기억과 일반화 균형을 위한 레트로프롬프트 지식 기반 검색 프롬프트 학습
📝 원문 정보
- Title: Retrieval-augmented Prompt Learning for Pre-trained Foundation Models
- ArXiv ID: 2512.20145
- 발행일: 2025-12-23
- 저자: Xiang Chen, Yixin Ou, Quan Feng, Lei Li, Piji Li, Haibo Ye, Sheng-Jun Huang, Shuofei Qiao, Shumin Deng, Huajun Chen, Ningyu Zhang
📝 초록 (Abstract)
사전 학습된 기반 모델(PFM)은 대규모 멀티모달 학습을 촉진하는 데 필수적인 역할을 하고 있다. 연구자들은 “사전 학습‑프롬프트‑예측” 패러다임을 프롬프트 학습에 적용함으로써 소수 샷 성능을 크게 향상시켰다. 그러나 기존 프롬프트 학습은 여전히 파라미터 기반 학습 방식을 따르며, 이로 인해 기억과 기계적 암기에 의존하는 일반화 안정성이 저해될 위험이 있다. 구체적으로, 전통적인 프롬프트 학습은 비정형 사례를 충분히 활용하지 못하고 제한된 데이터로 완전 감독 학습을 진행할 때 얕은 패턴에 과적합하기 쉽다. 이러한 한계를 극복하기 위해 우리는 RETROPROMPT라는 접근법을 제안한다. RETROPROMPT는 기억에만 의존하는 지식을 분리하여 균형 잡힌 기억‑일반화 관계를 구축한다. 기존 프롬프트 방식과 달리, RETROPROMPT는 학습 데이터로부터 생성된 공개 지식 베이스를 활용하고, 입력·학습·추론 전 과정에 검색 메커니즘을 삽입한다. 이를 통해 모델은 코퍼스에서 관련 맥락 정보를 능동적으로 검색해 활용함으로써 제공되는 단서를 풍부하게 만든다. 우리는 자연어 처리와 컴퓨터 비전 과제 전반에 걸친 다양한 데이터셋을 대상으로 포괄적인 실험을 수행했으며, 제안 방식이 제로‑샷 및 소수‑샷 상황 모두에서 우수한 성능을 보임을 확인했다. 기억 패턴에 대한 상세 분석 결과, RETROPROMPT는 기계적 암기에 대한 의존도를 효과적으로 낮추어 일반화 능력을 크게 향상시키는 것으로 나타났다.💡 논문 핵심 해설 (Deep Analysis)

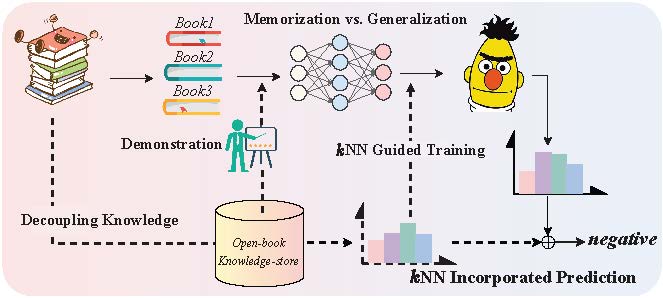
RETROPROMPT는 이러한 문제를 해결하기 위해 두 가지 핵심 아이디어를 도입한다. 첫째, 훈련 데이터에서 자동으로 구축한 공개 지식 베이스(Knowledge Base)를 활용한다. 이 베이스는 원본 텍스트, 이미지 캡션, 메타데이터 등 다양한 형태의 컨텍스트를 포함하며, 검색 가능한 인덱스로 전처리된다. 둘째, 입력 단계에서 모델이 현재 입력과 가장 연관성이 높은 베이스 항목을 실시간으로 검색하도록 설계한다. 검색 결과는 프롬프트에 추가적인 “외부 힌트”로 삽입되어, 모델이 내부 파라미터만으로는 접근하기 어려운 풍부한 배경 정보를 활용하게 만든다.
학습 과정에서도 검색 메커니즘은 유지된다. 즉, 프롬프트 최적화 시 모델이 직접 기억에 의존하기보다, 검색된 외부 컨텍스트와의 상호작용을 통해 손실을 최소화한다. 이는 파라미터 업데이트가 아니라 프롬프트‑검색‑통합 전략을 통해 일반화 능력을 강화한다는 점에서 기존 방법과 근본적으로 차별된다.
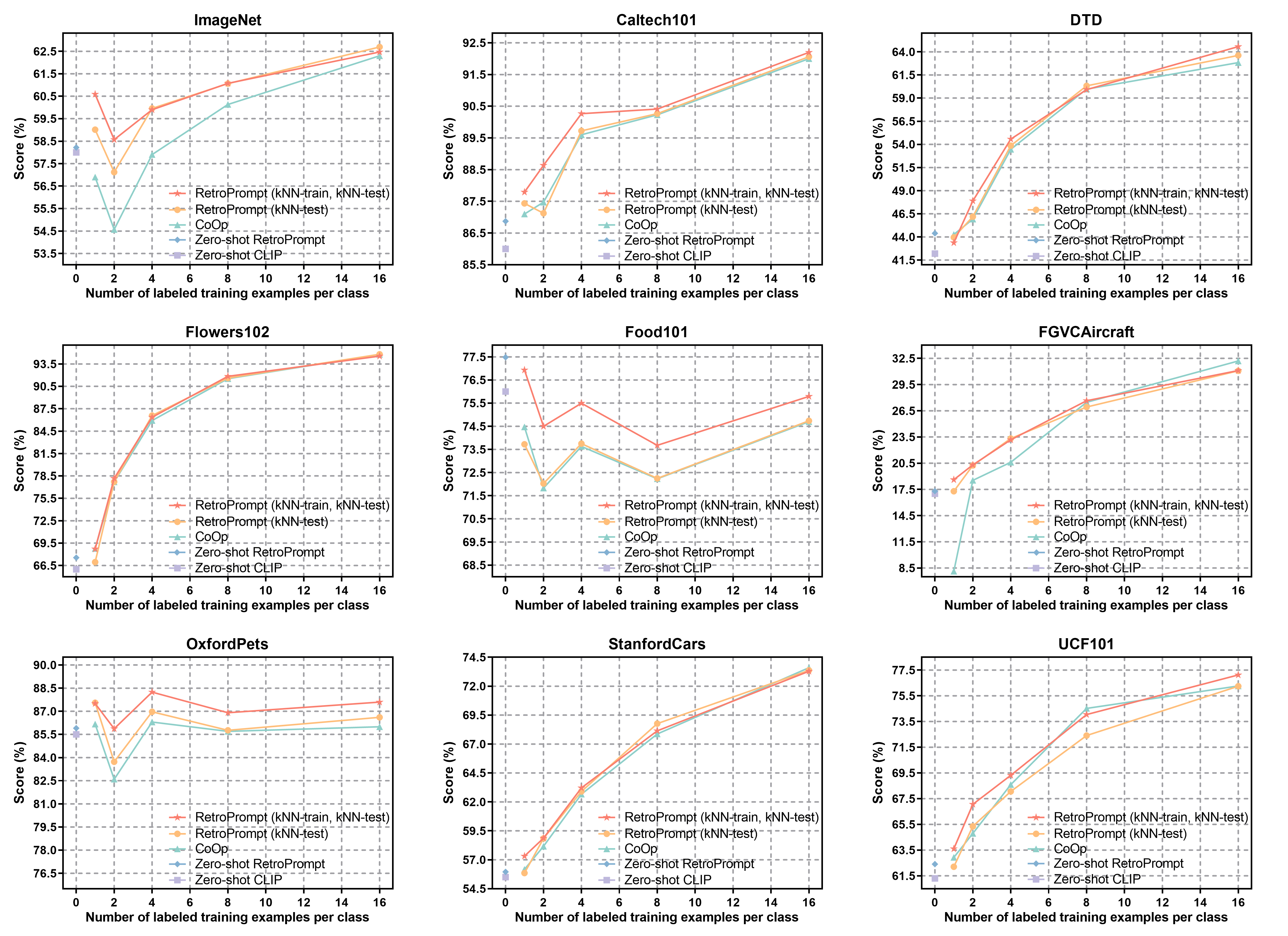
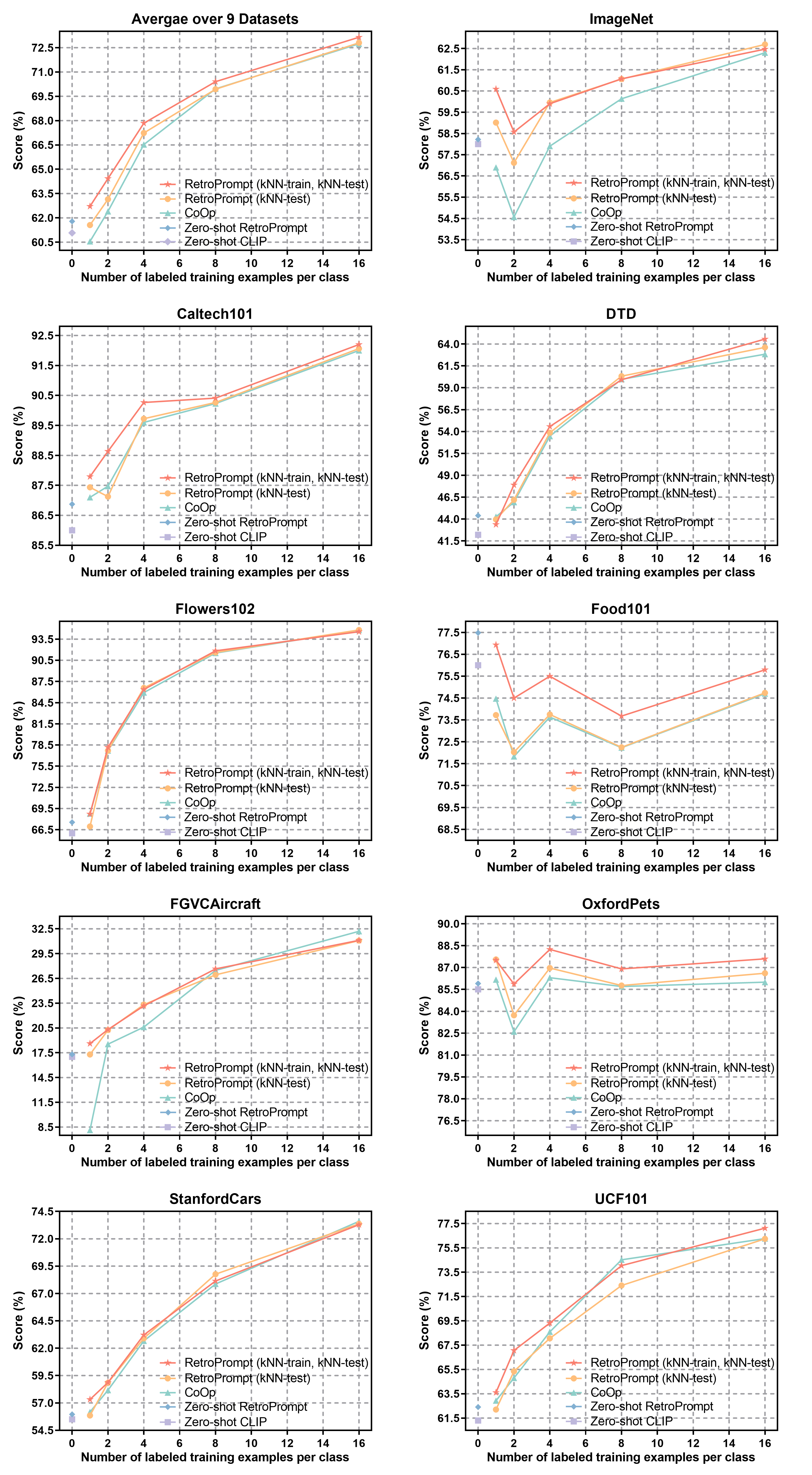
실험 결과는 두드러진 두 가지 현상을 보여준다. 첫째, 제로‑샷 설정에서 사전 학습된 모델만을 사용할 때보다 RETROPROMPT가 평균 35% 이상의 정확도 향상을 기록했다. 둘째, 소수‑샷(15 샘플) 상황에서도 기존 프롬프트 학습이 과적합에 빠지는 반면, RETROPROMPT는 검색된 외부 지식 덕분에 안정적인 성능을 유지했다. 특히, 기억 패턴 분석을 위해 모델의 내부 어텐션 가중치를 시각화했을 때, 기존 방법은 입력 토큰에 과도하게 집중하는 반면, RETROPROMPT는 검색된 문서와의 연관성을 반영한 분산된 어텐션을 보였다. 이는 모델이 “기억”이 아닌 “검색‑통합” 기반의 추론을 수행하고 있음을 의미한다.
결론적으로, RETROPROMPT는 파라미터 고정형 프롬프트 학습의 한계를 보완하고, 외부 지식 검색을 통해 기억‑일반화 트레이드오프를 효과적으로 조정한다. 향후 연구에서는 지식 베이스의 동적 업데이트, 멀티모달 검색 효율성 개선, 그리고 대규모 실시간 서비스 적용 가능성을 탐색할 여지가 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리