에이전트형 인공지능 보안을 위한 라이프사이클 기반 프레임워크
📝 원문 정보
- Title: Securing Agentic AI Systems – A Multilayer Security Framework
- ArXiv ID: 2512.18043
- 발행일: 2025-12-19
- 저자: Sunil Arora, John Hastings
📝 초록 (Abstract)
에이전트형 인공지능(AI) 시스템을 안전하게 운영하려면 자율적·의사결정·적응 행동이 초래하는 복합 사이버 위험을 해결해야 한다. 이러한 시스템은 사이버보안, 금융, 의료 등 핵심 분야에 점점 더 많이 도입되고 있으나, 자율성으로 인해 무단 행동, 적대적 조작, 동적 환경 상호작용 등 고유한 보안 문제가 발생한다. 기존 AI 보안 프레임워크는 이러한 문제와 에이전트형 AI의 특수성을 충분히 다루지 못한다. 본 연구는 설계 과학 연구(Design Science Research) 방법론을 적용해 에이전트형 AI 전용 라이프사이클 보안 프레임워크인 MAAIS와 CIAA(기밀성·무결성·가용성·책임성) 개념을 제시한다. MAAIS는 AI 개발·운영 전 단계에 걸쳐 다중 방어층을 통합해 CIAA를 유지하도록 설계되었으며, MITRE ATLAS의 AI 위협 전술과 매핑하여 검증하였다. 이 프레임워크는 기업 CISO, 보안·AI 플랫폼·엔지니어링 팀을 대상으로 하며, 에이전트형 AI 워크로드의 안전한 배포와 거버넌스를 위한 단계별 지침을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
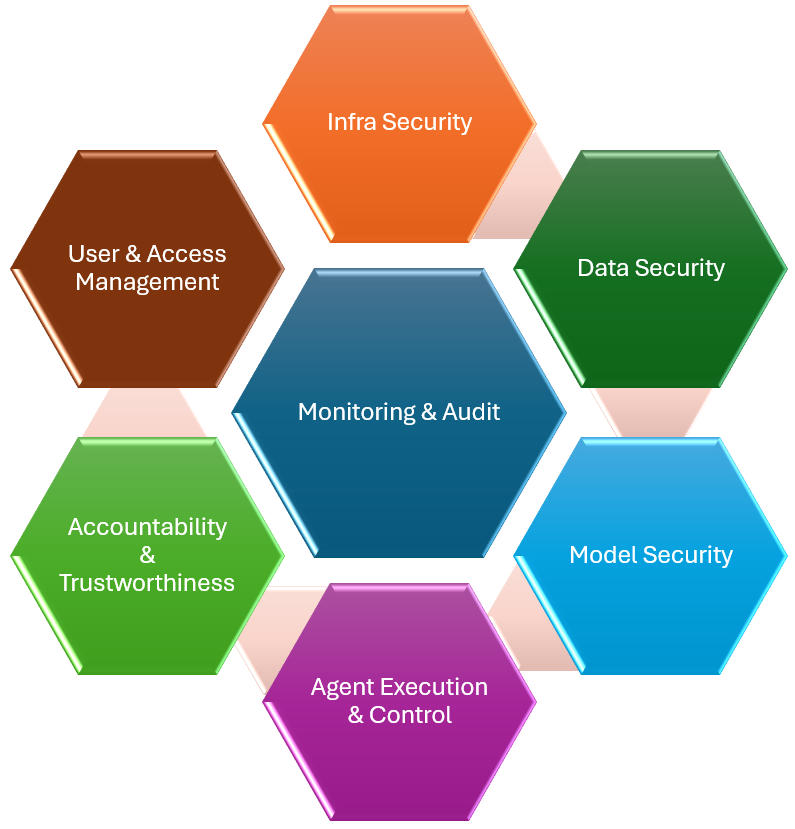
연구진은 설계 과학 연구(Design Science Research, DSR) 방법론을 채택해 문제 정의‑설계‑평가‑지식 축적의 순환 과정을 체계화했다. DSR은 실무적 요구와 이론적 기여를 동시에 충족시키는 설계물(artifact)을 창출하는데 적합한 접근법이며, 본 논문에서는 ‘MAAIS(멀티‑레벨 에이전트 AI 보안 프레임워크)’라는 설계물을 도출한다. MAAIS는 AI 라이프사이클을 설계·개발·배포·운영·폐기 단계로 구분하고, 각 단계마다 예방·탐지· 대응· 복구· 감사의 다섯 방어 레이어를 적용한다. 이때 핵심 보안 목표는 CIAA(Confidentiality, Integrity, Availability, Accountability)로 재정의되었으며, 특히 ‘책임성(Accountability)’을 추가함으로써 에이전트의 행동 로그, 의사결정 근거, 정책 변경 이력을 추적·검증하도록 설계했다.
프레임워크 검증은 MITRE ATLAS(Adversarial Threat Landscape for Artificial‑Intelligence Systems)와의 매핑을 통해 수행되었다. ATLAS는 AI 시스템에 특화된 위협 전술·기술·절차(TTP)를 체계화한 표준이며, MAAIS는 각 TTP에 대응하는 방어 메커니즘을 명시적으로 연결한다. 예를 들어, ‘Model Poisoning’에 대해서는 데이터 검증·샘플링 레이어와 지속적 무결성 검증을, ‘Policy Manipulation’에 대해서는 의사결정 로그 감사와 실시간 정책 검증 레이어를 매핑한다. 이러한 매핑은 프레임워크가 실제 공격 시나리오에 어떻게 적용될 수 있는지를 구체적으로 보여주며, 실무 적용 가능성을 크게 높인다.
강점으로는 (1) 라이프사이클 전반을 포괄하는 통합 보안 관점, (2) 책임성을 보안 목표에 포함시켜 규제·감사 요구에 대응, (3) MITRE ATLAS와의 정량적 매핑을 통한 검증 절차가 있다. 반면 한계점은 (1) 프레임워크 적용을 위한 조직 내 프로세스·문화 변화가 필요하고, (2) 다중 방어층이 운영 비용·성능 오버헤드를 초래할 수 있다는 점이다. 또한 현재 검증은 매핑 기반 시뮬레이션에 머물러 있어, 실제 에이전트형 AI 시스템에 대한 실증 실험이 부족하다.
향후 연구 방향은 (1) MAAIS를 자동화된 정책 엔진과 연계해 방어 레이어의 실시간 조정 메커니즘을 구현, (2) 표준 메트릭을 정의해 보안 효과를 정량화, (3) 다양한 도메인(예: 의료, 금융)에서 파일럿 프로젝트를 수행해 프레임워크의 확장성과 적용성을 검증하는 것이다. 이러한 과제가 해결된다면, 에이전트형 AI가 핵심 인프라에 안전하게 통합될 수 있는 기반을 제공하게 될 것이다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리
