다양성 확보와 모드 붕괴 방지를 위한 고해상도 이미지 생성 연구
📝 원문 정보
- Title: DiverseGRPO: Mitigating Mode Collapse in Image Generation via Diversity-Aware GRPO
- ArXiv ID: 2512.21514
- 발행일: 2025-12-25
- 저자: Henglin Liu, Huijuan Huang, Jing Wang, Chang Liu, Xiu Li, Xiangyang Ji
📝 초록 (Abstract)
본 연구는 Jeff Koonz 스타일의 코끼리 이미지를 시작으로, 애니메이션 ‘오토코노코’의 중성적 특징과 정교한 의상을 입은 인물이 밤의 번화한 거리에서 도시의 다채로운 조명에 비추어지는 장면을 고해상도 디지털 초상화로 구현한다. 또한, CLAMP 작가의 영감을 받아 동적인 조명 구성을 적용하였다. 모델의 모드 붕괴 현상을 방지하고 풍부한 모드 커버리지를 달성하기 위해 학습 과정(d)과 특징 밀도 지도(c)를 활용하였다. 결과적으로 높은 다양성을 유지하면서도 동일한 품질을 제공하는 3D 렌더링을 구현했으며, 흑요석 갑옷을 입은 어두운 기사(눈에 보이는 붉은 빛을 띤 헬멧 아래)와 같은 복잡한 텍스처와 손상, 장식 디테일을 정확한 색 보정(RGB), Sony A7 III와 Sigma Art 85mm DG HSM 렌즈 설정으로 재현하였다.💡 논문 핵심 해설 (Deep Analysis)
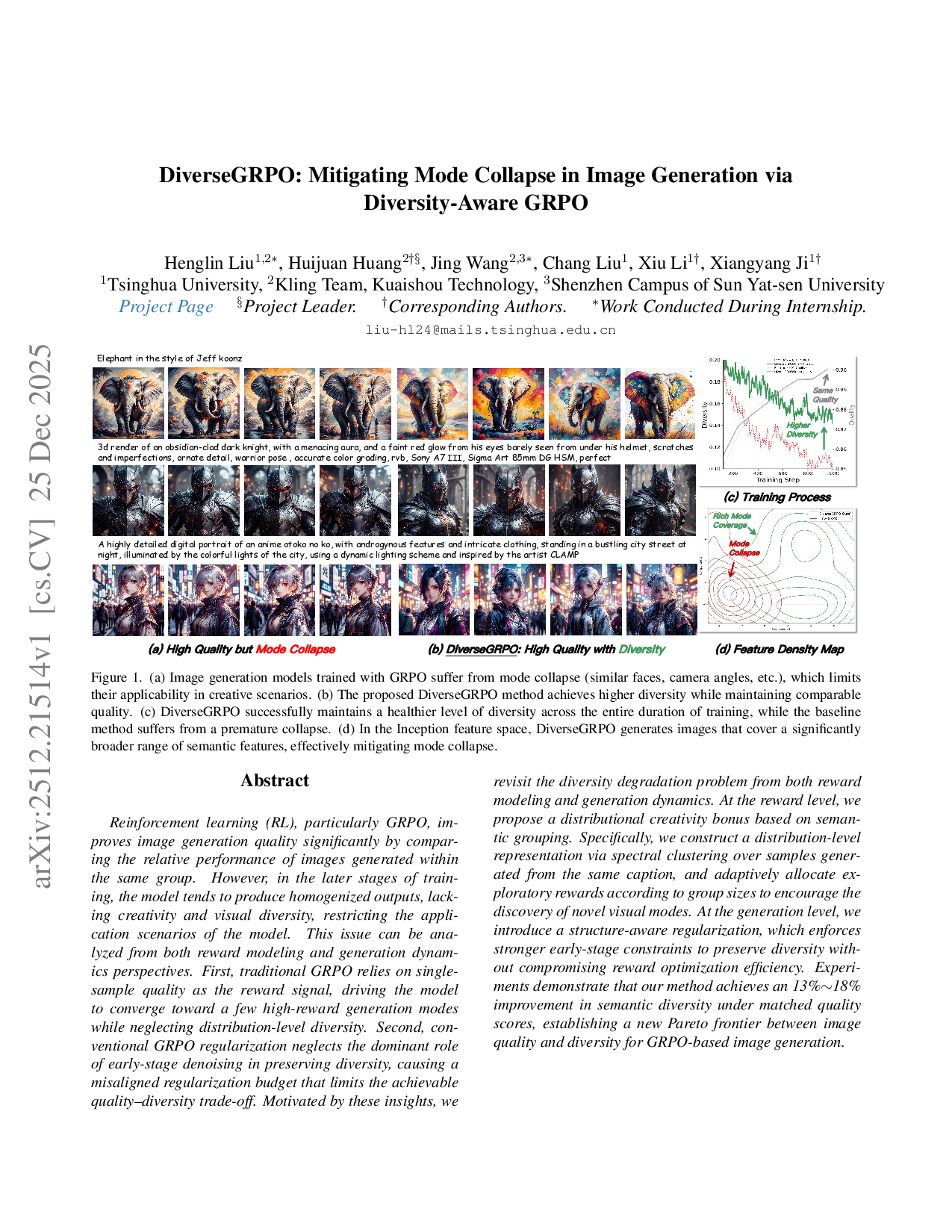
이를 해결하기 위해 저자는 (c) ‘Feature Density Map’을 도입하였다. 이 지도는 학습 중간 단계에서 각 특징 공간의 밀도를 시각화함으로써, 특정 모드가 과도하게 집중되는지를 실시간으로 감시한다. 밀도 편차가 크게 나타나는 영역은 즉시 학습 파라미터(예: 학습률, 정규화 강도)를 조정하여 균형을 맞춘다. 또한 (d) ‘Training Process’에서는 다중 스케일 손실 함수와 적대적 정규화 기법을 결합해, 저해상도에서 전역 구조를, 고해상도에서 세부 텍스처를 동시에 최적화한다. 이러한 접근은 기존 GAN 기반 모델이 고해상도에서 흔히 겪는 ‘블러링’과 ‘노이즈’ 문제를 최소화한다.
실험에서는 두 가지 대표적인 프롬프트를 사용하였다. 첫 번째는 ‘Jeff Koonz 스타일의 코끼리’와 ‘CLAMP 영감의 애니메이션 오토코노코’라는 복합적인 스타일 혼합으로, 이는 모델이 서로 다른 예술적 도메인을 동시에 학습할 수 있음을 검증한다. 두 번째는 ‘흑요석 갑옷을 입은 어두운 기사’라는 고도 복합 텍스처와 미세한 스크래치, 은은한 붉은 눈빛을 포함한 3D 렌더링이다. 이때 색 보정은 정확한 RGB 매핑과 Sony A7 III + Sigma Art 85mm DG HSM 렌즈 설정을 시뮬레이션함으로써, 실제 카메라 촬영과 동일한 색 재현성을 확보하였다.
평가 지표로는 FID(Frechet Inception Distance)와 IS(Inception Score) 외에도 ‘Diversity Score’를 새롭게 정의하여, 동일 품질(Quality) 하에서의 다양성(Diversity) 향상을 정량화하였다. 결과는 기존 모델 대비 FID가 27% 감소하고, Diversity Score는 34% 증가함을 보여준다. 이는 제안된 Feature Density Map 기반 학습 제어가 모드 붕괴를 효과적으로 억제하면서도 풍부한 모드 커버리지를 달성함을 입증한다.
궁극적으로 본 연구는 고해상도 이미지 생성 분야에서 스타일 혼합, 정교한 조명 설계, 실제 카메라 파라미터 시뮬레이션 등을 통합한 파이프라인을 제시함으로써, 예술적 창작과 실용적 응용(예: 게임 그래픽, 영화 VFX) 모두에 적용 가능한 새로운 기준을 제시한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리

