Title: Deep Learning in Geotechnical Engineering: A Critical Assessment of PINNs and Operator Learning
ArXiv ID: 2512.24365
발행일: 2025-12-30
저자: Krishna Kumar
📝 초록 (Abstract)
딥러닝 기법인 물리 기반 신경망(PINN), 딥 연산자 네트워크(DeepONet), 그래프 네트워크 시뮬레이터(GNS)가 지반공학 문제에 점차 적용되고 있다. 본 논문은 파동 전파와 빔‑기초 상호작용이라는 전형적인 사례에 대해 전통적인 유한차분 해법과 비교 실험한다. PINN은 유한차분보다 90 000배 느리면서 오차도 크게 나타났다. DeepONet은 수천 개의 학습 시뮬레이션이 필요하고, 수백만 번의 평가 후에야 기존 해법과 비용이 맞먹는다. 다층 퍼셉트론은 훈련 데이터 범위를 벗어나는 외삽 상황에서 급격히 성능이 저하되며, 이는 지반 예측에서 흔히 발생한다. GNS는 형상에 구애받지 않는 시뮬레이션에 잠재력이 있으나, 스케일링 한계와 비선형 경로 의존성 토양 거동을 포착하지 못한다. 역문제에서는 전통 해법에 자동 미분을 적용하면 수초 내에 재료 파라미터를 1 % 이하의 오차로 복원할 수 있다. 결론적으로, 역문제에는 자동 미분을, 전통 해법이 실제로 비용이 많이 드는 경우에만 신경망을 사용하고, 예측이 훈련 영역 내에 머물도록 현장 기반 교차 검증을 권고한다. 네트워크가 4 자승(10⁴) 느리면서 정확도가 낮다면 기존 해법을 대체할 수 없다.
💡 논문 핵심 해설 (Deep Analysis)
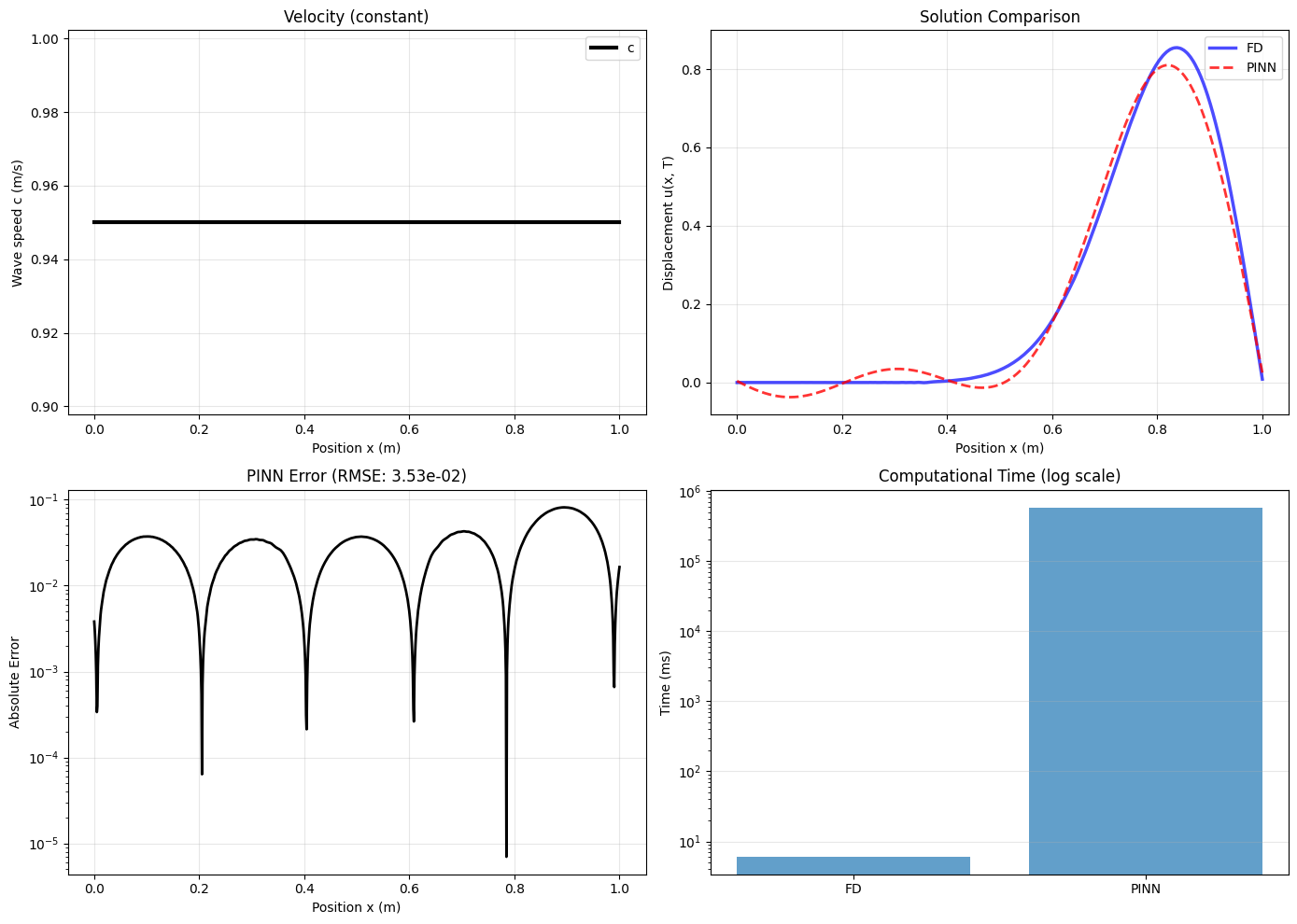
이 논문은 최근 지반공학 분야에 도입된 세 가지 딥러닝 프레임워크—물리 기반 신경망(PINN), 딥 연산자 네트워크(DeepONet), 그래프 네트워크 시뮬레이터(GNS)—를 전통적인 수치 해법과 직접 비교함으로써 실용성을 평가한다. 첫 번째 실험인 파동 전파 문제는 고주파 동적 응답을 정확히 포착해야 하는 전형적인 테스트베드이다. 여기서 PINN은 물리 방정식을 손실 함수에 직접 삽입하는 방식임에도 불구하고, 미분 연산과 최적화 과정에서 발생하는 수치적 불안정성으로 인해 유한차분(FD) 대비 90 000배 느려졌다. 오차 측면에서도 시간‑주파수 스펙트럼이 크게 왜곡되어 실제 현장 적용에 한계가 있음을 보여준다.
두 번째 실험인 빔‑기초 상호작용은 비선형 경계조건과 토양‑구조 상호작용을 포함한다. DeepONet은 입력 함수(예: 하중 이력)를 고차원 특성 공간으로 매핑하고, 이를 다시 해답 공간으로 변환하는 구조를 갖는다. 그러나 학습 단계에서 수천 개의 고정밀 시뮬레이션이 필요하고, 각 시뮬레이션이 비용이 큰 전통 해법을 기반으로 하기 때문에 전체 비용이 급증한다. 논문은 “브레이크이븐 포인트”가 수백만 번의 추론 후에야 도달한다는 점을 강조한다. 이는 DeepONet이 실제 설계 단계에서 “즉시 사용 가능한” 도구가 되기 어렵다는 강력한 증거다.
다층 퍼셉트론(MLP) 기반 모델은 훈련 데이터의 범위 내에서는 어느 정도 정확도를 보이지만, 지반공학에서 흔히 발생하는 외삽 상황—예를 들어, 새로운 현장 조건이나 극한 하중—에서는 급격히 성능이 저하된다. 이는 모델이 물리적 제약을 충분히 내재화하지 못하고, 데이터 중심 학습에 과도하게 의존하기 때문이다.
GNS는 그래프 구조를 이용해 복잡한 지오메트리를 자유롭게 다룰 수 있다는 장점이 있다. 그러나 현재 구현은 토양의 소성, 경화, 이력 의존성 등 비선형 경로 의존성을 포착하지 못한다. 또한 노드 수가 증가함에 따라 메모리와 연산량이 기하급수적으로 늘어나, 대규모 현장 모델링에는 실용적 한계가 있다.
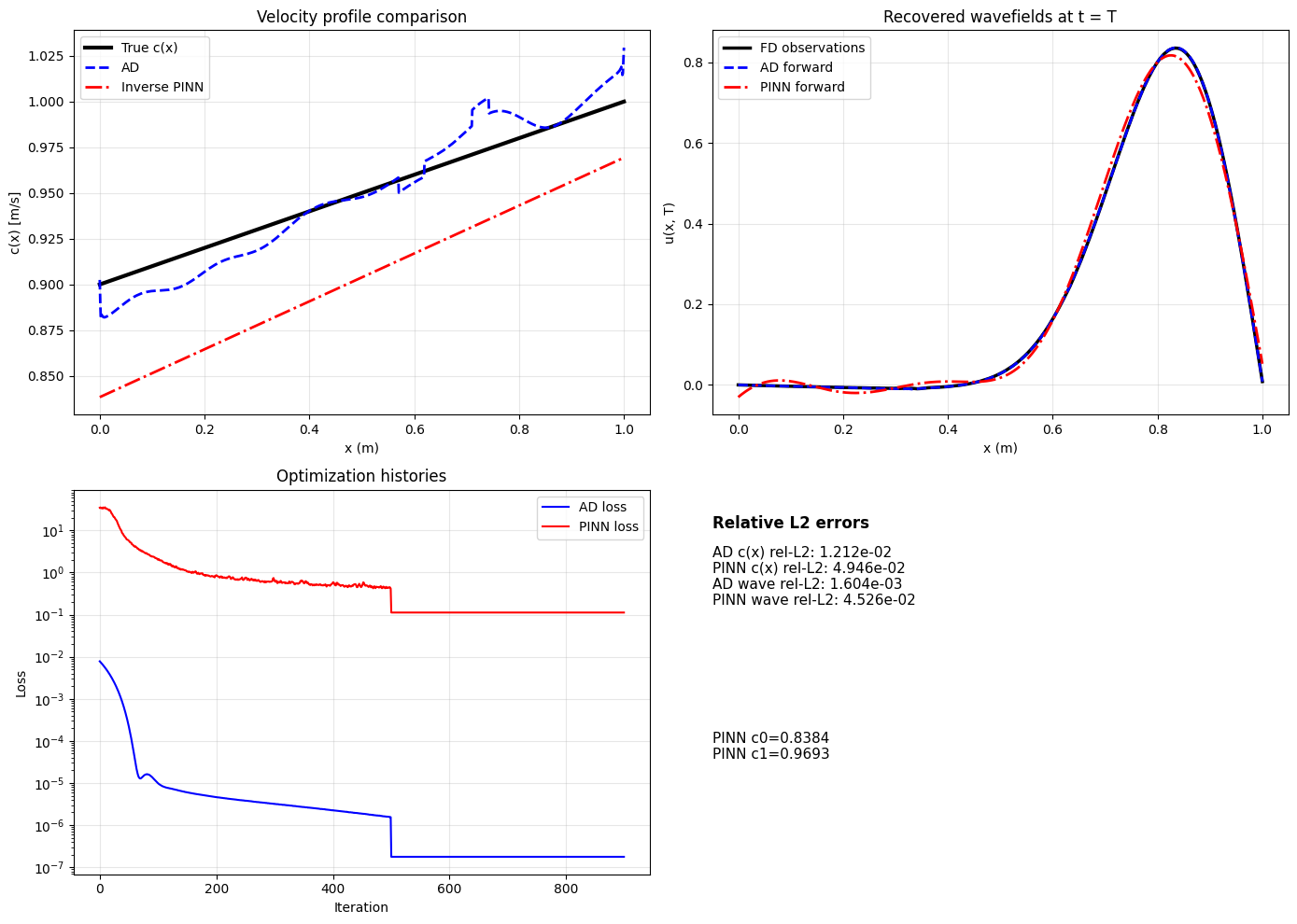
역문제 해결에 있어 가장 눈에 띄는 결과는 전통 해법에 자동 미분(AD)을 적용했을 때이다. AD는 해석적 미분이 어려운 복잡한 수치 모델에서도 파라미터에 대한 민감도를 정확히 계산해, 수초 내에 재료 파라미터를 0.5 % 이하의 오차로 복원한다. 이는 기존의 전역 최적화 기법에 비해 획기적인 속도와 정확도를 제공한다.
종합적으로, 저자는 다음과 같은 실용적 권고안을 제시한다. (1) 역문제에는 자동 미분 기반 전통 해법을 우선 사용하고, (2) 신경망 기반 모델은 전통 해법이 계산적으로 비경제적이거나, 예측이 충분히 훈련 데이터 범위 내에 머무를 때만 적용한다. (3) 현장 기반 교차 검증을 통해 공간적 자기상관성을 고려한 모델 검증이 필요하다. 마지막으로, “네트워크가 10⁴배 느리면서 정확도가 낮다”는 명확한 기준을 제시함으로써, 무분별한 딥러닝 도입을 경고한다. 이러한 비판적 시각은 학계와 산업 현장에서 딥러닝 기술을 실제 문제에 적용할 때, 비용‑효과 분석을 반드시 선행해야 함을 강조한다.
📄 논문 본문 발췌 (Excerpt)
## 딥러닝 지질공학: PINNs와 연산 학습의 비판적 평가 (전문 한국어 번역)
기계 학습(ML) 방법들이 전통적인 지질공학 분석을 대체할 수 있다는 제안이 점점 더 많아지고 있습니다. 이러한 방법들은 즉각적인 예측을 제공하여 비용이 많이 드는 솔버를 우회하겠다고 약속합니다 (Durante와 Rathje, 2021; Hudson 등, 2023; Geyin과 Maurer, 2023; Ilhan 등, 2025). 지질공학 저널에서 흔히 볼 수 있는 응용 분야로는 물리 기반 신경망(PINNs)이 파동 전파에 사용되고, 심층 연산자 네트워크(DeepONet)가 기초 반응에 적용됩니다. 이러한 약속은 매력적이지만, 기계 학습이 전통적인 방법보다 진정으로 우수한 성능을 발휘하는지 의문을 제기할 필요가 있습니다.
본 논문은 이러한 질문에 답하기 위해 직접적인 수치 비교를 통해 ML 방법을 평가합니다. 우리는 “스트레스 테스트"를 수행하여 전통적인 솔버와 ML 방법을 비교하고, 벽시계 시간, 정확도, 구현 용이성을 측정합니다. 우리의 초점은 단순한 1차원 문제에 집중하며, 이는 1D 파동 전파 및 응축과 같은 물리학이 명확하게 밝혀져 있고 정확한 해가 존재하기 때문에 지질공학의 기본 분석에서 시작점을 제공한다는 점에서 중요합니다. 전통적인 솔버는 이미 1D에서는 매우 효율적이기 때문에 이러한 단순 테스트는 필수적입니다. 이를 통해 성능 기준을 확립하고, ML 방법의 근본적인 한계, 상대적인 계산 오버헤드, 실패 모드를 드러낼 수 있습니다. 만약 방법이 1차원 문제에서 부정확하거나 전통적인 솔버보다 훨씬 느리면, 그 이유는 이해하기 전에 신뢰할 수 없습니다. 이는 복잡한 3D 문제에서 이러한 검증이 거의 불가능하기 때문입니다.
최근 리뷰에서 인정했듯이 (Wang 등, 2025; Fransen 등, 2025), 기계 학습은 데이터 요구 사항, 물리적 일관성, 예측 신뢰도 등의 중요한 과제에 직면해 있습니다. 이는 기계 학습을 지질공학 도구로 채택하기 전에 같은 검증 표준을 적용해야 함을 의미합니다. 우리는 증명된 솔버를 신경망으로 대체하기 전에 정확도, 계산 비용, 또는 물리적 일관성의 명확한 장점을 입증해야 한다고 주장합니다.
본 논문의 구조는 다음과 같습니다. 먼저, ML 방법의 두 가지 근본적인 한계를 다루고, 그 다음 다층 퍼셉트론(MLPs), PINNs, DeepONet과 그들의 유한차분 대응체 간의 성능을 정량화합니다. 마지막으로, 대안으로 자동 미분(AD)을 제시하고, 지질공학자가 이러한 현대적 계산 도구를 효과적으로 활용하기 위한 실용적인 의사결정 프레임워크를 제공합니다.
2. 지질공학에서 다층 퍼셉트론 (MLPs)
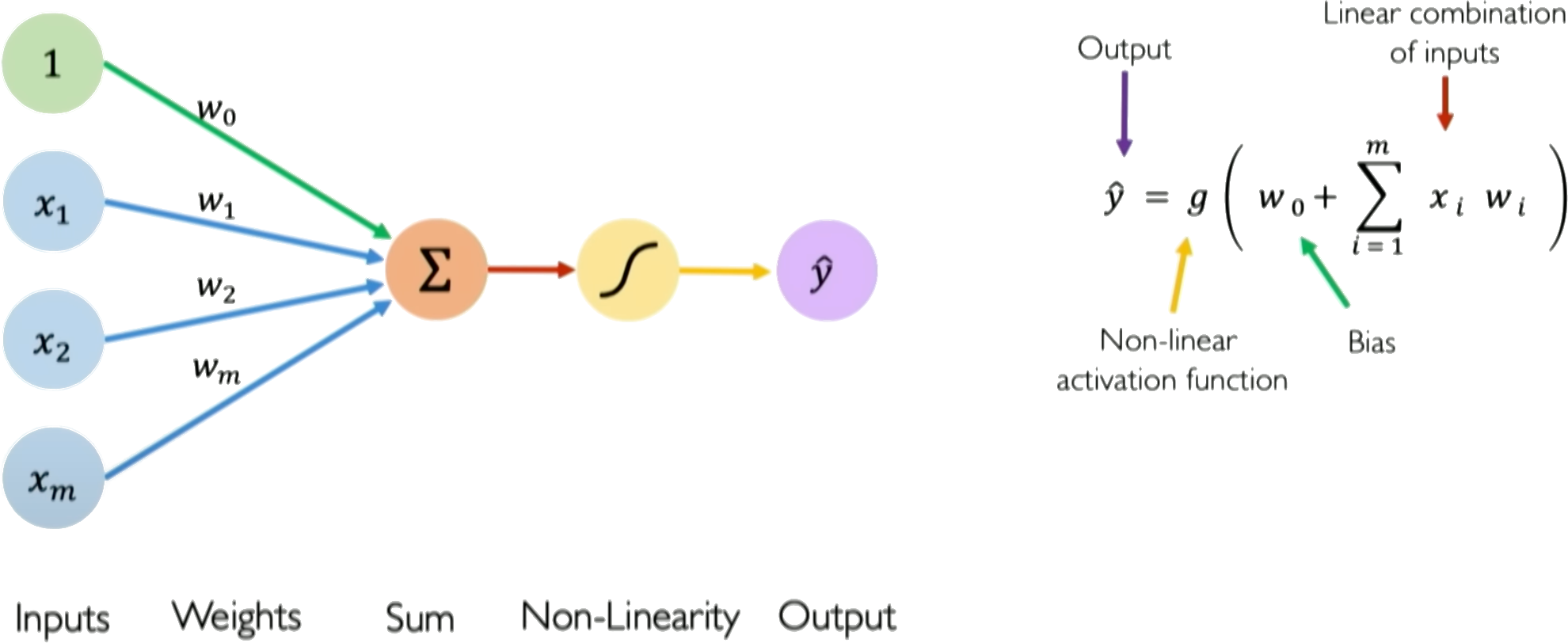
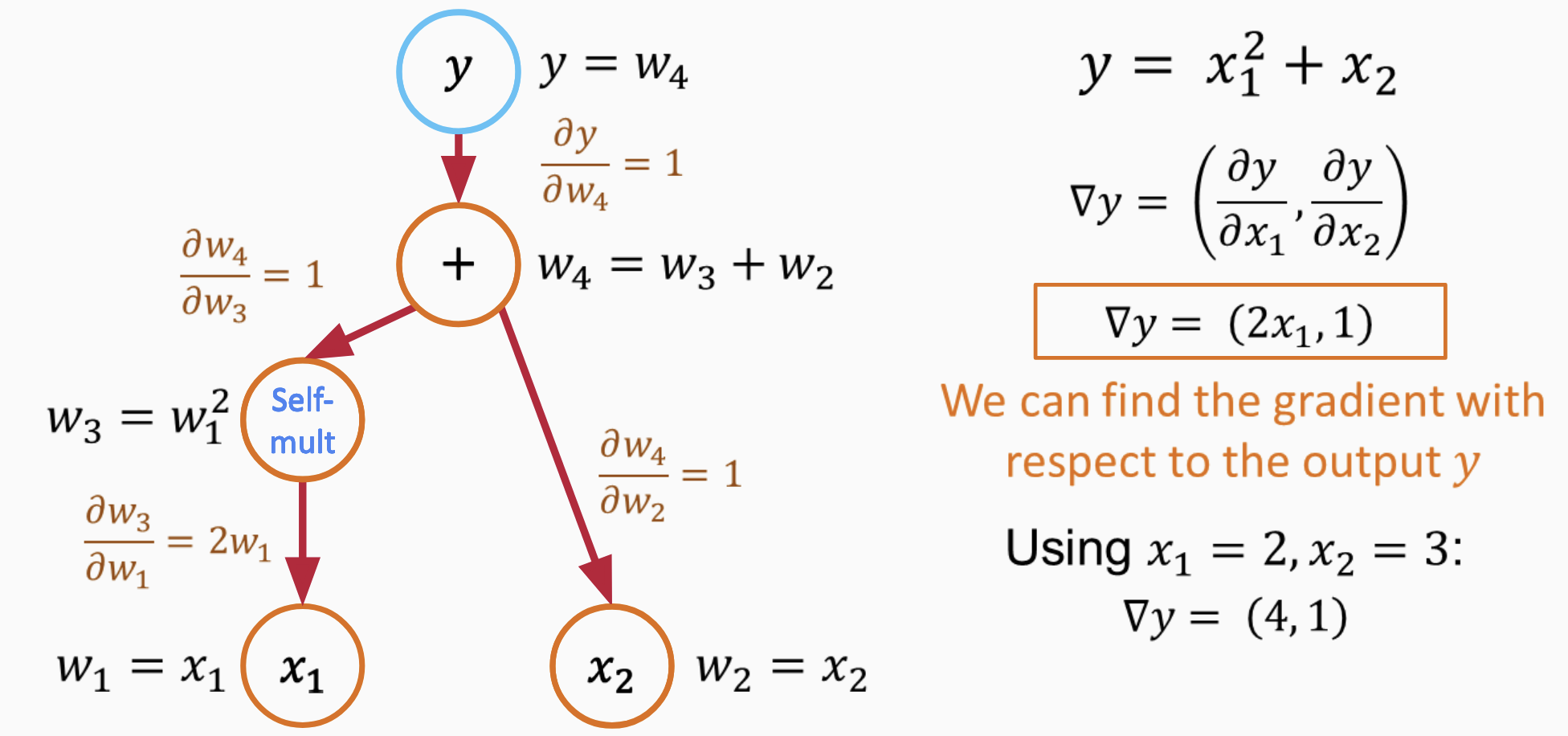
다층 퍼셉트론은 현대 신경망의 기초이며 이해하는 것이 ML 방법의 작동 원리를 명확히 하는 데 도움이 됩니다. MLP는 입력을 받아 출력으로 변환하는 여러 개의 연결된 뉴런으로 구성된 네트워크입니다. 각 뉴런은 가중합과 편향을 사용하여 입력 값에 선형 조합을 수행한 후 비선형 활성화 함수를 적용합니다 (그림 1).
여기서 xi는 입력(예: 깊이, 콘 크러시 저항, 포르 말 압력), wi는 학습 가능한 가중치, b0는 편향이며, g는 활성화 함수입니다.
핵심 개념은 가중치와 편향만 학습 가능하고, 활성화 함수는 고정되어 있다는 것입니다. 네트워크는 선형 조합을 통해 학습 데이터에 적응한 후 활성화 함수를 적용하여 비선형성을 도입합니다. 학습은 손실 함수를 최소화하여 가중치를 업데이트함으로써 이루어집니다. 역전파 알고리즘은 이러한 가중치 업데이트를 효율적으로 계산하기 위해 계층별로 적용됩니다. 여러 뉴런을 쌓아 다층 퍼셉트론을 만들면 복잡한 비선형 관계를 모델링할 수 있습니다.
활성화 함수의 선택은 네트워크가 비선형성을 어떻게 표현하는지에 중요한 영향을 미칩니다. 일반적인 옵션으로는 ReLU (max(0, z) 함수), tanh (tanh(z) 함수로 출력 범위는 -1과 1 사이), 시그모이드 (1/(1 + e-z) 함수로 출력 범위는 0과 1 사이)가 있습니다. 이러한 활성화 함수는 모두 작은 입력 변화에 큰 출력 변화를 일으키는 민감한 영역을 가지고 있으며, |z| > 2와 같은 과대입력 영역에서는 출력이 포화됩니다.
특징 정규화는 입력을 이 민감한 영역에 유지하는 데 도움이 됩니다. 깊이가 다른 메커니즘(예: 1미터의 깊이와 1kPa의 효과적 응력)을 가진 특징은 가중 합의 선형 조합이 수백 또는 수천의 값을 생성할 수 있습니다. 이러한 과도한 가중치는 뉴런을 포화 상태로 몰아넣고 학습을 방해합니다. Z-점수 정규화는 이 문제를 해결하기 위해 사용됩니다. 이는 특징을 평균과 표준 편차로 표준화하여 모든 입력을 민감한 영역에 유지합니다.
지질공학의 문제에서 이러한 개념을 이해하는 것은 중요합니다. 예를 들어, 매트 기초 설계에 대한 고층 건물의 정착 측정을 위한 신경망을 훈련한다고 가정해 봅시다. 새로운 건물은 200 kPa의 하중을 받으며, 기존 구조물은 이전에 200 kPa의 하중을 받은 후 100 kPa의 정착을 보였습니다. 신경망이 이 데이터에 대해 훈련된 후에도 이러한 새로운 하중 조건에 대한 정착을 정확하게 예측할 수 있을까요?
답은 ‘아니오’이며, 이를 통해 ML 방법의 첫 번째 근본적인 한계를 이해할 수 있습니다. Terzaghi의 응축 평형은 다음과 같은 식으로 표현됩니다:
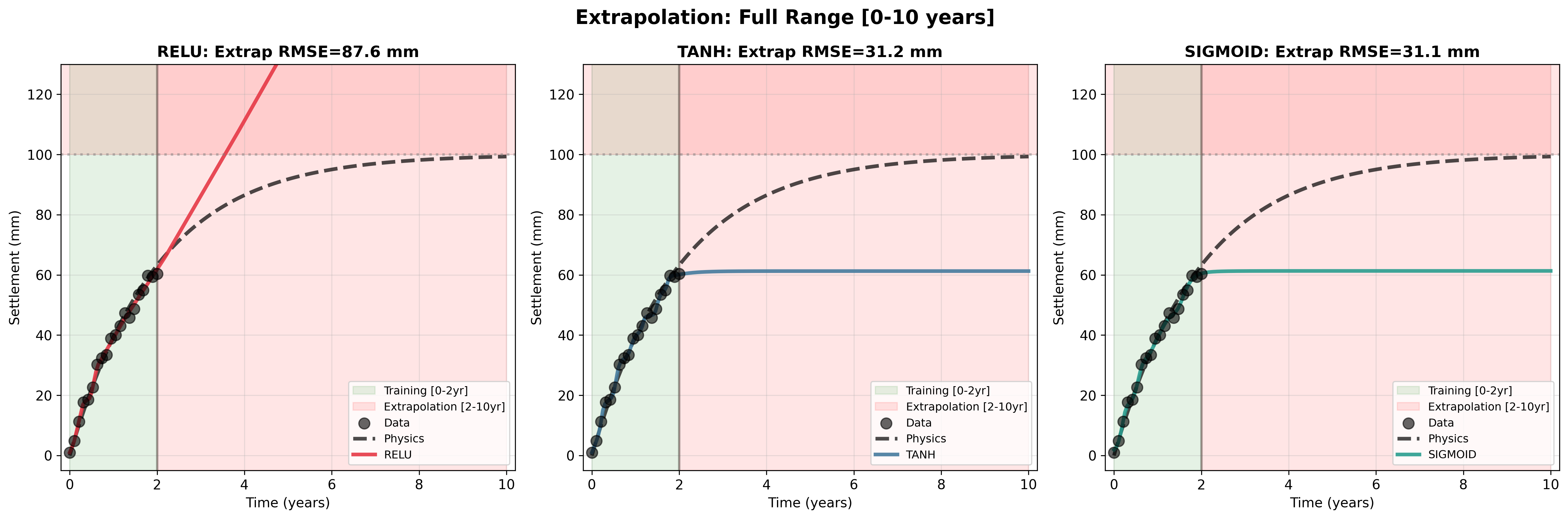
S∞는 최종 정착이고, α는 정착 속도입니다. 이 곡선은 초기 0에서 시작해 급격히 상승한 후 점차 수렴하여 최종 값에 도달합니다.
우리는 직접 실험을 수행했습니다. 20개의 정착 데이터 포인트를 사용하여 2년 동안의 정착 측정을 훈련 데이터로 사용했습니다. 세 개의 MLP를 훈련시켰으며, 각각 두 개의 은닉층과 32개의 뉴런을 가지고 있으며 ReLU, tanh, 시그모이드 활성화 함수를 사용했습니다. 세 네트워크 모두 훈련 데이터에 대해 완벽하게 적합되었기 때문에 평균 제곱 오차가 6mm² 이하입니다 (그림 2). 이제 이 네트워크를 예측에 사용해 보겠습니다. 과거 데이터의 훈련 영역 외부에서 정착을 예측해야 합니다. 예를 들어, 10년 후 정착을 예측해야 합니다. S∞ = 100 mm, α = 0.5/년인 경우입니다.