대규모 암 데이터 자동 추출을 위한 에이전트 기반 LLM 프레임워크
📝 원문 정보
- Title: HARMON-E: Hierarchical Agentic Reasoning for Multimodal Oncology Notes to Extract Structured Data
- ArXiv ID: 2512.19864
- 발행일: 2025-12-22
- 저자: Shashi Kant Gupta, Arijeet Pramanik, Jerrin John Thomas, Regina Schwind, Lauren Wiener, Avi Raju, Jeremy Kornbluth, Yanshan Wang, Zhaohui Su, Hrituraj Singh
📝 초록 (Abstract)
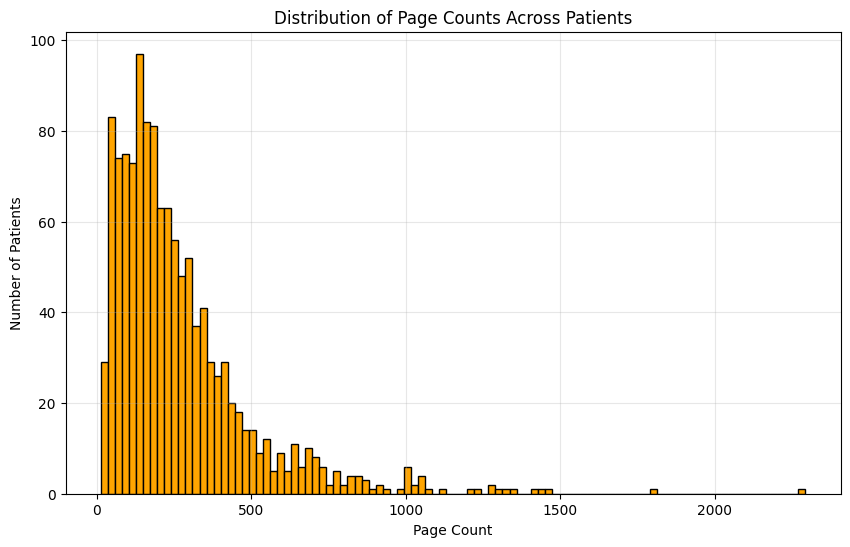
전자 건강 기록(EHR) 내 비구조화된 메모는 암 치료 의사결정과 연구에 필수적인 풍부한 임상 정보를 담고 있지만, 변동성, 전문 용어, 문서 형식의 불일치 등으로 구조화된 온콜로지 데이터를 신뢰성 있게 추출하는 것은 여전히 어려운 과제이다. 수작업 추출은 정확도가 높지만 비용이 과도하고 확장성이 부족하다. 기존 자동화 방법은 합성 데이터셋에 의존하거나 문서 수준 추출에 국한되며, 특정 변수(예: 병기, 바이오마커, 조직학)만을 대상으로 하는 경우가 대부분이라 다수의 임상 문서에 걸친 환자 수준의 종합 정보를 충분히 다루지 못한다. 본 연구에서는 복잡한 온콜로지 데이터 추출 작업을 모듈화하고 상황에 맞게 적응하도록 설계된 에이전트 프레임워크를 제안한다. 구체적으로, 대형 언어 모델(LLM)을 추론 에이전트로 활용하고, 문맥에 민감한 검색 및 반복적 합성 메커니즘을 결합하여 방대한 임상 문서에서 구조화된 임상 변수를 철저하고 포괄적으로 추출한다.💡 논문 핵심 해설 (Deep Analysis)
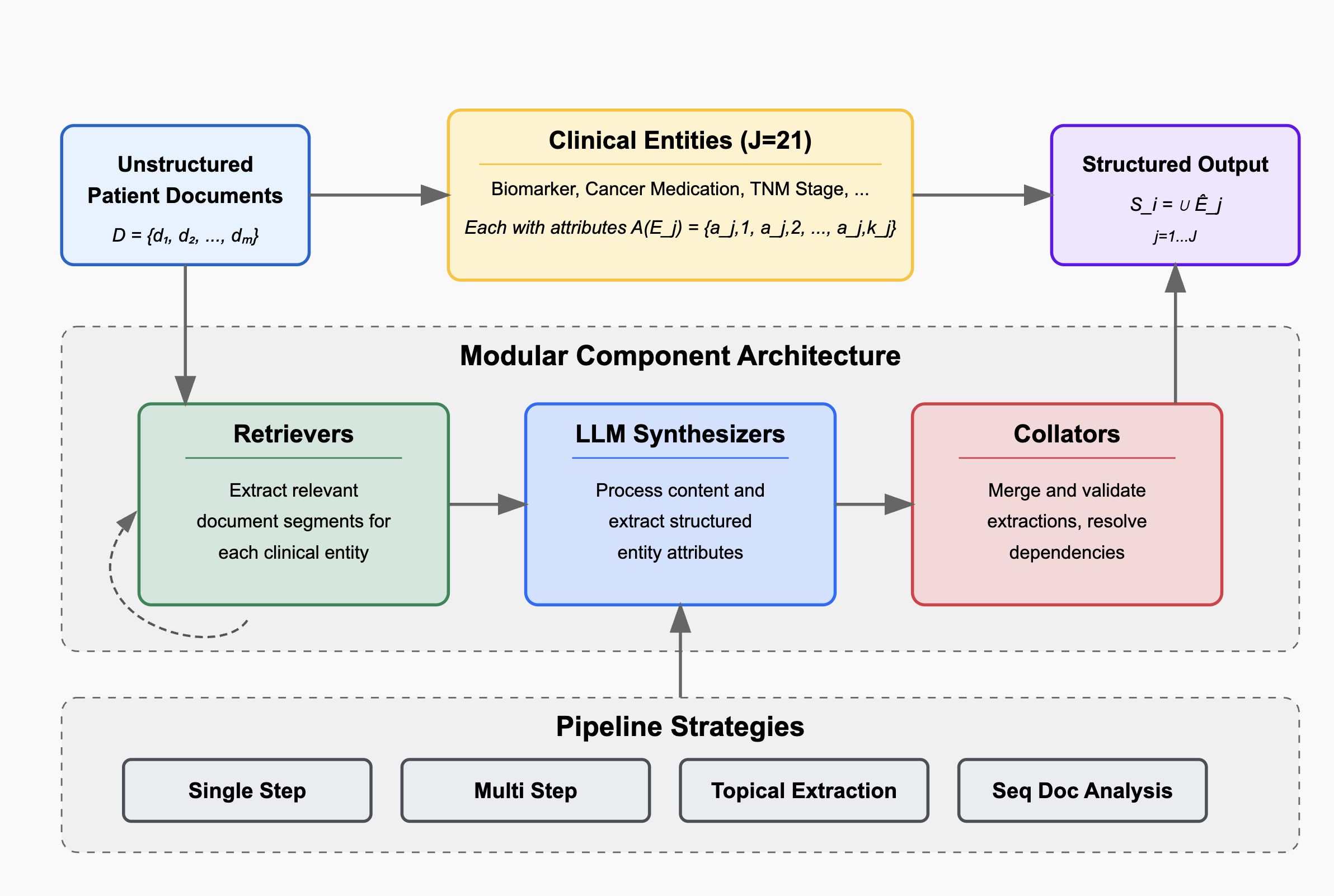
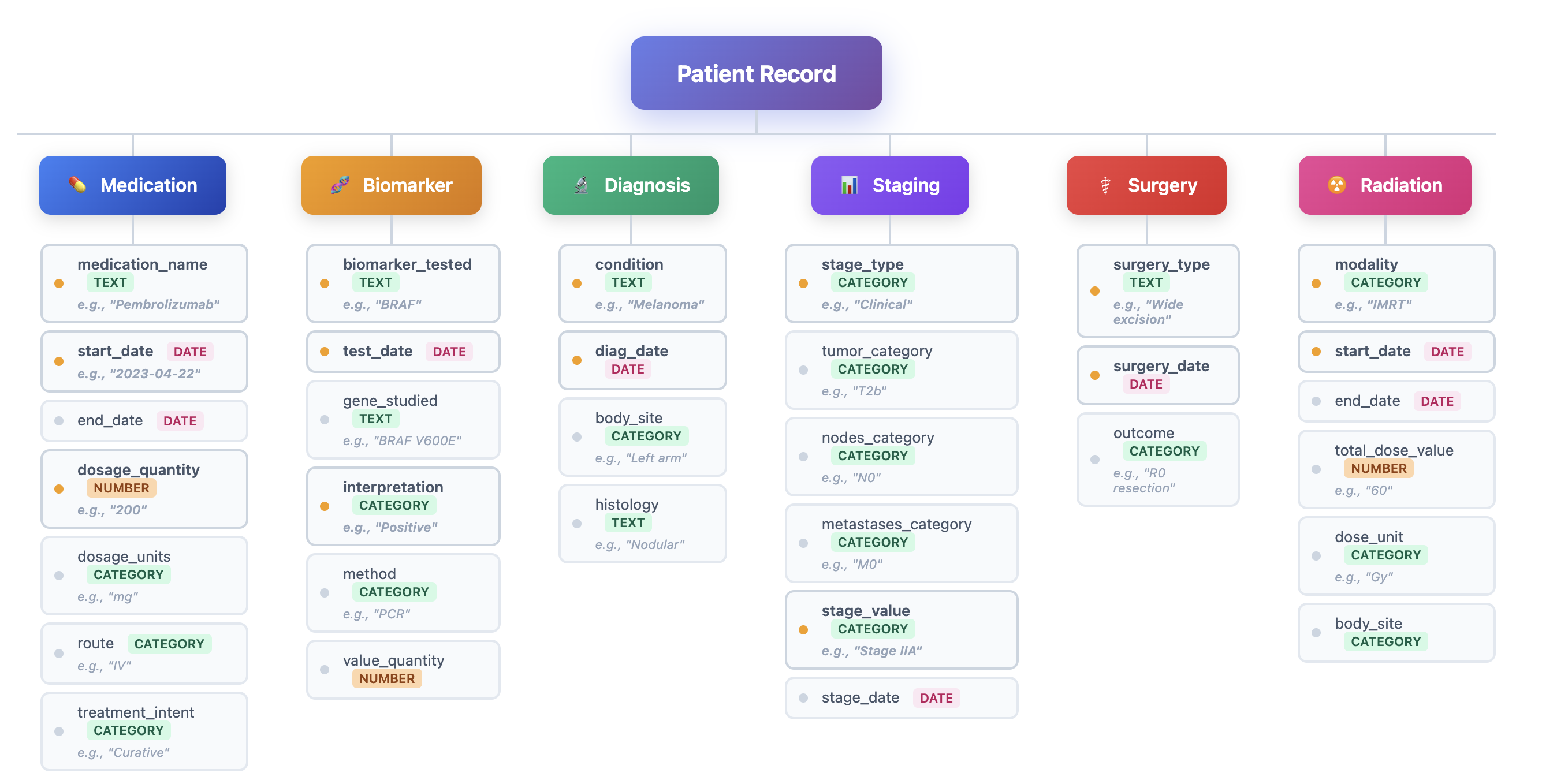
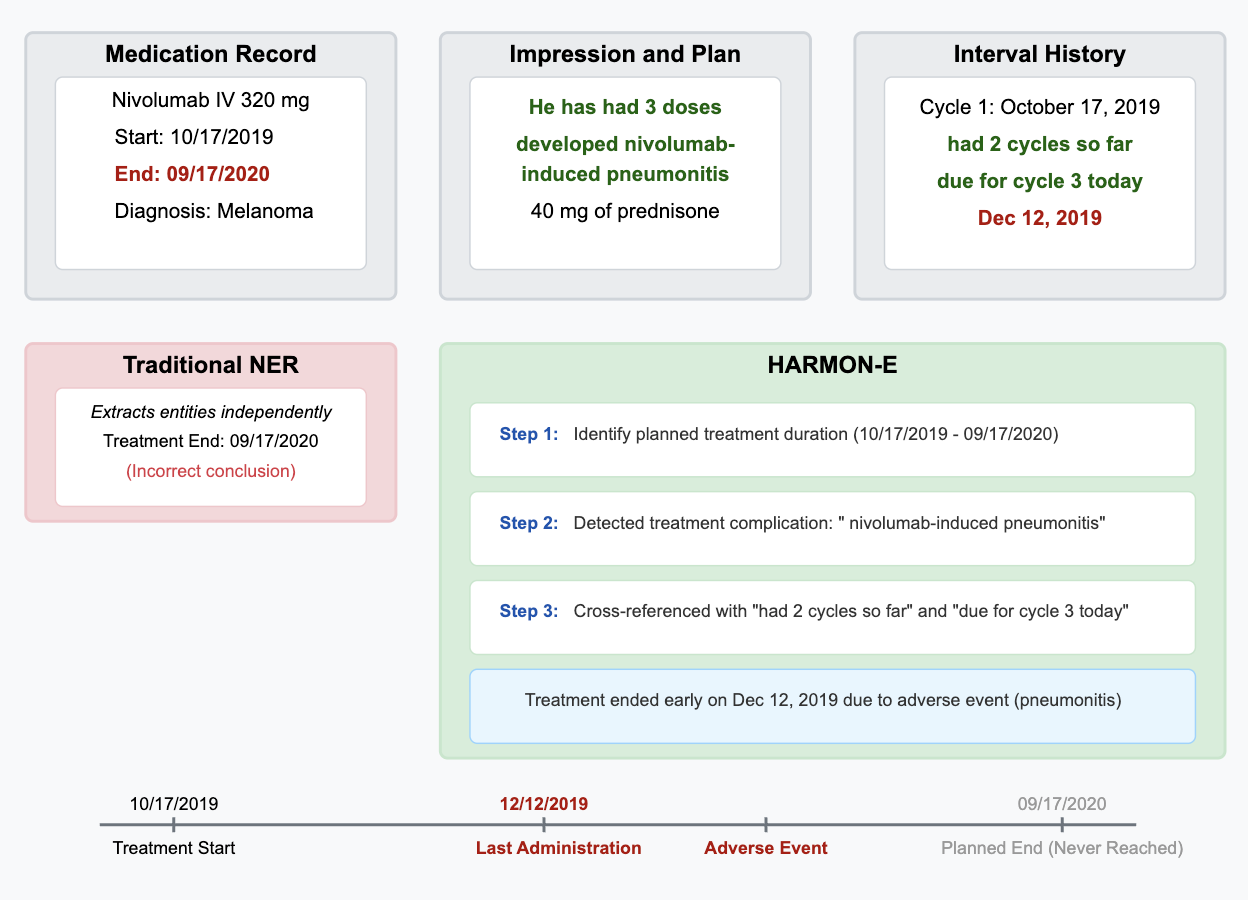
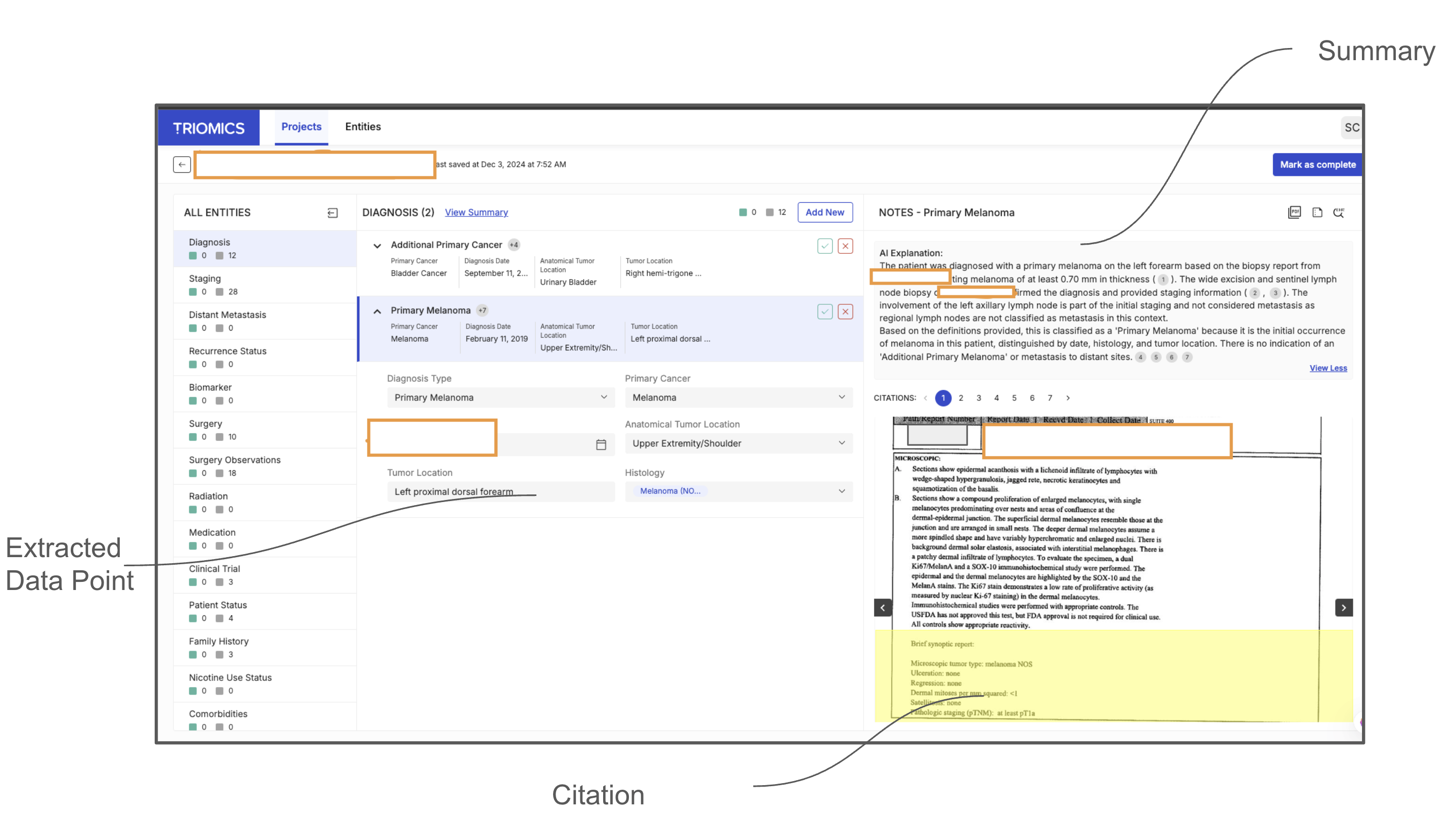
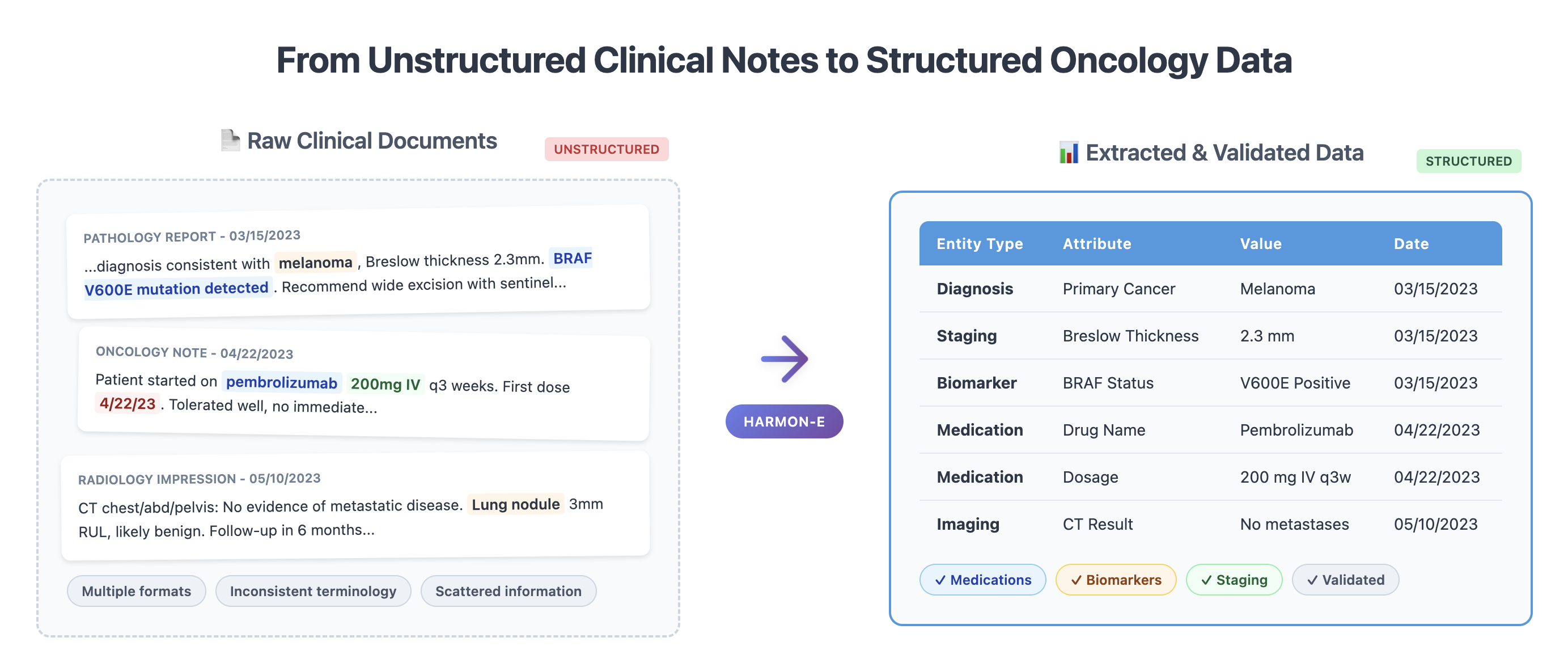
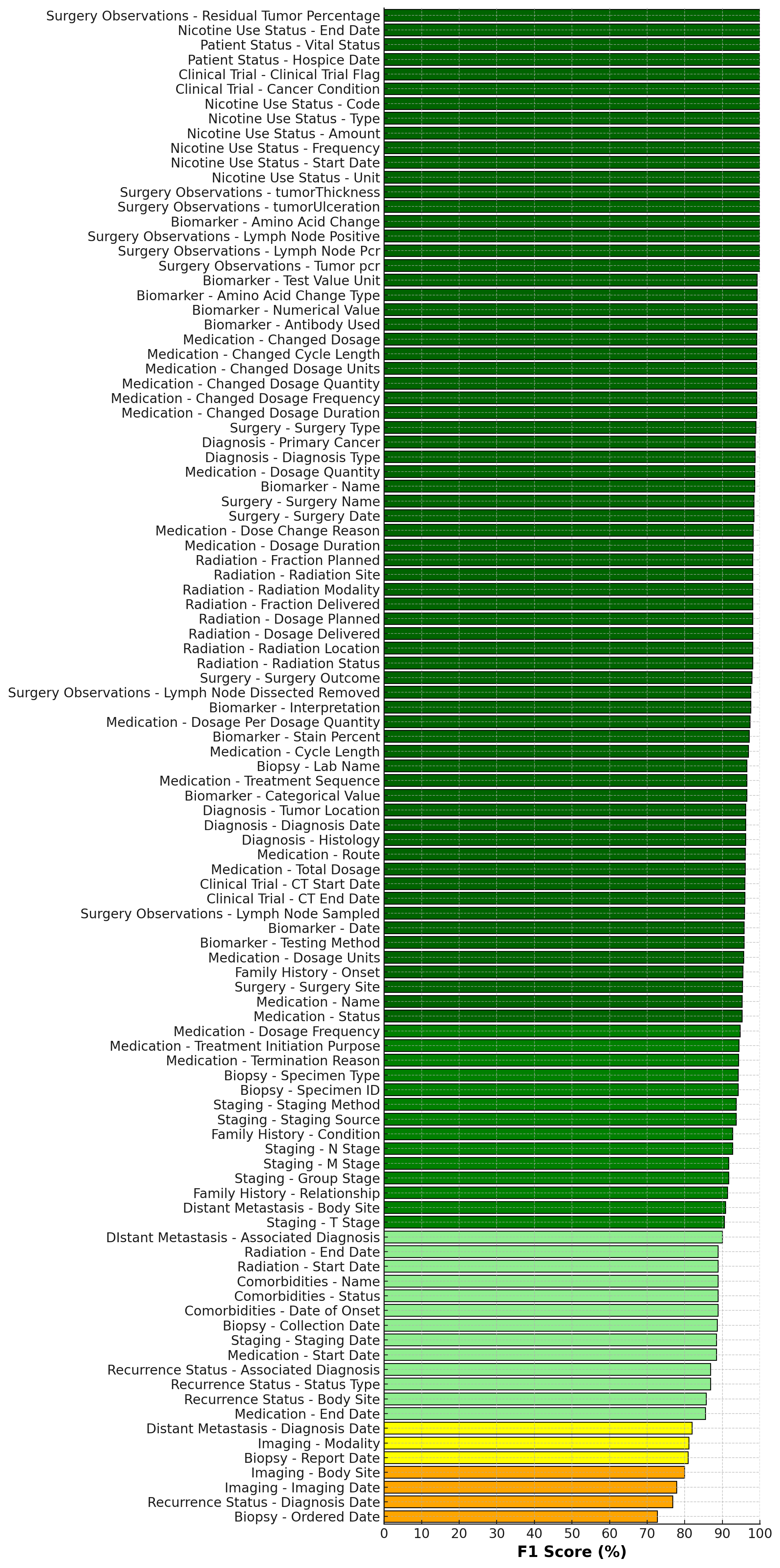
이러한 문제점을 해결하기 위해 저자들은 “에이전트 기반 프레임워크”라는 새로운 패러다임을 제시한다. 핵심 아이디어는 LLM을 단순한 텍스트 생성기가 아니라 ‘추론 에이전트’로 활용해, (1) 문맥에 맞는 문서 검색, (2) 단계별 정보 추출, (3) 추출된 결과의 교차 검증 및 통합, (4) 필요 시 인간 전문가에게 피드백을 요청하는 순환 구조를 만든다. 구체적으로, 프레임워크는 먼저 환자 ID를 기준으로 관련 문서를 전용 검색 모듈이 수집한다. 이후 각 문서는 ‘질문-응답’ 형태의 프롬프트를 통해 LLM에게 특정 변수(예: TNM 병기, HER2 발현, 조직학적 등급)를 추출하도록 지시한다. 추출된 값들은 메타데이터(문서 출처, 추출 시점, 신뢰도 점수)와 함께 임시 데이터베이스에 저장된다. 다음 단계에서는 동일 변수에 대해 여러 문서에서 나온 결과를 비교·대조하고, 충돌이 감지되면 “재검증 프롬프트”를 발행해 LLM에게 추가 근거를 제시하도록 요구한다. 최종적으로 가장 높은 신뢰도와 일관성을 보이는 값이 환자 수준의 구조화된 레코드로 확정된다.
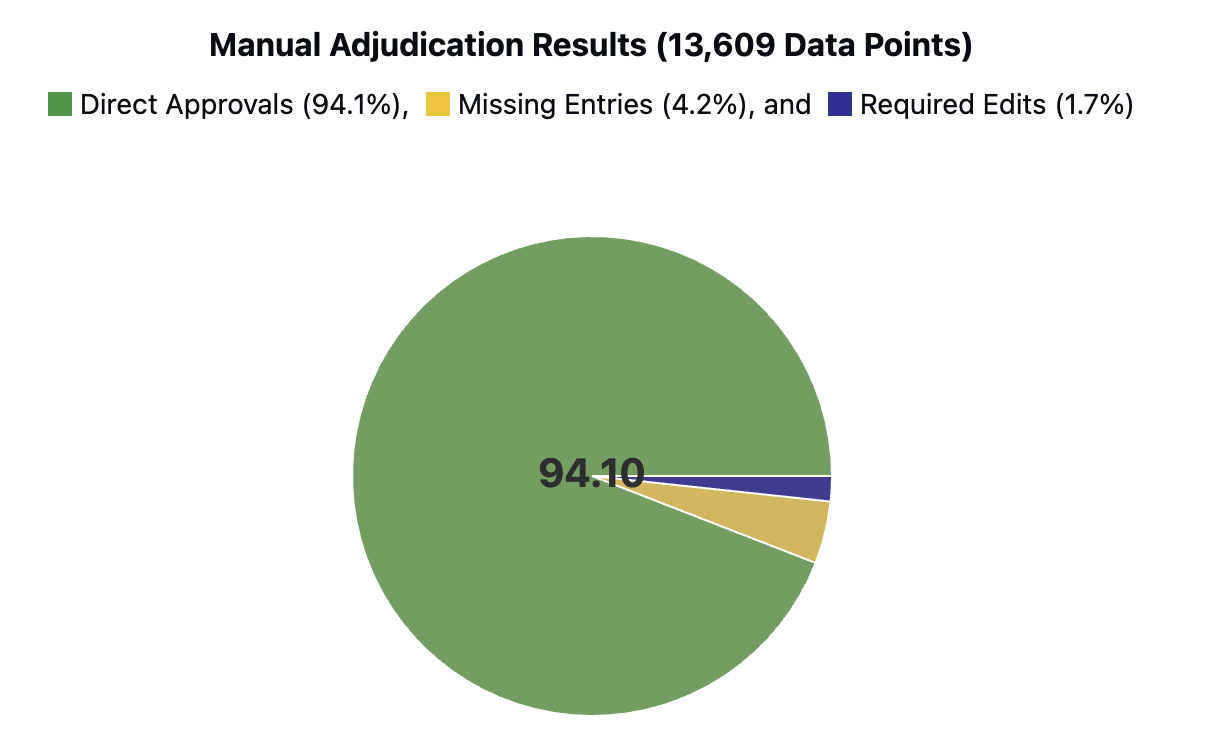
이 접근법의 강점은 첫째, 모듈화된 설계 덕분에 각 단계(검색, 추출, 합성)를 독립적으로 개선하거나 교체할 수 있다는 점이다. 예를 들어 최신 정보 검색 엔진이나 도메인 특화된 용어 사전을 삽입해 성능을 향상시킬 수 있다. 둘째, 반복적 합성 메커니즘을 통해 문서 간 모순을 자동으로 탐지하고 해결함으로써 인간 전문가가 수행하던 ‘데이터 정제’ 작업을 크게 경감한다. 셋째, LLM을 에이전트로 활용함으로써 복잡한 임상 질문에 대한 추론 과정을 투명하게 로그로 남길 수 있어, 결과에 대한 설명 가능성(Explainability)도 확보한다.
그러나 몇 가지 한계도 존재한다. 현재 프레임워크는 LLM의 사전 학습 데이터에 크게 의존하므로, 최신 치료 가이드라인이나 희귀 변이에 대한 지식이 부족할 경우 정확도가 떨어질 수 있다. 또한, ‘재검증 프롬프트’가 무한히 반복될 위험이 있어, 수렴 기준과 비용(시간·연산량) 관리가 필요하다. 마지막으로, 실제 병원 환경에서 개인정보 보호와 데이터 보안 요구사항을 충족시키기 위해 프레임워크를 온프레미스 형태로 구현하거나, 모델을 의료 전용으로 파인튜닝하는 추가 작업이 요구된다.
향후 연구 방향으로는 (1) 도메인 특화 파인튜닝을 통해 LLM의 의료 용어 이해도를 높이고, (2) 강화학습 기반의 ‘합성 정책’ 학습을 도입해 모순 해결 과정을 최적화하며, (3) 대규모 실제 EHR 데이터셋에 대한 베타 테스트를 통해 실용성을 검증하고, (4) 규제 기관과 협력해 인증된 의료 AI 솔루션으로 전환하는 로드맵을 제시할 수 있다. 전반적으로, 이 논문은 복잡하고 이질적인 암 임상 데이터를 자동으로 구조화하는 데 필요한 기술적·방법론적 토대를 제공하며, 향후 정밀 의학 및 임상 연구 데이터 파이프라인 구축에 중요한 전환점을 마련한다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리