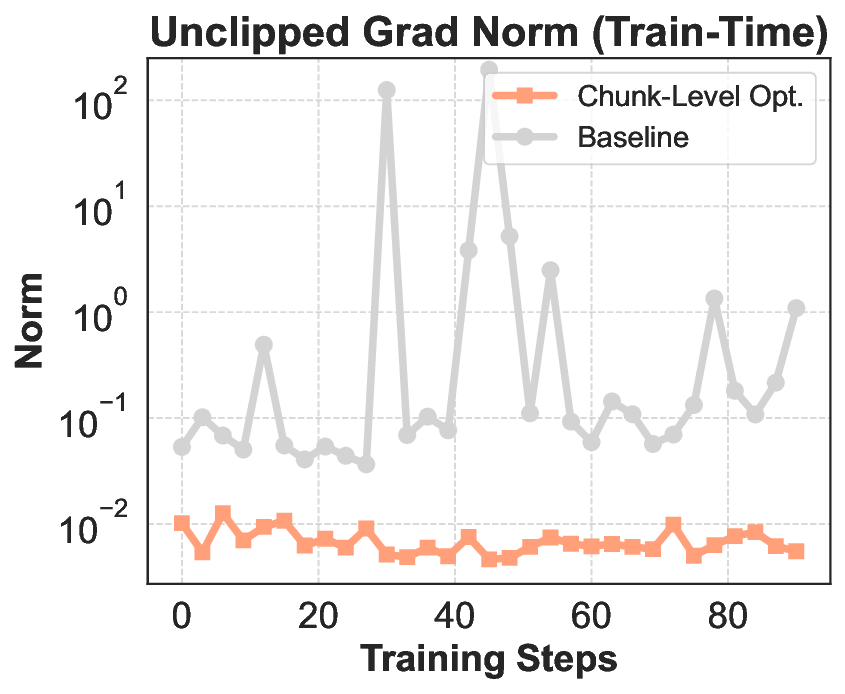
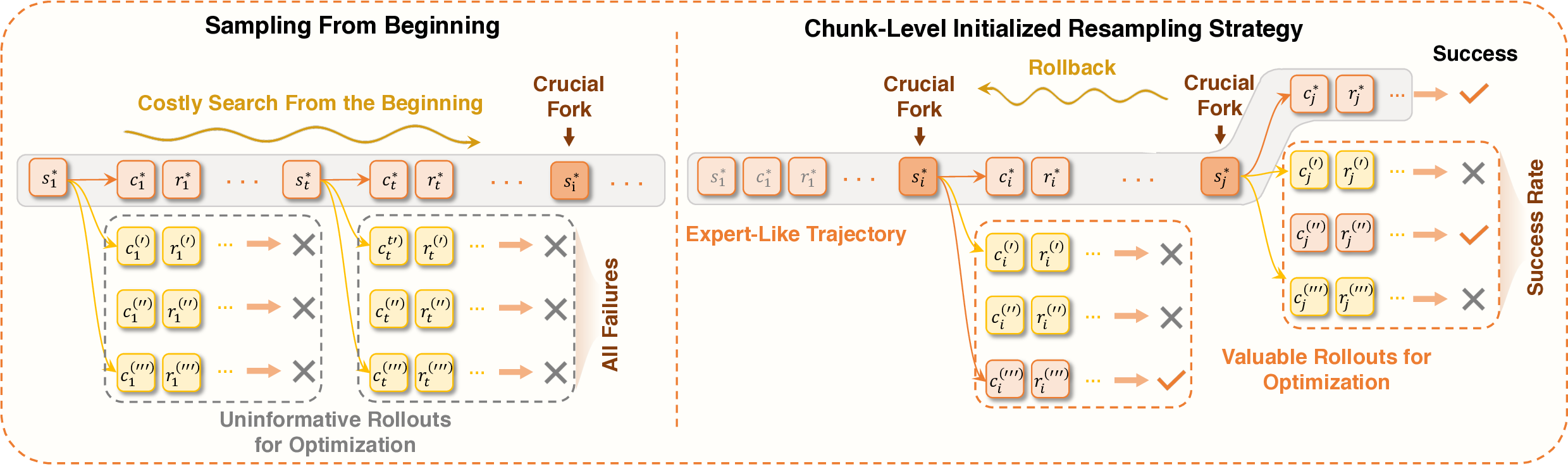
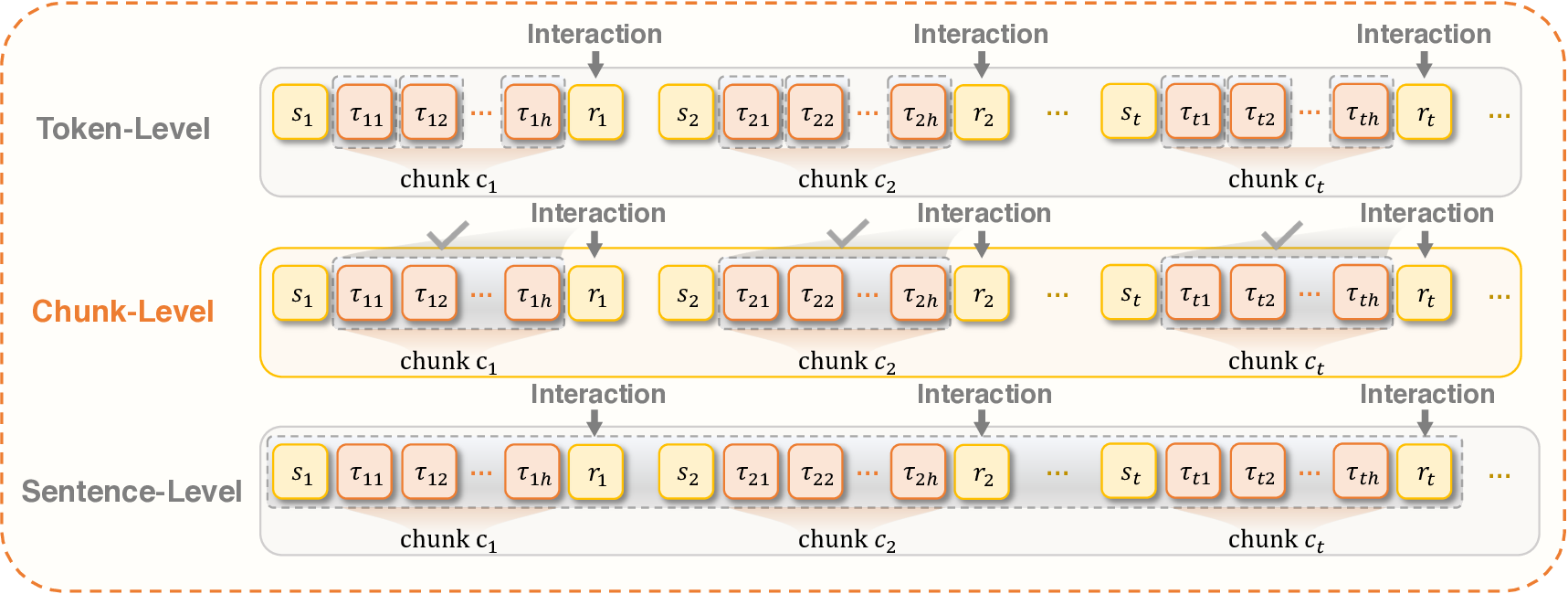
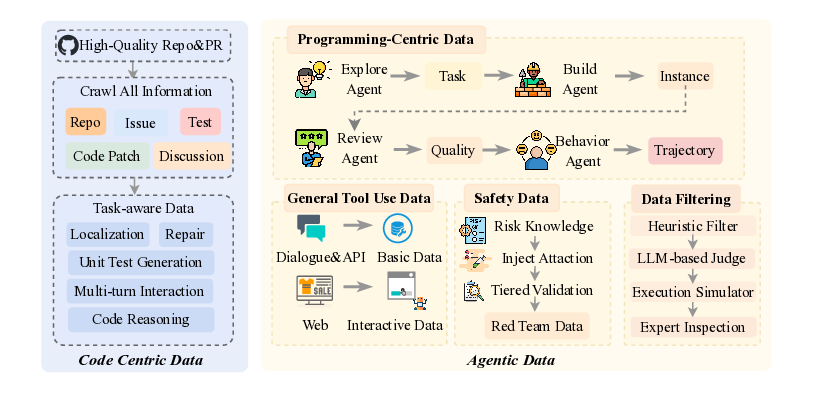
이 기반 위에 구축된 ROME은 1 백만 이상의 행동 궤적을 학습 데이터로 활용한다. 데이터 구성 프로토콜은 정적 코드 스니펫부터 동적 멀티스텝 시나리오까지 포괄하며, 각 샘플에 대해 안전·보안·유효성 검증을 자동화한다. 특히 새로운 정책 최적화 알고리즘 IPA는 토큰 단위가 아니라 의미적 상호작용 청크(예: “파일 열기 → 내용 읽기 → 결과 저장”)에 보상을 할당함으로써 장기 의존성 문제를 완화하고 학습 안정성을 크게 향상시킨다.
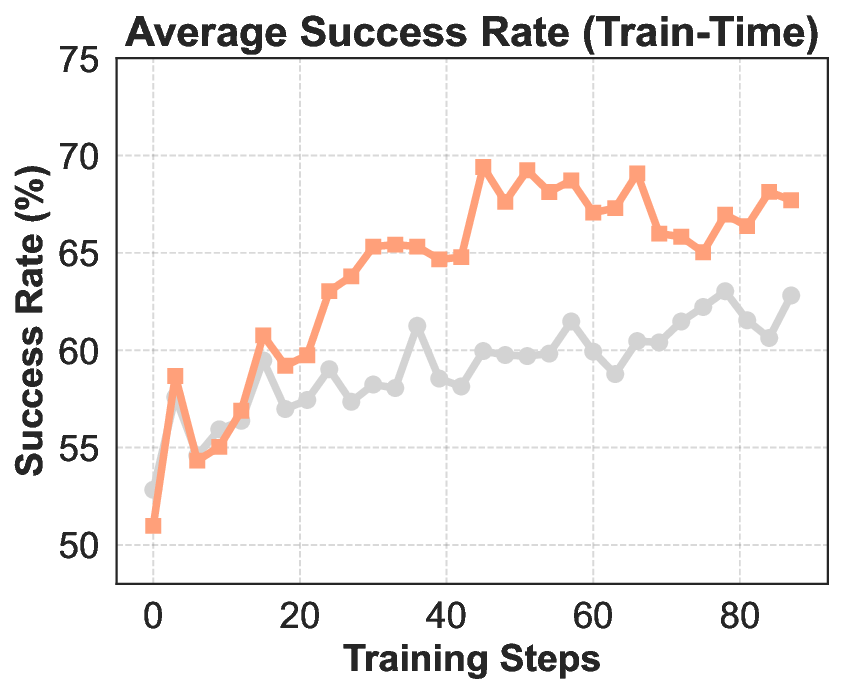
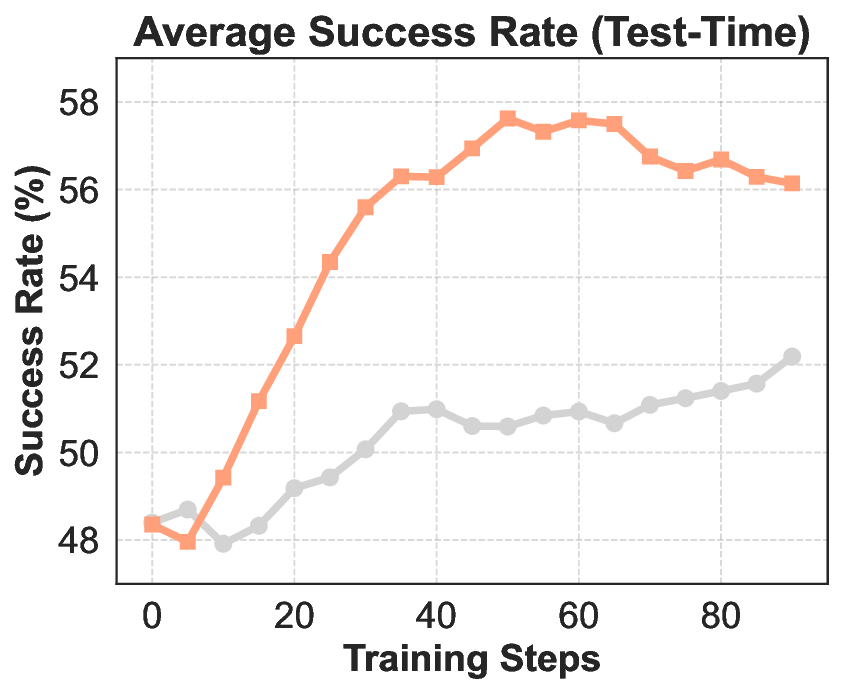
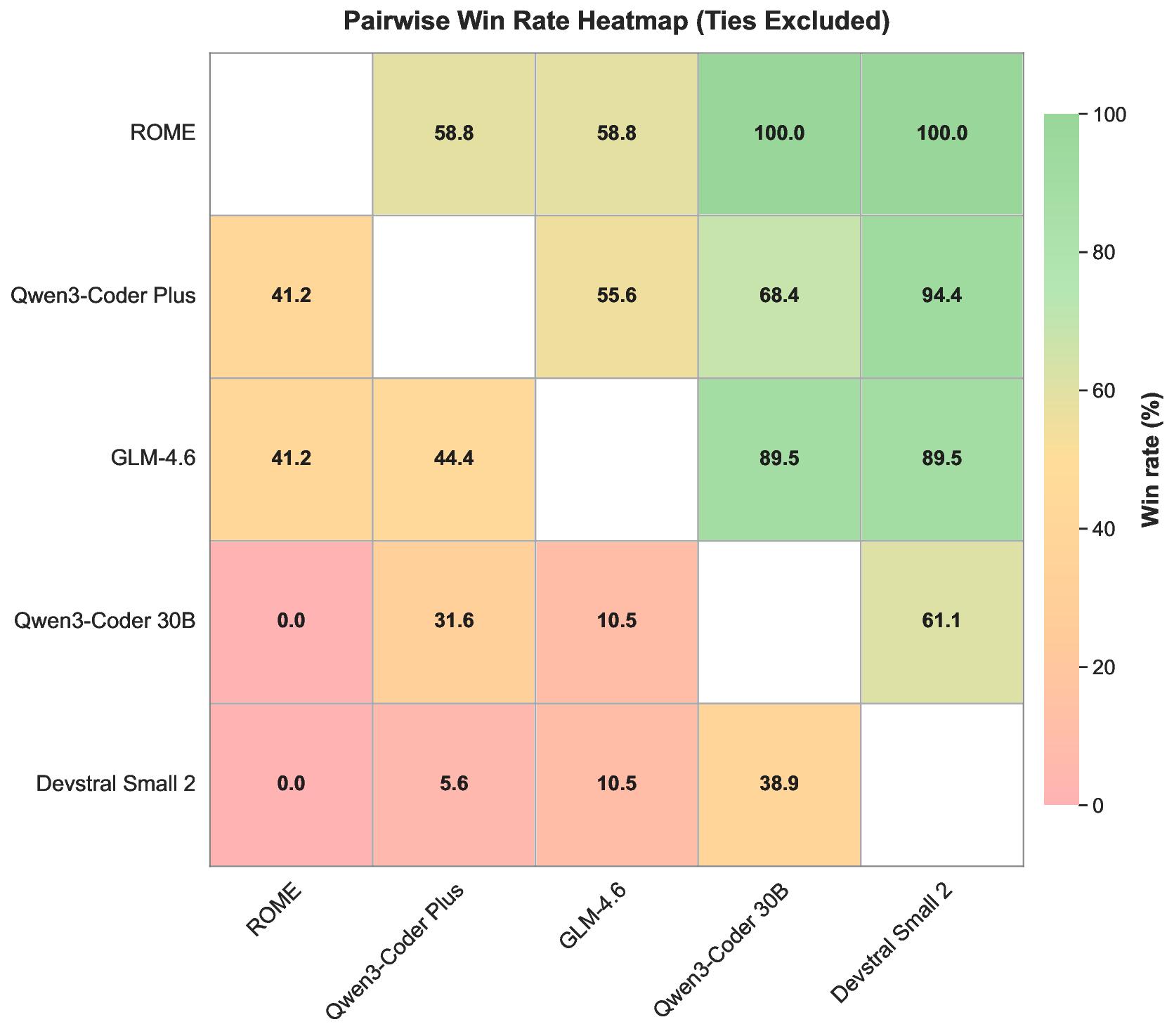
실험에서는 ROME이 기존 오픈소스 에이전트 모델들을 능가하는 성과를 보였다. Terminal‑Bench 2.0에서 24.72 %라는 점수는 동일 규모 모델 평균을 8 %p 이상 앞선 것이며, SWE‑bench Verified에서는 57.40 % 정확도로 100 B 파라미터급 상용 모델에 근접한다. 또한 논문은 평가 편향을 최소화하고 도메인 다양성을 확대한 Terminal Bench Pro를 제시해, 향후 에이전트 성능 비교에 보다 신뢰할 수 있는 기준을 제공한다.
전반적으로 이 연구는 ‘에이전트 제작’이라는 새로운 패러다임을 실현하기 위한 인프라‑데이터‑알고리즘 삼위일체 접근법을 제시한다는 점에서 의의가 크다. ALE라는 오픈소스 생태계를 공개함으로써 연구자와 기업이 자체 에이전트를 빠르게 구축·실험·배포할 수 있는 기반을 마련했으며, ROME의 실서비스 적용 사례는 이 접근법이 이론을 넘어 실제 산업 현장에서도 유효함을 입증한다. 앞으로는 ALE의 확장성을 바탕으로 멀티모달 환경, 인간‑에이전트 협업, 그리고 지속적인 안전 검증 메커니즘을 추가하는 연구가 진행될 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리