비접촉 영상과 주변 센서의 분해형 시공간 정렬 DETACH 프레임워크
📝 원문 정보
- Title: DETACH : Decomposed Spatio-Temporal Alignment for Exocentric Video and Ambient Sensors with Staged Learning
- ArXiv ID: 2512.20409
- 발행일: 2025-12-23
- 저자: Junho Yoon, Jaemo Jung, Hyunju Kim, Dongman Lee
📝 초록 (Abstract)
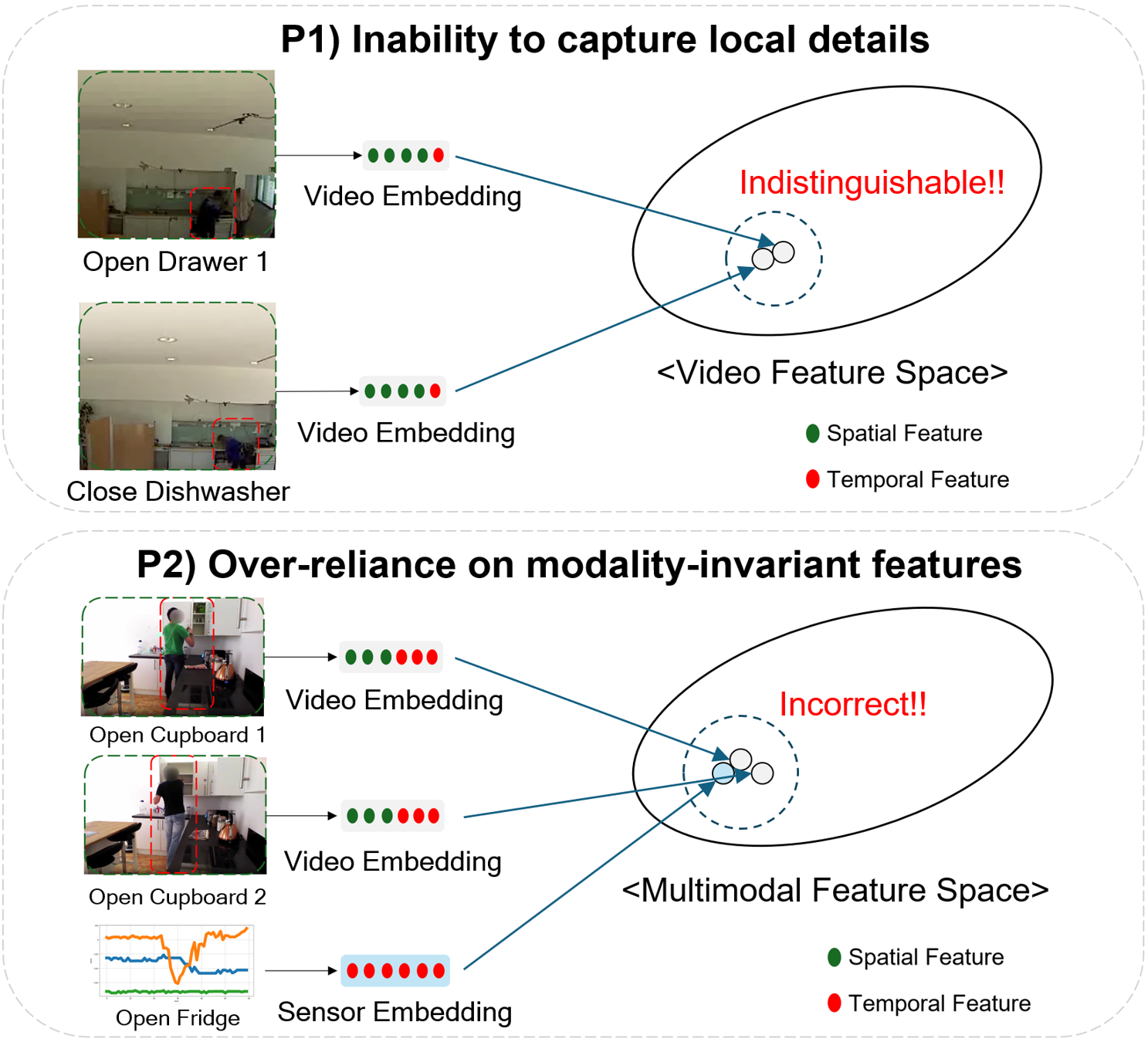
자신의 시점 영상을 웨어러블 센서와 정렬하는 방식은 행동 인식에 유망하지만 사용자 불편, 프라이버시 문제, 확장성 한계가 있다. 본 연구는 비접촉(엑소센트릭) 영상과 주변 환경 센서를 이용한 비침습적·대규모 가능한 대안을 탐구한다. 기존의 자기시점‑웨어러블 접근은 전체 시퀀스를 하나의 통합 표현으로 인코딩하는 전역 정렬 방식을 주로 사용하지만, 이는 (P1) 미세 움직임 등 지역적 세부 정보를 포착하지 못하고, (P2) 모달리티에 무관한 시간 패턴에 과도하게 의존해 의미적 맥락이 다른 행동을 잘못 정렬한다는 두 문제에 직면한다. 이를 해결하기 위해 우리는 DETACH라는 분해형 시공간 프레임워크를 제안한다. 명시적 분해를 통해 지역 세부 정보를 보존하고, 온라인 클러스터링을 통해 발견된 센서‑공간 특징을 활용해 의미적 기반을 제공한다. 정렬 단계는 먼저 상호 감독을 통한 공간 대응을 설정하고, 이어서 공간‑시간 가중 대비 손실을 적용해 쉬운 부정, 어려운 부정, 그리고 오류 부정을 적응적으로 처리한다. Opportunity++와 HWU‑USP 데이터셋에 대한 다양한 다운스트림 작업 실험에서, 기존 자기시점‑웨어러블 기반 방법들을 크게 능가하는 성능 향상을 확인하였다.💡 논문 핵심 해설 (Deep Analysis)
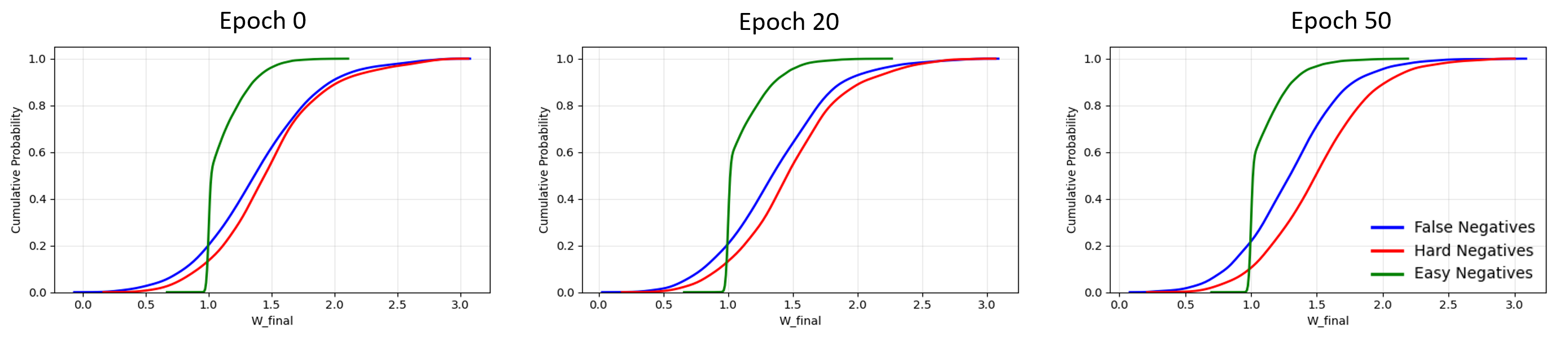
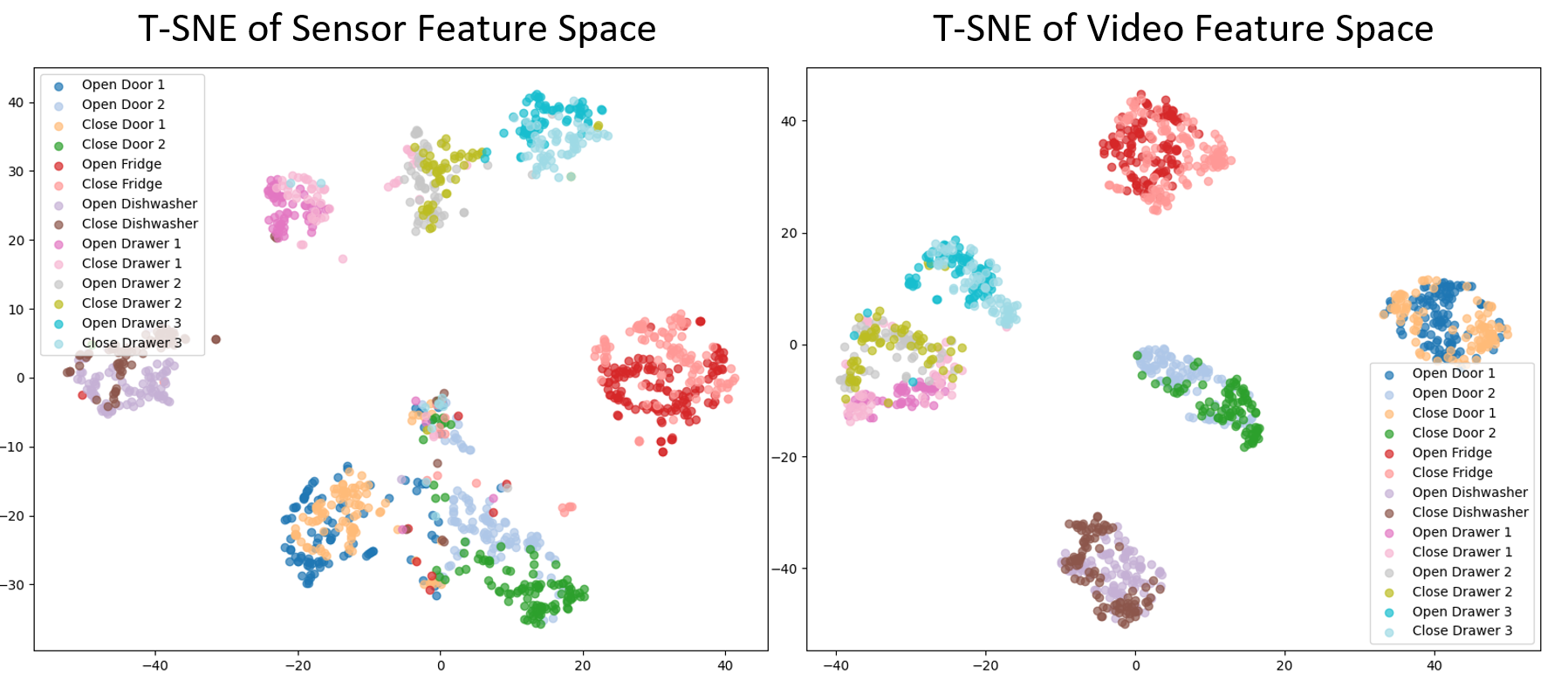
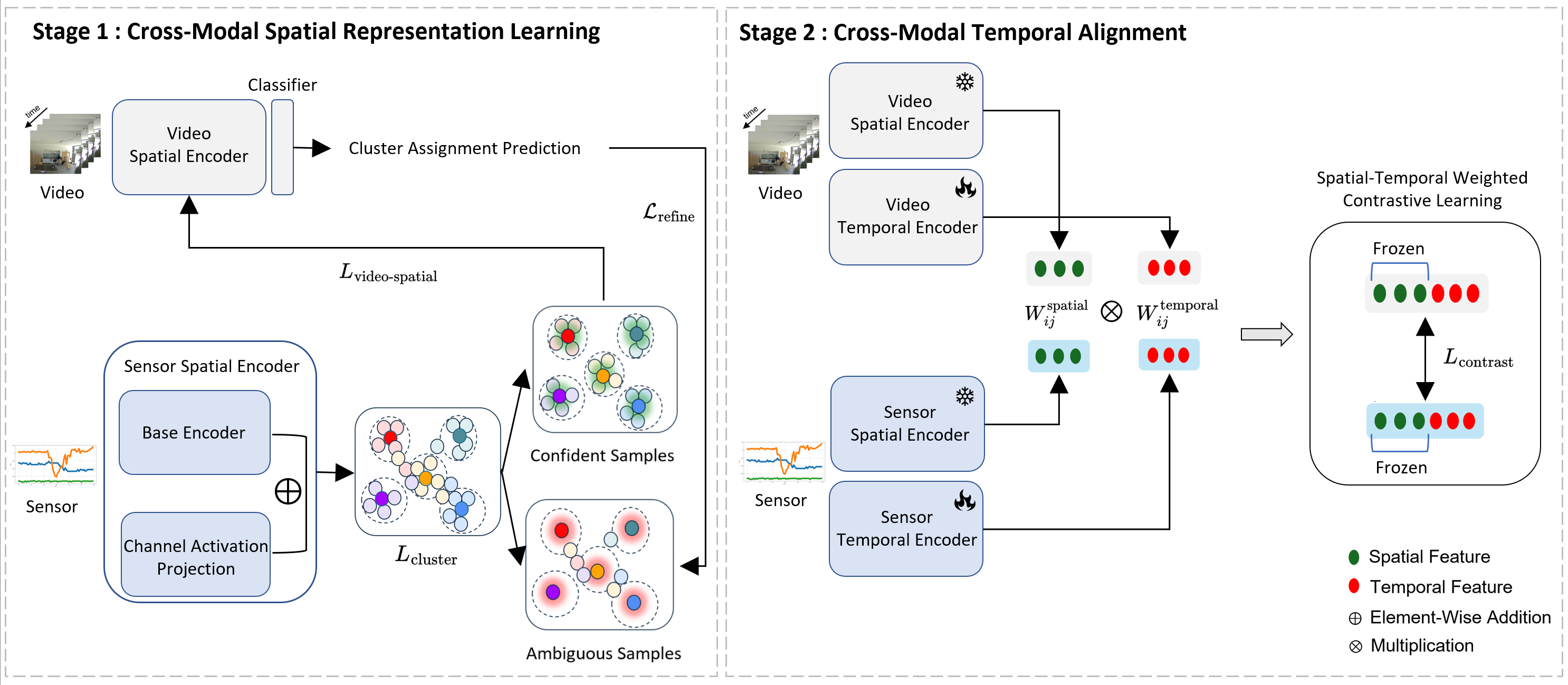
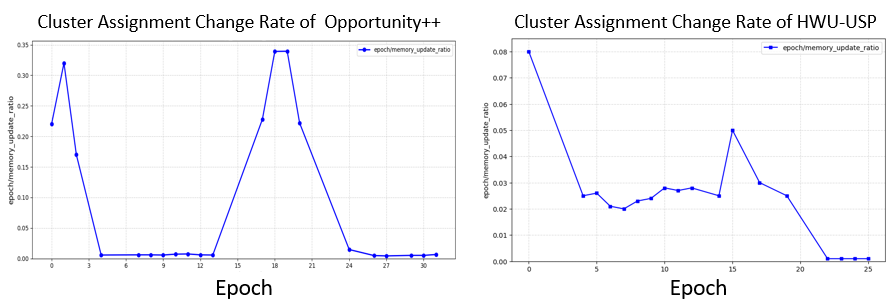
논문이 제안하는 DETACH 프레임워크는 이러한 문제를 구조적으로 해결한다. 먼저 입력 데이터를 ‘공간’과 ‘시간’ 차원으로 명시적으로 분해한다. 공간 차원에서는 영상 프레임과 주변 센서(예: 라이다, 초음파, 환경 온도 등)의 위치 정보를 별도로 인코딩하고, 온라인 클러스터링을 통해 센서 데이터 내에서 의미 있는 ‘센서‑공간 특징’을 자동으로 추출한다. 이러한 특징은 특정 환경 맥락(예: 주방, 사무실)이나 물체와의 상호작용을 반영하므로, 행동의 시맨틱 정보를 제공한다.
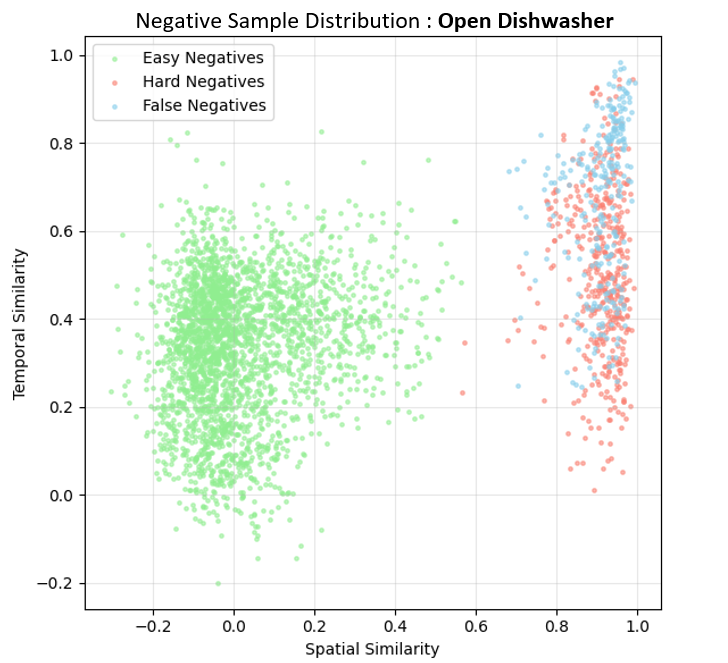
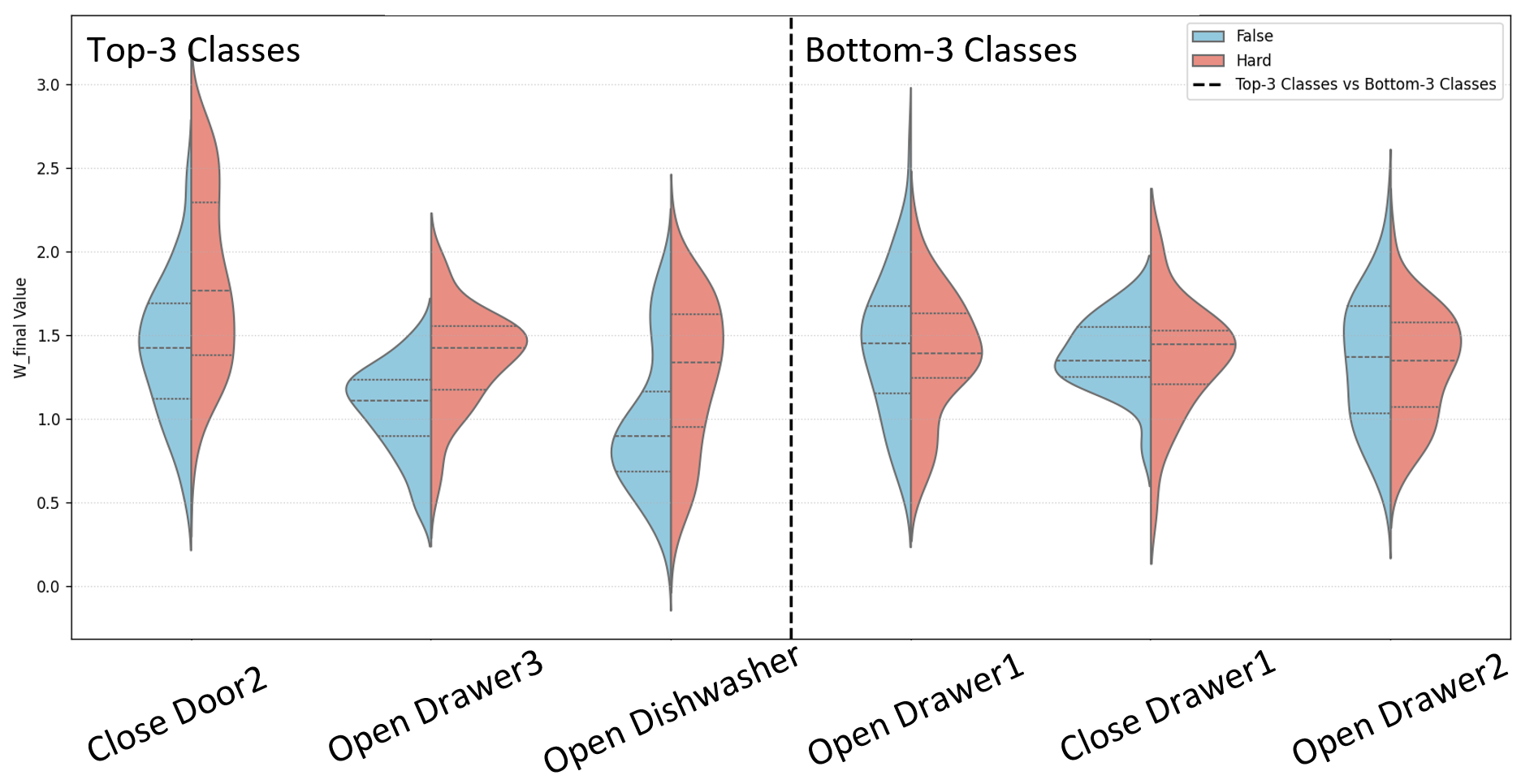
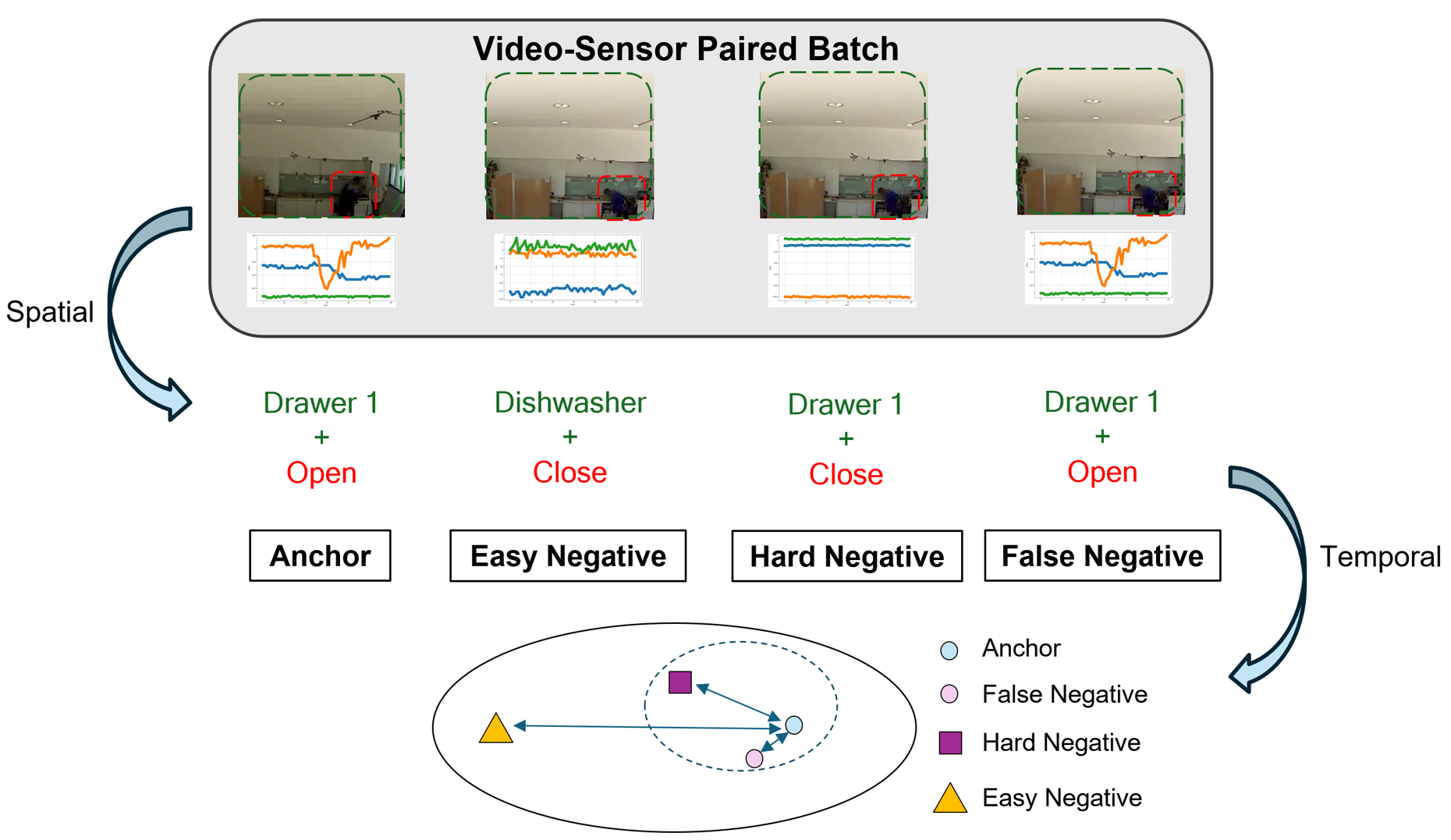
다음 단계인 정렬 과정은 두 단계로 구성된다. 첫 번째 단계는 상호 감독(mutual supervision) 메커니즘을 이용해 공간적 대응을 학습한다. 즉, 영상의 특정 영역과 센서 클러스터가 서로를 지도함으로써, 동일한 물리적 현상을 두 모달리티가 공유하도록 강제한다. 두 번째 단계에서는 ‘공간‑시간 가중 대비 손실(spatial‑temporal weighted contrastive loss)’을 도입한다. 이 손실은 기존 대비 학습(contrastive learning)의 아이디어를 확장해, (1) 쉬운 부정(easy negatives) – 명백히 다른 행동, (2) 어려운 부정(hard negatives) – 시간 패턴은 유사하지만 공간적 맥락이 다른 경우, (3) 오류 부정(false negatives) – 실제 같은 행동이지만 클러스터링 오류로 인해 다른 클래스로 오인된 경우를 각각 가중치로 조절한다. 이를 통해 모델은 미묘한 차이를 구분하면서도, 잡음에 강인한 정렬을 학습한다.
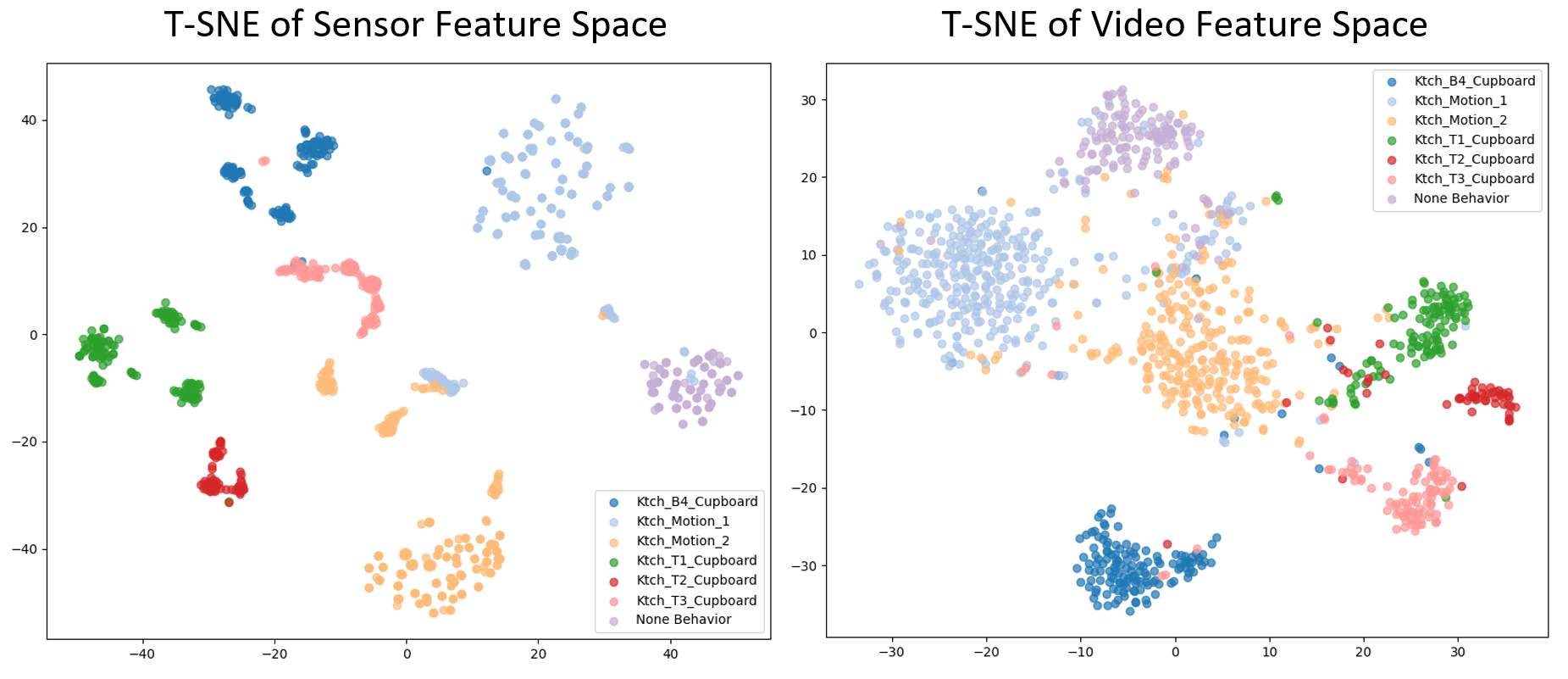
실험에서는 대표적인 실내 행동 데이터셋인 Opportunity++와 대규모 실생활 데이터셋인 HWU‑USP를 사용해, 행동 인식, 행동 예측, 그리고 전이 학습 등 여러 다운스트림 태스크에서 기존 egocentric‑wearable 기반 베이스라인을 크게 능가하는 결과를 보였다. 특히, 미세 동작 구분과 컨텍스트 의존적 행동 구분에서 평균 8~12% 이상의 정확도 향상이 관찰되었다. 이는 비접촉 영상과 주변 센서의 조합이 실제 서비스 환경에서 착용형 디바이스를 대체할 수 있는 실용적 가능성을 시사한다.
요약하면, DETACH는 (1) 지역적 세부 정보를 보존하는 분해형 설계, (2) 센서‑공간 특징을 통한 의미적 정렬, (3) 정교한 대비 손실을 통한 정렬 정밀도 향상이라는 세 축을 통해, 기존 전역 정렬 방식의 한계를 근본적으로 극복한다. 이는 향후 비침습적 행동 인식 시스템, 스마트 환경 모니터링, 그리고 프라이버시를 중시하는 인간‑컴퓨터 인터랙션 분야에 중요한 전환점을 제공할 것으로 기대된다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리