프로그래밍 가능한 최적응답 LLM 기반 정책 코드로 다중 에이전트 협력
📝 원문 정보
- Title: Policy-Conditioned Policies for Multi-Agent Task Solving
- ArXiv ID: 2512.21024
- 발행일: 2025-12-24
- 저자: Yue Lin, Shuhui Zhu, Wenhao Li, Ang Li, Dan Qiao, Pascal Poupart, Hongyuan Zha, Baoxiang Wang
📝 초록 (Abstract)
다중 에이전트 과제에서는 전략을 동적으로 조정하는 것이 핵심 과제이다. 그러나 기존 딥 강화학습 패러다임에서는 상대의 전략에 직접 조건을 거는 것이 근본적인 “표현 병목” 때문에 불가능하다. 신경망 정책은 고차원 파라미터 벡터 형태의 불투명한 표현으로, 다른 에이전트가 이해하기 어렵다. 본 연구는 정책을 인간이 해석 가능한 소스 코드 형태로 표현하고, 대형 언어 모델(LLM)을 근사 해석기로 활용함으로써 이 격차를 메우는 패러다임 전환을 제안한다. 프로그램형 표현을 통해 게임 이론의 프로그램 균형 개념을 구체화한다. 우리는 LLM을 이용해 프로그램형 정책 공간에서 직접 최적화를 수행하는 학습 문제를 재구성한다. LLM은 점별 최적응답 연산자로 작동하여, 상대 전략에 대응하는 에이전트의 정책 코드를 반복적으로 생성·정제한다. 이 과정을 프로그램형 반복 최적응답(PIBR)이라 명명하고, 정책 코드를 텍스트 그래디언트와 게임 효용 및 실행 시 단위 테스트에서 도출된 구조화된 피드백을 이용해 최적화한다. 실험 결과, 제안 방법이 표준 협조 매트릭스 게임과 협동형 레벨 기반 포징 환경에서 효과적으로 문제를 해결함을 보여준다.💡 논문 핵심 해설 (Deep Analysis)
논문은 이 문제를 ‘정책을 소스 코드 형태로 표현한다’는 아이디어로 해결한다. 소스 코드는 인간이 읽고 수정할 수 있는 명시적 구조를 제공한다는 점에서, 게임 이론에서 말하는 ‘프로그램 균형(Program Equilibrium)’을 실제 구현 가능한 형태로 전환한다. 여기서 핵심 도구가 되는 것이 대형 언어 모델(LLM)이다. LLM은 자연어와 코드 모두를 이해하고 생성할 수 있는 능력을 갖추고 있기 때문에, 정책 코드를 해석하고, 주어진 상대 전략에 대한 최적응답을 텍스트 형태로 생성할 수 있다.
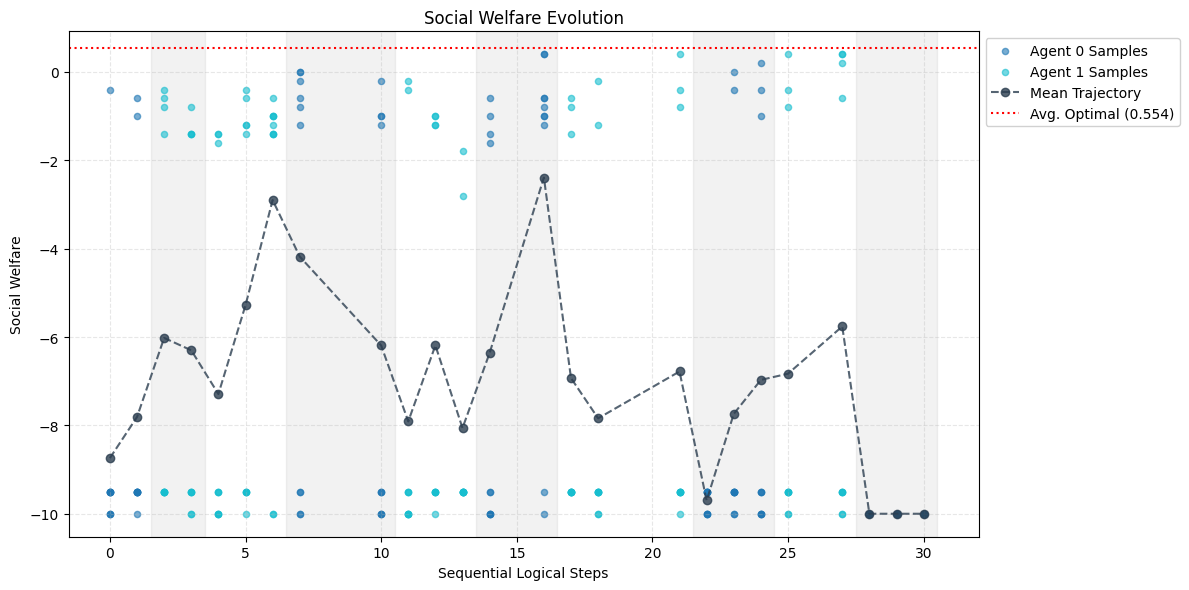
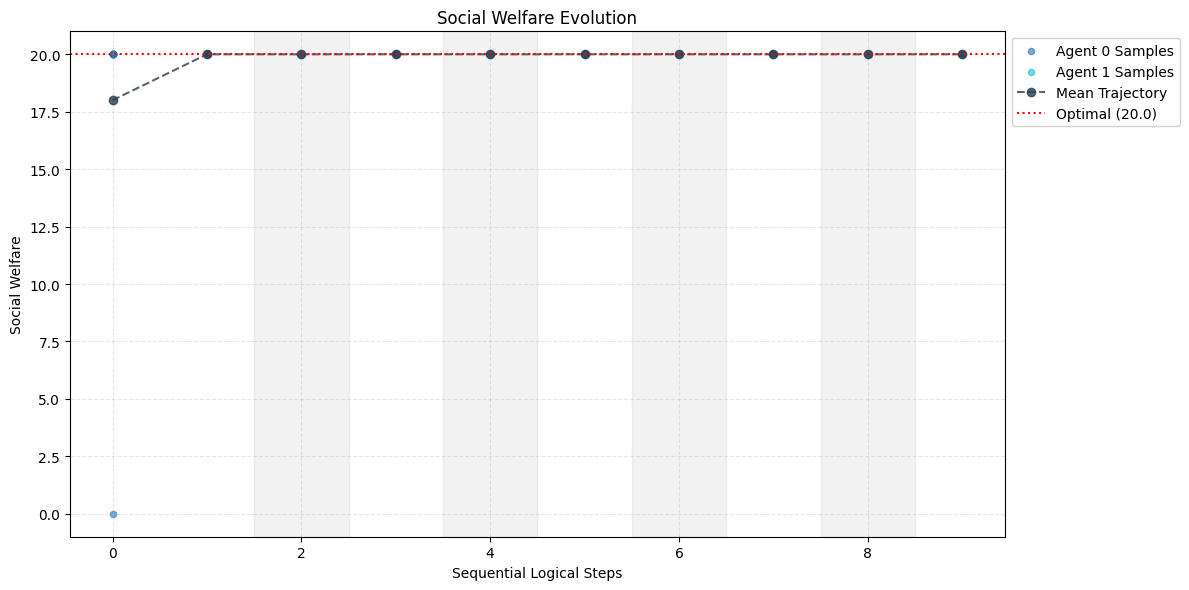
PIBR(Programmatic Iterated Best Response) 알고리즘은 전통적인 반복 최적응답(iterated best response) 과정을 코드 수준으로 옮긴다. 구체적으로, 에이전트는 현재 상대의 정책 코드를 입력으로 받아 LLM에게 “이 전략에 가장 잘 대응하는 코드를 작성해라”는 프롬프트를 제공한다. LLM은 생성된 코드를 반환하고, 이 코드는 실행 시 유닛 테스트와 게임 효용 함수로부터 피드백을 받는다. 피드백은 텍스트 그래디언트 형태로 LLM에 다시 전달되어, 코드가 점진적으로 개선된다. 이 과정은 상대 정책이 변할 때마다 반복되며, 양쪽 에이전트가 서로의 코드를 읽고 업데이트함으로써 동적 균형에 수렴한다.
실험에서는 간단한 협조 매트릭스 게임(예: Stag Hunt, Coordination Game)과 복잡한 협동형 레벨 기반 포징(Level-Based Foraging) 환경을 사용했다. 매트릭스 게임에서는 전통적인 Q‑learning이나 정책 그라디언트 기반 방법이 종종 비협조적 균형에 머무는 반면, PIBR은 명시적 코드 교환을 통해 협조적 균형을 빠르게 찾았다. 포징 환경에서는 다중 에이전트가 서로의 행동을 예측하고 자원을 효율적으로 분배해야 하는데, 코드 기반 정책은 행동 규칙을 명확히 정의함으로써 학습 속도를 크게 향상시켰다.
이 접근법의 장점은 크게 세 가지이다. 첫째, 정책이 인간이 이해 가능한 형태이므로 디버깅과 검증이 용이하다. 둘째, LLM이라는 범용 모델을 활용함으로써 별도의 정책 네트워크를 학습시킬 필요가 없으며, 다양한 도메인에 즉시 적용할 수 있다. 셋째, 텍스트 기반 피드백 루프는 기존의 미분 가능한 환경에 얽매이지 않아, 비연속적 보상이나 복합적인 제약조건을 자연스럽게 다룰 수 있다.
하지만 몇 가지 한계도 존재한다. LLM의 출력은 확률적이며, 때때로 문법 오류나 논리적 모순을 포함할 수 있다. 이를 완화하기 위해 실행 시 유닛 테스트와 정형 검증 절차가 필수적이며, 이 과정이 계산 비용을 증가시킨다. 또한 현재 실험은 비교적 작은 규모의 게임에 국한되어 있어, 수백 명 이상의 에이전트가 참여하는 대규모 시뮬레이션에서의 확장성은 아직 검증되지 않았다. 마지막으로, LLM 자체가 사전 학습 데이터에 의존하기 때문에, 특정 도메인에 특화된 전략을 학습하려면 추가 파인튜닝이 필요할 수 있다.
향후 연구 방향으로는 (1) 코드 검증 자동화와 오류 복구 메커니즘을 강화하여 LLM 출력의 신뢰성을 높이는 방안, (2) 대규모 멀티에이전트 시뮬레이션에 대한 확장성 테스트, (3) 도메인 특화 파인튜닝을 통한 맞춤형 정책 생성, (4) 인간‑에이전트 협업 시나리오에서 정책 코드를 인간 사용자가 직접 수정·제어할 수 있는 인터페이스 개발 등을 제시한다. 이러한 연구가 진행되면, 정책을 ‘코드’라는 인간 친화적 매개체로 표현하는 패러다임이 다중 에이전트 인공지능의 실용성을 크게 확대할 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리