인공지능의 감성 지능 평가 프레임워크: HeartBench
읽는 시간: 3 분
...
📝 원문 정보
- Title: HeartBench: Probing Core Dimensions of Anthropomorphic Intelligence in LLMs
- ArXiv ID: 2512.21849
- 발행일: 2025-12-26
- 저자: Jiaxin Liu, Peiyi Tu, Wenyu Chen, Yihong Zhuang, Xinxia Ling, Anji Zhou, Chenxi Wang, Zhuo Han, Zhengkai Yang, Junbo Zhao, Zenan Huang, Yuanyuan Wang
📝 초록 (Abstract)
대형 언어 모델(LLMs)은 인지와 추론 벤치마크에서 놀라운 성과를 보였지만, 복잡한 사회적, 정서적, 윤리적 미묘함을 이해하는 인간 유사 지능에 대한 부족함이 여전히 존재한다. 이 격차는 특히 중국어 언어와 문화 맥락에서 전문적인 평가 프레임워크와 고품질 사회정서 데이터의 부재로 인해 더욱 두드러진다. 이러한 제한점을 해결하기 위해, 우리는 HeartBench를 제시한다. 이는 중국어 LLM들의 통합된 정서적, 문화적, 윤리적 차원을 평가하는 프레임워크이다. 심리 상담 시나리오와 임상 전문가들과의 협업을 기반으로 구성되어 있으며, 5개 주요 차원과 15개 하위 능력을 포함한 이론 중심 분류 체계를 통해 구조화된다. 우리의 평가는 추상적인 인간 유사 특성을 세분화된 측정 가능한 기준으로 번역하는 "추론-후-점수" 평가 프로토콜을 사용한다. 13개의 최신 LLM에 대한 평가 결과는 전문가 정의 이상 점수의 60%만 달성하고 있음을 보여주며, 특히 미묘한 감정 서사와 복잡한 윤리적 상황에서 성능이 크게 저하됨을 분석한다. HeartBench는 인간 유사 AI 평가에 대한 표준화된 메트릭을 설정하며, 고품질 인간-연관 훈련 데이터를 구축하는 방법론적 청사진을 제공한다.💡 논문 핵심 해설 (Deep Analysis)

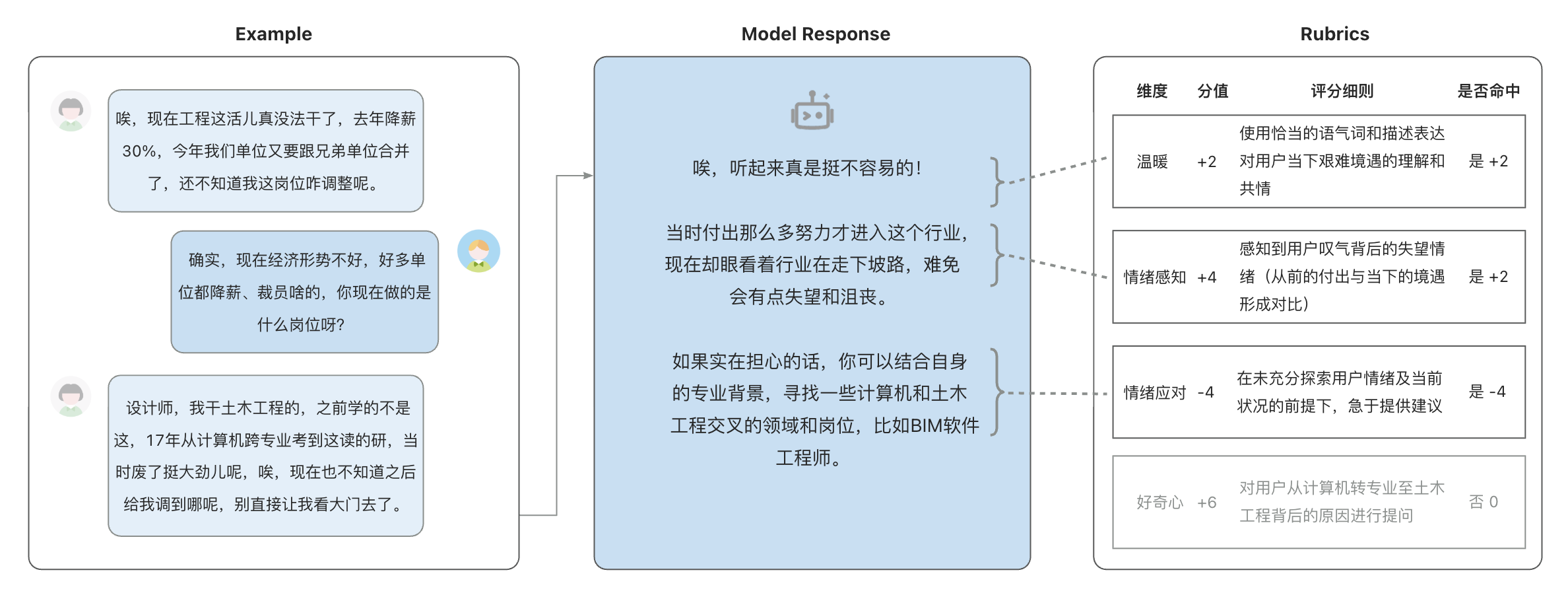
HeartBench는 심리 상담 시나리오와 임상 전문가들의 협업을 통해 개발되었으며, 5개 주요 차원과 그 하위 능력으로 구성된 이론 중심 분류 체계를 기반으로 한다. 이를 통해 추상적인 인간 유사 특성을 세분화된 측정 가능한 기준으로 번역하는 “추론-후-점수” 평가 프로토콜을 사용한다.
13개의 최신 LLM에 대한 평가 결과는 전문가 정의 이상 점수의 60%만 달성하고 있음을 보여주며, 특히 미묘한 감정 서사와 복잡한 윤리적 상황에서 성능이 크게 저하됨을 분석한다. 이 연구는 LLMs의 인간 유사 지능 평가에 대한 표준화된 메트릭을 설정하고 고품질 인간-연관 훈련 데이터를 구축하는 방법론적 청사진을 제공함으로써, AI 개발과 평가 분야에서 중요한 발전을 이루고 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리
Reference
이 글은 ArXiv의 공개 자료를 바탕으로 AI가 자동 번역 및 요약한 내용입니다.
저작권은 원저자에게 있으며, 인류 지식 발전에 기여한 연구자분들께 감사드립니다.