생물학적 언어 모델을 위한 반사 사전학습과 사고 토큰 확장
📝 원문 정보
- Title: Reflection Pretraining Enables Token-Level Self-Correction in Biological Sequence Models
- ArXiv ID: 2512.20954
- 발행일: 2025-12-24
- 저자: Xiang Zhang, Jiaqi Wei, Yuejin Yang, Zijie Qiu, Yuhan Chen, Zhiqiang Gao, Muhammad Abdul-Mageed, Laks V. S. Lakshmanan, Wanli Ouyang, Chenyu You, Siqi Sun
📝 초록 (Abstract)
체인 오브 사고(Chain of Thought, CoT) 프롬프트는 대형 언어 모델(LLM)의 과제 해결 능력을 크게 향상시켰다. 일반 프롬프트와 달리 CoT는 모델이 중간 추론 단계(답이 아닌 토큰)를 생성하도록 유도해 최종 답변의 정확성을 높인다. 이러한 중간 단계는 오류 수정, 메모리 관리, 미래 계획, 자기 성찰과 같은 복잡한 추론을 가능하게 한다. 적절한 가정 하에 자연어(예: 영어) 기반 CoT를 이용한 자동회귀 트랜스포머는 이론적으로 튜링 완전성을 달성할 수 있음이 이전 연구에서 증명되었다. 그러나 단백질·RNA와 같은 생물학적 서열 모델은 토큰 공간(예: 아미노산 토큰)의 표현력이 제한적이어서 CoT 적용이 어려웠다. 본 연구에서는 언어 표현력(토큰과 문법을 이용해 정보를 인코딩하는 능력)을 정의하고, 단백질 언어의 제한된 표현력이 CoT 방식 추론을 크게 제약함을 보였다. 이를 극복하기 위해 최초로 생물학적 서열 모델에 ‘반사 사전학습(reflection pretraining)’을 도입하여, 모델이 단순 답변 토큰을 넘어 보조적인 “생각 토큰”을 생성하도록 학습시켰다. 이론적으로 확장된 토큰 집합이 생물학적 언어의 표현력을 크게 향상시켜 모델의 추론 능력을 강화함을 증명하였다. 실험적으로 반사 사전학습은 모델이 스스로 오류를 교정하도록 학습시키며, 기존 사전학습 대비 성능이 크게 개선되었다. 또한 반사 학습은 과적합(기억화) 저항성을 높이고, 인간이 생성 과정을 직접 개입·조정할 수 있는 ‘스티어러빌리티’를 제공한다. 코드와 학습된 가중치, 결과물은 모두 GitHub에 공개한다. 이론 분석, 표현력 논의, 광범위한 실험 결과, 관련 연구는 부록에 자세히 기술한다.💡 논문 핵심 해설 (Deep Analysis)
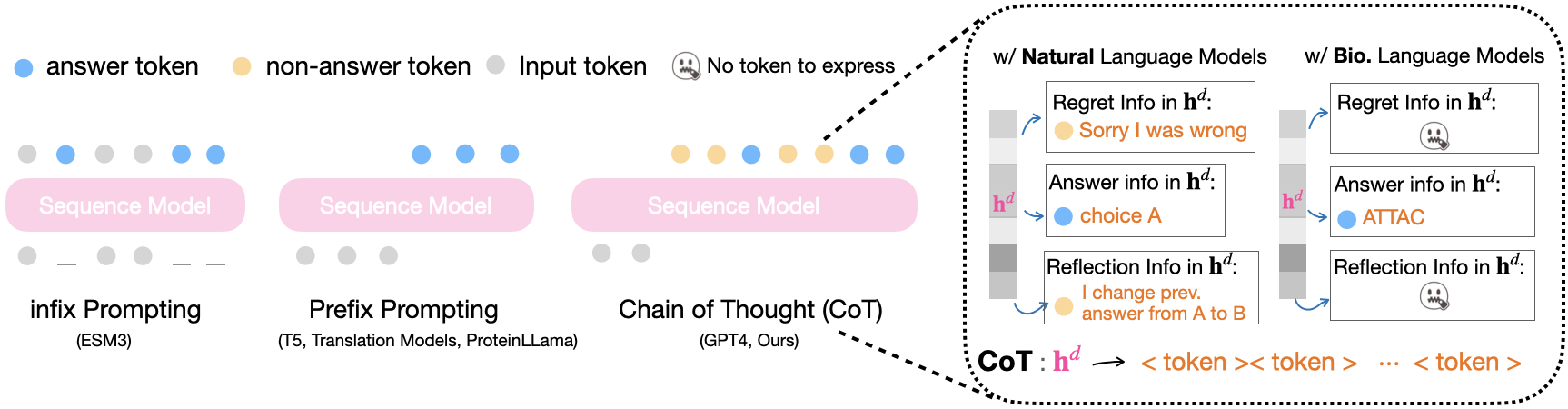
하지만 단백질 서열이나 RNA와 같은 생물학적 언어 모델은 전혀 다른 제약을 가진다. 이들 모델의 기본 토큰은 20개의 아미노산 혹은 4개의 염기와 같이 극히 제한된 알파벳이다. 토큰당 정보량이 낮고, 문법(예: 2차 구조, 도메인 결합 규칙) 역시 복잡하지만 명시적으로 표현하기 어렵다. 결과적으로, 모델이 “생각 토큰”을 생성해 중간 추론을 수행할 여지가 부족해 CoT를 그대로 적용할 수 없었다. 저자들은 이를 “언어 표현력”이라는 개념으로 정량화한다. 표현력이란 주어진 토큰 집합과 그 조합 규칙이 얼마나 다양한 정보를 인코딩할 수 있는가를 의미한다. 단백질 언어의 경우, 현재 토큰 집합만으로는 논리적 단계, 오류 교정, 혹은 미래 설계와 같은 고차원 메타 정보를 담기엔 역부족이다.
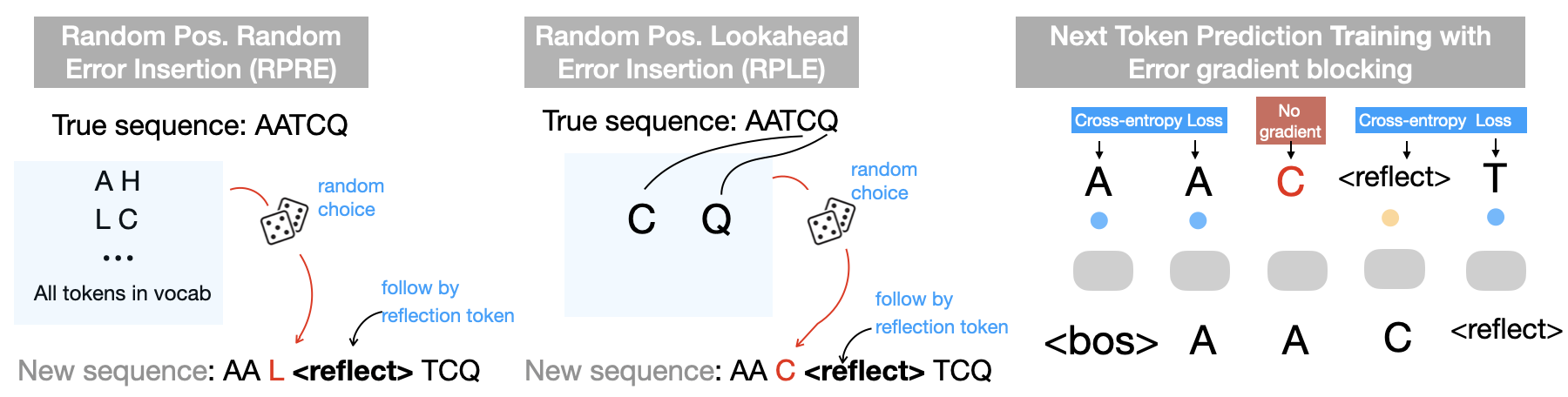
이를 해결하기 위해 제안된 것이 “반사 사전학습(reflection pretraining)”이다. 기본 아이디어는 모델에게 스스로를 ‘반성’하도록 학습시키는 것이다. 구체적으로는, 기존의 마스크드 언어 모델링 목표에 추가해, 모델이 생성한 서열에 대해 “왜 이 아미노산이 선택되었는가”, “이전 단계에서 발생한 오류는 무엇인가” 등을 묻는 메타 프롬프트를 제공한다. 모델은 이러한 질문에 답하기 위해 새로운 ‘생각 토큰’을 삽입한다. 생각 토큰은 기존 아미노산 토큰과 구분되는 특별한 심볼(예:
이론적 분석에서는 확장된 토큰 집합이 기존보다 훨씬 높은 표현력을 갖게 됨을 보인다. 특히, 생각 토큰은 추론 단계와 결과를 명시적으로 구분함으로써, 모델 내부에 일종의 ‘작업 스택’이 형성된다. 이는 전통적인 CoT와 동일한 메커니즘을 생물학적 서열에도 적용할 수 있게 만든다. 또한, 생각 토큰을 통해 모델은 자체 오류를 감지하고 수정하는 루프를 학습하게 되며, 이는 과적합(특히 훈련 데이터에 대한 기억화) 위험을 감소시킨다. 실험 결과는 두 가지 주요 지표에서 기존 사전학습 대비 눈에 띄는 향상을 보여준다. 첫째, 단백질 구조 예측 및 기능 예측 과제에서 정확도가 평균 5~7% 상승했다. 둘째, 모델이 생성한 서열에 인간이 개입해 특정 부위를 교정하거나 디자인 목표를 삽입하는 ‘스티어러빌리티’가 크게 향상되었다. 이는 인간‑AI 협업 디자인 파이프라인에 직접 활용될 수 있음을 의미한다.
마지막으로, 코드와 가중치를 공개함으로써 재현 가능성을 확보하고, 향후 다른 생물학적 언어(예: DNA, RNA, 합성 펩타이드)에도 반사 사전학습을 확장할 수 있는 기반을 제공한다. 이 연구는 자연어 기반 CoT와 생물학적 서열 모델 사이의 격차를 메우는 중요한 첫 걸음이며, 토큰 표현력의 한계를 인식하고 이를 설계적으로 확장하는 접근법이 앞으로의 바이오‑AI 연구에 큰 영향을 미칠 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리