Title: Benchmark Success, Clinical Failure: When Reinforcement Learning Optimizes for Benchmarks, Not Patients
ArXiv ID: 2512.23090
발행일: 2025-12-28
저자: Armin Berger, Manuela Bergau, Helen Schneider, Saad Ahmad, Tom Anglim Lagones, Gianluca Brugnara, Martha Foltyn-Dumitru, Kai Schlamp, Philipp Vollmuth, Rafet Sifa
📝 초록 (Abstract)
최근 대형 언어 모델(LLM)의 강화학습(RL) 기반 추론 능력 향상이 의료 영상 분야에 적용되기엔 자원 제약이 큰 상황이다. 본 연구는 2,000개의 지도학습(SFT) 샘플과 1,000개의 RL 샘플만을 사용하고, A100 GPU 한 대로 학습한 비전‑언어 모델 ChexReason을 제안한다. ChexReason은 R1‑style 방법론(SFT 후 GRPO)으로 훈련되었다. CheXpert와 NIH 데이터셋에서 평가한 결과, GRPO는 CheXpert 내분포 성능을 23 % 향상시켜 macro‑F1 = 0.346을 기록했지만, NIH 데이터셋에 대한 교차‑데이터셋 전이 성능은 19 % 감소하였다. 이는 대규모 모델(NV‑Reason‑CXR‑3B)에서도 동일하게 나타나며, 문제의 원인이 모델 규모가 아니라 RL 패러다임 자체에 있음을 시사한다. 특히, SFT 체크포인트가 NIH에서 최적화 전보다 유일하게 성능을 높이는 ‘일반화 역설’이 관찰되었으며, 이는 교사‑유도 추론이 기관‑불변 특성을 더 잘 포착한다는 의미다. 또한, 구조화된 추론 스캐폴드는 일반 목적 VLM에는 도움이 되지만, 의료 전용 사전학습 모델에는 큰 이득을 주지 못한다. 따라서 임상 현장에서 다양한 인구집단에 대한 견고함이 요구될 경우, 과도한 RL보다 정교히 설계된 지도학습이 더 나은 선택일 수 있다.
💡 논문 핵심 해설 (Deep Analysis)
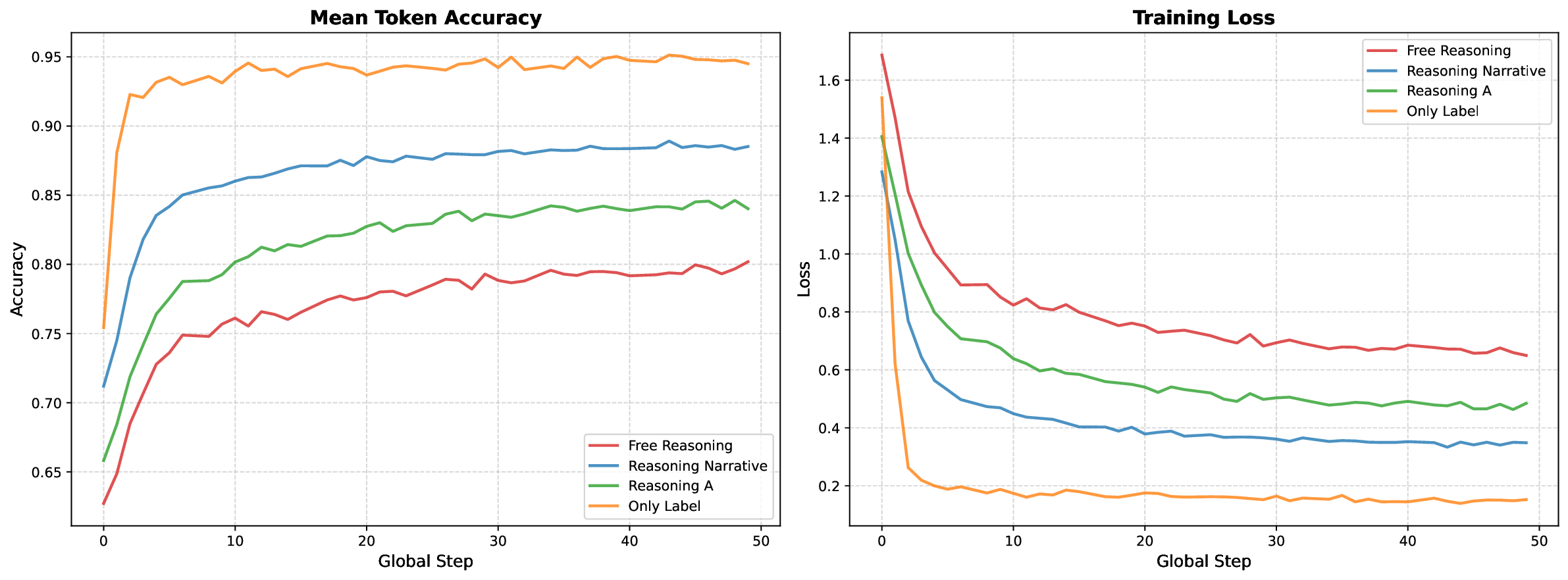
본 논문은 의료 영상 분야에서 최근 각광받고 있는 강화학습(RL) 기반 파인튜닝이 실제 임상 적용에 어떤 함의를 갖는지 심도 있게 탐구한다. 먼저 저자들은 “R1‑style”이라 명명한 두 단계 학습 파이프라인을 제시한다. 첫 단계는 비교적 적은 양(2,000개)의 라벨링된 이미지‑텍스트 쌍을 이용한 지도학습(Supervised Fine‑Tuning, SFT)이며, 두 번째 단계는 1,000개의 RL 샘플을 활용해 GRPO(Goal‑oriented Reward‑based Policy Optimization)라는 정책 최적화 기법을 적용한다. 이 과정 전체를 단일 A100 GPU 한 대에서 수행했음에도 불구하고, CheXpert 벤치마크에서 macro‑F1 0.346이라는 의미 있는 성능 향상을 달성했다는 점은 자원 효율성 측면에서 큰 의미를 가진다.
하지만 핵심적인 발견은 “성능 패러독스”이다. SFT 단계에서 얻은 체크포인트는 NIH 데이터셋(다른 기관에서 수집된 CXR 이미지)에서 오히려 기존 사전학습 모델보다 높은 점수를 기록했으며, 이는 SFT가 기관‑불변적인 영상 특징을 잘 포착한다는 증거다. 반면, GRPO 단계에서 정책을 최적화하면서 CheXpert 내분포 성능은 23 % 상승했지만, 동일 모델을 NIH에 그대로 적용했을 때는 19 %의 성능 저하가 발생한다. 즉, RL이 목표 지표(벤치마크 점수)를 극대화하는 과정에서 모델이 데이터셋‑특정 편향을 과도하게 학습하게 되고, 그 결과 일반화 능력이 손상되는 것이다.
흥미로운 점은 이 현상이 대규모 모델(NV‑Reason‑CXR‑3B)에서도 동일하게 나타난다는 점이다. 따라서 “스케일이 문제다”는 기존 가설을 배제하고, RL 파라다임 자체가 의료 영상과 같이 데이터 분포가 기관마다 크게 달라지는 도메인에 부적합할 가능성을 제기한다. 특히, 의료 현장은 ‘데이터 다양성’과 ‘안전성’이 최우선이므로, 벤치마크 점수만을 최적화하는 RL 접근법은 실제 임상 배포 시 위험 요소가 된다.
또한, 저자들은 구조화된 추론 스캐폴드(예: 단계별 사고 체인)를 일반 목적 비전‑언어 모델에 적용했을 때는 성능 향상이 관찰되지만, 이미 의료 전용으로 사전학습된 모델에는 큰 효과가 없음을 보고한다. 이는 의료 이미지에 특화된 사전학습이 이미 충분히 도메인 지식을 내재하고 있어, 추가적인 추론 구조가 중복된 역할을 할 가능성을 시사한다.
결론적으로, 본 연구는 “벤치마크 최적화 ≠ 임상 최적화”라는 중요한 교훈을 제공한다. 제한된 라벨 데이터와 적은 연산 자원으로도 SFT만으로 충분히 견고한 성능을 달성할 수 있으며, RL을 적용할 경우 반드시 교차‑데이터셋 검증과 일반화 평가를 병행해야 한다. 향후 연구는 (1) RL 보상 설계에 도메인‑불변성을 반영하는 방법, (2) 멀티‑도메인 데이터로 사전학습된 멀티태스크 모델, (3) RL과 SFT를 혼합한 하이브리드 학습 스케줄을 탐색함으로써, 임상 현장에서 실제 환자에게 도움이 되는 모델을 만들 수 있을 것이다.
📄 논문 본문 발췌 (Excerpt)
## 벤치마크 성공, 임상 실패: 강화 학습이 벤치마크를 최적화하지만 환자는 아닙
요약:
최근 연구는 강화 학습(RL)이 대규모 언어 모델의 성능을 크게 향상시킬 수 있음을 보여주었습니다. 특히 명확한 보상 신호가 있고 결과가 쉽게 검증 가능한 수학 또는 코드 생성 분야에서 두드러집니다 (예: DeepSeek-R1). 그러나 이러한 성과가 더 약하거나 주관적인 감독 하에 문제를 해결할 때, 즉 자연어 생성과 다중 모달 입력과 같은 문제에 어떻게 전이되는지는 명확하지 않습니다. 본 연구는 R1 스타일 훈련(Supervised Fine-tuning (SFT)와 Group Relative Policy Optimization (GRPO)의 조합)이 심각한 자원 제약 하에서 소형 비전-언어 모델의 다중 레이블 흉부 X선 분류 성능을 향상시킬 수 있는지 조사합니다.
우리는 R1 스타일 훈련이 임상적으로 중요한 과제인 흉부 X선 진단에서 그 이점을 보여줄 수 있다고 주장합니다. 이 분야는 방사학자가 신속한 평가에 대한 가치와 함께 신뢰할 수 있는 출력 추론을 위한 근거를 제공하는 데 중점을 둡니다. 또한, 흉부 X선은 큰 공개 데이터 세트에 다중 레이블 주석이 제공되어 RL에 자연스러운 보상 신호를 제공합니다.
우리의 접근 방식은 R1 스타일 훈련을 극한 자원 제약 조건에서 조사하는 것입니다. 이는 50배 적은 훈련 데이터와 4배 적은 컴퓨팅 리소스를 의미하며, 이를 통해 임상 실무자들이 광범위한 주석 파이프라인이나 고급 인프라 없이도 추론 지침을 활용하여 진단 성능을 향상시킬 수 있는 방법을 제시합니다.
본 연구의 주요 기여는 다음과 같습니다:
저자원 R1 스타일 훈련: 우리는 2,000개의 SFT 샘플과 1,000개의 RL 샘플로 단일 NVIDIA A100 GPU에서 훈련된 ChexReason 모델을 제시합니다. 이를 통해 R1 스타일 훈련이 제한적인 자원에서도 가능함을 보여줍니다.
지시 형식의 민감성: 교차 모델 분석은 최적의 지시 형식이 의료 사전 훈련에 따라 달라짐을 드러냅니다. 구조화된 의학 정보 기반 추론 사슬은 일반 목적 VLMs에 유익하지만 도메인 전문 모델에는 거의 영향을 미치지 않습니다.
벤치마크 전이 대 가격: GRPO는 CheXpert 성능을 향상시킵니다 (+23%) 하지만 NIH 전이성에는 부정적인 영향을 미칩니다 (-19%). 이는 NV-Reason-CXR-3B의 실패와 유사하며, RL 기반 접근 방식의 근본적인 문제점을 시사합니다.
일반화 모순: SFT 체크포인트는 아웃 오브 디스트리뷰션 데이터에서 특히 잘 수행됩니다. 이는 교사 지침이 더 일반화된 특징을 포착하는 반면 보상 최적화된 출력은 그렇지 않다는 것을 의미합니다.
관련 연구:
최근 몇 년간, 의료 시각 질의 응답(VQA)에 RL을 적용한 연구가 증가했습니다. 예를 들어, MedVLM-R1은 GRPO를 사용하여 MRI, CT 및 Xray 벤치마크에서 VQA 정확도를 크게 향상시킵니다. 또한, Med-R1은 RL이 일반 도메인 접근 방식과 비교하여 진단 및 신뢰성 측면에서 우수한 성능을 발휘함을 보여주었습니다.
그러나 다중 레이블 흉부 X선 분류는 상대적으로 덜 연구되었습니다. NVIDIA의 NV-Reason-CXR-3B는 GRPO를 사용하여 CheXpert에 대한 추론과 분류를 향상시키는 선구적인 노력입니다. 이 모델은 두 단계 훈련 파이프라인을 사용하여 구조화된 의학 추론을 생성합니다.
본 연구는 이러한 접근 방식과 비교하여 저자원 환경에서 R1 스타일 훈련의 효과를 조사하고, 다중 레이블 흉부 X선 분류에 대한 새로운 통찰력을 제공합니다.
방법:
우리는 두 단계로 구성된 방법론을 사용하여 비전-언어 모델을 훈련합니다: SFT와 GRPO.