셀프 호스팅 LLM을 위한 스마트 오케스트레이션 프레임워크 Pick and Spin
📝 원문 정보
- Title: Efficient Multi-Model Orchestration for Self-Hosted Large Language Models
- ArXiv ID: 2512.22402
- 발행일: 2025-12-26
- 저자: Bhanu Prakash Vangala, Tanu Malik
📝 초록 (Abstract)
자체 호스팅 대형 언어 모델(LLM)은 프라이버시, 비용 통제, 맞춤형 서비스 제공을 원하는 조직에 점점 더 매력적인 선택이 되고 있다. 그러나 사내 모델을 배포하고 유지하는 과정에서는 GPU 활용 효율, 워크로드 라우팅, 시스템 신뢰성 등 여러 과제가 존재한다. 본 논문에서는 이러한 문제를 해결하기 위해 Kubernetes 기반의 실용적인 프레임워크인 Pick and Spin을 제안한다. 이 프레임워크는 Helm을 이용한 통합 배포 시스템, 적응형 ‘scale‑to‑zero’ 자동화, 그리고 키워드 기반 휴리스틱과 경량 DistilBERT 분류기를 결합한 하이브리드 라우팅 모듈을 포함한다. Llama‑3(90B), Gemma‑3(27B), Qwen‑3(235B), DeepSeek‑R1(685B) 네 모델을 대상으로 8개의 공개 벤치마크 데이터셋, 5가지 추론 전략, 2가지 라우팅 변형을 조합해 총 31,019개의 프롬프트와 163,720회의 추론을 수행하였다. 실험 결과 Pick and Spin은 정적 배포 대비 성공률을 최대 21.6% 향상시키고, 지연 시간을 30% 감소시키며, 쿼리당 GPU 비용을 33% 절감했다. 이는 지능형 오케스트레이션과 효율적인 스케일링이 기업 수준의 LLM 성능을 자체 인프라에서도 경제적으로 구현할 수 있음을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
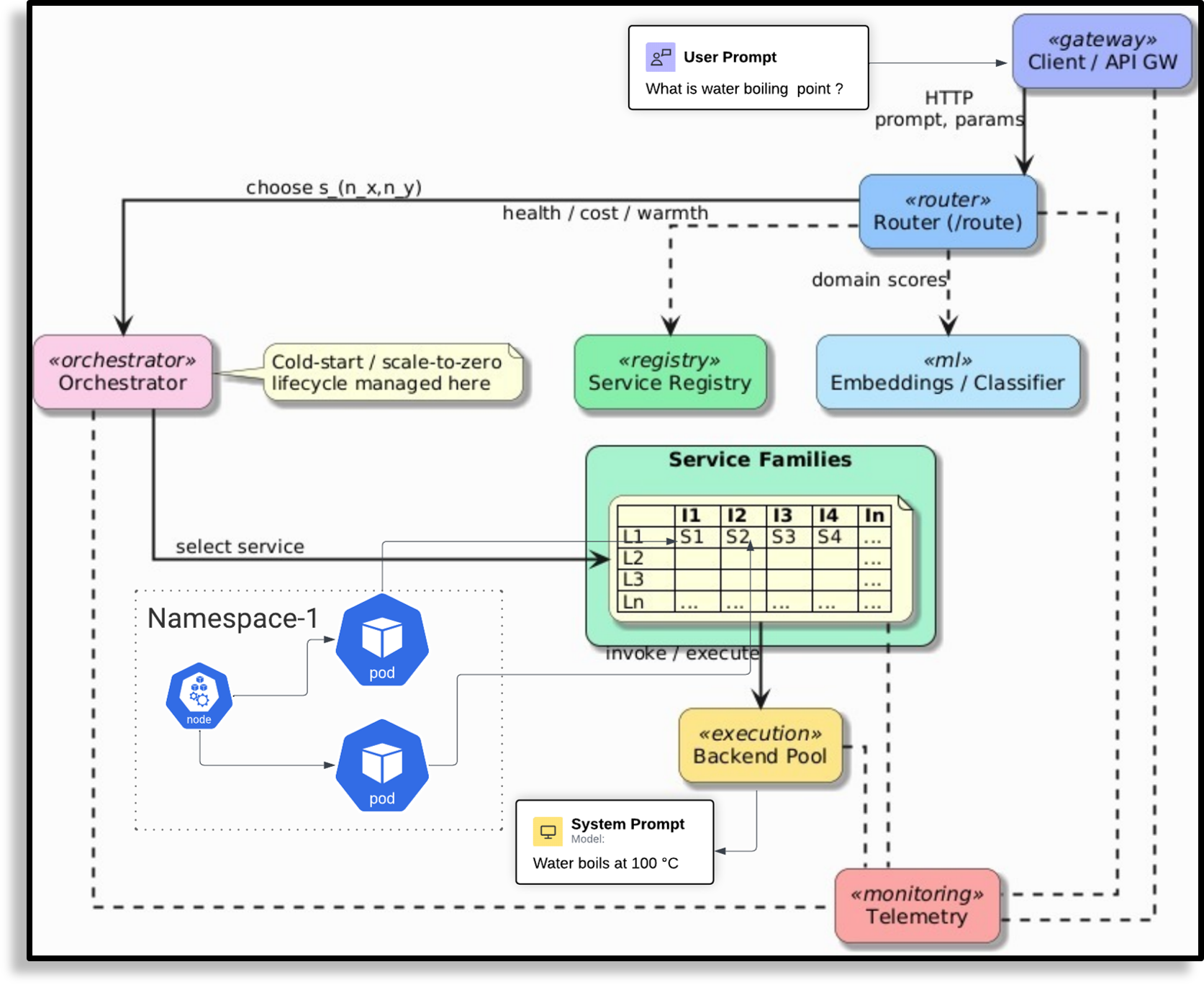
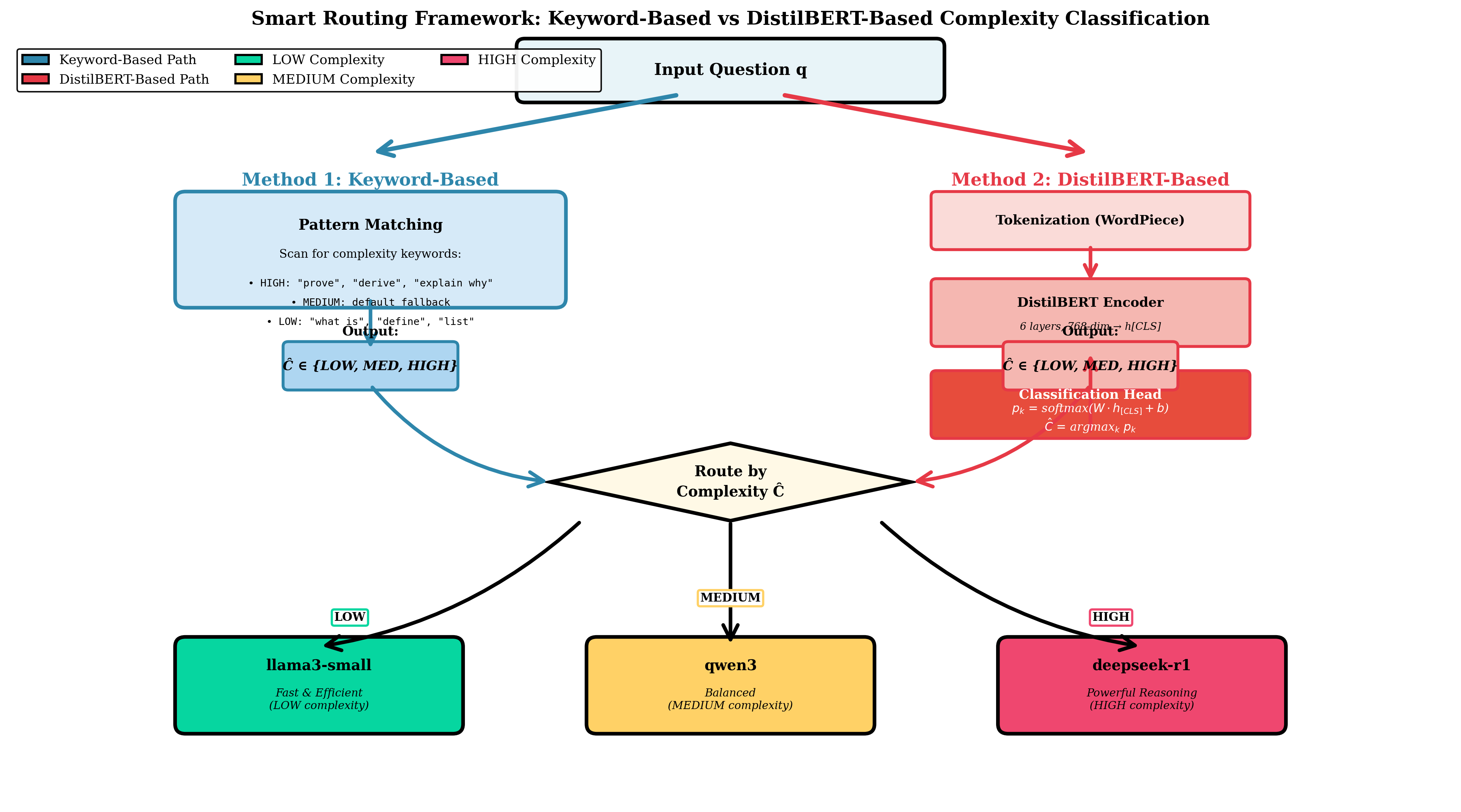
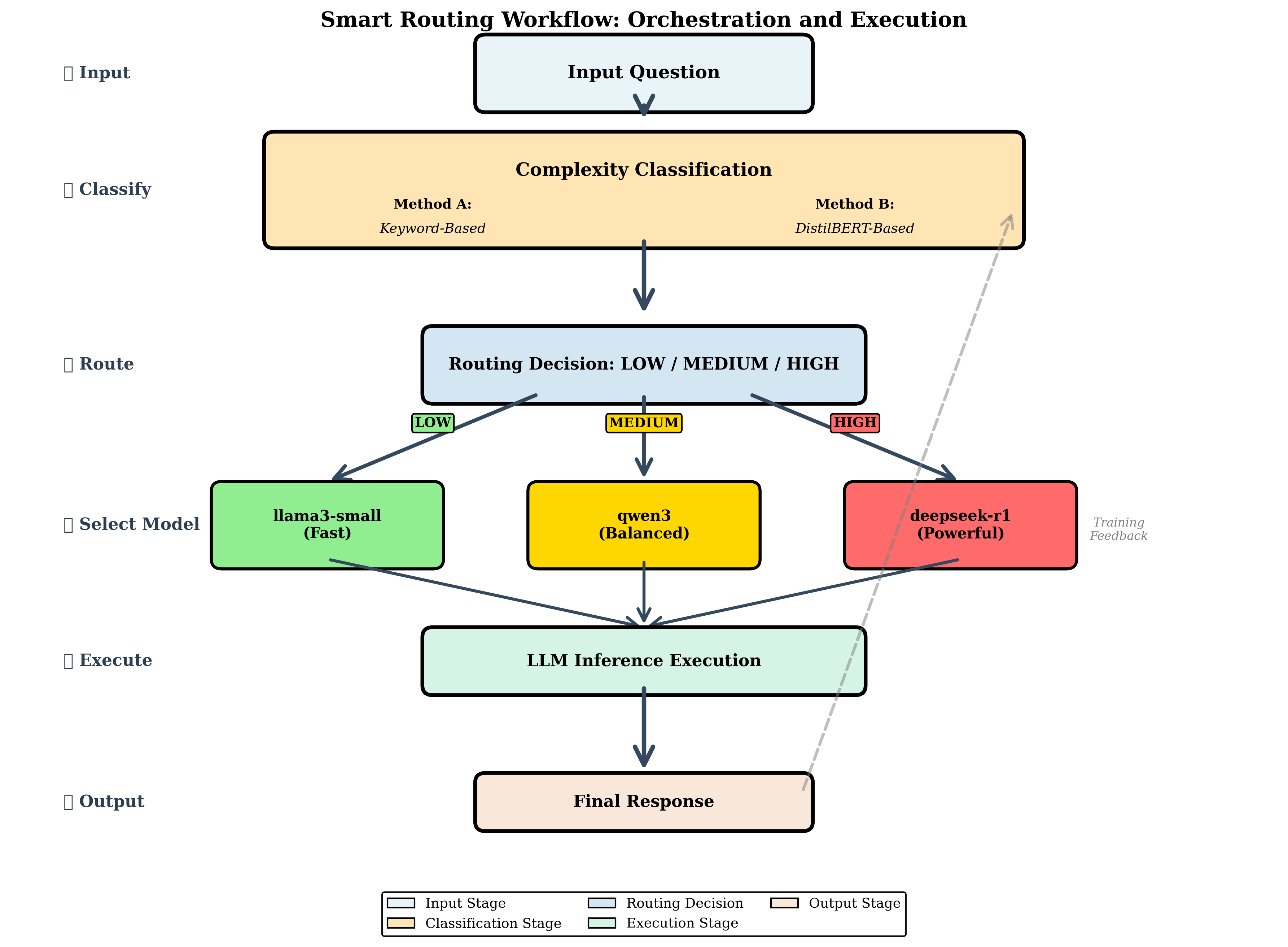
Pick and Spin은 이러한 문제를 Kubernetes와 Helm을 기반으로 한 자동화된 인프라 관리 체계로 해결한다. Helm 차트를 이용해 모델별 컨테이너 이미지, GPU 요구량, 네트워크 설정 등을 선언형으로 정의함으로써 배포 일관성을 확보한다. ‘scale‑to‑zero’ 메커니즘은 사용량이 없을 때 해당 모델 파드를 완전히 종료하고, 새 요청이 들어오면 즉시 재시작하도록 설계돼, GPU 비용을 크게 절감한다. 라우팅 모듈은 두 단계로 구성된다. 먼저 키워드 기반 휴리스틱이 요청의 도메인·복잡도를 빠르게 판단해 대략적인 후보 모델을 선정한다. 이어서 경량 DistilBERT 분류기가 보다 정교한 특성을 평가해 최적 모델을 선택한다. 이 하이브리드 접근은 복잡한 딥러닝 라우터를 도입하는 비용을 피하면서도 높은 정확도를 유지한다.
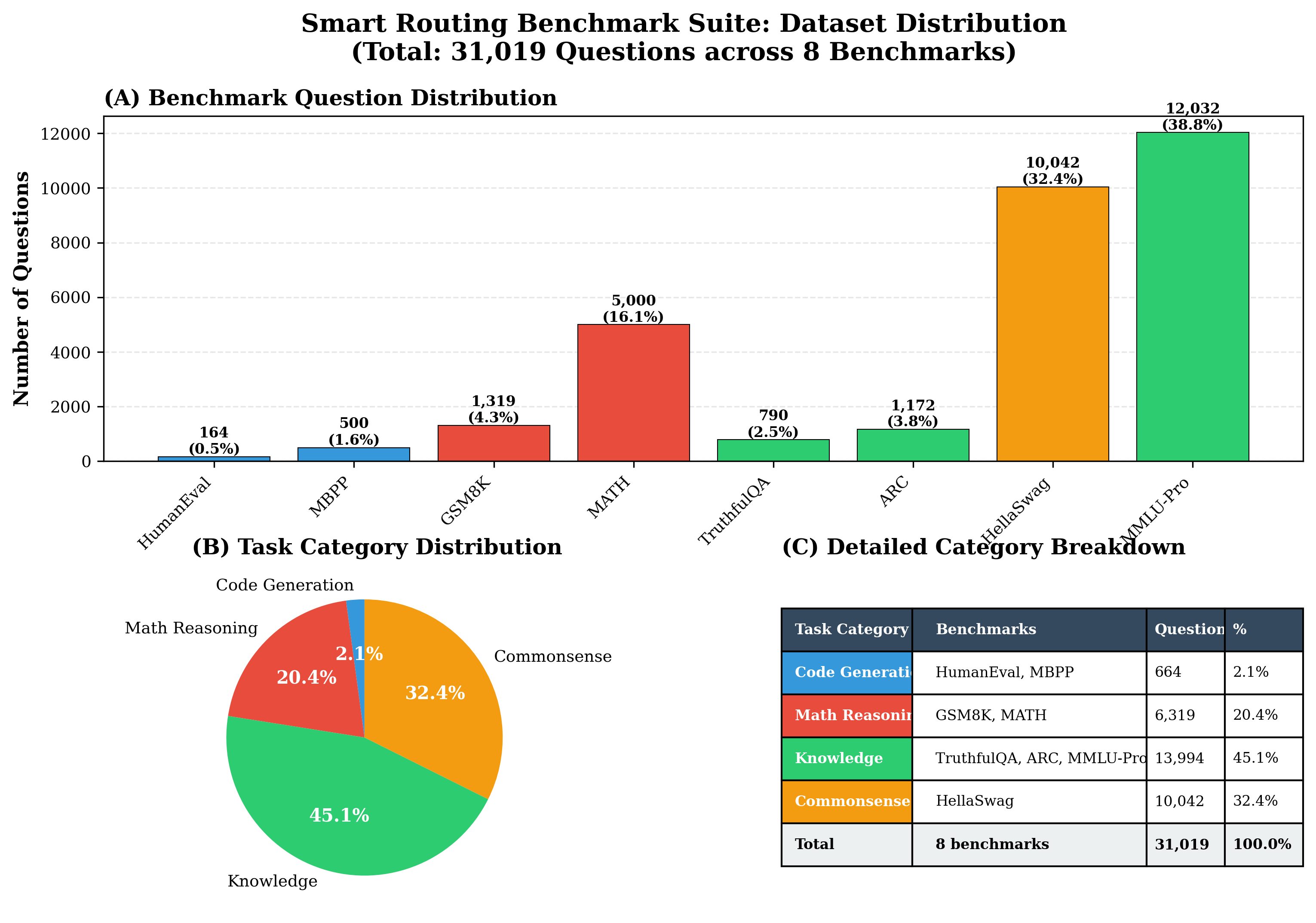
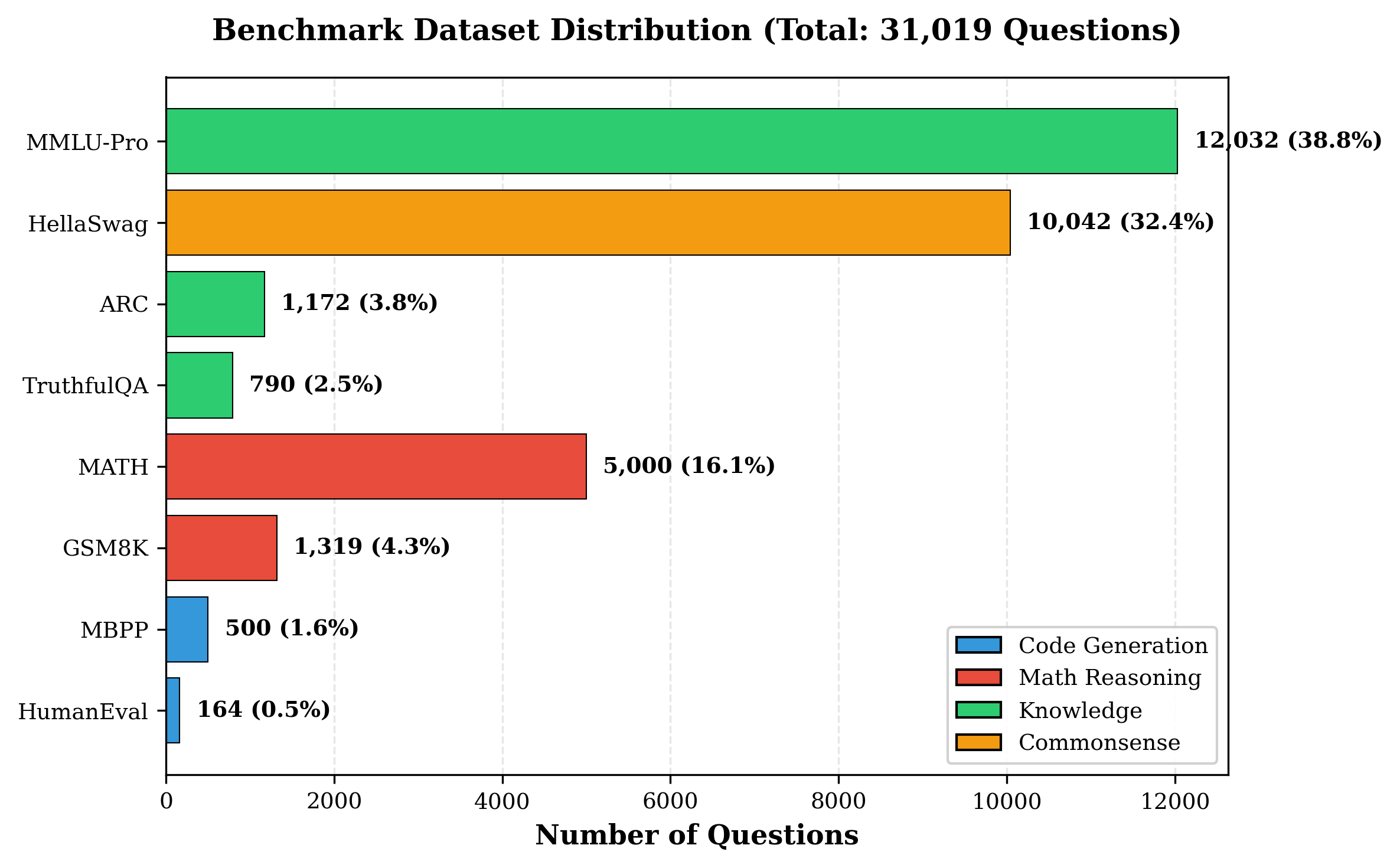
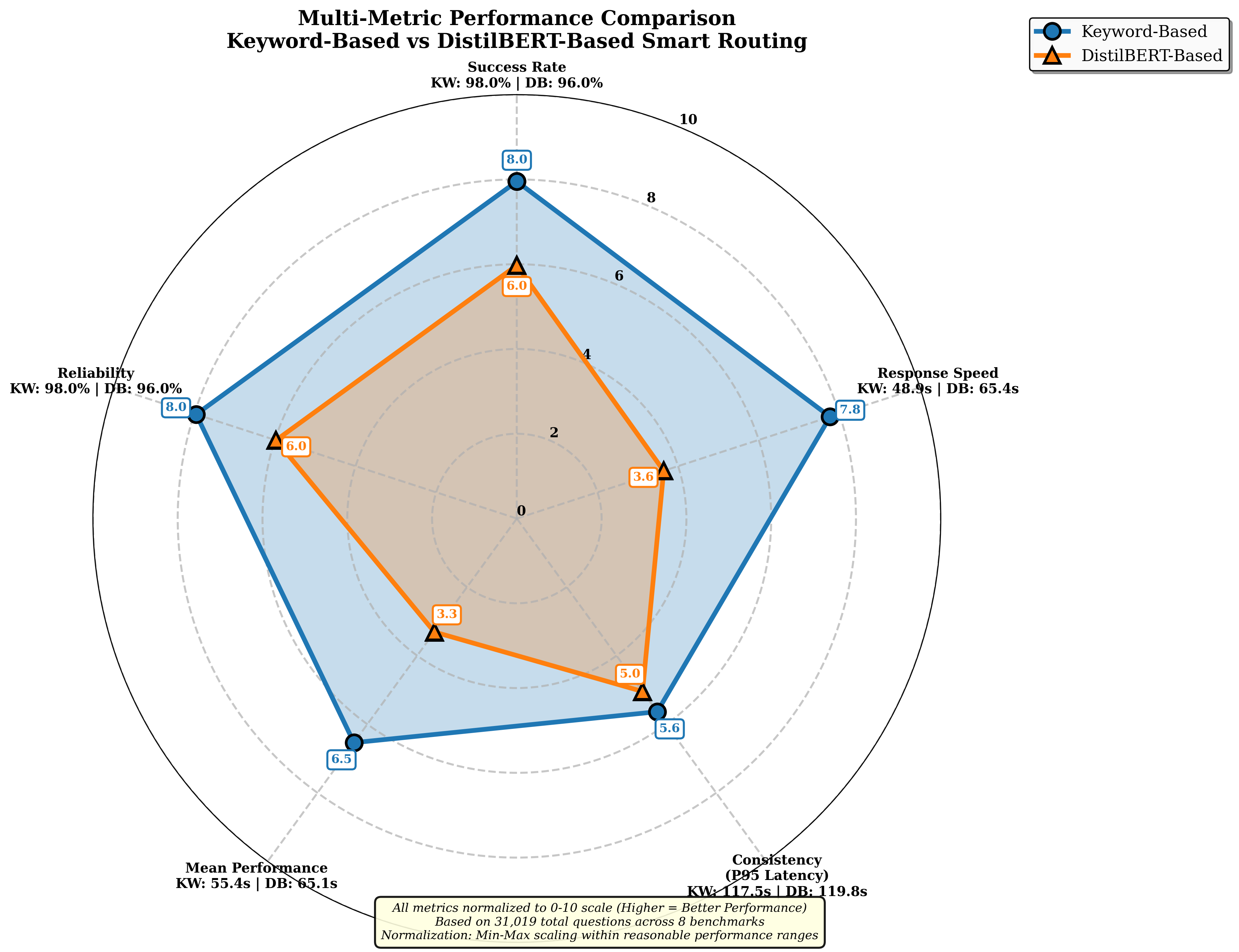
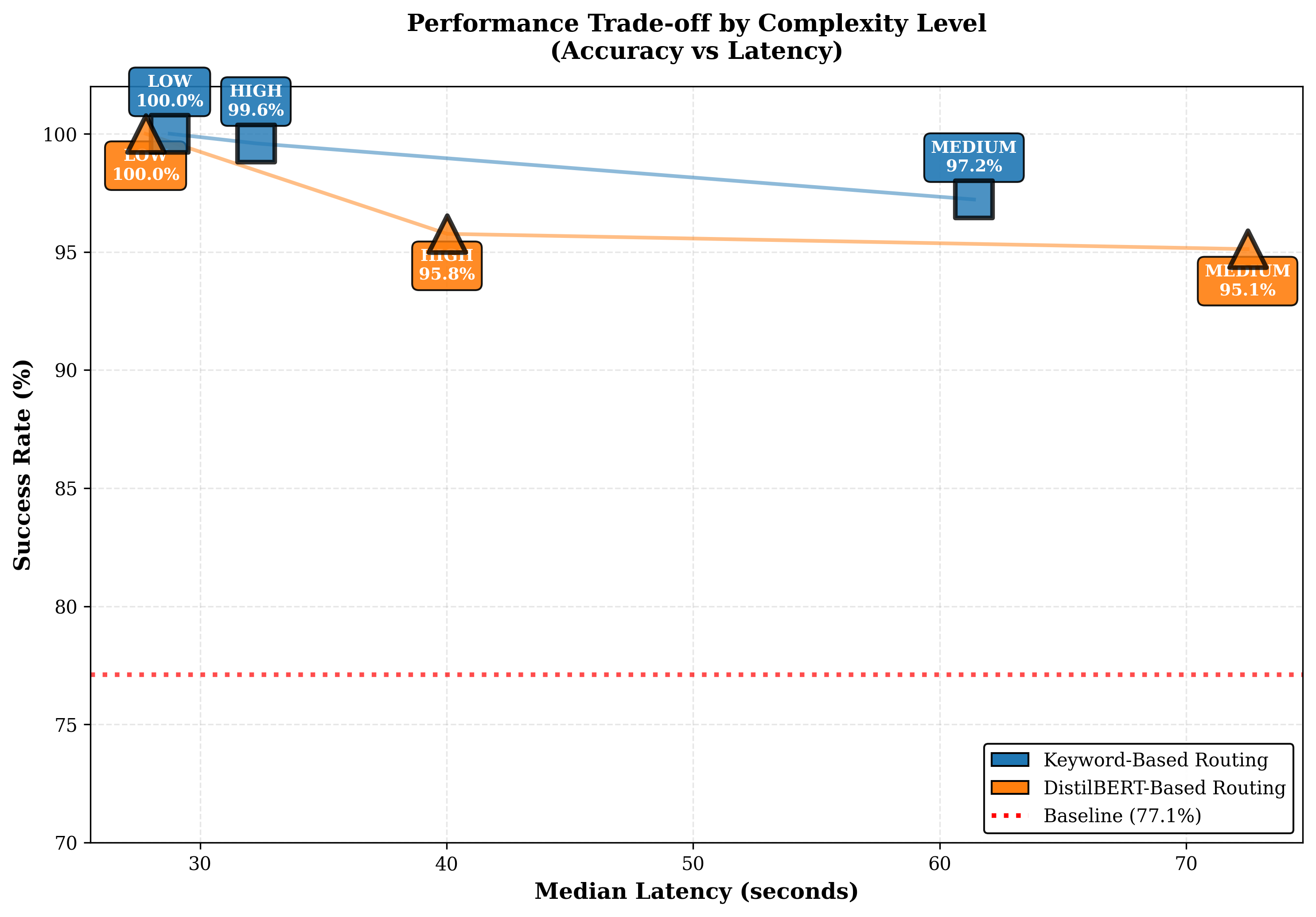
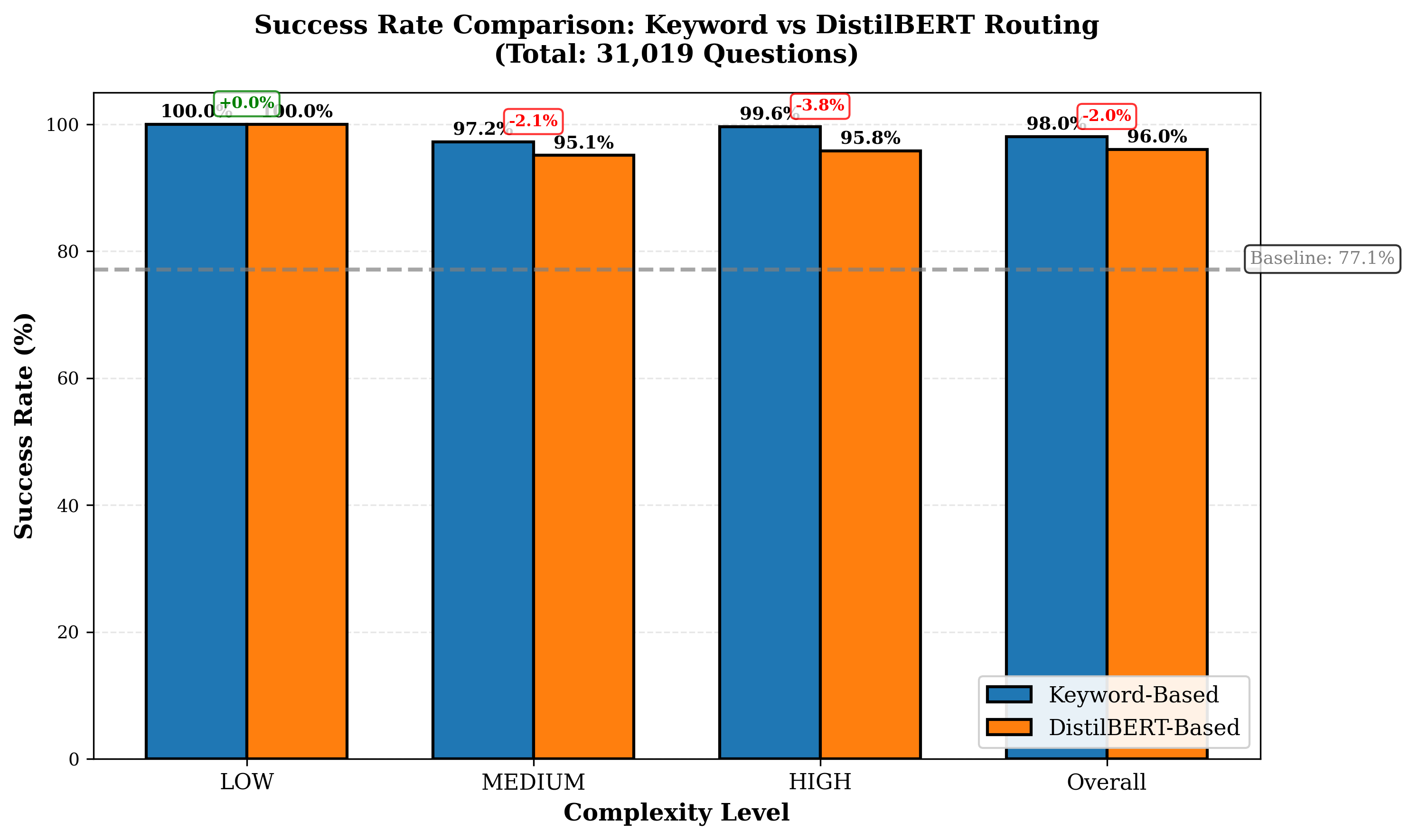
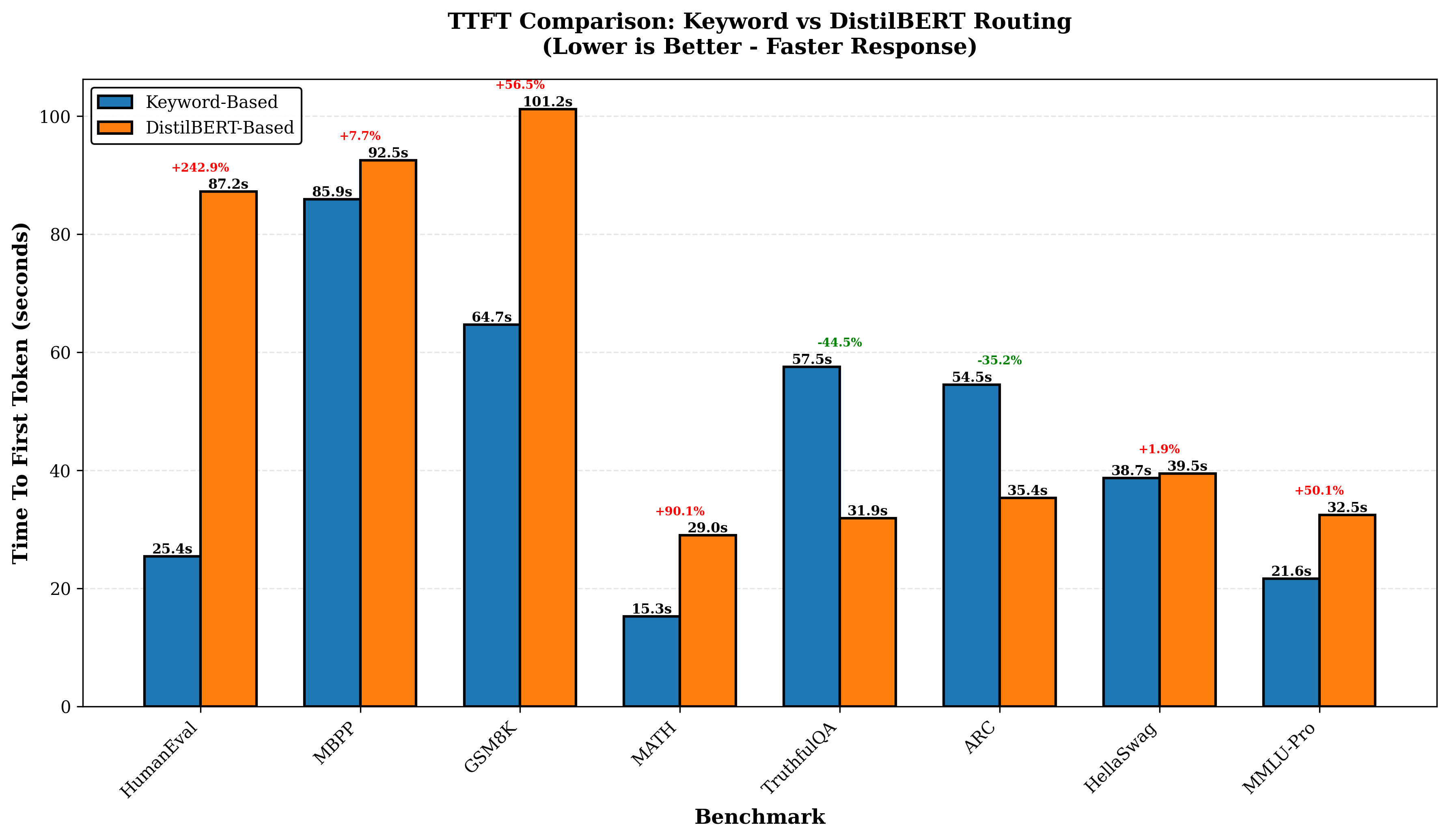
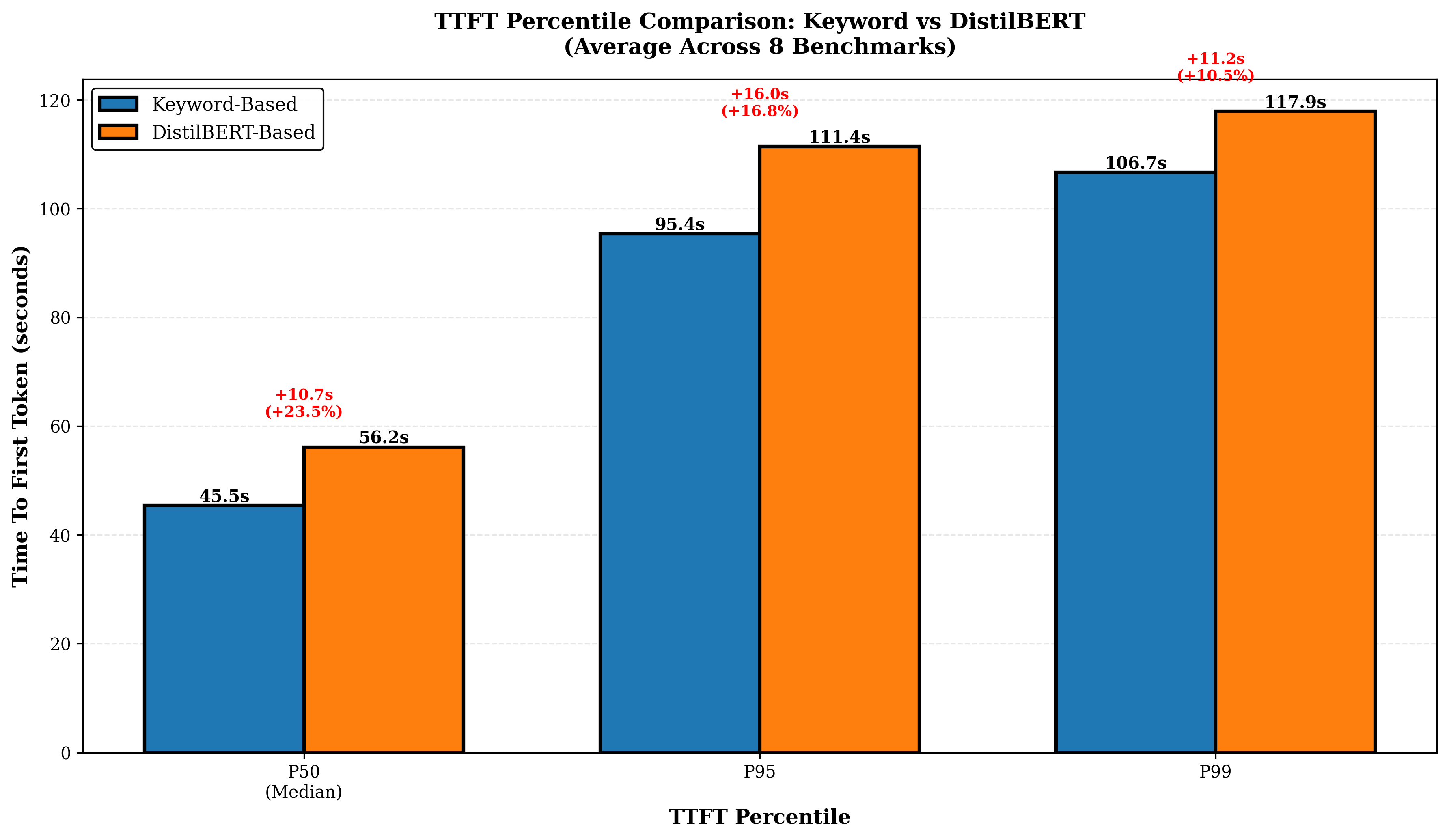
평가에서는 4개의 최신 LLM을 선택해 8개의 공개 벤치마크(예: MMLU, GSM‑8K 등)와 5가지 추론 전략(예: greedy, beam, sampling 등)을 적용했으며, 라우팅 변형 두 가지(휴리스틱‑단독 vs. 휴리스틱+DistilBERT)를 비교했다. 총 31,019개의 프롬프트와 163,720회의 추론 실행을 통해 성공률, 평균 지연시간, GPU당 비용을 측정했다. 결과는 Pick and Spin이 정적 배포 대비 성공률을 최대 21.6% 끌어올리고, 평균 지연시간을 30% 단축했으며, 쿼리당 GPU 비용을 33% 절감함을 보여준다. 특히 대형 모델(685B)에서 ‘scale‑to‑zero’가 비용 절감에 크게 기여했으며, 하이브리드 라우팅이 정확도와 비용 사이의 트레이드오프를 효과적으로 조정했다.
이 논문의 의의는 기술적 구현뿐 아니라 실제 기업 환경에서 적용 가능한 운영 프레임워크를 제공한다는 점이다. Kubernetes와 Helm이라는 표준 도구를 활용함으로써 기존 DevOps 파이프라인에 손쉽게 통합할 수 있다. 또한 라우팅 전략을 플러그인 형태로 설계해 향후 더 정교한 메타러닝 기반 라우터나 비용‑예측 모델을 추가할 여지를 남긴다. 한계점으로는 DistilBERT 라우터 자체가 추가적인 추론 비용을 발생시키며, 매우 짧은 응답시간이 요구되는 실시간 서비스에서는 여전히 병목이 될 수 있다. 또한 ‘scale‑to‑zero’ 재시작 시 초기화 지연이 발생하므로, 지속적인 트래픽이 보장되는 서비스에는 별도의 상시 가용 파드가 필요하다. 향후 연구에서는 라우팅 비용을 최소화하는 경량 모델 개발과, 예측 기반 사전 스케일링 기법을 결합해 더욱 낮은 레이턴시를 달성하는 방안을 모색할 수 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리